
Chapter 8: Improving the Security of Software
Software has enabled organizations around the world to increase their productivity to unforeseen levels of efficiency, helping to automate previously manual and menial tasks. By looking at your organization's software assets (and updating your risk register as you do it), you have become more and more aware that nearly every business process is aided by at least one software solution, and that the more resilient, secure, and available the software is, the more benefit is seen by the organization.
Some of your software has probably been developed in-house, and other software has been purchased or licensed from third parties. These systems often present huge attack surfaces, with many moving parts that are ready to be exploited, and since they process confidential and sensitive information and store business-critical data, unauthorized access to (or destruction of) these systems can lead to either permanent loss of critical data or the loss of confidentiality or integrity of intellectual property, company secrets, and customer data. Furthermore, these breaches can lead to colossal fines from regulators, adding insult to injury.
The terrifying thing is, even with all of the reasons to care that I've just listed, the procurement, development, and use of various software systems are usually undertaken with absolutely zero security-focused oversight. This is exactly why understanding and enforcing improved software security is crucial in order to ensure your organization mitigates the risk presented by the software it uses.
In this chapter, I'm going to delve into some of the topics that can help you ensure a higher standard for software security in your organization. This includes topics such as the following:
- Exploring software security paradigms
- Understanding the secure development life cycle
- Utilizing the OWASP Top 10 Proactive Controls
- Assessing software security
Overall, what we want to learn from this chapter is how to establish requirements for software, regardless of whether it has been developed by a third party or an in-house development team. I'll cover the methods we can use to understand the risk profile for software systems developed by a vendor, how to reduce the likelihood of vulnerabilities and errors in your organization's in-house development activities, and methods to mitigate against security risks, focusing on the CIA triad.
Without further ado, let's proceed on with this chapter.
Exploring software security paradigms
I'd like to take you on a trip down memory lane for a moment, and remember April 2014, an important moment in the general history of InfoSec; the world was blindsided by the disclosure of the CVE-2014-0160 vulnerability, given the moniker of Heartbleed. Now, when I use the term the world, I mean it. Heartbleed was the Jaws of software security blockbusters, getting a website of its own (heartbleed.com), and even its own logo:

Figure 8.1 – The Heartbleed vulnerability's logo
In the disclosure was information about how the OpenSSL cryptography library contained a vulnerability related to a buffer over-read, allowing a malicious actor to access cryptographic keys and login credentials, along with various other pieces of confidential information. It sounds bad, but it gets worse: the OpenSSL cryptography library is used in the OpenSSL version of the TLS protocol, widely used globally for securing data in transit, pretty much everywhere. To put it plainly: over half of the top 1 million most-popular TLS-/HTTPS-protected sites were affected and able to be exploited.
Even though a fix was released for Heartbleed on the same day as the disclosure, it didn't prevent devices such as firewalls, Android phones, and other trusted hardware, as well as software and websites, from being left vulnerable until the patches were implemented and updates were rolled out to align with the most recent version.
Furthermore, let's be clear: the vulnerability had existed in the code since 2011; we know this because it was viewable to anybody who cared to look through and read the source code. This was as a result of the fact that OpenSSL was software created in an open source development context. Open source means that the source code of the software is freely available to be read, modified, and redistributed. A perceived advantage of the open source software movement is the idea that transparent software prevents security-through-obscurity among other vulnerabilities in the source code, as it would be discovered by anybody who cares to look. Unfortunately, in the case of OpenSSL's cryptography library, it seems as though either nobody noticed or nobody was willing to shout about the vulnerability until 3 years later.
That might seem strange, right? Wrong. Up until recently, it's been the default. Security has been an afterthought to any organization looking to create new features and roll out new products, but as time has gone on, with blockbuster-style disclosures such as Heartbleed entering into the lexicon of the average business owner and IT professional, we've seen a paradigm shift toward giving security a bit more consideration.
So, how can we ensure we avoid implementing vulnerable software into our organization, regardless of whether it's a vendor-created productivity suite, an open source cryptography library, or a tool developed by an in-house team for your employees? You're not going to catch every issue, so it's important to manage your expectations on the matter. Just like with anything in information security, it's about risk management and setting up the appropriate policies and procedures to ensure the necessary steps have been taken, in line with the value of the assets in question.
To begin with, let's look at an idea that can be applied to more than just InfoSec, to any time we buy anything.
Buyer beware
Have you ever heard the term let the buyer beware? I'm betting you've heard the Latin version, caveat emptor, right? How about we use this opportunity to do what every person reading this chapter focusing on software security was hoping for and take a quick dip into Latin terms found in contract law:
Loosely translated to English, this means the following:
I'm surprised it's caught on so well, to be honest. Usually, if you need to take a breath in the middle of reciting an adage, it doesn't really last. Despite being quite long-winded, this idea has stood the test of time and must be considered when procuring new software.
It's up to the buyer to perform due diligence on software systems that are going to be utilized in their estate. It's your responsibility to ensure your organization has undertaken that due diligence appropriately and stores that information for future use in the event of needing to prove to regulators or auditors that the appropriate precautions were taken and that due care was applied in the process.
"But how?", you ask. "How can I make sure?".
Legal documentation
"Oh great," you say after reading the heading of this section, "he's going to talk about paperwork next." Well yes, I am, unfortunately.
The fact of the matter is, you can't be 100% certain that the software you've purchased has been developed securely. You can, however, try to implement terms into the contractual agreement you have with the vendor to ensure they understand your requirements and are responsible for ensuring their developed solutions are created with security in mind.
Contracts that define liabilities associated with the vendor are a form of risk mitigation. What I mean is that in the event of a breach that leads to the disclosure of either your organization's confidential information or sensitive information related to individuals, are you able to be reimbursed by the vendor based on the level of loss your organization faces from fines and reputational damage?
Whether or not the vendor accepts those terms depends on various factors, including the nature of the terms, the size of the vendor, the size of your organization, how big of a customer you are for them, and so on.
