
Chapter 9: Powered by Apache Arrow
Apache Arrow is becoming the industry standard as more and more projects adopt and/or support it for their internal and external communication formats. In this chapter, we're going to take a look at a few projects that are using Arrow in different ways. With the flexibility that Arrow provides, it is able to serve a variety of use cases in different environments, and many developers are taking advantage of that. Of course, Arrow is used in many different analytical engine projects, but it is also used in other contexts ranging from machine learning (ML) to data visualization in the browser.
With new projects and uses popping up all the time, it only makes sense to give a small overview of a selection of some of those projects. In this chapter, you're going to see a couple of different use cases for how Arrow is being used in the wild. These include the following:
- A distributed SQL query engine named Dremio Sonar, which we just used to demonstrate Arrow Flight in Chapter 8, Exploring Apache Arrow Flight RPC
- Building applications that rely on Artificial Intelligence (AI) and ML techniques with Spice AI
- Several projects using the Arrow JavaScript library to perform super-fast computations right inside the browser
Swimming in data with Dremio Sonar
The roots of Arrow can be found in the ValueVector objects from the Apache Drill project, a SQL query engine for Hadoop, NoSQL, and cloud storage. Dremio Sonar was originally built out of Apache Drill and Dremio's founders co-created Arrow. Arrow is used by Dremio Sonar as the internal memory representation for its query and calculation engine, which helps power its performance. Since its inception, Dremio's engineers have made many contributions to the Arrow project resulting in significant innovations. First, let's look at the architecture used and where Arrow fits in.
Clarifying Dremio Sonar's architecture
As a distributed query engine, Dremio Sonar can be deployed in many different environments and scenarios. However, at its core, it has a pretty simple architecture, as shown in Figure 9.1. Being distributed, it can scale horizontally by increasing the number of Coordinators and Executors that handle the planning and execution of queries, respectively. Cluster coordination is handled by an Apache ZooKeeper cluster that is communicated with by both the Coordinator node and all the Executor nodes. While the metadata storage used by the Coordinator node(s) can be local to it, the executors need to all share a distributed storage mechanism. The Executor nodes need to share a Distributed Storage location so that we can ensure the raw data, configuration data, and cached data is in sync:
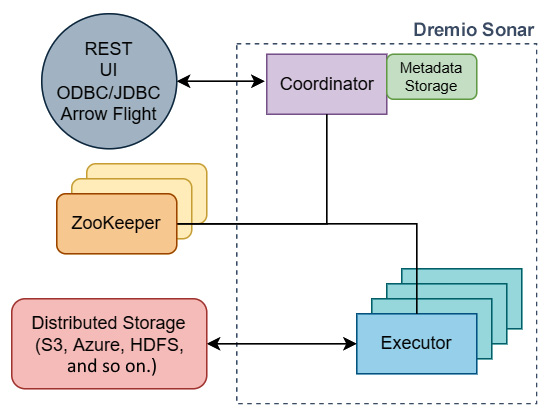
Figure 9.1 – The basic Dremio Sonar cluster architecture
So, I mentioned that Dremio Sonar uses Arrow as its internal memory representation of data for computation. Since Dremio Sonar can connect to various sources of data, this means that any raw data has to be converted into the Arrow format after it has been retrieved from its physical storage location. If your raw data simply consists of Parquet files in a distributed storage service such as S3, this can be very easy and performant because Parquet has a fast conversion to and from Arrow. But if your raw data is stored in, say, a PostgreSQL database connected with ODBC, that conversion can potentially be slower due to PostgreSQL and ODBC often becoming bottlenecks for transferring large amounts of data.
At a certain point, even the fastest execution engine cannot provide sub-second response times when hitting the limits of physics when dealing with very large datasets. To combat that, Dremio Sonar uses a technique it calls reflections. A reflection is a hybrid between a materialized view and an index which is stored as simply a collection of Parquet files. Each reflection may be partitioned and/or sorted in order to minimize the number of files that need to be read to service a query. That said, when aiming to achieve super-fast query times, even converting this data from Parquet to Arrow while highly optimized, can still take time for a lot of data. To address those situations, Dremio Sonar provides the option to store the data of a reflection in raw Arrow IPC format, allowing the cached Arrow data to be pulled directly into memory without any conversion required. All of this translates into super-fast query executions and computations.
With Dremio's usage of Arrow and involvement in the community, its engineers have contributed significantly to the libraries. They were involved in the creation and development of Arrow Flight, with Dremio being the first system with an Arrow Flight connector (which showed a 20x–50x improvement over their ODBC/JDBC connectors). They were also heavily involved in the development of Arrow Flight SQL, being part of the contributors that provided the initial official implementations of it. However, one significant contribution Dremio has made that we haven't already covered in this book is the Gandiva Initiative. This is an execution kernel for Arrow that provides enormous performance improvements for low-level operations on Arrow's data buffers. Initially developed to improve the performance of analytical workloads being serviced by Dremio Sonar, the Gandiva library was donated to the Arrow Project in 2018.
