
Chapter 11: Future Development and Plans
There is quite a lot of development still going on in the Arrow libraries and utilities. Aside from updating and improving the libraries as they currently stand, multiple efforts are operating simultaneously to build community tools utilizing Apache Arrow. Sometimes, this results in new protocols and technologies; other times, it results in entirely new libraries and software. Given the size of the developer community surrounding Arrow, it's no surprise that there's plenty of development with new things in the works.
This chapter's goal is to get you excited about the development plans and projects that are in the works as of the time of writing. Hopefully, the following will intrigue you:
- Flight SQL is still under heavy development, so we're going to cover it a bit more in-depth, and the future plans such as a generic ODBC driver.
- An extensible and distributed query execution framework called DataFusion and its associated distributed compute engine named Ballista.
- Arrow Compute Intermediate Representation (IR) and the related Substrait project.
So, without further ado, let's dive in. With any luck, by the time you are reading this book, some of these ideas will be closer to production already!
Examining Flight SQL (redux)
Way back in Chapter 8, Exploring Apache Arrow Flight RPC, we briefly touched on the topic of Arrow Flight SQL and why it was important. Very briefly. Flight SQL is still very new, and while the protocol has stabilized (for the most part), it's very much under development and there are only C++ and Java reference implementations so far. So, first, let's quickly cover the motivations for Flight SQL's development and what it is and isn't.
Why Flight SQL?
We first mentioned the Java Database Connectivity (JDBC) and Open Database Connectivity (ODBC) standards in Chapter 3, Data Science with Apache Arrow. While they have done well for decades, the standards simply don't handle columnar databases well at all. Both of these standards define APIs that are row-based. If the connected database uses a columnar representation of the data, using ODBC/JDBC will require transposing the data not once, but twice! Once for the database to provide row-oriented data to the ODBC/JDBC API for its driver, then a second time for the consumer to get it back into columns. This is depicted in Figure 11.1, showing the difference between a dedicated column-oriented API such as Arrow Flight, and row-oriented APIs such as ODBC/JDBC:
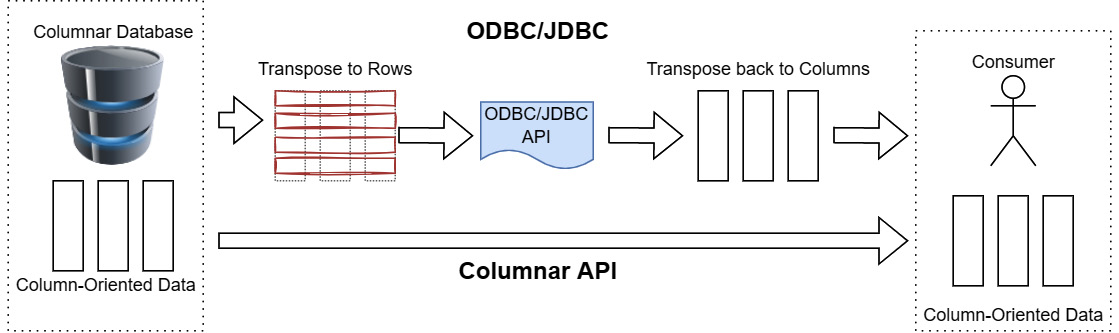
Figure 11.1 – Columnar API versus ODBC/JDBC API
Even when an ODBC API provides bulk access directly to the result buffers, the data still needs to be copied into Arrow arrays for use with any libraries or utilities that expect Arrow-formatted data. The goal of Flight SQL is to remove these intermediate steps and make it easier for database developers to develop a single standard interface designed around Apache Arrow and column-oriented data. Currently, any new database would need to design its own (or use an existing) wire protocol for communication between the database and the ODBC driver. For a database, Figure 11.2 shows how Flight SQL could simplify things:
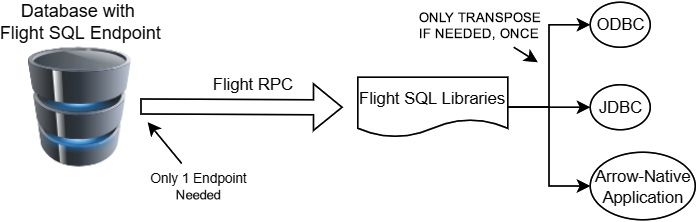
Figure 11.2 – Database with Flight SQL
Databases could use Flight directly, which already implements features such as encryption and authentication, without having to re-implement any of these features. Additionally, this would enable databases to easily benefit from the other features of Flight, such as the parallelization and horizontal scaling. While Flight defines operations such as DoGet and DoPut, it leaves the exact form of the commands used up to the application developer. Flight SQL takes this further and fully defines a SQL interface over the Flight wire protocol, complete with enumeration values, metadata structures, and operations. If you're building a database server, using Flight SQL gives you all the benefits of Arrow Flight, while still having a strongly defined universal interface to code against for you and your consumers.
