
(2.80)
(2.81)
where ![]() is the state vector of system,
is the state vector of system, ![]() is the control input vector,
is the control input vector, ![]() is the external input vector,
is the external input vector, ![]() and
and ![]() are the control output vector and the measured output vector, respectively, which are similar to the
are the control output vector and the measured output vector, respectively, which are similar to the ![]() in Eq. (2.5). The design of controller mainly involves two aspects: one is the controller should make the system asymptotically stable, the other is to make the H∞-norm of the sensitivity function (transfer function) minimum. The controller can be designed as the following:
in Eq. (2.5). The design of controller mainly involves two aspects: one is the controller should make the system asymptotically stable, the other is to make the H∞-norm of the sensitivity function (transfer function) minimum. The controller can be designed as the following:
(2.82)
where ![]() is a gain matrix.
is a gain matrix.

To obtain the transfer function matrix of the system, the measured output vector ![]() is substituted into Eq. (2.82), then Eq. (2.82) is rewritten as:
is substituted into Eq. (2.82), then Eq. (2.82) is rewritten as:
(2.83)
Substituting Eq. (2.83) into Eq. (2.79) and Eq. (2.80), the state-space equations of the controlled system and the controller can be written as:
(2.84)
(2.85)
where ![]() ,
, ![]() ,
, ![]() ,
, ![]() . So, the transfer function matrix of system
. So, the transfer function matrix of system ![]() can be given by:
can be given by:
(2.86)
Thus the H∞-norm of the transfer function matrix is defined as:
(2.87)
where ![]() is the maximum singular value of the transfer function. For the single-input single-output system, the maximum singular value of the transfer function is the maximum modules amplitude of transfer function.
is the maximum singular value of the transfer function. For the single-input single-output system, the maximum singular value of the transfer function is the maximum modules amplitude of transfer function.
2.6.2 H∞ Feedback Control
The infimum of the H∞-norm set of the transfer function of controllers that ensure the closed-loop system stable is expressed as:
(2.88)
If a controller can ensure the closed-loop system stable and ![]() , the controller is defined as
, the controller is defined as ![]() suboptimal controller.
suboptimal controller.
Generally, the measurements of all of the states of the controlled system are unrealizable, so the controller is designed based on the static output feedback approach. In any given case ![]() , the controller can be designed as:
, the controller can be designed as:
(2.89)
(2.90)
where ![]() is the state vector of the controller.
is the state vector of the controller.
(2.91)
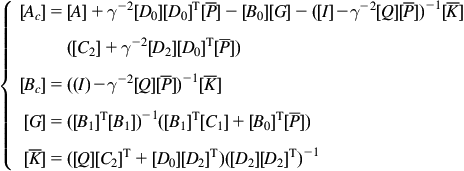 (2.91)
(2.91)The matrixes ![]() and
and ![]() are the semi-positive definite solutions of the following Riccati matrix equations:
are the semi-positive definite solutions of the following Riccati matrix equations:
(2.92)
(2.93)
Sometimes, the measurements of all of the states of the controlled system are realizable, so the control is designed based on the full state feedback approach, and the controlled system and the controller are expressed as:
(2.94)
(2.95)
(2.96)
The full state feedback controller is designed as:
(2.97)
where ![]() is the positive-definite solution of the following Riccati equation:
is the positive-definite solution of the following Riccati equation:
(2.98)
 (2.98)
(2.98)The excellent robustness is an advantage of ![]() feedback control in the intelligent control of civil engineering structures. In addition, the operation of
feedback control in the intelligent control of civil engineering structures. In addition, the operation of ![]() feedback control is relatively simple, and the only problem is the selection of the transfer function matrix of the controlled structure.
feedback control is relatively simple, and the only problem is the selection of the transfer function matrix of the controlled structure.
2.7 Sliding Mode Control
SMC method is widely applied into the control of variable structures, and the core of SMC is that the motion of the structure needs to tend to the defined sliding surface [44,45]. Meanwhile, the motion of the structure on the sliding surface defined is asymptotically stable. The SMC has an excellent robustness for the external excitation and the parameter perturbations of system, and many random disturbances and inevitable uncertainties exist in the process of structural vibration control. Therefore the SMC is more effective in control of both linear structures and nonlinear structures. Generally, the design of the SMC is determined by two aspects: the sliding surface and the controller.
2.7.1 Design of Sliding Surface
The equation of the linear time-invariant system can be expressed as Eq. (2.62), and the sliding surface can be designed as the linear combination of the state vectors of the system:
(2.99)
where ![]() is a
is a ![]() matrix, which determines the stability and performance of the sliding mode, and the design of the sliding surface is to find the matrix
matrix, which determines the stability and performance of the sliding mode, and the design of the sliding surface is to find the matrix ![]() . The
. The ![]() can be designed based on the LQR algorithm or the pole assignment algorithm, when the control is the full state feedback. If the static output feedback control is adopted,
can be designed based on the LQR algorithm or the pole assignment algorithm, when the control is the full state feedback. If the static output feedback control is adopted, ![]() can be designed based on pole assignment algorithm. Here the LQR algorithm is selected to design the sliding surface.
can be designed based on pole assignment algorithm. Here the LQR algorithm is selected to design the sliding surface.