The library of the Gods…of data analysis
Gandiva is a mythical, divine bow from the Hindu epic story, the Mahābhārata. In the story, Gandiva is indestructible, and any arrow that is fired from it becomes 1,000 times more powerful. Given the performance benefits of the Arrow-based execution that this library provides, it seems to be an extremely fitting name.
Like many big data query engines, Dremio Sonar is implemented using Java. Before the development of Gandiva, the execution of a SQL query by Dremio Sonar involved dynamically compiling that query into an efficient byte code format that could be executed by the Java Virtual Machine (JVM). Dynamically compiling queries into a byte code representation provides significant performance benefits over simply interpreting and evaluating a SQL expression; however, Gandiva takes this approach just one step further. By leveraging the capabilities of the LLVM compiler, many low-level in-memory operations on Arrow data, such as sorting or filtering, can have highly optimized assembly code generated on the fly. This results in better resource utilization and faster operations.
What Is LLVM?
LLVM is an open source project that provides a set of compiler and toolchain utilities; it was originally developed around 2000. In addition to providing many utilities for being a general-purpose compiler for a multitude of programming languages, it also provides libraries for performing Just-In-Time compilation. As opposed to compiling source code to machine code before execution, just-in-time compilation occurs at runtime, allowing a program to dynamically translate operations into machine code and then execute that code. This provides extra flexibility, while still being able to leverage the execution performance of highly optimized, compiled code. This capability is what Gandiva is leveraging!
To ensure the fastest possible execution, Gandiva is a C++ library, and it provides Java APIs utilizing the Java Native Interface bridge to talk to the C++ code. Since Dremio Sonar is written in Java, it then leverages those APIs for generating code and evaluating expressions. Figure 9.2 shows a high-level representation of how the Gandiva library is utilized:
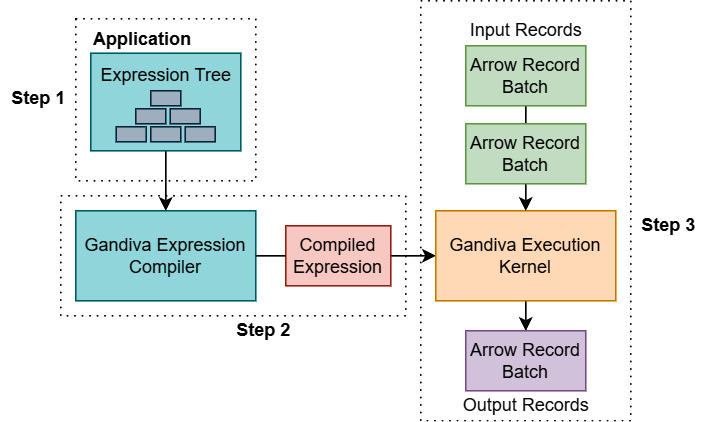
Figure 9.2 – Using the Gandiva library
The basic steps for using Gandiva are labeled and listed as follows:
- Step 1: First, the application creates an expression tree to represent the operation that it desires to compute. Gandiva supports filter and projection operations along with a wide variety of mathematic, Boolean, and string manipulation operations.
- Step 2: The expression tree is passed to the Gandiva Expression Compiler, which returns an object containing a reference to the compiled module. The compilation step also utilizes caches of precompiled expressions to ensure it is fast.
- Step 3: The compiled expression can then be passed to the Gandiva Execution Kernel and given a stream of Arrow record batches as input for it to operate on, returning Arrow record batches as output.
At the time of writing, in addition to the C++ API and Java bindings, there are also Python bindings for the Gandiva library. Hopefully, as time goes on, the community will continue to build bindings for using the Gandiva library with other languages, including Ruby, Go, and more. The continued adoption of Gandiva builds on Arrow's adoption, making processing data in Arrow format ever more efficient. Utilizing and embedding Gandiva prevents the need for applications to have to reinvent the wheel and implement this work on their own.
In addition to the analytics pipelines and SQL evaluations, there are other use cases where using Arrow can provide significant benefits. The next use case we're going to talk about is how to utilize Arrow as an in-memory data representation for sequence alignment/map objects for genomics data processing.