Revisiting our comparison with ODBC, an important thing to note is that Flight SQL provides a unified driver and protocol, while ODBC only provides a unified API. The difference to highlight here is emphasized in Figure 11.3:
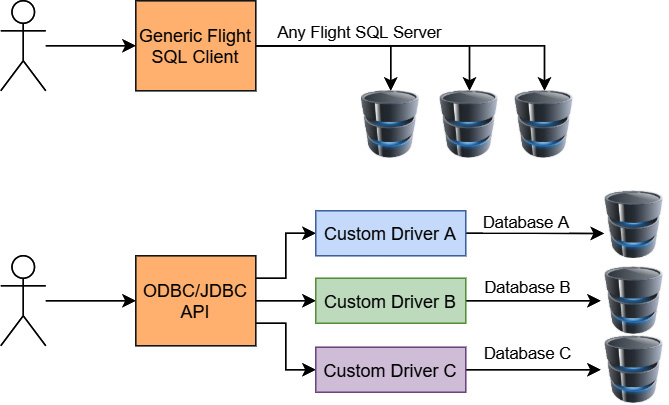
Figure 11.3 – Flight SQL versus ODBC/JDBC drivers
Using the generic Flight SQL client libraries allows you to connect to any server that uses Flight SQL. There's no additional work needed by a user or database vendor; just connect to the Flight SQL server and you're good to go. On the contrary, as Figure 11.3 shows, ODBC may provide a generic API to write code against, but it requires a custom driver for a given database. Supporting multiple databases requires multiple, different drivers. To support ODBC/JDBC, database vendors have to create and distribute the specific drivers that facilitate connecting to their database. This difference in development burden is what's being referred to by saying that ODBC only provides a unified API while Flight SQL lifts the burden because it is a combined driver and protocol.
So, how does Flight SQL extend the regular Flight protocol?
Defining the Flight SQL protocol
The Flight SQL protocol defines new request and response message types using Protobuf to be used on top of the existing Arrow Flight RPC messages. While we'll briefly go over the new message types, we're not going to cover them as in-depth as we did for Flight. If you want to see the full definitions of the Flight SQL messages, you can look at the .proto file in the Arrow repository at https://github.com/apache/arrow/blob/release-7.0.0/format/FlightSql.proto.
The vast majority of requests for Flight SQL utilize this pattern:
- The client uses one of the pre-defined Protobuf messages to construct a request.
- The client sends the request using either the GetSchema method (to query what the schema of the response would be) or the GetFlightInfo method (to execute the request).
- The client uses the endpoints returned from GetFlightInfo to request the response(s).
All the usual suspects appear as predefined messages in Flight SQL's protocol:
- Requesting metadata: The various message types for requesting metadata about the SQL database itself, including the available tables, keys, and SQL information:
- CommandGetCatalogs – Get a list of catalogs from the database.
- CommandGetCrossReference – Get a list of foreign key columns in one table referencing a specific table.
- CommandGetDbSchemas – Get a list of schemas in a catalog.
- CommandGetExportedKeys – Get a list of foreign keys referencing a table.
- CommandGetImportedKeys – Get a list of foreign keys in a table.
- CommandGetPrimaryKeys – Get a list of primary keys from a table.
- CommandGetSqlInfo – Get database information and the dialect of SQL it supports.
- CommandGetTables – Get a list of tables in a catalog/schema.