Sometimes, you'll just need to implement other types of mitigation and accept that the vendor isn't accepting liability in the event of a breach, regardless of whether a backdoor or malware was introduced from their side. It's your responsibility to keep the agreements documented and reference them when you're performing risk assessments, both before and after the software has been implemented.
Furthermore, the ideologies relating to InfoSec for your assets that we've covered in this book still stand. We must allow least-privilege access to the software, we should monitor the software's activity and how it interacts with our other assets, and we will continually review and assess the software's suitability and risks over its entire life cycle in our organization.
Speaking of life cycles, I figure we should discuss the idea surrounding the Secure Development Life Cycle (SDLC), as knowledge surrounding this topic relates to both software developed by third parties and your organization's own undertakings in developing software.
Understanding the secure development life cycle
The SDLC is all about baking security into the development of software through a set of processes. When you ask your vendors about their SDC, you're going to want to understand the methods that they are employing to ensure the software they're selling you is secure enough for your organization.
The same company that offers the CISSP, known as (ISC)², also offers the CSSLP, or Certified Secure Software Lifecycle Professional, which covers eight domains that you need to understand in order to pass the exam:
- Secure Software Concepts
- Secure Software Requirements
- Secure Software Architecture and Design
- Secure Software Implementation
- Secure Software Testing
- Secure Software Lifecycle Management
- Secure Software Deployment, Operations, Maintenance
- Secure Software Supply Chain
Obviously, going into each of these topics in any sort of depth is going to occupy more than the 30-page limit I have on this chapter, and if I did so, it would repeat much of the concepts I've previously touched on in this book, including labeling the types of data or implementing the principles of least-privilege and separation of duties, or defense-in-depth, but it's still worthwhile to highlight some of the key takeaways unique to the SDLC and pique your interest for further investigation.
We can essentially split the SDLC into five stages, each with its own sub-groups:
- Defining business and security requirements
- Designing secure software
- Test plans for secure software
- Secure software development
- Testing the software
Shall we delve briefly into each of these bullets to discuss the process at a slightly more detailed level? Let's do it, but first I would like to address the elephant in the room: the idea that nobody develops code this way anymore. Let's talk about the various software development methodologies and how they might work with the SLDC.
Compatibility with various software development methodologies
Over time, the most widely chosen methods of developing software have transitioned from a stage-by-stage, project-managed, "release major updates twice a year" Waterfall type of approach to software development toward a more rapidly iterative approach, often referred to as Agile, where the solution is broken up into small cycles, attempting to deliver a working product early and improving incrementally and often.
Furthermore, there might be a split between the developer team at an organization, and the IT operations team, or there might be a more integrated approach to developing and deploying software, such as the DevOps approach, for example:
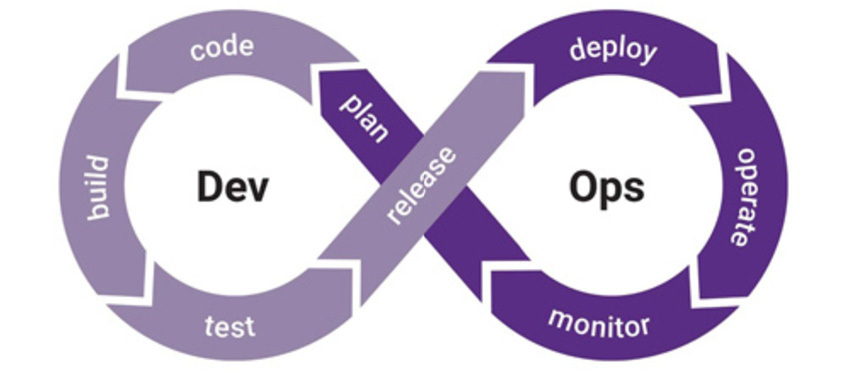
Figure 8.2 – The DevOps life cycle diagram
Regardless of which method(s) your organization develops software with (and there are many different styles inside those methodologies), the SDLC process can still be utilized and employed as a baked-in approach. Notice in the preceding diagram of the DevOps life cycle that it aligns with the five steps of the SDLC I mentioned previously, as long as you find a place to ensure you define the business and security requirements for the software in the planning phase!
Okay, let's take a closer look at each of the five steps of the SDLC, starting with defining your business and security requirements.
Defining business and security requirements
You see, in order for good software to be created, requirements must be defined at the beginning of any iteration. It rarely is, but then again, software is rarely what we would consider good. Inside those requirement definitions, along with usage scenarios and solutions, we need to ensure we define the security and privacy requirements for the software, and in the process of development, the software must be tested against those security and privacy requirements.
Beyond that, we need to consider the abuse cases or ways a malicious actor may misuse the software, essentially performing threat modeling with consideration into the attack surface. As a result of the findings from the abuse cases, we need to ensure that the appropriate mitigations have been put into place (with expenditure in line with the level of risk) to prevent or decrease the likelihood of those attacks from being successful and find a way to reduce the impact if the attack is successful.
I will discuss how we can do this in a more detailed fashion in the Utilizing the OWASP Top Ten Proactive Controls section.
Designing secure software
With the abuse cases and requirements in place, we want to design the software architecture to have the appropriate controls (preventative, detective, and responsive) in place, and ensure the overall structure of the application and the way it interacts with other systems and individuals are secure by design.
Testing plans for secure software
Along with unit testing, integration testing, system testing, and acceptance testing, security testing must be implemented into the SDLC in order to catch security vulnerabilities through various methodologies, including both automated and manual processes.
Prior to the development of the software, we want to plan and define the tests that must be done in order to ensure the software development process takes these tests into consideration.
The ISO/IEC/IEEE 29119 standards for Software and Systems Engineering – Software Testing are a set of standards comprising five different parts:
- Part 1: Concepts and definitions
- Part 2: Test concepts
- Part 3: Test documentation
- Part 4: Test techniques
- Part 5: Keyword-driven testing
There was a bunch of pushback over the 29119 standard, where several groups claimed it's unnecessary to standardize testing. I don't think this should matter to you in this chapter; it's up to you to determine whether any of these ideologies is applicable in your organization. The bottom line is, the standard's Part 3 offers template documentation examples for your test plans, and if we're following the SDLC, then it might make sense to lean on those rather than spending time reinventing the wheel.