Spicing up your ML workflows
Among the various fields of engineering that work with very large sets of data, one field that deals with processing some of the largest datasets would be ML and AI workflows. However, if your full-time job isn't ML, and you don't have the support of a dedicated ML team, it can often be very difficult to create an application that can learn and adapt. This is where a group of engineers decided to step in and make it easier for developers to create intelligent and adapting applications. Spice AI (https://spiceai.io) is, at the time of writing, a venture-capital-funded start-up that is working to create a platform to make it easier for developers to create AI-driven applications that can adapt and learn. They've open-sourced a product on GitHub called Spice.ai (https://github.com/spiceai/spiceai). It is currently in alpha development and utilizes Apache Arrow, Arrow Flight, as well as Dremio Sonar for its data processing and transport (https://blog.spice.ai/announcing-spice-xyz-94323159cd2b).
Generally, a traditional approach to integrating AI/ML into an application uses a completely separate service from the application. A dedicated team or pipeline, usually data scientists, acquires data from somewhere and trains a model on it. After a significant amount of time in a cycle of training the model on data, tweaking it based on the results, and then training it again, this model is deployed as a service. The application then interacts with that service to get answers or insights based on the model. In comparison, Spice.ai allows developers to incorporate the AI engine into the application directly instead of as a separate piece of infrastructure, as shown in Figure 9.3:
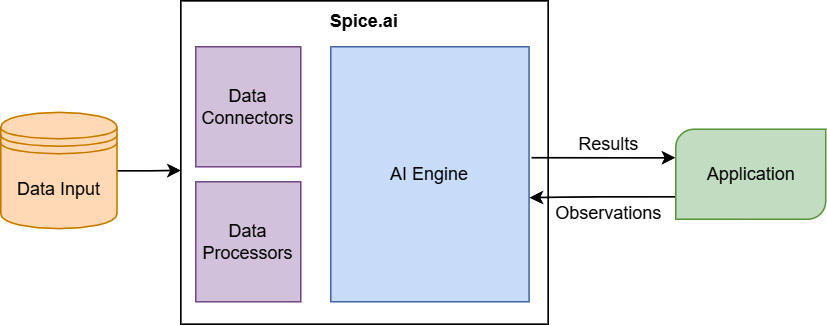
Figure 9.3 – The Spice.ai integration with an application
For the various levels of communication between data sources and data connectors/processors and those processors and the AI engine, Arrow is used for efficiency. Switching to using Arrow and Flight for communication and processing enabled Spice.ai to scale to datasets that were 10x–100x larger than it was previously able to. Also, it improved transport time for large datasets, just as we saw in Chapter 8, Exploring Apache Arrow Flight RPC. Integrating with Arrow also enabled them to connect with data sources such as InfluxDB, Snowflake, and Google BigQuery as input for the AI/ML engine. Essentially, they can integrate with anything that provides an Arrow Flight endpoint or an Arrow IPC record batch stream.
Bringing the AI engine to where the data lives
With any time-sensitive data, the best route for performance is to always bring your computation to where your data is. This is the premise behind Spice.ai's decision to provide a portable container runtime. Making it deployable using simple HTTP APIs allows it to be deployed alongside any application regardless of whether it is on-premises, part of a public cloud, or deployed on an edge device such as a cell phone. They are also keen into building a community by including a library of community-driven, reusable components for the Spice.ai runtime.
The next step for Spice AI is that they are targeting data scientists with blockchain and smart-contract data with the release of Spice.xyz (https://spice.xyz). Using an Arrow Flight API, Spice.xyz provides a SQL interface to a high-performance pipeline of blockchain data such as Ethereum gas fees or Non-Fungible Token (NFT) trading activity. By building on top of Arrow and Arrow Flight, they've created a unified and efficient platform across AI workflows and the data needed to train the ML models.
Now, let's take a more visual approach. Historically, trying to provide faster and more efficient processing of data inside web browsers has been extremely difficult to do. This tends to be the case due to the limitations of JavaScript, the primary language used for interactive websites. Being an interpreted language, with significant limitations on memory usage (for the user's protection), JavaScript is not exactly ideal for processing data. This sort of processing is critical for being able to create ways to easily interact with data. As a result, many projects have popped up to utilize Arrow in browsers to power these kinds of use cases, which we will discuss in the following section.
Arrow in the browser using JavaScript
One of the most common ways to currently deploy an application to consumers is by developing a web application. You can provide an application intended for mobile phones, tablets, or laptop/desktop browsers all in one location. When it comes to building modern interactive applications on the web, you can be sure that JavaScript and/or TypeScript are going to be involved somewhere. Now that we've covered some examples of services and systems utilizing Arrow, we'll cover a couple of projects that are leveraging Arrow front-and-center right in the browser.