- CommandGetTableTypes – Get a list of table types that are supported by the database, such as views and system tables.
- Querying data: The Protobuf messages for performing queries and creating prepared statements:
- CommandStatementQuery – Execute a SQL query.
- CommandStatementUpdate – Execute a SQL update query.
- Manipulating prepared statements:
- ActionCreatePreparedStatementRequest – Create a new prepared statement.
- ActionClosePreparedStatementRequest – Close a prepared statement handle.
- CommandPreparedStatementQuery – Execute a prepared statement with the provided bound parameter values.
- CommandPreparedStatementUpdateQuery – Execute a prepared statement that updates data with provided bound parameter values.
To utilize these message types, you simply serialize them to bytes and send them in the body of a FlightDescriptor or DoAction request to the Flight SQL server. In the Arrow GitHub repository, you can find the following examples:
- A C++ Flight SQL server implementation that wraps a SQLite instance: https://github.com/apache/arrow/blob/release-7.0.0/cpp/src/arrow/flight/sql/example/sqlite_server.h
- A Java Flight SQL server implementation that uses JDBC internally to bridge a connection to Apache Derby: https://github.com/apache/arrow/blob/release-7.0.0/java/flight/flight-sql/src/test/java/org/apache/arrow/flight/sql/example/FlightSqlExample.java
- A simple Flight SQL CLI client implementation: https://github.com/apache/arrow/blob/release-7.0.0/cpp/src/arrow/flight/sql/test_app_cli.cc
It's expected that there will be more refinements and extensions to this protocol as development continues and more individuals get involved, either as contributors or adopters of Flight SQL. Currently, the only engine I'm aware of that supports Flight SQL is Dremio Sonar. This makes sense given that engineers from Dremio were heavily involved in both the creation of Flight and Flight SQL in the first place! Other expected future improvements are Python bindings, Go bindings, and a generic ODBC/JDBC driver that communicates via Flight SQL. If this has piqued your interest and you want to get involved, reach out on the Arrow mailing lists or directly on the Arrow GitHub repository!
Up next, Arrow DataFusion and Ballista!
Firing a Ballista using Data(Fusion)
Started as a personal project, the distributed compute platform called Ballista was donated to the Arrow project. Ballista is implemented in Rust and powered by Arrow as its internal memory model. Underneath Ballista's scheduling and coordination infrastructure is Arrow DataFusion, a query planning and execution framework. What does all this mean? Well, I'm glad you asked!
Most large data computation is done using some sort of distributed cluster. Multiple machines work together in a coordinated fashion to complete complex tasks. A great example of a framework like this you might be familiar with is Apache Spark. Currently, the architecture of Ballista looks something like Figure 11.4. You'll note the usage of Arrow Flight as the communication protocol along with a client for Rust and Python:
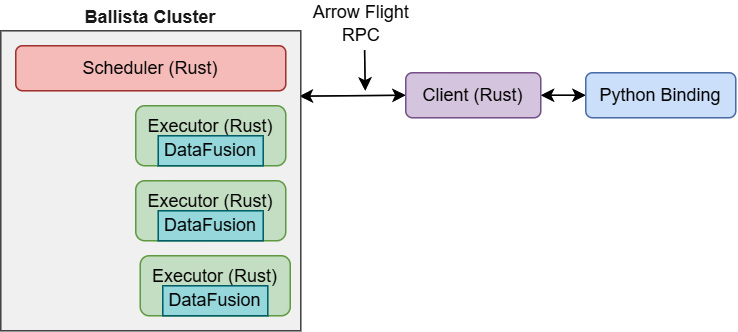
Figure 11.4 – Ballista cluster architecture (today)
The end goal of the project is to eventually have an architecture that looks like Figure 11.5. You can see integrated executors for user-defined functions in multiple programming languages, along with client connections for existing Spark pipelines and other utilities for ease of use. Using Arrow Flight as communication between executors allows for data to be passed between different languages with minimal overhead!
