
Chapter 5: Crossing the Language Barrier with the Arrow C Data API
Not to sound like a broken record, but I've said several times already that Apache Arrow is a collection of libraries rather than one single library. This is an important distinction from both a technical standpoint and a logistical one. From a technical standpoint, it means that third-party projects that depend on Arrow don't need to use the entirety of the project and instead can only link against, embed, or otherwise include the portions of the project they need. This allows for smaller binaries and a smaller surface area of dependencies. From a logistical standpoint, it allows the Arrow project to pivot easily and move in potentially experimental directions without making large, project-wide changes.
As the goal of the Arrow project is to create a collection of tools and libraries that can be shared across the data analytics and data science ecosystems with a shared in-memory representation, there are lots of areas in which Arrow can become useful. First of all, there are the utilities for reading and writing data files which we've already covered (Chapter 2,Working with Key Arrow Specifications), and there are the interoperability utilities provided for integration with pandas and Spark (Chapter 3, Data Science with Apache Arrow). This chapter is going to specifically cover another area – the efficient sharing of data between different languages and runtimes in the same process:
- The Arrow C data interface for sharing both schemas and data
- The Arrow C data interface for streaming record batches of data
- Use cases where this interface is beneficial
Technical requirements
This chapter is intended to be highly technical, with various code examples and exercises diving into the usage of the different Arrow libraries. As such, like before, you need access to a computer with the following software to follow along:
- Python 3+ – the pyarrow module installed and importable
- Go 1.16+
- A C++ compiler supporting C++11 or better
- Your preferred IDE – Sublime, Visual Studio Code, Emacs, and so on
Using the Arrow C data interface
Back in Chapter 2, Working with Key Arrow Specifications, I mentioned the Arrow C data interfaces in regard to the communication of data between Python and Spark processes. At that point, we didn't go much into detail about the interface or what it looks like; now, we will.
Because the Arrow project is fast-moving and evolving, it can sometimes be difficult for other projects to incorporate the Arrow libraries into their work. There's also the case where there might be a lot of existing code that needs to be adapted to work with Arrow piecemeal, leading to you having to create or even re-implement adapters for interchanging data. To avoid redundant efforts across these situations, the Arrow project defines a very small, stable set of C definitions that can be copied into a project to allow to easily pass data across the boundaries of different languages and libraries. For languages and runtimes that aren't C or C++, it should still be easy to use whatever Foreign Function Interface (FFI) declarations correspond to your language or runtime.
The benefits of this approach are as follows:
- Developers can choose to either tightly integrate their utilities with the Arrow project and all of its facilities and libraries, or have minimal integration with just the Arrow format.
- A stable Application Binary Interface (ABI) for zero-copy sharing of data between different runtimes and components in the same process.
- Allows for integration of Arrow without needing an explicit compile-time or runtime dependency on the Arrow libraries.
- Avoids needing to create singular adapters for specific cases such as JPype (a bridge between Java and Python) in favor of a generalized approach that anyone can implement support for, with little investment needed.
One thing to keep in mind is that the C interface is not intended to provide a C API for the higher-level operations exposed by things such as Java, C++, or Go. It's specifically for just passing the Arrow data itself. Also, the interface is intended for sharing data between different components of the same process – if you're passing data in between distinct processes or attempting to store the data, you should use the IPC format instead (which we covered in Chapter 4, Format and Memory Handling).
If we compare the IPC and C data formats, we can see some important considerations.
A C data interface is superior to the IPC format in the following ways:
- Zero-copy by design.
- Customizable release callback for resource lifetime management.
- Minimal C definition that is easily copied to different code bases.
- Data is exposed in Arrow's logical format without any dependency on FlatBuffers.
The IPC format is superior to the C data interface in the following ways:
- It allows for storage and persistence or communication across different processes and machines.
- It does not require C data access.
- It has room to add other features such as compression since it is a streamable format.
Now that we've explained why the C data interface exists, let's dive into the structure definitions and how it all works. There are three structures exposed in the header file – ArrowSchema, ArrowArray, and ArrowArrayStream. At the time of writing, the following Arrow language libraries already provide functionality for both exporting and importing Arrow data using the C data interface:
- C++
- Python
- R
- Rust
- Go
- Java
- Ruby
- C/GLib
The first thing we're going to dive into is the ArrowSchema structure.
The ArrowSchema structure
When working with data frequently, either the data type or schema is fixed by the API or one schema applies to multiple batches of data of varying sizes. By separating the schema description and the data itself into two separate structures, the ABI allows producers of Arrow C data to avoid the cost of exporting and importing the schema for every single batch of data. In cases where it's just a single batch of data, the same API call can return both structures at once, providing efficiency in both situations.
An Interesting Tidbit
Despite the name, the ArrowSchema structure is actually more similar to the arrow::Field class in the C++ library than the arrow::Schema class. The C++ Schema class represents a collection of fields (containing a name, datatype, and potential metadata) and optional schema-level metadata. By having the ArrowSchema structure more closely resemble the Field representation, it can serve dual purposes; a full schema is represented as the Struct type whose children are the individual fields of the schema. This reuse keeps the ABI smaller and requires only the two ArrowSchema and ArrowArray structures instead of requiring another to represent fields too.