Firstly, the state vector of the system is conducted by a linear transformation:
(2.100)
where ![]() is a state-transition matrix, which can be expressed as:
is a state-transition matrix, which can be expressed as:
![]() ,
, ![]() ,
, ![]() ;
; ![]() is the position matrix of installed controllers, which is rewritten as partition form,
is the position matrix of installed controllers, which is rewritten as partition form, ![]() matrix
matrix ![]() and
and ![]() matrix
matrix ![]() . The former represents the position where controllers are not installed, the latter represents the position where p controllers are installed and is a nonsingular matrix. If the external load is ignored, the state equations of a system and sliding surface can be rewritten as:
. The former represents the position where controllers are not installed, the latter represents the position where p controllers are installed and is a nonsingular matrix. If the external load is ignored, the state equations of a system and sliding surface can be rewritten as:
(2.101)
(2.102)
where ![]() ,
, ![]() ,
, ![]() . In order to achieve the feedback mechanism, the matrixes and vector in Eqs. (2.101) and (2.102) are rewritten as partition form:
. In order to achieve the feedback mechanism, the matrixes and vector in Eqs. (2.101) and (2.102) are rewritten as partition form: ![]() ,
, ![]() ,
, ![]() .
.
Then the state equations of system and sliding surface can be expressed as:
(2.103)
(2.104)
In order to simplify the derivation, the ![]() is assumed as a unit matrix, then:
is assumed as a unit matrix, then:
(2.105)
(2.106)
Assuming that all of the states are measured, the performance index of the system is given by:
(2.107)
where ![]() is a positive definite weighting matrix. The performance index of the system can be expressed by
is a positive definite weighting matrix. The performance index of the system can be expressed by ![]() after a further transformation:
after a further transformation:
(2.108)
where  .
.
In order to minimize the above performance index and satisfy the constraint, ![]() is expressed by the feedback state
is expressed by the feedback state ![]() based on the maximum principle:
based on the maximum principle:
(2.109)
where ![]() is the solution of the following Riccati equation:
is the solution of the following Riccati equation:
(2.110)
 (2.110)
(2.110)
where ![]() . So far, the sliding surface can be identified as
. So far, the sliding surface can be identified as
(2.111)
(2.112)
2.7.2 Design of Controller
The design of the controller is the second phase of SMC design, and the aim is to make the state of the system tend to the sliding surface and keep stable on the surface. Here the controller is designed based on the Lyapunov direct method.
Setting Lyapunov function as follows:
(2.113)
The sufficient condition to ensure the system performance stable on sliding surface is:
(2.114)
Substituting Eq. (2.5) into Eq. (2.114), then
(2.115)
 (2.115)
(2.115)
According to the above sufficient condition in Eq. (2.114), the control force derived from ith controller can be designed as
(2.116)
 (2.116)
(2.116)
where Wi is a given smaller constant, ![]() . Considering the maximum driving force of the actuator, the final control force is given by:
. Considering the maximum driving force of the actuator, the final control force is given by:
(2.117)
 (2.117)
(2.117)
The SMC is conducted by the above operation in civil engineering structures, in which the sliding surface can be defined as the linear combination of the state vectors of the controlled structure, and the controller can be designed through the Lyapunov direct method or the other control laws. Generally, the SMC is applied to the control that the parameters of the controlled system constantly change, such as the semi-active variable stiffness and variable damping controls.
2.8 Optimal Polynomial Control
The canonical theory in the stochastic optimal control of structures is subjected to an open challenge to the practical nonstationary, non-Gaussian white noise excitation system, such as earthquake ground motions, strong winds and sea waves which are usually encountered in civil engineering structures. For replying this challenge, a physical approach to structural stochastic optimal controls, i.e., OPC, has been proposed. Compared with nonlinear optimal control methods, such as instantaneous optimal control, SMC, generalized optimal control, etc. the OPC is considered as one of the preferred methods for nonlinear systems [46].
2.8.1 Basic Principle
The physical stochastic optimal control is implemented by solving a collection of deterministic dynamic equations corresponding to the representative realizations with preassigned weights [47]. Hence it is spontaneous to develop a nonlinear stochastic optimal control strategy by integrating a physical stochastic control scheme and a deterministic nonlinear optimal control theory. According to the original physical scheme, the nonlinear stochastic optimal control strategy can be performed and optimized as follows [48]. Firstly, for each representative realization of stochastic parameters, the minimization of a cost function is executed to build a functional mapping from the set of parameters of control policy to the set of control gains. Then the specified parameters of control policy are obtained by minimizing a performance function related to the objective structural performance, as well as the corresponding control gain. The content mentioned above is the fundamental theory of stochastic optimal polynomial.
In Section 2.1, the motion equation of the structural system with a finite number n degrees of freedom under dynamic loads has been given as Eq. (2.1), which can be expressed as the following after mathematical simplification
(2.118)
where ![]() is an n-dimensional displacement vector;
is an n-dimensional displacement vector; ![]() is an r-dimensional control force vector;
is an r-dimensional control force vector; ![]() is a
is a ![]() mass matrix;
mass matrix; ![]() is a n-dimensional vector denoting nonlinear internal forces, including a nonlinear damping force and a nonlinear restoring force;
is a n-dimensional vector denoting nonlinear internal forces, including a nonlinear damping force and a nonlinear restoring force; ![]() is a p-dimensional random excitation vector, in which
is a p-dimensional random excitation vector, in which ![]() represents a point in the probability space, i.e., an embedded basic random event characterizing the randomness inherent in the external excitation.
represents a point in the probability space, i.e., an embedded basic random event characterizing the randomness inherent in the external excitation. ![]() denotes a random parameter vector mapped from
denotes a random parameter vector mapped from ![]() , which implicitly underlies the state and control force vectors.