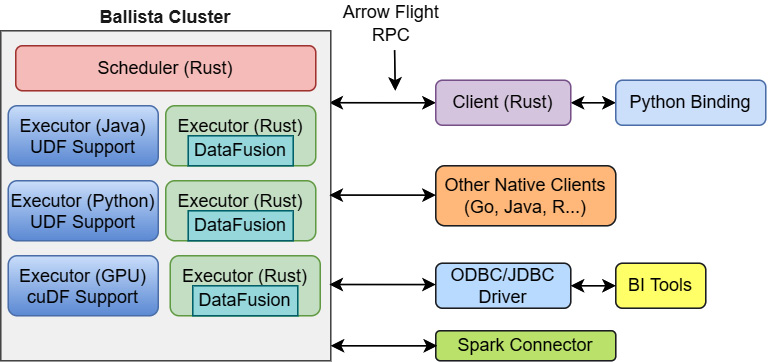
Figure 11.5 – Ballista architecture (eventually)
There's a long way to go with the development as it's still a fairly new project, but everything is looking extremely promising with it. As expected though, a large question that frequently comes up is how Ballista and DataFusion relate to Spark and why you'd want to use them instead of just using Spark. So, let's address that.
What about Spark?
Ballista's primary inspiration was, of course, Apache Spark. However, there are some significant differences between Spark and Ballista, which makes it a particularly interesting project:
- Ballista is written using the Rust language, which does not utilize a garbage collector or special runtime. As a result, Ballista's memory usage is much more deterministic than Spark's and does not have the overhead of pauses caused by a garbage collector.
- Although there is some column-oriented support in Spark, for the most part, it is still currently row-based. Instead, from the beginning, Ballista has been designed to be efficient with columnar data so that it can leverage the vectorized processing of single instruction, multiple data (SIMD), and even utilize GPUs.
- Using Rust along with the Arrow libraries in it can result in some cases where Ballista requires 5x to 10x less memory than Spark. This means you can do more processing on a single node at a time and need fewer nodes to run your workloads.
- One of the largest restrictions on Apache Spark is how you can interface with it. Because of the usage of Arrow and Arrow Flight, executors for Ballista and DataFusion can be written in any language with very little overhead costs by being able to communicate by utilizing Arrow directly.
So far, DataFusion can be embedded and used as an in-process query executor and it can be combined with Ballista to create a cluster for distributed query execution. Clients exist in Rust and Python so far, but since it utilizes Flight RPC for its communication, it's possible to easily create clients in other programming languages. Ballista and DataFusion may be in the early stages of their development, but they are already capable of significantly performant query execution at scale.
Looking at Ballista's development roadmap
You can already deploy a Ballista cluster using Docker or Kubernetes if you want to test it out. You can find all the documentation, and more, at https://arrow.apache.org/datafusion/index.html. But, before we move on to the next topic, let me whet your appetite with the published roadmap containing the current priorities of contributors.
For Ballista, the current priorities are to evolve its architecture to allow for deployment in multi-tenant cloud-native environments, such as a cluster stretching across servers in both AWS and Microsoft Azure. First and foremost, ensuring that Ballista is scalable, elastic, and stable enough for production usage is the highest priority. After that, the next priority they have published is to develop more comprehensive distributed machine learning capabilities. If you're looking for something that can do any or all of this, you should probably watch the Ballista project for further updates and keep an eye out.
For DataFusion, aside from general enhancements and improvements to query optimization and execution, interoperability is a big priority. The addition of support for nested/complex structures (list and struct columns), along with better support and performance when reading data from remote locations such as S3, are both big priorities. Additionally, there is a desire to add DataFrame APIs, similar to Spark and pandas, to make it easier to integrate DataFusion and Ballista into existing computation pipelines.
DataFusion is already in use by several projects and its community continues to grow while still being intimately tied to the Arrow ecosystem. It's a worthwhile project to check out and worth your time to keep an eye on if you have any interest in distributed computation or something that could be faster and easier to use than Spark. I highly recommend checking out both the documentation and the GitHub repository at https://github.com/apache/arrow-datafusion. You won't be disappointed!
Note
Just to call attention to it, unlike the other Arrow library implementations, the Rust language Arrow implementation is not under the formal Apache Arrow repository at https://github.com/apache/arrow. Likewise, DataFusion is also in its own separate repository from the primary Arrow GitHub repository. The Rust library can instead be found at https://github.com/apache/arrow-rs.