The templates from ISO/IEC/IEEE 29119:-3:2013 (yes, I know, what a name) cover the organizational-level, project-level, and dynamic test documentation you might like to use, including the following:
- Organizational test process documentation templates:
- Test policy
- Organizational test strategy
- Test management process documentation templates:
- Test plan (including a test strategy)
- Test status
- Test completion
- Dynamic test process documentation templates:
- Test design specification
- Test case specification
- Test procedure specification
- Test data requirements
- Test data readiness report
- Test environment requirements
- Test environment readiness report
- Actual results
- Test result
- Test execution log
- Test incident report
This means you'll have the appropriate suite of templates to help your product team(s) and engineering team(s) quickly and systematically document and meet the requirements set out for your software. If it seems like all of this process and documentation will get in the way of getting actual engineering work done, you're probably a software engineer.
With that said, I'm well aware of the complaints and concerns that are raised by developers in this circumstance, especially the faster we develop things and the more rapidly we integrate changes into our production environment. If your organization is utilizing these principles, then I'm not going to advise you to bog down your team with a bunch of paperwork.
Our job as information security professionals is to understand the risk and reduce it to an acceptable level. Part of this process is ensuring that the software that is being created by the development team is fit for purpose and meets the requirements defined, and showing that without these processes in place is a difficult task.
With the documentation I mentioned from ISO/IEC/IEEE 29119, we aim to do the following:
- Analyze the software, where we specify the users, use cases, use scenarios, and resources utilized by the solution.
- Design the test strategy, where we define the objectives for the tests and estimate the resources required and costs associated with the testing phase. We also define what is in scope and what is out of scope.
- Define the test criteria, where we create a flow that defines when we stop testing in the event of a failure and what constitutes a successful test completion.
- Define the test environment, where we specify the user and business environments that we will test in.
- Define the schedule, including deadlines, estimations for each resource, and any blockers or dependencies that might hamper the ability to complete the tests.
- Determine test deliverables, including test results and reports, test procedure documentation, and release notes in the event of the software meeting the test requirements.
So, it's not like I'm asking you to write War and Peace here, and if we're following the Agile process, each small improvement can have a truly short definition for each of the six previously listed concepts, potentially right after the user story. The user story is a way to define software requirements to developers in a structured way:
As a <insert role>, I want <insert requirement>, so I can <insert use-case>.
That covers most of the first step, analyze the software, and after that, we can include our test objectives, resources required for the tests, acceptance criteria, test environment, and test schedule.
If errors are found, they can be solved quickly and easily in the same iteration or sprint.
So, how might you want to test the software in order to ensure security vulnerabilities are taken into consideration and avoided?
I'm going to go into that, but first I'd like to talk about the process of securing software development, the next phase of the SDLC.
Securing software development
In the process of developing the code, we want to ensure our developers are following certain ideologies related to secure code. We can create training and awareness programs and provide documentation on how to ensure they are following secure software development ideologies, including but not limited to the following:
- Input and output sanitation, to prevent injection vulnerabilities and denial of services from malicious or negligent user input
- Appropriate error handling, and ensuring the user isn't given too much information in the event of an error occurring
- Resource management and concurrency, ensuring processes are scalable
- Isolation, ensuring processes are segregated through sandboxing, virtualization, containerization, and related technological concepts
- Cryptographic control selection and implementation, ensuring the appropriate protocols are implemented correctly, with cost-benefit analysis taken into consideration
- Access control structures, including ensuring trust zones, least-privilege, and Role-Based Access Controls (RBACs) are considered and appropriately applied
In order to avoid repeating ourselves, I think it might be more useful to cover these ideologies in further depth by having a look at the types of tests we may implement to check for well-known security flaws in software and explaining how those flaws can be avoided or mitigated against.
Testing the software
Considering we have already defined the appropriate test processes, relevant stakeholders, environments, and acceptance criteria, now is the time to execute those plans, with both automated and manual processes being undertaken to ensure any changes that have been made to the source code, environment, or usages of the software are appropriately effective, efficient, and secure.
This is not to say we perform all these tests after the software has been developed. If we're using more rapid development methodologies, we must leverage more automated systems and create rapid notifications for any manual testing processes required in order to ensure there isn't a bottleneck at the testing phase of the SDLC. This near-real-time approach to testing new software results discovers issues quickly and ensures the developers are adaptive and fail fast, discovering their errors quickly and remediating before too much time has been put into a flawed approach. By doing so, we're helping the developers create more secure software, quickly.
Looking back at how we might have defined our test plans and designed our test processes, a few examples of what we would like to implement along the process in order to increase security and speed up testing processes could include the following:
- Architecture analysis, including end-to-end process and design examination.
- Dependency checks, which automate the process of checking for vulnerabilities in imported third-party software dependencies.
- Automated SAST, or static application security testing, which we've mentioned in previous chapters.
- Automated DAST, or dynamic application security testing, which we've also mentioned in previous chapters.
- Code review, where one developer reads and critiques the code of another developer. This helps with knowledge-sharing, as well as implementing the two-man principle, which means the two parties would need to collude in order to implement a backdoor or malware. It's not fail-safe, but it's part of a defense-in-depth approach.
- Penetration testing, which we've spoken about multiple times, could occur upon significant change, as well as on a regular point-in-time basis.
Inside these processes, we will as a bare minimum want to check to ensure that the OWASP Top 10 Proactive Controls (https://owasp.org/www-project-proactive-controls/v3/en/0x04-introduction.html) have been implemented. This means putting documented procedures into place for both automated scans as well as manual code reviews, and training developers on all of these steps and controls. It's crucial for the success of your SDLC, so don't neglect training, awareness, policies, and procedures!