, which implicitly underlies the state and control force vectors. ![]() is a
is a ![]() matrix denoting the location of controllers;
matrix denoting the location of controllers; ![]() is a
is a ![]() matrix denoting the location of excitations.
matrix denoting the location of excitations.![]() and
and ![]() are the initial displacement and initial velocity, respectively.
are the initial displacement and initial velocity, respectively.
The classical OPC theory was proposed on the basis of Hamilton–Jacobi theoretical framework and the optimal principle [49], which is essentially the extended formulation of the LQR control in state space. In order to express Eq. (2.118) as the form of its state equation, the nonlinear internal force ![]() needs to be expanded. It is usually expressed as the following Maclaurin series:
needs to be expanded. It is usually expressed as the following Maclaurin series:
(2.119)
 (2.119)
(2.119)
where ![]() is the highest order of the Maclaurin series, and is equal to the order of the nonlinear internal force, indicating that the terms of series with
is the highest order of the Maclaurin series, and is equal to the order of the nonlinear internal force, indicating that the terms of series with ![]() and the higher-order parts are zero. Meanwhile, the zero order terms and the
and the higher-order parts are zero. Meanwhile, the zero order terms and the ![]() cross terms which make little contribution to the nonlinear internal force of engineering structure are omitted.
cross terms which make little contribution to the nonlinear internal force of engineering structure are omitted.
The state-space equation has been given as Eq. (2.5), with the initial state ![]() ;
; ![]() is same as
is same as ![]() ; and
; and ![]() can be expressed as the following after mathematical deformation:
can be expressed as the following after mathematical deformation:
(2.120)
 (2.120)
(2.120)
A polynomial cost function, in stochastic case with ![]() [50], is given by
[50], is given by
(2.121)
 (2.121)
(2.121)
where ![]() is the terminal cost;
is the terminal cost; ![]() is the terminal state;
is the terminal state; ![]() and
and ![]() are the start and terminal time, respectively;
are the start and terminal time, respectively; ![]() is a
is a ![]() positive semi-definite matrix denoting state weighting;
positive semi-definite matrix denoting state weighting; ![]() is a
is a ![]() positive-definite matrix denoting control weighting;
positive-definite matrix denoting control weighting; ![]() is the higher-order term of the cost function whose order is higher than the quadratic term.
is the higher-order term of the cost function whose order is higher than the quadratic term.
The minimization of the polynomial cost equation will result in the celebrated Hamilton–Jacobi–Bellman equation [51]:
(2.122)
where the optimal cost function ![]() satisfies all the properties of a Lyapunov function, considered as [51]
satisfies all the properties of a Lyapunov function, considered as [51]
(2.123)
where ![]() is a
is a ![]() Riccati matrix [48];
Riccati matrix [48]; ![]() is a positive-definite multinomial in
is a positive-definite multinomial in ![]() . The Hamiltonian function
. The Hamiltonian function ![]() is defined by [50]
is defined by [50]
(2.124)
 (2.124)
(2.124)
The necessary condition for the minimization of the right-hand side of Eq. (2.122) is
(2.125)
The optimal nonlinear controller is then given by
(2.126)
To express the controller Eq. (2.126) as an explicit function, ![]() is chosen as the following [50]
is chosen as the following [50]
(2.127)
where ![]() ,
, ![]() are
are ![]() Lyapunov matrices [49].
Lyapunov matrices [49].
Both ![]() and
and ![]() are related to the gradient matrix
are related to the gradient matrix ![]() . Therefore the gain matrices of the polynomial controller cannot be calculated off-line. An approximate solution to the gain matrices is obtained by linearizing the gradient matrix
. Therefore the gain matrices of the polynomial controller cannot be calculated off-line. An approximate solution to the gain matrices is obtained by linearizing the gradient matrix ![]() at the initial equilibrium point
at the initial equilibrium point ![]() [50], i.e., replacing
[50], i.e., replacing ![]() into
into ![]() . Furthermore, the Riccati matrix
. Furthermore, the Riccati matrix ![]() and the Lyapunov matrices
and the Lyapunov matrices ![]() , for a class of optimal control system with time infinite, could be approximately evaluated as constant matrices (
, for a class of optimal control system with time infinite, could be approximately evaluated as constant matrices (![]() and
and ![]() ) by solving the following algebraic Riccati and Lyapunov equations, i.e., the steady-state Riccati and Lyapunov matrix equations, respectively
) by solving the following algebraic Riccati and Lyapunov equations, i.e., the steady-state Riccati and Lyapunov matrix equations, respectively
(2.128)
(2.129)
where ![]() .
.
Eqs. (2.128) and (2.129) can be solved using any well-known numerical algorithms or by virtue of computing software, e.g., MATLAB.
Hence an optimal polynomial controller can be obtained analytically in the form
(2.130)
Eq. (2.130) indicates that the polynomial controller consists of two components, the linear term which is the first order and the nonlinear term which is the odd higher order.
2.8.2 Applications
As an extended conventional LQR, OPC provides more flexibility in the control design and further enhances system performance. Under strong earthquakes, the main objective of intelligent control is to reduce the peak (maximum) response of the structure in order to minimize the damage. For both linear and nonlinear or hysteretic structures, it has been shown that the polynomial controller is more effective than the classical linear controller in suppressing the peak response, due to its ability to provide large control force under strong earthquakes [50,52].