Now for something very different: Substrait and Arrow Compute IR!
Building a cross-language compute serialization
It may surprise you to know that SQL execution engines don't actually execute SQL directly! (Or you may already know this, in which case, good job!) Under the hood of your favorite query engine, what happens is that it parses the query into some intermediate representation of the query and executes that. There are multiple reasons for this:
- It's really hard to optimize a SQL query directly and be sure that you haven't changed the semantics of what it is doing. Translating to an intermediate representation allows for easier, programmatic optimizations that are guaranteed to be equivalent to the original query.
- Abstracting the specific query language (ANSI SQL versus other dialects) from the execution reduces the impact that changes to the language have on the execution engine. As long as the same intermediate representation is created by the parser, it doesn't matter what changes in the query language.
- Representing a query as a logical or physical plan allows different optimizations to be made to improve performance based on deeper knowledge of the current resources available.
Figure 11.6 represents a simplified view of the flow of a query going through these steps:
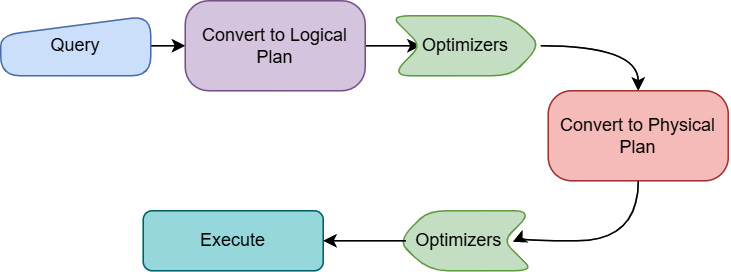
Figure 11.6 – Simplified query execution path
This approach is similarly taken by the LLVM compiler architecture that we mentioned when discussing Gandiva in the context of Dremio Sonar during Chapter 9, Powered by Apache Arrow. In that case, the compiler system is made up of several components, but I want to focus on three of them:
- Frontend modules that produce an intermediate representation for individual programming languages such as C/C++, Java, and Fortran
- A series of optimization modules that operate on the produced intermediate representation
- A code generator that can produce machine code from the intermediate representation for a variety of different processor architectures
Why should we architect the system like this, and what does this have to do with analytical computations with Arrow? Consider the life cycle of a query having three parts to it: the query itself, a parser/plan generator, and an execution engine for that plan. What if you could easily swap each of these pieces out for other modules without breaking your existing workflows? This would allow you to easily connect any plan generation you want to any execution engine you want, as shown in Figure 11.7. This is the goal of a project called Substrait (https://substrait.io):
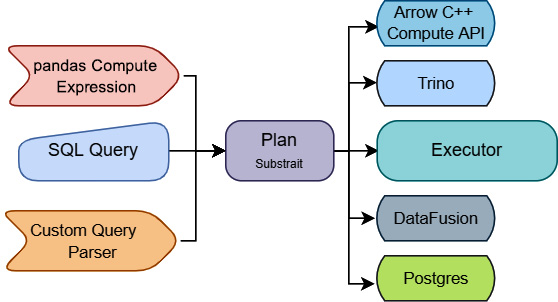
Figure 11.7 – Substrait's goal
As long as everyone can agree on what that intermediate representation looks like and how it should be built, both the producers and consumers of it can be swapped around. Consider taking an existing SQL parser and allowing it to communicate execution plans to an Arrow C++ computation kernel. Or, maybe allowing the execution of pandas expressions directly inside of a different execution engine without the overhead of passing the data to Python. While Arrow creates a standardized in-memory representation of columnar data, Substrait aims to create a standardized representation of the operations to be done on data. Arrow Compute IR is an implementation in the Arrow libraries of consuming that representation.
Keep in Mind
One thing to note is prototypes are being built to potentially include Substrait plans as a Flight SQL command type. Keep an eye out for more on this in the future!
Why Substrait?