I'd like to go into the Top 10 Proactive Controls from OWASP in the following sections.
Utilizing the OWASP Top 10 Proactive Controls
Let me briefly cover each of the OWASP Top 10 Proactive controls for improving the security of software. Each control has its own section.
Define security requirements
As we've previously discussed, the ability to articulate and document the requirements expected to be fulfilled by a software solution is highly beneficial to the organization for various reasons, including cost-savings and useability improvements, but another business requirement that must be fulfilled by either software development work or purchased/open source software are those requirements surrounding information security.
Creating standard security requirements based on best practices and industry knowledge helps developers and procurement staff reuse the knowledge they gain from previous iterations, so it's highly recommended to define the requirements in a way that will be uniform and stand the test of time.
Inside the OWASP Top 10 Proactive Controls section on defining security requirements, they reference the OWASP ASVS, or Application Security Verification Standard, which is a collection of security requirements, and the various criteria required for verifying that those requirements have been met. As a sample, it includes categories of best practices for various information security functions, such as access control, error handling, authentication, and so on. It's an excellent resource that should not be ignored.
As we previously spoke about, utilizing user stories, as we would see in Agile software development processes, as well as misuse user stories, can help teams operating in these functions to verify that the security requirements have been met.
As an example, we can reference the ASVS requirements that you could leverage for authentication, such as verifying that there are no default passwords in use, as referenced here:
To convert that into a user story, use the formula I mentioned previously:
As a <insert role>, I can <insert requirement>, so I can <insert use-case>.
Let's do it for ASVS 3.0.1, requirement 2.19:
Or:
A misuse user story is told from the perspective of the malicious actor:
It's up to you whether you want to utilize one or both of these in your user stories, but just be careful that your developers understand what they are, and don't misread the misuse user story as a requirement!
Leverage security frameworks and libraries
Software development has a wealth of resources available online, from free online courses to learn various languages to documentation for web app frameworks, and the list goes on. That culture has extended into the world of security in software development, with standards, frameworks, libraries, and other highly documented resources available to anybody interested enough in learning. Sometimes, it's as simple as importing a few packages into a development project.
With that, it's still important to remember a few key ideologies to ensure the risk of utilizing third-party resources is safe and secure:
- Using trusted sources that have a track record for maintenance activity. If a framework or resource isn't actively updated and maintained, it will present challenges and has a high likelihood of vulnerabilities.
- Ensure we document all third-party libraries and software inside our risk management asset catalog. This may be difficult, but there are services such as Snyk (https://snyk.io/) that automate the process of gathering the list and applying a risk score to that list.
- Ensuring that updates are applied before the software is facing breaking changes due to lack of maintenance. Aside from the previously mentioned Snyk, OWASP themselves offer a tool called OWASP Dependency-Check to look for publicly disclosed vulnerabilities in your third-party library list. NPM has a similar service available, and more options appear regularly.
- Ensure developers maintain the principle of least-privilege any time they can. Allowing increased access increases the attack surface, and therefore will likely increase risk.
You know, the basics that we've been harping on about for this entire book now!
Secure database access
When software interacts with data stores, such as SQL databases, a number of key ideologies can be upheld in order to increase the security of the software and reduce risk to an acceptable level. As an example, we don't want users to be able to input anything into a query that is then interpreted as a command without being parsed, checked, and sanitized first:

Figure 8.3 – XKCD #327 – sanitizing inputs
Ideally, we won't even give the users the ability to enter queries themselves, but that depends on the use cases. By using protections such as query parameterization, you can create secure queries that reduce the likelihood of an injection attack, such as SQL injection.
Read more about query parameterization from the OWASP Query Parameterization Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Query_Parameterization_Cheat_Sheet.html).
Furthermore, you'll want to ensure your database and any computing platform used to run the database are properly set up with a secure configuration, preferably leveraging the baseline configurations we referenced in previous chapters.
Secure authentication means that authentication is protected through various means. For example, it's important to ensure that authentication is performed through a secure channel, protecting any credentials from being exposed. When credentials are stored at rest, they must be protected with defense-in-depth for the various threats, including access control and encryption-at-rest for protection against attacks on confidentiality, and redundancy for attacks on availability.
Finally, while the software and database communicate back and forth, it's important to ensure that the communication takes place over a secure channel, utilizing encryption-in-transit, as well as preventing the user from gaining too much information from error messages and logs.
You can read further into database security from the OWASP Database Security Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Database_Security_Cheat_Sheet.html).
Encode and escape data
Another way to prevent injection attacks is to encode and escape any special characters with an escape character (such as adding a backslash character before a double quote character, ", to prevent the interpreter from closing a string) in order to reduce the risk of the interpreter or browser outputting dangerous content as a result of bad input.
Encoding output data helps protect against Cross-Site Scripting (XSS) attacks, among other flaws such as operating system command injection or the time somebody's emoji use ended up crashing an entire banking system (https://www.vice.com/en/article/gv5jgy/iphone-emoji-break-apps).
Encoding and escaping can occur at various stages in the process of accepting and outputting data and should be considered any time user input or other untrusted data is interpreted or dynamically output back onto the interface.
You can read more about how to prevent XSS attacks from the OWASP Cross-Site Scripting Prevention Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html), and how to prevent injection attacks from the OWASP Injection Prevention Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Injection_Prevention_Cheat_Sheet.html).
Validate all inputs
Closely related to the last point is the idea of validate all inputs. We want to ensure all inputs are appropriately validated and properly formatted before they're stored or interact with any part of the software or system.
That includes the classic syntax checks, such as if a user is entering a credit card number, we want to make sure that it follows the format of a credit card number.
This includes preventing any blacklisted characters or terms from being accepted, as well as having a whitelist if the input can only be a certain number of things. For example, if the input is asking for a two-letter abbreviation for a US state, we can have a whitelist of the 50 "approved" inputs and prevent any other input from being approved.