At present, the optimal polynomial controller is widely applied in the control of highly nonlinear or inelastic hybrid protective systems, such as the base-isolated building using lead-core rubber bearings and the fixed-base yielded building. The performances of the optimal polynomial controller with respect to various control objectives are investigated by means of numerical simulations [50]. The results have shown obvious advantages of the optimal polynomial controller in the field of structural vibration control.
2.9 Fuzzy Control
In the field of traditional control, whether the dynamic model of the control system is accurate or not directly dominates the calculation results. The more detailed the dynamic information of the control system is, the easier to achieve the purpose of precise control. However, for complex systems, it is often very difficult to describe the dynamic characteristics of the systems accurately due to too many variables. Thus engineers always use various methods to simplify the dynamic characteristics of the systems to achieve the control purpose, while the result is still not ideal. In other words, the traditional control theory can deal with the relatively simple systems very well, but it will be unideal or powerless for the systems which are very complicated or difficult to be described accurately. The control strategies introduced in the previous sections belong to the traditional control strategies, and they can achieve good control effects in their applicable conditions. But civil engineering structures are complicated systems with the characteristics of strong nonlinear, time-varying and time-delay, so it is difficult to establish their accurate models. Fuzzy control is the combination of fuzzy logical theory and the control technology, which is essentially a kind of nonlinear control and belongs to the category of intelligent control. The fuzzy control algorithm does not need the accurate mathematical model of controlled systems, and can achieve real-time control, according to the input and output data of the actual system and the expert's knowledge or operating experience. The fuzzy control method will be introduced in this section in detail.
2.9.1 Basic Principle
The core of fuzzy control method is the fuzzy controller. The fuzzy controller mainly includes three parts: fuzzification, fuzzy reasoning, and defuzzification, and its basic structure is shown in Fig. 2.3.

A fuzzification of mathematical concepts is based on a generalization of these concepts from characteristic functions to membership functions. That is, fuzzification of accurate input values means the external excitation acquired by computer sampling is translated into the membership functions. The purpose of fuzzification is to change the variable type such that it can be accepted and operated by the knowledge base.
The formation and reasoning of fuzzy rules are based on the control rules which are designed by the experienced operator or expert. A fuzzy output set is obtained by fuzzy reasoning, namely a new fuzzy membership function. The purpose of fuzzy reasoning is to adapt the control rules, determine the fitness of each control rules, and then the outputs are gained by fuzzy rules weighted.
The output value can be obtained by defuzzification according to the output fuzzy membership function, and different methods can be used to find a representative accurate value as the control value. The purpose of defuzzification is to obtain the accurate output value, which can be applied to the actuator to realize control.
2.9.2 Design of Fuzzy Controller
The design of fuzzy controller mainly consists of the following parts.
2.9.2.1 Determination of the basic domain
After the input and output variables of the fuzzy controller are chosen, the basic domain should be determined subsequently. For the determination of basic domain of input variables, it should be determined according to the characteristics of the whole controlled systems. The choice of the basic domain is very important. If the basic domain is too small, the normal data may exceed the threshold and will influence the performance of the system, such as, oscillation, amplification, and even divergence. On the contrary, if the field is too large the system responses will be slow, the output of the system cannot converge quickly to the expected value. At the same time, the basic domain of the output value is also very important. If the domain is too large, the invalid area will be enlarged and lead to the oscillation of the system responses. If the domain is too small, the time of the system response will be extended and maybe cannot meet expectations.
2.9.2.2 Fuzzification of the accurate value
For the fuzzy controller, the input and output values must be fuzzy values. However, the input and output values of the actual controlled systems all are accurate values. Thus the fuzzification method should be employed to transform the accurate value to the fuzzy values. This process can be divided into two steps, the first step is to determine the fuzzy domain, and the second step is fuzzification.
The following formula can be adopted to transform the basic domain into the fuzzy fiedomain,
(2.131)
where ![]() and
and ![]() are accurate variable and fuzzy variable, respectively;
are accurate variable and fuzzy variable, respectively; ![]() is the basic domain of
is the basic domain of ![]() ;
; ![]() is the fuzzy domain of
is the fuzzy domain of ![]() ; and
; and ![]() is a positive integer which is larger than 2. In fact, Mamdani method often is used, i.e.,
is a positive integer which is larger than 2. In fact, Mamdani method often is used, i.e., ![]() . In addition, then variable
. In addition, then variable ![]() in the domain
in the domain ![]() also can be transformed into the asymmetric domain
also can be transformed into the asymmetric domain ![]() , where
, where ![]() and
and ![]() are both positive integers which are larger than 2. The transformation formula is as follows:
are both positive integers which are larger than 2. The transformation formula is as follows:
(2.132)
Fuzzification is to divide the continuous quantity in fuzzy domain into several levels, according to the requirement, each level can be regarded as a fuzzy variable and corresponds to a fuzzy subset or a membership function. Usually, the fuzzy domain can be divided into the following the fuzzy subsets described as language variable: [NB (negative big), NM (negative middle), NS (negative small), Z (zero), PS (positive small), PM (positive middle), PB (positive big)], respectively.