This is the definition of the ArrowSchema structure:
#define ARROW_FLAG_DICTIONARY_ORDERED 1
#define ARROW_FLAG_NULLABLE 2
#define ARROW_FLAG_MAP_KEYS_SORTED 4
struct ArrowSchema {// Array type description
const char* format;
const char* name;
const char* metadata;
int64_t flags;
int64_t n_children;
struct ArrowSchema** children;
struct ArrowSchema* dictionary;
// Release callback
void (*release)(struct ArrowSchema*);
// Opaque producer-specific data
void* private_data;
};
Simple, straightforward, and easy to use, right? Let's look at the different fields.
- const char* format (required):
- A null-terminated, UTF8-encoded string describing the data type. Child data types for nested arrays are encoded in the child structures.
- const char* name (optional):
- A null-terminated, UTF8-encoded string containing the name of the field or array. Primarily for reconstructing child fields of nested types. If omitted, it can be NULL or an empty string.
- const char* metadata (optional):
- A binary string containing the metadata for the type; it is not null-terminated. The format is described in Figure 5.6.
- int64_t flags (optional):
- Bitfield of flags computed by performing a bitwise OR of the flag values. If omitted, it should be 0. The flags available are the macros defined above the structure:
- ARROW_FLAG_NULLABLE: Set if the field is allowed to be null (regardless of whether there are actually any nulls in the array).
- ARROW_FLAG_DICTIONARY_ORDERED: If this is a dictionary-encoded type, set this if the order of the index is semantically meaningful.
- ARROW_FLAG_MAP_KEYS_SORTED: For a map type, set this if the keys within each value are sorted.
- Bitfield of flags computed by performing a bitwise OR of the flag values. If omitted, it should be 0. The flags available are the macros defined above the structure:
- int64_t n_children (required):
- The number of children for this data type if nested, or 0
- struct ArrowSchema** children (optional):
- There must be a number of pointers equal to n_children in this C array. If n_children is 0, this may be null.
- struct ArrowSchema* dictionary (optional):
- If this schema represents a dictionary-encoded type, this must be non-null and point to the schema for the type of the dictionary values. Otherwise, this must be null.
- void (*release)(struct ArrowSchema*) (required):
- A pointer to a callback function for releasing the associated memory for this object
- void *private_data (optional):
- A pointer to some opaque data structure provided by the producing API if necessary. Consumers must not process this member; the lifetime of any memory it points to is handled by the producing API.
Note that the format field describes the data type using a string. Let's see how to determine the data type from that string.
The data type format
The data type itself is described by a format string that only describes the top-level type's format. Nested data types will have their child types in child schema objects, and metadata will be encoded in a separate member field. All the format strings are designed to be extremely easy to parse, with the most-common primitive formats each having a single character for their format string. The primitive formats are shown in Figure 5.1:
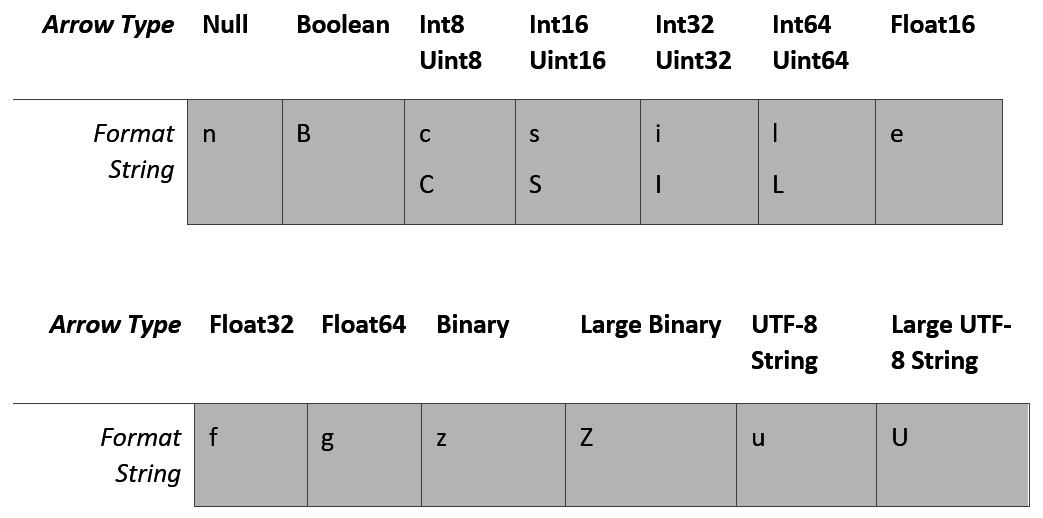
Figure 5.1 – Primitive type format strings
A couple of parameterized data types such as decimal and fixed-width binary have format strings consisting of a single character and a colon, followed by parameters, as shown in Figure 5.2:

Figure 5.2 – Decimal and fixed-width binary format strings
Our next group of types are the temporal types, the dates and the times; these format strings are all multi-character strings that start with t, as depicted in Figure 5.3. For the timestamp types that may optionally contain a specified time zone, that time zone is appended as is after the colon without any quotes around it. The colon character is not omitted when the time zone is empty; it must still be included:
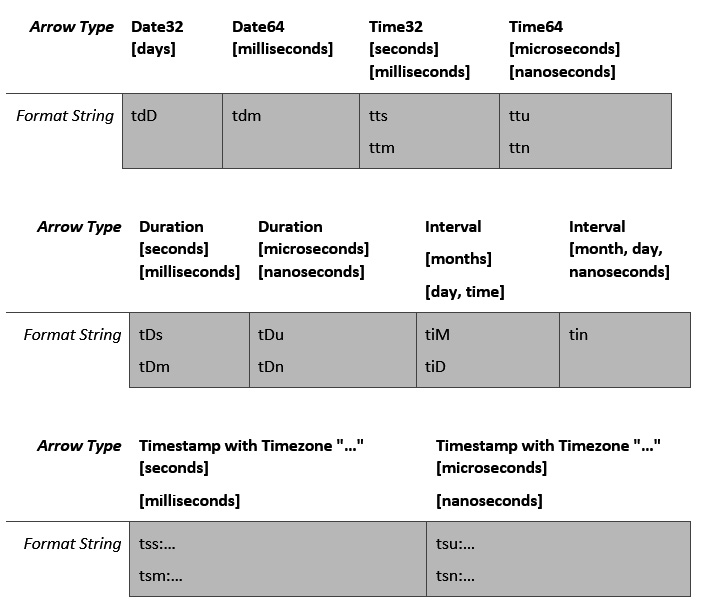
Figure 5.3 – Temporal data type format strings
Note that dictionary-encoded types don't have a specific format string to indicate that they are encoded as such. For a dictionary-encoded array, the format string of ArrowSchema indicates the format of the index type with the value type of the dictionary described by the dictionary member field. For example, a dictionary-encoded timestamp array using milliseconds as the unit with no time zone that uses the int16 indices would have a format string of s, and the dictionary member field would have a format string of tsm:.
Finally, there are the nested types. All the nested types, shown in Figure 5.4, are multi-character format strings that begin with +:

Figure 5.4 – Nested-type format strings
Just like the case for dictionary-encoded arrays, the data type and name of the child fields for the nested types will be in the array of child schemas. Keep in mind when thinking about the Map data type; according to the Arrow format specification, it should always have a single child type named entries, which is itself a struct, with two child types named key and value.
The last important piece for the schema description is encoding metadata for your field or record batch.
The encoding scheme for metadata
The metadata field in our schema object needs to represent a series of pairs of keys and values in a single binary string. To do this, the metadata key-value pairs are encoded with a defined format that can be easily parsed but is still compact:
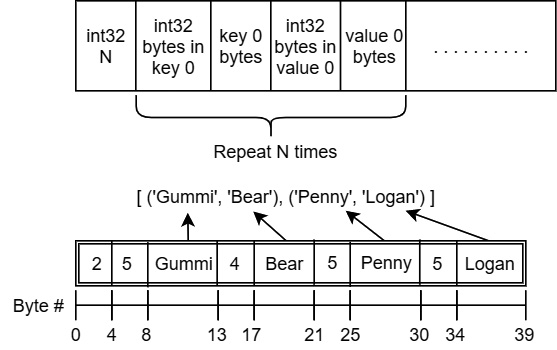
Figure 5.5 – Metadata encoding with an example
Figure 5.5 shows the format of the encoded metadata along with an example using the key-value pairs ([('Gummi', 'Bear'), ('Penny', 'Logan')]). The 32-bit integers being encoded in the metadata will use whatever the native endianness is for the platform, so for the same metadata, here is what it would look like on a little-endian machine:
x02x00x00x00x05x00x00x00Gummix04x00x00x00Bearx05x00x00x00Pennyx05x00x00x00Logan
Note that the bytes for the keys and values are not null-terminated. On a big-endian machine, the same metadata would be represented like this:
x00x00x00x02x00x00x00x05Gummix00x00x00x04Bearx00x00x00x05Pennyx00x00x00x05Logan
Look closely at the 4-byte groups that define the number of keys and the length of the strings. The difference between the endianness is the order of the bytes when specifying numbers, with the most significant byte occurring first on a big-endian machine and last on a little-endian machine.
What about the extension type?
Eagle-eyed readers may notice that one data type was missing from those data type format strings – the user-defined extension type. To recap a little, the extension type exists as a way for users of Arrow to define their own data types in terms of the existing ones by defining metadata keys. The format field of the ArrowSchema struct indicates the storage type of the array and, as such, wouldn't indicate something like an extension type. Instead, that information would get encoded in the metadata using the established ARROW:extension:name and ARROW:extension:metadata keys. Exporting an array of an extension type is merely just exporting the storage type array with those metadata key-value pairs added in.
Exercises
Before we move on to describe how the array data is described, try a couple of exercises:
- How would the schema of a dictionary-encoded decimal128(precision=12, scale=5) array using the uint32 indices be represented with the format strings and this struct?
- What about a list<uint64> array?
- Let's switch it up a bit now – try the struct<ints: int32, floats: float32> data type.
- Try with an array with the map<string, float64> type.
Okay, let's now move on to the data itself.