These checks should follow the defense-in-depth idea and shouldn't rely on a happy path for the user to follow, as malicious actors like to find ways around the frontend controls.
Leveraging validation functionality in various security libraries and frameworks can simplify this process for your development team, but they should always be tested to ensure they're fit for purpose on your project.
Treating all inputs as though they are malicious is the way forward, so let's just agree to add that to all of our SDLC policies moving forward, alright? Further reading on input validation can be done with the OWASP Input Validation Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Input_Validation_Cheat_Sheet.html).
Implement digital identity
We need to ensure that our individual users are given an ID while interacting with our software, in order to both offer a streamlined experience during their session, as well as providing ourselves the ability to understand errors and track misuse.
NIST released a special publication, 800-63B, Digital Identity Guidelines – Authentication and Lifecycle Management (https://pages.nist.gov/800-63-3/sp800-63b.html), and it's worth referencing in the process of implementing and leveraging digital identity.
Inside the NIST Special Publication 800-63B, various controls and their proper implementations are detailed. This includes requirements for various "levels" of applications, depending on the information contained and processing performed.
For example, a Level 1 application is one that is considered low-risk and doesn't contain any private data or PII. As a result, only password authentication is required, with checks against commonly used passwords and password length requirements of 10 characters or more being suggested for users not utilizing multi-factor authentication (MFA). I highly recommend reading the publication for further guidance.
The process for users of your software to reset their forgotten passwords should include MFA methods to prove their identity. A typical way to achieve this is to utilize a side-channel such as email and send a password reset email containing a unique link to the email address associated with the account. More information on the suggested process can be found in the OWASP Forgot Password Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Forgot_Password_Cheat_Sheet.html).
When we talk about session management and cookies, a few steps can be taken toward better security for our users. For example, expiry for the cookie should be set. Setting an HttpOnly attribute on a cookie prevents the cookie from being referenced and utilized in JavaScript code. Any transfer should be protected with TLS encryption to prevent man-in-the-middle attacks from grabbing a session ID, by setting the Secure attribute.
Further reading on session management, web authentication, and access control can be found in the OWASP Session Management Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Session_Management_Cheat_Sheet.html).
Enforce access controls
Similar to the previous point on digital identity, access control and authorization are about granting and revoking various permissions or privileges from users. By leveraging known paradigms, such as RBAC, for example, which we've gone into previously in this book, and by building out strong access controls up front that prevent vulnerabilities and flaws such as access creep, you're ensuring that your users have access to what they need, nothing more and nothing less.
In order to enforce the access controls implemented, all requests must be passed through an access control check, with the default setting being deny. As a result, rules shouldn't be hardcoded, and instead should be dynamic based on the access level granted to the present user interacting with the software. Again, it's a matter of defense in depth.
Finally, ensure you keep track of all events related to access with logging and pass those logs into security monitoring resources. We will discuss that later.
Further reading can be found in the OWASP Access Control Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Access_Control_Cheat_Sheet.html).
Protect data everywhere
The basis of the information security profession is to ensure the security of information. When we transfer or store data in our applications, we want to make sure that it's adequately protected from threats and take a risk-based approach to applying controls, with the ideas of least-privilege, defense in depth, and other approaches we've discussed in this book taken into consideration.
In terms of data security, it includes data classification, where we apply a sensitivity level label to each piece of data, and map those labels to the adequate control requirements defined by you and your organization, based on regulations, reputational risk appetite, and confidentiality, integrity, and availability risk appetite.
An easy win in terms of protecting data is to implement encryption for data in transit, generally TLS. This protects against man-in-the-middle and side-channel attacks occurring on either the communication between the user and the frontend application server or between the frontend application server and the backend.
Encrypting the data at rest reduces the risk related to loss of confidentiality, but the complexity and technical skills required might slightly increase the potential for misconfiguration leading to a loss of availability. Encrypting data at rest is an important step, but must be carefully planned and implemented in order to be effective.
Leveraging cryptographic libraries can be a good starting point, regardless of whether my horror story at the beginning of this chapter was entirely based on organizations experiencing an information security incident due to using a third-party cryptographic library.
Secrets such as credentials, certificates, SQL passwords, and so on should be managed and protected as though they are the crown jewels of your application. Don't store them in plaintext in the databases, don't hardcode them, and rotate/de-provision the keys associated with users when they leave the organization. Secret vaults such as HashiCorp Vault offer the streamlined automation of this process but require a technical skillset.
Further reading can be found at the following links:
- OWASP Transport Layer Protection Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Transport_Layer_Protection_Cheat_Sheet.html)
- OWASP Cryptographic Storage Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Cryptographic_Storage_Cheat_Sheet.html)
- OWASP Password Storage Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html)
Implement security logging and monitoring
As we've previously spoken about security monitoring in previous chapters, I don't believe I need to delve deeply into how that might help your organization. The bottom line is: more information can help you and your colleagues detect security incidents with better accuracy and improved response times.
You can increase the level of information that your organization's developed applications feed into your monitoring solution, but remember that sensitive information such as PII or confidential information is sometimes included in diagnostic and debugging information, and might need to be removed before reaching the monitoring solution. Additionally, make sure that your timestamps align across your nodes or your data will be inaccurate and difficult to use.
In order to prevent any log forging or injection attacks, you should consider the encoding principles and validation exercises we mentioned in #4 and #5 of this list. Another protection against tampering is to set up access control and authorization principles for your logging solution. In order to avoid loss of availability, your solution should have some form of redundancy in the dataset, such as storage in multiple locations and backups.
Further reading into how you might use security logging and monitoring can be found in the OWASP Logging Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Logging_Cheat_Sheet.html).
Handle all errors and exceptions
Ensuring your application is resilient and able to handle errors and exceptions is an important property of ensuring all forms of the CIA triad. Bad error handling can lead to the disclosure of confidential or sensitive information, disruptions to the application's stability, or even modification to important data that you rely on for various monitoring purposes.