2.9.2.3 Parameter selection
The parameters of fuzzy controller mainly include quantization factor and proportional factor. In order to transform the accurate value from basic domain into the corresponding fuzzy domain, the quantization factors should be employed, e.g., error quantization factor ![]() and the error rate quantization
and the error rate quantization ![]() . In addition, the control value deduced from the fuzzy control algorithm cannot be used to control systems directly, and it should be transformed into the basic domain. Thus the proportion factor
. In addition, the control value deduced from the fuzzy control algorithm cannot be used to control systems directly, and it should be transformed into the basic domain. Thus the proportion factor ![]() should be employed.
should be employed.
The quantization factors and the proportion factors dominate the performance of fuzzy controller directly. Taking the dynamic property of the system, e.g., the larger the quantization factor, the larger the overshoot and the transition process of the system. The reason is that the basic domain will be narrow with the increasing of ![]() , the control effect of the error variance will increase, which will lead to the overshoot phenomenon and the extension of the transition process. If the error rate quantization
, the control effect of the error variance will increase, which will lead to the overshoot phenomenon and the extension of the transition process. If the error rate quantization ![]() is chosen comparatively larger, the system overshoot will be small and the system response time will be extended. As for the static performance of the system, the increase of quantization factor
is chosen comparatively larger, the system overshoot will be small and the system response time will be extended. As for the static performance of the system, the increase of quantization factor ![]() and
and ![]() can reduce the steady-state error and the error rate, but the steady-state error cannot be eliminated. The small output proportion factor
can reduce the steady-state error and the error rate, but the steady-state error cannot be eliminated. The small output proportion factor ![]() will extend the dynamic process, while large
will extend the dynamic process, while large ![]() will lead to the oscillation of the system.
will lead to the oscillation of the system.
2.9.2.4 Selection of the membership function
The membership function is the characteristic function of the fuzzy set, and it is the basis to solve practical problem using the fuzzy theory. Thus it is very important to select an appropriate membership function, and the following principles should be considered.
1. The shape of the membership function has direct influence on the system stability, which is usually restricted to the convex fuzzy set. The functions with high resolution are usually adopted in the areas with small error to increase the sensitivity; while the functions with comparatively low resolution are usually used in the large error areas to guarantee the satisfying robustness of the system.
2. The membership function should comply with the semantic sequence to avoid inappropriate overlap, and the overlap degree directly influences the performance of the system.
3. The distributions of the membership functions are always symmetric and balanced.
2.9.2.5 Determination of the rule base
The essence of the fuzzy control rules is summarizing the experience of the operator or the knowledge of the experts to form the control rules, which consists of the rule base.
The fuzzy rules should have the characteristics of ![]() completeness, consistency, and interaction. The
completeness, consistency, and interaction. The ![]() completeness characteristic means that a rule can be always found for each input state, which can match the output in a certain larger than
completeness characteristic means that a rule can be always found for each input state, which can match the output in a certain larger than ![]() . The consistency characteristic means that the formation of the fuzzy rule is based on the knowledge of the experts and the experience of the operator, and the rule can match different performance standard. For a complete rule base, if the input is
. The consistency characteristic means that the formation of the fuzzy rule is based on the knowledge of the experts and the experience of the operator, and the rule can match different performance standard. For a complete rule base, if the input is ![]() , and the expectable output is
, and the expectable output is ![]() , the actual control force is usually not equal to
, the actual control force is usually not equal to ![]() . In other word, taking R to represent the fuzzy relation, then the rules will have the interaction characteristics if they fit the following equation
. In other word, taking R to represent the fuzzy relation, then the rules will have the interaction characteristics if they fit the following equation ![]()
2.9.2.6 Defuzzification
The results of fuzzy reasoning are fuzzy set or membership functions, and they reflect the combination of different control languages. However, the controlled objective can only accept one control accurate quantity, thus one control accurate quantity should be chosen from the output fuzzy set. In other word, the method of defuzzification is to deduce a mapping from fuzzy set to the ordinary number set. The commonly used method are the coefficient weighted mean method, the gravity method, and the maximum membership degree method. These methods will be introduced as follows:
1. The coefficient weighted mean method
The output quantity of this method can be expressed as,
(2.133)
where ![]() is the output value of solving fuzzy,
is the output value of solving fuzzy, ![]() is the fuzzy input,
is the fuzzy input, ![]() is the coefficient; the selection of
is the coefficient; the selection of ![]() should depend on the actual condition, and different coefficients will result in different response characteristics.
should depend on the actual condition, and different coefficients will result in different response characteristics.
2. The gravity method
The gravity method means, that the gravity of the area enveloped by the fuzzy membership function curve and the output value is chosen as the abscissa. The following equation can be employed,
(2.134)
where ![]() is the fuzzy input, and
is the fuzzy input, and ![]() is the membership degree function. In the actual calculation process, the following simple equation is adopted,
is the membership degree function. In the actual calculation process, the following simple equation is adopted,
(2.135)
In addition, the gravity method is the special case of the coefficient weighted mean method, and they are same when ![]() .
.
The maximum membership degree method is one of the simplest methods, and only the element with the maximum membership degree is chosen as the output value. What is more, the curve of the membership function should be convex (unimodal curve). If the curve is flat trapezoid, the element with a maximum membership degree is larger than 1 and the average value should be adopted.
2.10 Neural Network Control
Neural network control method is a kind of mathematical model of the distributed parallel algorithm of information processing, which can imitate animal neural network behavior characteristics. This kind of network depends on the complexity of the system to achieve the purpose of processing information by adjusting the internal relations between a large number of nodes connected, and has the ability of self-learning, self-adaptive and self-organization. Neural networks have been used to solve problems in almost all spheres of science and technology. For civil engineering structures having the characteristics of strong nonlinear, time-varying and time-delay, neural network control algorithm can be used to identify the models of the controlled civil engineering structures, predict the responses of the structures, and so on. This section will focus on the basic theory of the neural network control method.