The ArrowArray structure
To interpret an ArrowArray instance and use the data that is being described, you need to already know the schema or array type first. This is determined either by convention, such as a defined type that your API always produces, or by passing a corresponding ArrowSchema object along with the ArrowArray object. The definition of this structure is as follows:
struct ArrowArray {int64_t length;
int64_t null_count;
int64_t offset;
int64_t n_buffers;
int64_t n_children;
const void** buffers;
struct ArrowArray** children;
struct ArrowArray* dictionary;
// release callback
void (*release)(struct ArrowArray*);
// opaque producer related data
void* private_data;
};
If you look closely, it essentially just follows the definition of how the Arrow format specification describes an array. Here's what each field is used for and whether it is required or optional:
- int64_t length (required):
- The logical length of the array and the number of items
- int64_t null_count (required):
- The number of null items in the array. It may be -1 to represent it not being computed yet.
- int64_t offset (required):
- The number of physical items in the buffers before the start of the array. This allows buffers to get reused and sliced by setting lengths and offsets into the buffers. It must be 0 or a positive integer.
- int64_t n_buffers (required):
- The number of allocated buffers that contain the data associated with this array, dependent on the data type, as described in Chapter 1, Getting Started with the Arrow Format. The buffers of child arrays are not included; this must match the length of the C array of buffers.
- const void** buffers (required):
- A C array of pointers to the start of each buffer of data associated with this array. Each void* pointer must point to the start of a contiguous chunk of memory or be null. There must be exactly n_buffers pointers in this array. If null_count is 0, the null bitmap buffer may be omitted by setting its pointer to null.
- int64_t n_children (required):
- ArrowArray** children (optional):
- A C array of pointers to the ArrowArray instances for each child of this array. There must be exactly n_children pointers in this array. If n_children is 0, this may be null.
- ArrowArray* dictionary (optional):
- A pointer to the dictionary value array if the data is dictionary-encoded. If the array is a dictionary-encoded array, this must be a valid pointer and must be null if it's not a dictionary-encoded array.
- void (*release)(struct ArrowArray*) (required):
- A pointer to a callback function for releasing the associated memory for this object
- void *private_data: (optional):
So, why would you use this? When would it be relevant to you? Let's see.
Example use cases
One significant proposed benefit of having the C Data API was to allow applications to implement the API without requiring a dependency on the Arrow libraries. Let's suppose there is an existing computational engine written in C++ that wants to add the ability to return data in the Arrow format without adding a new dependency or having to link with the Arrow libraries. There are many possible reasons why you might want to avoid adding a new dependency to a project. This could range from the development environment to the complexity of deployment mechanisms, but we're not going to focus on that side of it.
Using the C Data API to export Arrow-formatted data
Do you have your development environment all set up for C++? If not, go and do that and come back. You know the drill; I'll wait.
We'll start with a small function to generate a vector of random 32-bit integers, which will act as our sample data. You know how to do that? Well, good. Go and do that yourself before you look at my bare-bones random data generator code snippet, as follows:
#include <algorithm>
#include <limits>
#include <random>
#include <vector>
std::vector<int32_t> generate_data(size_t size) {static std::uniform_int_distribution<int32_t> dist(
std::numeric_limits<int32_t>::min(),
std::numeric_limits<int32_t>::max());
static std::random_device rnd_device;
std::default_random_engine generator(rnd_device());
std::vector<int32_t> data(size);
std::generate(data.begin(), data.end(), [&]() {return dist(generator); });
return data;
}
Note that we use the static keyword in the function, so it only instantiates the random device once. However, this has the side effect of the function not being thread-safe.
Okay, now that we have our random data generator function, we can make something to utilize the C Data API and export the data:
- First, you will need to download a copy of the C Data API from the Arrow repository. The file you want is located here: https://github.com/apache/arrow/blob/master/cpp/src/arrow/c/abi.h.
Make sure you have that header file locally; it has the definitions for the ArrowSchema and ArrowArray structs I mentioned earlier.
- Next, we need to create a function that will export the data. To simulate the idea of an engine that exports data through this C API, it will be a function that only takes a pointer to an ArrowArray struct. We know that we're exporting 32-bit integer data, so this example won't pass ArrowSchema. The following function will populate the passed-in struct with the data generated from our random generator function:
- The function signature will take a pointer to the ArrowArray object to populate:
void export_int32_data(struct ArrowArray* array) {
- First, we'll create a pointer to a vector on the heap using the move constructor and our data generator:
std::vector<int32_t>* vecptr =
new std::vector<int32_t>(
std::move(generate_data(1000)));
- Now, we can construct our object. Note the highlighted lines pointing out where we allocate the C array for the buffers and the release callback function, and maintain a pointer to the vector of data. We know the length will be the size of the vector and that we're going to have two buffers, the null bitmap and the raw data. An ArrowArray object is marked as released by setting its release callback to null, which we do as the last step of the release Lambda function:
array = (struct ArrowArray) {
.length = vecptr->size(),
.null_count = 0,
.offset = 0,
.n_buffers = 2,
.n_children = 0,
.buffers = (const void**)malloc(sizeof(void*)*2),
.children = nullptr,
.dictionary = nullptr,
.release = [](struct ArrowArray* arr) {
free(arr->buffers);
delete reinterpret_cast<
std::vector<int32_t>*>(
arr->private_data);
arr->release = nullptr;
},
.private_data =
reinterpret_cast<void*>(vecptr),
};
- Finally, since there are no nulls, we can set the first buffer (the null bitmap) to null. The highlighted line sets the second buffer to just point at the raw underlying data of the vector itself:
array->buffers[0] = nullptr;
array->buffers[1] = vecptr->data();
} // end of function
- So far, we have a C++ file that creates a function, but we want to export it as a C-compatible API. All we have to do is add this snippet somewhere before the definition of the function we just created:
extern "C" {
void export_int32_data(struct ArrowArray*);
}
If you're familiar with the differences between C++ linking and C linking, you'll understand why this is needed. For everyone else, the long and short of it is that C++ likes to mangle the names of your exported functions in specific ways. By declaring the function as extern "C", you're informing the compiler of your intent to keep this function name unmangled because you want it to be externally linkable by C.