Gaining a little perspective
In Chapter 3, Data Science with Apache Arrow, we briefly touched on a library named Perspective in the context of a widget for Jupyter notebooks. Perspective was originally developed at J.P. Morgan and was then open-sourced under the Apache Open Source License 2.0 through the Fintech Open Source Foundation (FINOS). Perspective is written in C++ and compiled for both WebAssembly and Python, with JavaScript components provided to wrap around the WebAssembly module. Two main modules are exported by the Perspective library: a data engine library and a user-configurable web component for visualization (which depends on the data engine).
Look It Up!
The home page for Perspective is https://perspective.finos.org. Here, you can find the documentation and a link to the GitHub repository. Additionally, it contains a variety of images and views showing what can be done with it.
In the browser, the Perspective engine runs as a web worker that runs as a separate process. When using Node.js, the engine runs in-process by default rather than as a separate process. In both cases, a promise-based interface is exported (async/await can be used with ES6). If the data is read-only, static, or provided by the user, then near-native performance can be achieved with the JavaScript client-only library running WebAssembly and a web worker for parallel rendering. The only drawback is that it requires the entire dataset to be downloaded to the client. Perspective is able to understand data in Arrow format, as raw CSV data, or as JSON (row-oriented objects) data.
When dealing with larger, real-time, or synchronized data being accessible by multiple users concurrently, one alternative is a client/server model. Servers are provided for either Node.js or Python, allowing JavaScript clients to replicate and synchronize the server-side data. By leveraging Arrow, data is able to be passed around extremely efficiently between the server and the client, while still allowing the browser's UI to render a variety of chart types ranging from simple bar charts to complex heatmaps or scatter plots. The rendering in the browser will dynamically and interactively update views as data, and updates are streamed from the server.
If you're ever working on an application that will be drawing visualizations of datasets, I highly recommend seeing whether you can leverage the perspective library and/or its components! For instance, this was done by the Visual Studio Code extension, Data Preview (https://marketplace.visualstudio.com/items?itemName=RandomFractalsInc.vscode-data-preview). This extension for the Visual Studio Code IDE utilizes the Perspective library to provide tools for importing, viewing, slicing, and charting a wide selection of objects or files and data formats, just as we saw previously with the Jupyter widget. What might you be able to build with it?
If Perspective isn't quite your speed, how about trying a different module called Falcon?
Taking flight with Falcon
Similar to Perspective, Falcon is a library for the interactive visual analysis of data in the browser. The module itself can be found at https://github.com/vega/falcon with a series of demos hosted to display its capabilities. What sets Falcon apart is its swappable engine to go along with the multitude of widgets and components it offers for cross-filtering between records.
For smaller datasets of up to 10 million rows, it has an engine built entirely on Arrow that operates completely in the browser. Alternately, even greater performance can be achieved using DuckDB's WebAssembly SQL database (https://github.com/duckdb/duckdb-wasm) for browsers (which is also built on top of Arrow!) as Falcon's query engine. Lastly, Falcon also can connect to the Heavy.AI (formula OmniSci) database to use as an engine (https://www.heavy.ai/product/heavyidb). And before you ask…yes, Heavy.AI also supports Arrow for data ingestion and uses libraries provided by Arrow to utilize GPUs for computation.
Remember, this chapter is just supplying brief snippets of information about projects that I think are utilizing Arrow in interesting ways. Go check some of them out if they catch your fancy!
Summary
It doesn't matter what the shape or form of your data is, if you're going to be doing any sort of processing or manipulation of the data, then it pays to see whether Arrow can enhance your workflows. In this chapter, we've seen relational databases, analytical engines, and visualization libraries all powered by Apache Arrow. In each case, Arrow was being leveraged for a smaller memory footprint and generally better resource utilization than what had previously been done.
Every industry has a need for processing large amounts of data extremely quickly, from brand new scientific research to manufacturing metrics. If you are doing work with data processing, you can probably leverage Arrow somewhere in your pipeline. If you don't believe me, have a gander at the projects listed on the official Apache Arrow website as powered by Arrow: https://arrow.apache.org/powered_by/. You'll find every project mentioned in this chapter on that list, along with many other interesting ones. I'm sure you'll be able to find something that's at least tangentially related to your particular use case; at a minimum, you'll pique your curiosity.
If you can't find something that already exists to leverage, maybe you'll build something and contribute to the Arrow project instead! That's the topic of our next chapter: How to Leave Your Mark on Arrow. Arrow has become what it is by nurturing a community and drawing people to it. Like any other open source project, it needs developers to contribute to it in order to grow. Maybe there's a feature you want or need that I haven't mentioned yet. Maybe there is a use case that no one has considered yet. If, like me, you enjoy diving into the meat of a library and building something that many others can use, then come contribute to the Arrow libraries. The next chapter will help you to get started!