2.10.1 Basic Principle
The neural network is proposed by studying the human information according to the modern neurobiology and understanding science. It can be seen as a network which is composed of a large number of interconnected neurons (processing unit). The neural work has the characteristics of strong adaptability, learning ability, nonlinear mapping ability, robustness, and fault tolerance.
The neurons can transmit information, and their models can be classified as three parts: threshold unit, linear unit, and nonlinear unit. Once the model of neuron is determined, the performance and ability of a neural network will mainly depend on the topological structure and the learning method. The topological structures of neural networks are usually divided as
1. Feedforward network. The neurons of the network exist layer by layer, and each neuron is only connected to other neurons in the former layer. The top layer is the output layer, and the number of the hidden layer can be one or more. The feedforward network is widely used in the practical application such as sensors.
2. Feedback network. The network itself is a forward model. The difference between the feedforward and the feedback model is that the feedback network has a feedback loop.
3. Self-organizing network. The lateral inhibition and exciting mechanism of the neurons between the same layer can be realized through the interconnection of the neurons, thus the neurons can be classified into several categories, and each category can action as an integral.
4. Interconnection network. The interconnection network includes two categories: local interconnection and global interconnection. The neuron is connected to all the other neurons, while some of the neurons are not connected in the local interconnection network. The Hopfield network and the Boltzmann network belong to the interconnection network.
2.10.2 Learning Method
Once the topological structure of the neural network is determined, the learning method is indispensable to attribute the network with an intelligent characteristic, which is also the core problem in intelligent control using the neural network method. Through learning, neural networks can grasp the characteristics of intelligent or nonlinear structures. The learning method is actually the adjusting method of the weight of network connection. There are three major learning paradigms, each corresponding to a particular abstract learning task. These are supervised learning, unsupervised learning, and reinforcement learning. When the supervised learning model is used, the output of the network and the desired output signal (i.e., supervised signals) are compared, and then according to the difference the network's weights will be adjusted, finally differences will be smaller. When the unsupervised learning model is used, after the input signals are sent into the network, according to the present rules (such as competition rules), the network’s weights will be adjusted automatically, and the network will have pattern classification function eventually. The reinforcement learning method is a kind of learning method between the above two. There are several basic learning methods such as Hebb learning the rules, Delta (δ) learning rules, Probability learning rules, Competition learning rules and Levenberg–Marquart algorithm, and so on. As an example of learning methods, the commonly used Levenberg–Marquart algorithm will be introduced in the following.
Levenberg–Marquart algorithm belongs to the supervised learning model. When the output value ![]() is not equal with the expected output
is not equal with the expected output ![]() , the error signal will propagate from the output end in the reverse direction of the net, and the weight and threshold values are always modified to make the output value close to the desired output. When sample
, the error signal will propagate from the output end in the reverse direction of the net, and the weight and threshold values are always modified to make the output value close to the desired output. When sample ![]() is weight adjusted, it will be delivered to the other sample models for learning train until
is weight adjusted, it will be delivered to the other sample models for learning train until ![]() times are completed.
times are completed.
The quadratic error function of the input and output modes of each sample ![]() is defined as,
is defined as,
(2.136)
Thus the error function of the whole system is,
(2.137)
 (2.137)
(2.137)For simplicity, the subscript ![]() is omitted in the following equations, and the PIF is chosen as the error function of the system, thus
is omitted in the following equations, and the PIF is chosen as the error function of the system, thus
(2.138)
where ![]() is the number of the output neuron,
is the number of the output neuron, ![]() is the error of the
is the error of the ![]() output neuron.
output neuron.
The weighting adjustment should be proceeded in the reverse direction of the gradient of function ![]() to make the output close to the desired value as far as possible. When Levenberg–Marquardt algorithm is employed in the training process of feedback neural network, the weighting matrix can be expressed as [53]
to make the output close to the desired value as far as possible. When Levenberg–Marquardt algorithm is employed in the training process of feedback neural network, the weighting matrix can be expressed as [53]
(2.139)
 (2.139)
(2.139)
where ![]() is the training steps,
is the training steps, ![]() is the descent gradient of the performance function
is the descent gradient of the performance function ![]() with respect to the weighting matrix
with respect to the weighting matrix ![]() ,
, ![]() is the control factor,
is the control factor, ![]() is the unit matrix, and the Jacobi matrix of the weighting value can be obtained by the Taylor series expansion of the error vector
is the unit matrix, and the Jacobi matrix of the weighting value can be obtained by the Taylor series expansion of the error vector ![]() ,
,
(2.140)
 (2.140)
(2.140)
where ![]() is the number of output neuron, and
is the number of output neuron, and ![]() is number of weighting value. Combining Eqs. (2.139) and (2.140) can obtain the following equation,
is number of weighting value. Combining Eqs. (2.139) and (2.140) can obtain the following equation,
(2.141)
Eq. (2.141) is the key equation of Levenberg–Marquardt algorithm. The application of intelligent control on civil engineering structures by using Levenberg–Marquardt algorithm and neural network can be seen in the study [54].