- Now, we compile this file and create a lovely little shared library that we can load to call this function. Assuming you are using g++ as your compiler, the command you would use is the following:
$ g++ -fPIC -shared -o libsample.so example_cdata.cc
This will create a shared-object file, with the .so extension, which anything that can call a C API can use to call the export function we just made. We didn't include any Arrow C++ headers, just the copy of the C structs, and we didn't link against any Arrow libraries. This enables any caller, regardless of the language, runtime, or library, to call the function with a pointer to an ArrowArray struct and have it filled in with a chunk of data.
What can we do with this library? Well, let's write something to call it from a non-C++ runtime. Yes, I know – this is a trivial example. But you're a creative person, right? I'm sure you can take the concepts and generalized examples I've made here and adapt them for lots of creative purposes. Looking back at the earlier example in Chapter 3, Data Science with Apache Arrow, regarding how data was passed from Python to Java to improve performance, let's write a small script that will call the API from Python.
Importing Arrow data with Python
The common terminology for runtimes providing an interface for calling an API of another runtime or language is an FFI. In Python, we're going to use a library called cffi, which is used by the pyarrow module to implement the C Data API. Make sure that you're running the script we're about to write in the same directory as the libsample.so library file that we created in the previous exercise:
- First, the imports – the following highlighted line represents the essential case that we're importing the already compiled ffi library that is part of the pyarrow module:
import pyarrow as pa
from pyarrow.cffi import ffi
- There are a few different ways to integrate the FFI module, but for the purposes of this exercise, we're going to use dynamic loading of the library with the defined interface through the cdef function. Then, we load our shared object library with dlopen:
ffi.cdef("void export_int32_data(struct ArrowArray*);")
lib = ffi.dlopen("./libsample.so")
Note that this matches our extern "C" declaration from before.
- Now, we can create an ArrowArray struct and call the function we exported to populate it:
c_arr = ffi.new("struct ArrowArray*")
c_ptr = int(ffi.cast("uintptr_t", c_arr))
lib.export_int32_data(c_arr)
- Then, we use the pyarrow module to import data; remember that since we're passing around pointers, there's no copying of the data buffers. So, it doesn't matter if this array has 1,000 elements or 1 million elements; we're not copying the data here. Importing the data is just hooking everything up to point to the right areas in memory:
arrnew = pa.Array._import_from_c(c_ptr, pa.int32())
# do stuff with the array
del arrnew # will call the release callback
# once it is garbage collected
You can add a print statement in there if you like, to confirm that it is actually working as intended. But that's it. The library we created could create that array of data in any way we want, but as long as it properly populates the C struct, we're able to pass the data around in the Arrow format without having to copy it.
What if we wanted to work in the other direction? We can read in our data with Python and then hand it off to something faster for processing, similar to how Spark used JPype to communicate the data from Python to Java without copying. How would we go about doing that?
Exporting Arrow data with the C Data API from Python to Go
For this example, we're going to add a level here to go from Python to Go via the C Data API. As I mentioned earlier, the Arrow libraries for both Python and Go implement the C Data API directly, so you can easily export and import data to and from the libraries. So, let's get to it!
The first thing we're going to do is create the shared library in Go that will export a function for us to call. We're going to trivially import a passed-in Arrow record batch and write the schema, the number of columns, and the number of rows to the terminal. This can easily be replaced with calling some existing Go library or otherwise use the data, by performing calculations or some other operation that would be significantly faster in a compiled language such as Golang rather than Python, but I'll leave those ideas up to you. I'm just showing you how to do the connection to efficiently pass the data without having to perform any copies.
Building the Go shared library
Because of our usage of Cgo, you need to make sure you have the C and C++ compilers on your path and available in your Go development environment. If you're on a Linux or macOS machine, you probably already have gcc and g++ easily accessible already. On Windows, you must use either MSYS2 or MinGW development environments and install gcc and g++ to build this.
Important Note
There are a bunch of nuances and gotchas involved in using Cgo that I won't touch on much, but I highly recommend reading the documentation, which can be found here: https://pkg.go.dev/cmd/cgo.