Substrait is intended to be a cross-language specification for compute operations on data. The idea is to have a consistent way to describe common operations or custom operations, with the semantics strictly defined. Anything that can produce or consume the standard would then be able to interoperate with anything else that also does so. Many different projects and communities could benefit from this sort of a standardized effort, but they all have their own disparate existing systems. To resolve the competing priorities between various projects, one of the proposals for Substrait is to only incorporate something into the specification if it is supported by at least two of what they refer to as the "top four OSS data technologies": Arrow, Spark, Iceberg, and Trino.
Because Substrait is not coupled to any individual technology that already exists, it should be easier to drive its adoption and get people involved. It's not driven by a single community but rather by many individuals involved in many different data communities all injecting their own ideas, pain points, and considerations. It is a new and independent community of individuals that work with data and want to see this new level of interoperability get achieved between projects. As such, in addition to a specification, Substrait will define a serialization format for these plans and representations.
Working with Substrait serialization
There are two defined serialization types for Substrait's specification: binary serialization using Protobuf and text serialization using JSON. Why these two?
Binary serialization is intended for performance and needs to be easy to work with in many languages. By defining the serialization using a binary definition language, someone can take just the binary format definition and build tools for any language without having to directly rely on the Substrait project itself. In this case, using Protobuf, the .proto definition files can be used to build libraries for any language to work with the specification. While many formats exist that can be used to provide a compact binary serialization with generators for most languages, the project chose Protobuf due to "its clean typing system and large number of high-quality language bindings."
Text serialization, on the other hand, is not designed for performance but for readability. By providing a text-based serialization format, it is much easier to bring new users into the project. Simple command-line utilities can be built for converting SQL queries to Substrait plans or vice versa, among other potential basic tooling. Hopefully, this will promote more experimentation and adoption among interested individuals, making it easier to jump right in and play with the specification.
Currently, there isn't much in the way of tooling for Substrait plans as it's still very much in the early stages, but a few examples of potential planned tools could be a pluggable query plan visualization tool or enabling query planning as a microservice.
Getting involved with Substrait development
Substrait is consensus-driven and released under the Apache 2.0 open source license, with development on GitHub. You can get in touch with the community via GitHub issues and pull requests, or via Twitter and Slack. All the information necessary to get involved can be found on the Substrait website: https://substrait.io/community/. There's much more work to be done with, in my opinion, an extremely great goal. If nothing else, you should definitely keep an eye on the progress of the project and how it ends up affecting other related projects such as Arrow, Apache Calcite, Iceberg, and Spark. It'll be interesting to see how widely adopted Substrait and Arrow's Compute IR can become, and how it potentially changes the shape of the data science tooling ecosystem. Go read about it! Go!
Final words
This brings us to the end of this journey. I've tried to pack lots of useful information, tips, tricks, and diagrams into this book, but there's also plenty of room for much more research and experimentation on your end! If you haven't done so already, go back and try the various exercises I've proposed in the chapters. Explore new things with the Arrow datasets and compute APIs, and try using Arrow Flight in your own work.
Across the various chapters in this book, we've covered a lot of stuff, such as the following:
- The Arrow format specification
- Using the Arrow libraries to improve many aspects of analytical computation and data science
- Inter-process communication and sharing memory
- Using Apache Spark, pandas, and Jupyter in conjunction with Arrow
- Utilizing existing tools for interactive visualizations
- The differences between data storage formats and in-memory runtime formats
- Passing data across the boundaries of programming languages without having to copy it
- Using gRPC and Arrow Flight RPC to build highly performant distributed data systems
- The impact that Arrow is having on the data science ecosystem by highlighting several projects that are using it
Hopefully, you can find a lot of use for the content we've covered here and this book can serve as a reference book of sorts for you. I expect that Arrow is only going to continue to get wider adoption among the data science and analytical ecosystems, and now you'll have a leg up on understanding it all.
It doesn't matter if you're a software engineer, data scientist, or someone else, don't stop at just using the Arrow libraries in your work. Learn from the concepts and ideas that were put into these projects and try to find new ways to apply them in your own projects, whether they are personal or professional. Like anything else, Arrow and its related technologies are the culmination of many individuals working together and building upon the ideas that came before them. Maybe you'll come up with something else new and different that you can contribute back to the community! Who knows?
Enjoy, take care, and above all else, have fun with this stuff!