2.11 Particle Swarm Optimization Control
For vibration control, it is always the multiobjective optimization control. Firstly, the main control objective is to reduce the structural displacement responses to meet the request of anti-earthquake for civil engineering structures and the standard of civil engineering structures, and this objective is to ensure the safety of civil engineering structures. Secondly, the other control objective is to reduce structural acceleration responses, and this objective will influence the safety of furniture and decoration in civil engineering structures. The particle swarm optimization algorithm belongs to swarm intelligence, and it is a kind of probability search algorithm with the following advantages: (1) there are not centralized control constraints. That is, individual fault cannot affect the whole problem solving, which will ensure the systems having stronger robustness. (2) The method of the nondirect communication is used to ensure the scalability of the systems. (3) The parallel distributed algorithm model is used, which can make the best of multiple processors. (4) There are no special requirements for the continuity of the problem definition. (5) The algorithm is simple, and it is easy to implement. Especially, the multipoint parallel search feature of the PSO algorithm makes it not only suitable for single objective optimization control, and also it can be applied to multiobjective optimization control.
2.11.1 Basic Principle
In 1995, based on the idea of a bird flock foraging, James Kennedy, American social psychologist, and Russell Eberhart, electrical engineer, proposed the PSO algorithm [55–59]. That is, the birds in the bird flock are abstracted as “particles” without mass and volume, and these “particles” will mutually collaborate and share information to update their current movement velocity and direction according to their own and swarm’s best historical movement state information. This kind of method can well coordinate the movement relationship between the particles themselves and swarm, and look for the optimal solution in the complex solution space. The following, the basic PSO algorithm and the improved PSO algorithms will be described.
2.11.1.1 The basic PSO algorithm
Assuming that,
![]() is the current position of the
is the current position of the ![]() particle;
particle;
![]() is the current velocity of the
is the current velocity of the ![]() particle;
particle;
![]() is the optimal position once experienced of the
is the optimal position once experienced of the ![]() particle, and the optimal position stands for the optimal adaptive value. For the minimization problem, the smaller the objective value is, the better adaptive value is;
particle, and the optimal position stands for the optimal adaptive value. For the minimization problem, the smaller the objective value is, the better adaptive value is;
![]() is the optimal location of all particles of the swarm that experienced.
is the optimal location of all particles of the swarm that experienced.
The evolution equation of the basic PSO equation can be described as:
(2.142)
(2.143)
where subscript ![]() denotes the
denotes the ![]() dimension of the particles, subscript
dimension of the particles, subscript ![]() denotes the
denotes the ![]() particle of the swarm,
particle of the swarm, ![]() is the generation,
is the generation, ![]() is the cognitive learning coefficient,
is the cognitive learning coefficient, ![]() is the social learning coefficient, and
is the social learning coefficient, and ![]() and
and ![]() are the dependent random value within the range of
are the dependent random value within the range of ![]() .
.
There are three parts in Eq. (2.142). The first part is the former velocity of the particle, which makes the algorithm have the capability of global research. The second part (cognition part) means the process of the particle’s absorption of their own experience. The third part (social part) means the process of the particle absorption of the other particle. The model without the second part is called the social-only model, which converges quickly and may stick in the local optimal value for the complex problem. The model without the third part is called the cognition-only model, which cannot obtain the optimal value due to no contact between the individuals.
2.11.1.2 Improved PSO algorithm
As discussed above, the first part of Eq. (2.142) is to guarantee the global converging ability of the PSO algorithm, and the last two parts are to guarantee the local converging ability. Different balance relations exist between the global searching ability and the local searching ability for different problems, and balance relations should also be modified at any moment, but the basic PSO algorithm does not have this ability. Thus Shi and Eberhart [60] proposed the PSO algorithm with inertial weight, and the evolution equation is
(2.144)
(2.145)
where ![]() is the inertia weight, which determines the influence degree of the former velocity on the current velocity, thus it can balance the effect of the global and local searching ability.
is the inertia weight, which determines the influence degree of the former velocity on the current velocity, thus it can balance the effect of the global and local searching ability. ![]() can be a positive constant, positive linear or nonlinear function with respect to time.
can be a positive constant, positive linear or nonlinear function with respect to time.
In order to control the flight speed to balance the effect of the global and local searching ability, Clerc [61] proposed the PSO algorithm with constriction factor in 1999, then Eberhart and Shi [62] simplified the expression for practical use in 2000. The velocity evolution equation can be written as:
(2.146)
(2.147)
 (2.147)
(2.147)
where ![]() is the constriction factor,
is the constriction factor, ![]() and
and ![]() .
.
In fact, the velocity evolution equation of the PSO algorithm with constriction factor at ![]() ,
,![]() ,
, ![]() , is same as the particle swarm algorithm with inertial weight at
, is same as the particle swarm algorithm with inertial weight at ![]() ,
, ![]() .
.
In order to overcome premature convergence, Riget and Vesterstrøm [63] proposed the ARPSO algorithm to improve the performance of the algorithm based on the PSO, and used the diversity to measure and control the swarm characteristics to avoid premature convergence. The “attractive” and “repulsive” operators are employed to increase the efficiency. The velocity evolution equation can be written as,
(2.148)
(2.149)
The diversity function of the swarm is,
(2.150)
 (2.150)
(2.150)
where ![]() is the upper limit of the target of the swarm diversity,
is the upper limit of the target of the swarm diversity, ![]() is the upper limit of the target of the swarm diversity,
is the upper limit of the target of the swarm diversity, ![]() is the number of the particles of the swarm,
is the number of the particles of the swarm, ![]() is the dimension,
is the dimension, ![]() is the
is the ![]() component of the
component of the ![]() particle, and
particle, and ![]() is the average value of the
is the average value of the ![]() components of all the particles.
components of all the particles.