The following steps will walk you through constructing a dynamic library using Go, which exports a function that can be called as a C-compatible API:
- First, let's put together the function that we're going to export. We start off by initializing a go module:
$ go mod init sample
- When creating a dynamic library, we use the main package, similar to creating an executable binary. So, let's create our sample.go file:
package main
import (
"fmt"
"github.com/apache/arrow/go/v7/arrow/cdata"
)
func processBatch(scptr, rbptr uintptr) {
schema := cdata.SchemaFromPtr(scptr)
arr := cdata.ArrayFromPtr(rbptr)
rec, err := cdata.ImportCRecordBatch(arr, schema)
if err != nil {
panic(err) // handle the error!
}
// make sure we call the release callback when we're done
defer rec.Release()
fmt.Println(rec.Schema())
fmt.Println(rec.NumCols(), rec.NumRows())
}
Note the highlighted lines. The function signature takes in two uintptr values, the pointers to our structs. We then use the cdata package in the Arrow module to import our record batch.
Remember
"But wait!" you say. "There was no format string for record batches in the C Data API." You're correct! A record batch is simply represented as a struct array whose fields match the columns of the record batch. Importing a record batch involves just flattening the struct array out into a record batch.
- Now that we have our function to export we just need to… well, export it!
package main
import (
"fmt"
"github.com/apache/arrow/go/v7/arrow/cdata"
)
import "C"
//export processBatch
func processBatch(scptr, rbptr uintptr) {
...
}
func main() {}
The highlighted lines are the additions that need to be made to export the function. The import "C" line tells the Go compiler to use the Cgo command, which will recognize the export comment. There must be no space between the double-slash and the word export, and it must be followed by the function name exactly. You'll get a compiler error if it doesn't match. Finally, the addition of the main function is necessary for the C runtime connection with Go's runtime.
Setting the buildmode argument to c-shared tells the compiler that we're creating a dynamic library. On Windows, you'd change libsample.so to be libsample.dll instead, but otherwise, everything is the same. Building the library will also create a new file, libsample.h – a header file for C or C++ programs to include for calling the exported function.
We can use the cffi Python module as we did earlier when calling our C++ dynamic library to call the function, but we're going to take a different approach in this example, just to show some variety and other options that are available to you.
Creating a Python extension from the Go library
We're going to create what's called a Python C extension using the cffi module. Before we start, make sure you have the same abi.h file that we copied from the Arrow GitHub repository earlier – when compiling the C++ dynamic library – in the same directory as the libsample.h and libsample.so files that we created when building the shared library:
- We first create a build script that will compile our extension using the cffi module. Let's call this sample_build.py:
import os
from pyarrow.cffi import ffi
ffi.set_source("_sample",
r"""
#include "abi.h"
#include "libsample.h"
""",
library_dirs=[os.getcwd()],
libraries=["sample"],
extra_link_args=[f"-Wl,-rpath={os.getcwd()}"])
ffi.cdef("""
void processBatch(uintptr_t, uintptr_t);
""")
if __name__ == "__main__":
ffi.compile(verbose=True)
The call to the cdef function should look very familiar to you, as it's precisely what we did before when we were loading the C++ shared library we built earlier, only now it matches the signature of the processBatch function we exported.
Looking at the highlighted lines, we can see the header includes both the C API abi.h header file and the generated header file from our build. Then, we specify the directory that our library is in and its name; note the lack of the lib prefix, which is handled automatically. The extra link argument that we pass containing the rpath specification is to make it easier at runtime. The argument for the linker informs the system of the directory to look in for dependent libraries at runtime – in our case, telling it where the libsample.so is so that it can be loaded when the extension is called.
- Now, we build the extension by calling our build script!
$ python3 example_go_cffi.py
generating ./_sample.c
the current directory is '/home/matt/chapter5/go'
running build_ext
building '_sample' extension
x86_64-linux-gnu-gcc -pthread -Wno-unused-result ...x86_64-linux-gnu-gcc -pthread -shared -Wl,-O1 ... ./_sample.o -L/home/matt/chapter5/go -lsample -o ./_sample.cpython-39-x86_64-linux-gnu.so -Wl,-rpath=/home/matt/chapter5/go
This will produce a file named _sample.cpython-39-x86_64-linux-gnu.so if you're using Python 3.9 on a Linux machine. The filename will adjust based on your version of Python and the operating system that you're building on. This extension can now be imported and used by Python, so let's give it a try!
- Start a Python interpreter in the same directory you built the extension in so that we can import it:
>>> from _sample import ffi, lib
Note that there are two things we're importing from the extension, the ffi module and the library itself.
- We'll test out the extension by using the same Parquet file from previous examples, yellow_tripdata_2015-01.parquet. Use the to_batches function to create record batches from the table:
>>> import pyarrow.parquet as pq
>>> tbl = pq.read_table('<path to file>/yellow_tripdata_2015-01.parquet')
>>> batches = tbl.to_batches(None)
Because the default reading of Parquet files will be multi-threaded, the table is read in multiple chunks. This then results in multiple record batches being created when calling to_batches. On my machine, I got a list of 13 record batches; we'll just use one of the batches for this example.