Bad error messages can give a malicious actor more information than acceptable as well. Have a look at this signup page that I need to believe is a joke, or else I've lost all hope:
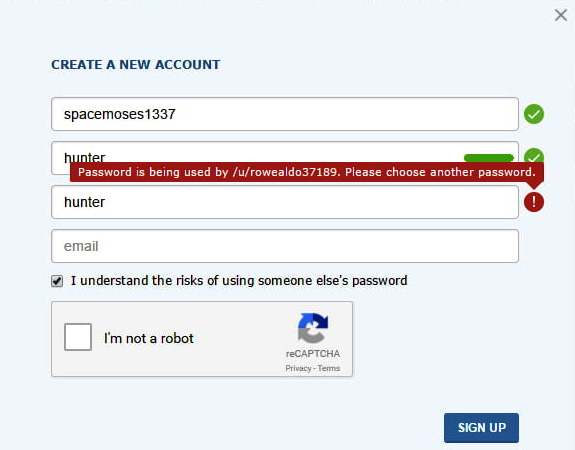
Figure 8.4 – The dumbest signup page error message ever
I can only guess the user decided to go with hunter2 as the password after that error message.
When we are creating errors, make sure the user isn't able to get more information than they need, but give them enough to find the answers themselves or to reach out to a member of support for help. Internally, we want to log enough to help with support, testers, forensic investigations, and incident response teams. Remember that if team members from the software developing team actively collaborate with the security, testing, and business team members, it will lead to better software overall.
Finally, good tests must be created in order to catch these exceptions before users do. Great testers, combined with some automated tooling for finding errors both statically and dynamically, will help reduce the overhead required for support, as well as reducing the risk of the application suffering a loss of one or more of the CIA triad principles.
Further reading can be found in the OWASP Error Handling Cheat Sheet (https://cheatsheetseries.owasp.org/cheatsheets/Error_Handling_Cheat_Sheet.html).
If you enjoy this topic as much as I do, I think some further reading might be of interest to you, and so I've compiled a few different links to frameworks and processes for you to investigate. These are useful in implementing security in the SDLC:
- MS-SDL, the Microsoft Security Development Lifecycle: https://www.microsoft.com/en-us/securityengineering/sdl
- NIST 800-160, Considerations for a Multidisciplinary Approach in the Engineering of Trustworthy Secure Systems: https://csrc.nist.gov/publications/detail/sp/800-160/vol-1/final
- The Cybersecurity and Infrastructure Security Agency's CLASP, or the Comprehensive Lightweight Application Security Process: https://us-cert.cisa.gov/bsi/articles/best-practices/requirements-engineering/introduction-to-the-clasp-process
Okay, fine, we've gone through the SDLC, so now we can go into detail about how it might help us with assessing software next.
Assessing software security
Moving forward, I would like to discuss the methods we might utilize in order to assess the security of software. In previous chapters, we've looked into the importance of regular testing of software and systems, including penetration testing and vulnerability scanning, and the remediation of any of the findings. I've encouraged the implementation of configuration management systems that can help keep your organization's assets up to date, and monitoring solutions to uncover performance issues, misuse, errors, or malicious activity. I've also talked about resilience and redundancy, and how expensive it might be for each hour that your organization loses access to one of their systems.
Now, with that all said, if we're going to go deeper, I think it's relevant to split this topic into two sections because the methodologies and approaches are different depending on who has ownership of the software, taking into consideration the cloud operating model and the shared responsibilities related to utilizing Software-as-a-Service (SaaS) products.
On one hand, we have third-party vendors who develop and sell software to companies. Their focus is creating a tool that is valuable to your organization, such as Customer Relationship Management (CRM) systems, HR software, productivity tools, web analytics software, cloud storage solutions, and so on.
On the other hand, we can also leverage an in-house development team to create software for our organization to either solve problems that aren't currently offered by a vendor or to save money based on the cost presented by the current offering from third parties. Additionally, we can leverage outsourced development teams to create our in-house software or leverage the power and convenience of open source software.
Let's delve into how to improve the security of third-party vendor software.
Reducing the risk from software developed by a third-party vendor
As we have now covered the various controls and processes that can be put into place to reduce the likelihood of software being created with vulnerabilities in the code itself, it must be noted that many of your organization's software solutions are going to be either purchased from a third party or pulled from an open source software repository resource such as the public repositories on GitHub.
Policies and procedures need to be put into place to ensure that you have visibility on the procurement process, regardless of which scenario is occurring, and have oversight on the software assets being utilized in your estate.
Here's the issue: what can you do about it? When we're looking at the major software that I see used by nearly every organization, such as those developed and sold by Microsoft, Salesforce, Atlassian, and so on, how can you ensure they're employing the appropriate controls for their solution, as well as following an SDLC approach?
Cloud-based software
The massive paradigm shift we've seen over the past decade toward the SaaS model has increased the pace of implementing new software into an organization, where a user is likely accessing the solution through their web browser. This model for using software has led to the responsibility of handling servers and databases shifting away from the customer and onto the vendor.
That isn't to say we absolve ourselves of any responsibility when it comes to the privacy and security of the data processed and stored in these SaaS applications, however; in fact, it is absolutely our responsibility as customers to ensure that the solution we choose is secure enough for our organization.
As I mentioned previously, it might be difficult to arrange for your own testing to be performed on the infrastructure and software currently being offered by your SaaS vendors. The reasoning behind that is simple: that type of testing activity could present a level of risk that is deemed unacceptable by the vendor, as you could accidentally disrupt their service for millions of other users. You can't perform any tests on infrastructure without permission either, or you'll be putting yourself and your organization at risk for legal liability.
So, how can we go about asking our vendors about their software's security?
Understanding third-party software risk
We've previously mentioned in this book that we might – from the perspective of being an information security professional working at a software vendor – create an information security whitepaper to detail security paradigms and controls utilized by your organization. With that said, now that you're the potential customer, how do you ask the appropriate questions to ensure the software your organization is in the process of procuring is appropriately secure and controls are in line with the level of risk?