- As before, we use ffi to create our ArrowSchema and ArrowArray objects and pointers and then cast them to be uintptr_t:
>>> c_schema = ffi.new('struct ArrowSchema*')
>>> c_array = ffi.new('struct ArrowArray*')
>>> ptr_schema = int(ffi.cast('uintptr_t', c_schema))
>>> ptr_array = int(ffi.cast('uintptr_t', c_array))
- Then, we export the record batch and call our shared function:
>>> batches[0].schema._export_to_c(ptr_schema)
>>> batches[0]._export_to_c(ptr_array)
>>> lib.processBatch(ptr_schema, ptr_array)
When we wrote our Go shared library, the function ended by printing out the schema, the number of columns, and the number of rows of the record batch. Following the execution of the highlighted line, you should see all of these get printed out on your terminal. The line denoting the columns and rows should follow the schema:
19 1048576
It might seem a bit unwieldy to call this repeatedly if you have many batches you want to pass. Perhaps it's even inefficient to pass the schema multiple times too. There's a need to be able to stream record batches through this API because, frequently, you're going to be dealing with streams of data, such as if you're working with Spark. This is why there's one more structure that exists in the header file for the C Data API, ArrowArrayStream.
Streaming across the C Data API
This particularly useful interface is considered experimental by the Arrow project currently, so technically, the ABI is not guaranteed to be stable but is unlikely to change unless user feedback proposes improvements to it. The C streaming API is a higher-level abstraction built on the initial ArrowSchema and ArrowArray structures to make it easier to stream data within a process across API boundaries. The design of the stream is to expose a chunk-pulling API that pulls blocks of data from the source one at a time, all with the same schema. The structure is defined as follows:
struct ArrowArrayStream {// callbacks for stream functionality
int (*get_schema)(struct ArrowArrayStream*, struct ArrowSchema*);
int (*get_next)(struct ArrowArrayStream*, struct ArrowArray*);
const char* (*get_last_error)(struct ArrowArrayStream*);
// Release callback and private data
void (*release)(struct ArrowArrayStream*);
void* private_data;
};
The release callback and private_data member should be familiar to you by now, but the remaining members are as follows:
- int (*get_schema)(struct ArrowArrayStream*, struct ArrowSchema*) (required):
- The callback function to retrieve the schema of the chunks of data. All chunks must have the same schema. This cannot be called after the object has been released. It must return 0 on success and a non-zero error code on failure.
- int (*get_next)(struct ArrowArrayStream*, struct ArrowArray*) (required):
- The callback function to return the next chunk of data from the stream. This cannot be called after the object has been released and must return 0 on success and a non-zero error code on failure. On success, consumers should check whether the stream has been released. If so, the stream has ended; otherwise, the ArrowArray data should be valid.
- const char* (*get_last_error)(struct ArrowArrayStream*) (required):
- The callback function that may only be called if the last called function returned an error and cannot be called on a released stream. It returns a null-terminated UTF-8 string that is valid until the next call of a callback on the stream.
The lifetime of the schema and data chunks that are populated from the callback functions is not tied to the lifetime of the ArrowArrayStream object at all and must be cleaned up and released independently to avoid memory leaks. The non-zero error codes for failures should be interpreted just like you would interpret the errno values for your platform.
Streaming record batches from Python to Go
Now, we can update our previous example to stream the record batches from the Parquet file to the shared library. Again, this is a trivial case, given that we can just as easily read the Parquet file natively in Go, but the concept is what is important here. Reading the Parquet file in Python can just as easily be something that is receiving pandas DataFrames and then converting them to Arrow record batches and sending them:
- First, we modify our Go file, adding a new function that accepts a single pointer for an ArrowArrayStream object and loops over our stream of batches. The difficult stuff has already been handled by the Arrow library when importing the Stream object:
- As before, we need to have the highlighted comment line to have Go export the function with a C-compatible interface:
//export processStream
func processStream(ptr uintptr) {
- Then, we can initialize the variables we're going to need in a var block:
var (
arrstream = (*cdata.CArrowArrayStream)(unsafe.Pointer(ptr))
rec arrow.Record
err error
x int
)
- Now, we can create a stream reader object, passing nil for the schema argument so that it knows to pull the schema from the stream object itself, rather than us providing it.
rdr := cdata.ImportCArrayStream(arrstream, nil)
- Finally, we use a loop, calling the Read method of the reader until we get a non-nil error. When we hit the end of the stream, it should return io.EOF; any other error means we encountered a problem:
for {
rec, err = rdr.Read()
if err != nil {
break
}
fmt.Println("Batch: ",x, rec.NumCols(), rec.NumRows())
rec.Release()
x++
}
if err != io.EOF {
panic(err) // handle the error!
}
} // end of the function
- Build the library as before with the Cgo command and the buildmode option. Don't forget import "C"; otherwise, it won't generate the header file!
$ go build -buildmode=c-shared -o libsample_stream.so .
- Modify the Python extension build script to use the new library and new function; you can even have both functions in the same library if you didn't remove the processBatch function. If you don't update the build script, the new processStream function won't be available to call from Python:
import os
from pyarrow.cffi import ffi
ffi.set_source("_sample_stream",
r"""
#include "abi.h"
#include "libsample_stream.h"
""",
library_dirs=[os.getcwd()],
libraries=["sample_stream"],
extra_link_args=[f"-Wl,-rpath={os.getcwd()}"])
ffi.cdef("""
void processBatch(uintptr_t, uintptr_t);
void processStream(uintptr_t);
""")
if __name__ == "__main__":
ffi.compile(verbose=True)
Then, run this to build the new _sample_stream extension as we did before.