Well, we perform due diligence and produce legal documentation defining liability and the agreements between your organization and the vendor. I already covered this in the preceding thrilling section where we talked about Latin terms found in contract law… and how could you not remember that?
In these agreements, you might be able to arrange for documentation from the latest penetration test performed on the software to be shared for your review, or for your own security team to be able to perform their own testing as a form of due diligence. It all depends on what both parties are willing to agree to and what will give you the assurance required to help meet your level of risk tolerance. As we've said, we have to be aware that it's not always possible to penetration test or even to vulnerability scan a software solution, but even if you were to find a vulnerability in a software solution that has been developed by a third party, how are you going to notify the vendor, and do you expect them to fix the vulnerability in a timely manner?
In your legal documentation, you might also want to try and define the SLAs and procedures for the remediation of vulnerabilities, but we still haven't covered how to get a better look into our vendors' security posturing. How do we know that they're handling security in a way that we deem is acceptable?
In this circumstance, we often send a set of documents known oftentimes as the Vendor Security Assessment Questionnaire (VSAQ) to software vendors for them to complete before an agreement is made. Most organizations send out some Excel spreadsheets with rows and rows of hundreds of questions, along with drop-down or free-text cells to input answers, and/or evidence and justifications for answering the way they did. If you've ever worked as a security professional at an organization that develops software to be offered to customers, you've had to fill these assessment spreadsheets out, and they're never the same, unfortunately. Google tried their best to standardize these questions into an open source, interactive, and dynamic solution on their GitHub page (https://github.com/google/vsaq), but from what I've seen, it still hasn't caught on. If we can make this happen, it would really save us all a load of time and effort, while delivering a high-quality result. Can we please make this happen?
Upon receiving the completed VSAQ back, we shall document the residual risk that is unmitigated by the vendor, and measure that residual risk to see whether it's below the threshold level of risk acceptance or not. In the event that the risk is above the acceptable level, we need to make the decision to either mitigate it, accept it, or avoid it. I should hope, considering we're nearly at the end of the book now, that it's all awfully familiar at this point.
Once you've completed your due diligence and communicated your findings to the business decision-makers, and the agreement is secured and finalized, the implementation of the software will begin. It might be on-prem installed software, or it might be cloud-based SaaS.
SDLC due diligence for software vendors
Since we covered the various steps and requirements for an SDC, you now know the basics, and you have much of the information you need to ensure you can perform the appropriate due diligence surrounding their development life cycle.
First of all, it's important to not only ask whether the vendor follows processes surrounding the SDLC, but also to have them detail how exactly they do so. You could also ask for evidence as a validation method. If they answer "no," then you need to highlight the risks associated with utilizing this software that has been developed without regard to the SDLC to the appropriate decision-makers in your organization.
Penetration testing and bug bounties
We might be able to arrange to penetration test the software, but if it's a SaaS, as we've said previously, don't get your hopes up, as most vendors will not allow it. Besides, performing that sort of in-depth, technical activity on all potential vendors will become costly for your organization very quickly. A novel solution for both vendors and customers that has recently become popular is the implementation of a bug bounty program, where a software vendor opens their product up to be penetration tested by bug bounty hunters, who are trying to exploit security vulnerabilities for a reward offered by the vendor. Companies such as Bugcrowd (https://www.bugcrowd.com/) and HackerOne (https://www.hackerone.com/) are offering organizations such as yours (and your vendors) the opportunity to have their software "hacked" by security professionals globally. If your vendor has a bug bounty program, it may bode well for where they stand in their security posture, especially if you are able to review the bugs that have been found and the current open bounties.
If the vendor claims to be secure but doesn't want to provide penetration test reports and doesn't take part in a bug bounty program, you might want to ask them how they process and prioritize vulnerabilities that are coming from their penetration tests, or which tools they use for DAST, SAST, or dependency scans. Use your knowledge of the landscape to see whether they know what they're talking about, and try your best to get evidence where you can. It is the security of your organization on the line, after all.
On-prem third-party software
When we're looking at software that is installed onto your company's servers or endpoints, we have a few simple mitigations that we can employ to ensure your environment's security isn't compromised due to a vulnerability in this software. We want to reduce our attack surface by following the foundational concept of least-privilege we've covered.
"Sorry, our software needs to run as admin," the vendor tells you.
Your first question back to them should be "why?". You know too much to be told that and not question it further. Find out what the software does and why it needs admin access, and find out whether there's a way to mitigate against that risk.
Furthermore, we've discussed vulnerability scanning at your organization in previous chapters, and your new on-prem software should be included in the scope. If you find a vulnerability through these means, it is worth starting a dialogue with the vendor to understand the vulnerability and to see about patching it. They might react poorly as a result, but in the near future, I am absolutely positive that it won't just be you that pushes back about bad security in their software. Together we can move mountains and force vendors to create software that follows best practices.
What about on-prem software that is open source?
Open source software
When we talk about open source software, what we're generally referring to is Free and Open Source Software (FOSS). With FOSS, you're able to download software that has been created and hosted on various platforms such as GitHub or SourceForge in a way that allows the potential user to actually see the underlying code.
The idea behind open source is that we get software that is transparent, peer-reviewed, and free created by people looking to solve technical (or societal) issues without further incentive to do so apart from altruism and potentially demonstrating mastery.
With that said, the events surrounding Heartbleed, which we investigated earlier in this chapter, were a situation stemming from the use of insecure open source software being widely utilized. How can we ensure the appropriate mitigations have been implemented during the development process of the open source tools and pieces of code – also known as snippets – that are either currently being used at your organization or are under consideration?
Additionally, we need to remember that many of our vendors are leveraging open source software in the process of developing their proprietary software. Let's keep that in mind when we're developing our VSAQs for the due diligence process.
On the plus side, we have the ability to review the code. There should be requirements in our information security policies to ensure that the same security steps that we have put into place for our own software development are also applied to the open source software we use. This means performing dependency checks, SAST, DAST, vulnerability scans, and so on. Oftentimes, we'll create a security pipeline that automates the defined processes and security scanning steps required on any code or software that is deemed in scope.