- Finally, let's open the Parquet file and then call our function to stream the data:
from _sample_stream import ffi, lib
import pyarrow as pa
import pyarrow.parquet as pq
f = pq.ParquetFile('yellow_tripdata_2015-01.parquet')
batches = f.iter_batches(1048756)
rdr = pa.ipc.RecordBatchReader.from_batches(
f.schema_arrow, batches)
c_stream = ffi.new('struct ArrowArrayStream*')
ptr_stream = int(ffi.cast('uintptr_t', c_stream))
rdr._export_to_c(ptr_stream)
del rdr, batches
lib.processStream(ptr_stream)
If you run this script, you should get the following output from it, calling the shared library that we built with Go:
Batch: 0 19 1048756
Batch: 1 19 1048756
Batch: 2 19 1048756
Batch: 3 19 1048756
Batch: 4 19 1048756
Batch: 5 19 1048756
Batch: 6 19 1048756
Batch: 7 19 1048756
Batch: 8 19 1048756
Batch: 9 19 1048756
Batch: 10 19 1048756
Batch: 11 19 1048756
Batch: 12 19 163914
Look at that – not only did you create some fancy dynamic extensions to pass Arrow data around but you are also passing it through different programming languages! Pretty neat, right? The next time you're trying to interface different technologies in different languages, think back to this and see where else you can apply these techniques.
Other use cases
In addition to providing an interface for zero-copy sharing of Arrow data between components, the C Data API can also be used in cases where it may not be feasible to depend on the Arrow libraries directly.
Despite a large number of languages and runtimes sporting implementations of Arrow, there are still languages or environments that do not have Arrow implementations. This is particularly true in organizations with a lot of legacy software and/or specialized environments. A great example of this would be the fact that the dominant programming language in the astrophysical modeling of stars and galaxies is still Fortran! Unsurprisingly, there is not an existing Arrow implementation for Fortran. In these situations, it is often not feasible to rewrite entire code bases so that you can leverage Arrow in a supported language. But with the C Data API, data can be shared from a supported runtime to a pre-existing unsupported code base. Alternatively, you can do the reverse and easily build out the C data structures to pass data into a component that expects Arrow data.
There are potentially many other cases where tight integration and direct dependency on the Arrow libraries might not be desirable. A few of these might be the following:
- Heavily resource-constrained environments such as embedded software development. A minimal build of the Arrow core library clocked in at ~15 MB on my system, despite the available modularization. This might not seem like much, but for embedded development, even this might be too large.
- The Arrow library is very fast-moving and frequently updated. Some projects might not be able to depend on a fast-moving project such as Arrow and ensure that they stay current and updated.
- Development might be in an environment where users cannot manually install external libraries such as Arrow due to permissions or other restrictions.
The existence of the C Data API allows consuming applications and libraries to work with Arrow memory without having to directly depend on the Arrow libraries or build their own integration. They can choose between tightly coupling with the Arrow project or just the Arrow format.
Some exercises
Before moving on, see whether you can come up with any other use cases that use the C Data API to communicate between languages or runtimes in a single process, and sketch out simple implementations or rough outlines to set it up. You can either use the Arrow libraries to import/export data or build some adapter from one data format into the C structure to return data in the Arrow format easily.
Consider this – you have a database engine and you want to add an option to deliver results as Arrow-formatted data, but you don't want to impose a new dependency on the project by relying directly on the Arrow libraries. How can you provide this without linking against the Arrow libraries and including the Arrow C++ headers? What would the API look like?
Maybe try reversing the direction of some of our import/export examples to pass data to Python, C++, or some other combination of technologies, languages, or runtimes. Be creative!
Of course, I've mentioned many times already how Arrow provides high-speed analytical capabilities, but so far, we've focused mostly on just fetching data and moving it around. But you aren't left to your own devices when it comes to actually performing computations on your Arrow data. The Arrow libraries provide a Compute API that can be used to build out complex queries and computation engines.
Summary
For this foray into the Arrow libraries, we've explored the efficient sharing of data between libraries using the Arrow C data interface. Remember that the motivation for this interface was for zero-copy data sharing between components of the same running process. It's not intended for the C Data API itself to mimic the features available in higher-level languages such as C++ or Python – just to share data. In addition, if you're sharing between different processes or need persistent storage, you should be using the Arrow IPC format that we covered in Chapter 4, Format and Memory Handling.
At this point, we've covered lots of ways to read, write, and transfer Arrow data. But once you have the data in memory, you're going to want to perform operations on it and take advantage of the benefits of in-memory analytics. Rather than having to re-implement the mathematical and relational algorithms yourself, in Chapter 6, Leveraging the Arrow Compute APIs, we're going to cover… well, the compute library! The Arrow libraries include a Compute API that has a significant number of common mathematical operations (sum, mean, median, and so on), along with relational operations (such as joins and sorting) already implemented for you to easily use.
So, let's get cracking!