Improving the security of in-house software
Let's say in-house software can include software that has been developed by either your organization's in-house development team or an outsourced development team, as well as the open source software that your organization is leveraging. Although that open source software was (likely) developed by a third party, you have the ability to treat it as in-house-developed code and put it through the same assurance processes.
I would like to discuss how we might implement security controls into development environments and deployment pipelines to ensure any risks have been identified and actioned before the code reaches the production stage.
Both in-house and outsourced development teams should be able to follow your direction when it comes to the policies you define to increase the security of your organization's developed software. Sometimes, outsourced teams have their own processes and solutions in place to provide the same level of assurance that you require, and other times you might need to reach an agreement to mitigate against any gaps.
With that, let's look at ways we can improve the security of our in-house software.
Software development life cycle
First, we want to implement the controls previously discussed in this chapter for the secure SDLC. These policies, procedures, and tools are able to ensure the efficient and secure development of high-quality software by your teams. You can design the SDLC to reflect your organization's risk tolerance and the idiosyncrasies of your existing processes, but staying in line with the general ideologies will help you in your quest.
With that, I don't believe it's necessary to cover all of the steps we've already covered earlier in this chapter, so instead, I would like to go into how we might implement practical controls to achieve the high-level goals we've previously covered.
Code repositories
Your organization likely uses a code repository solution to store and version-control any developed software. Examples of code repositories could include GitHub, Bitbucket, or GitLab, among others.
Inside these tools, we have various available features and controls that ensure our requirements for the SDLC are met. For example, issue trackers allow a transparent discussion between developers, product team members, and other stakeholders on software bugs, feature requests, vulnerability discoveries, and so on. These issue trackers allow teams to estimate requirements, assign priorities, and give complexity scores to each issue, to help organize how they might be handled.
There are what are known as branches, which allow developers to actively develop and make changes to software in a development context, without affecting the main branch, which is used for production, or even potentially a development branch for the current sprint. You want to protect this branch from change without various forms of sign-off, which you can arrange to include code reviews, testing, and ensuring the merge is following the separation-of-duties and two-man principles.
Each change to the code is documented and attributed to the associated software engineer, allowing transparent audit processes and clear documentation of all approvals. All commits can be signed using public-key cryptography, providing non-repudiation and integrity for each engineer's incremental contribution to the codebase.
Additionally, if we take into consideration the ideology of infrastructure as code that we previously covered, it's possible to store the configuration files for your organization's servers and tools in repositories and apply the same level of scrutiny as you would over the software that is being developed.
DevSecOps pipelines
Continuous Integration and Continuous Delivery (CI/CD) pipelines provide the automation flow aspect to ensuring only software that meets the specified requirements is able to be deployed to the next stage of the process, and by relying on the pipeline you are able to reduce developer and systems administrator access down to least-privilege, meaning they are not able to access or change production systems without following the pipeline and getting appropriate approval.
Quite often, these pipelines are related to the term DevSecOps, in which we bake security into the DevOps life cycle through automation and pipelines.
Let's imagine this pipeline flow for your organization's software development process:
- A software developer uses their SSH key to access a project's Git repository, creates a "feature branch" off from the development code, and clones the code to their workstation for local development.
- Their Interactive Development Environment (IDE) references secure coding paradigms, as well as performing regex checks for plaintext secrets and passwords, immediately informing the developer if any flaws are found in real time, allowing them to remediate before committing their code back to the repository and triggering a pipeline process.
- The developer makes a change and attempts to commit that code back to the Git branch they created. Their access is checked to ensure they're allowed to do so, their change is logged, and differences are highlighted in the Git solution.
- The CI pipeline runs and performs the following checks:
- A dependency scanner assesses the risk profile of any imported software.
- Static code analysis is performed by a SAST to check for the code's quality and any security risks.
- A secrets checker looks for secrets and passwords stored in the code.
- A container auditor checks for any vulnerabilities in the defined infrastructure as code.
- An ephemeral version of the updated software is deployed into a test environment, and a DAST performs the appropriate checks on the software, looking for errors, security vulnerabilities, and performance issues.
- If all automated systems pass, then another developer is notified via email or chat, and they perform a code review.
- If the code review is approved, a tester is notified, and the feature is tested by a human.
- If all steps are approved, the code is merged and the CD pipeline runs to implement the change into the next environment.
This process requires careful implementation and defined processes and expectations for the various team members involved but could lead to a streamlined, secure development process with automation at its core.
Summary
In this chapter, we covered the highly interesting topic of improving the security of software and highlighted various methodologies we could use to ensure the software used inside our organization's estate is "secure enough" from a risk perspective.
To begin the chapter, we went into a few universal paradigms for software security, including the SDLC, and the steps required for that process to be an effective undertaking.
After that, we highlighted that we put a lot of faith into software systems developed by third parties, especially when the processes under which they are developed are opaque, such as when we procure software from a vendor that doesn't disclose their approach when it comes to security. We delved into how we might better understand the risk presented by third-party software, either as proprietary solutions or in the context of the open source model.
From that, we went into how we can utilize our knowledge of the SDLC to produce better software in-house, with testing and automation at the heart of the solution to ensure scalability and efficiency in finding vulnerabilities, which could lead to a loss of confidentiality, integrity, or availability.
Overall, what we learned from this chapter was what to look for when you are establishing your requirements, policies, and procedures surrounding software development and use in your organization. With this knowledge, you're able to accurately measure the risk presented and respond to any residual risk that is deemed to be above the acceptable risk tolerance.
With that, you have now completed this book. Thank you so much for taking the time to read it! I hope you had fun and learned a few things along the way. If I was able to help you with your organization's security posture, I am delighted.
I would like to take this opportunity to thank my wife, Helen, for her support and care along the way. Furthermore, I would like to thank all of the members of the Packt team who have supported me in the creation of this book, from beginning to end.