During the operation of the algorithm, if the swarm diversity function satisfies ![]() , then
, then ![]() and the population will keep away from the optimal position; if the swarm diversity function increases and exceeds
and the population will keep away from the optimal position; if the swarm diversity function increases and exceeds ![]() , then
, then ![]() and the population will move close to the optimal position.
and the population will move close to the optimal position.
2.11.2 Design Procedure of the PSO Algorithm
For the different PSO algorithms, design steps are usually as follows:
1. To determine the problem representation scheme (coding scheme)
When the PSO algorithm is used to solve problems, firstly, solutions of the problems should be mapped from the solution space to the representation space with a certain structure, i.e., the solutions of the problems are expressed by specific code series. According to the feature of problems, appropriate coding method is selected, which will affect the result and the performance of the algorithm directly.
2. To determine the evaluation function of optimization problems
In the solving process, the adaptive value is used to evaluate the quality of the solution. When solving problems, therefore, according to the specific characteristics of the problem, the appropriate objective functions must be chosen to calculate the fitness. The fitness is the only parameter to reflect and guide the ongoing optimization process.
3. To choose the control parameters
The PSO parameters usually include the size of the particle group (the number of particles), the maximum number of iteration algorithm implementation, inertia coefficient, and the parameters of the cognitive, social and other auxiliary control parameters, etc. According to different algorithm models, the appropriate control parameters are selected, and the optimal performance of the algorithm is affected directly.
4. Flight model of particles
In PSO algorithm, the key is how to determine the speed of the particles. As the particles are described by multidimensional vector, the corresponding flight speed of particles can be described as a multidimensional vector. The speeds and directions of particles will be adjusted along each component direction dynamically in the process of flight by means of their own memories and social sharing information.
5. To determine of the termination criterion of the algorithm
The most common termination criterion of the particle swarm algorithm is setting a maximum flight algebra in advance, or terminating the algorithm when the fitness in successive generations has no obvious improvement during the search process.
6. Programming operation
Making program, according to the designed algorithm, and obtaining the solution of the specific optimization problem. The validity, accuracy, and reliability of the algorithm can be verified by evaluating the quality of the solution.
In intelligent control of civil engineering structures by using the PSO algorithm, the above design procedure is usually adopted. The numerical example about the intelligent control of civil engineering structures by using the PSO algorithm will be described in Section 8.5 in detail.
2.12 Genetic Algorithm
GA is an optimized search algorithm proposed based on natural selection and genetic mechanism. Compared to other intelligent control algorithms, such as the Fuzzy Logic and the Neural Network, the GA with self-adapting step size can search the best solution directly and more likely to the global optimum result. The GA provides an effective way to solve complex optimization problem in the field of structural vibration control. Moreover, the research on the combined application of the GA, the Fuzzy Logic and the Neural Network has drawn the attention of many researchers due to their complementary features.
2.12.1 Basic Principle
The GA is a search process based on natural selection and genetics, and usually consists of three operations: Selection, Genetic Operation, and Replacement, as shown in Fig. 2.4 [64].

A group of chromosomes constitutes the population of the GA cycle, and can be selected as candidates for the solutions of problems. Firstly, a population is generated randomly, and the objective function in a decoded form is calculated to analyze the fitness values of all chromosomes. Then a set of initial chromosomes is selected as the parents to generate offspring, according to the specified genetic operations, and a same fashion to the initial population is used to evaluate the fitness values of all the offspring. Finally, all the offspring will replace current chromosomes according to a certain replacement strategy.
The GA cycle will be performed repeatedly and terminated when a desired criterion (e.g., a predefined number of generations is produced) is reached. If all goes well throughout the simulated evolution process, the best chromosome in the final population can become a highly evolved solution.
2.12.2 Procedure of GA
Various techniques are employed in the GA process for encoding, fitness evaluation, parent selection, genetic operation, and replacement, which are introduced below.
2.12.2.1 Encoding scheme
The encoding scheme is a key issue in any GA because of its severe limitation on the window of information observed from the system [65]. In general, a chromosome representation, in which problem specific information is stored, is desired to enhance the performance of the algorithm. The GA evolves a multiset of chromosomes. The chromosome is usually expressed in a string of variables in binary [66], real number [67,68] or other forms, and its range is usually determined by specifying the problem.
2.12.2.2 Fitness techniques
The mechanism for evaluating the status of each chromosome can be mainly provided by the objective function, whose values vary from problem to problem. Therefore a fitness function is needed to map the objective value to a fitness value so that the uniformity over various problem domains can be maintained [64]. A number of methods can be used to perform this mapping, and two commonly used techniques are given as follows:
1. Windowing
Each chromosome can be assigned with a fitness value ![]() , which is proportional to the “cost difference” between chromosome
, which is proportional to the “cost difference” between chromosome ![]() and the worst chromosome. In mathematics, it is expressed as
and the worst chromosome. In mathematics, it is expressed as
(2.151)
where ![]() is the objective value of chromosome
is the objective value of chromosome ![]() ;
; ![]() is the objective value of the worst chromosome in the population; and
is the objective value of the worst chromosome in the population; and ![]() is a constant. The positive and negative signs in Eq. (2.151) are appropriate for the maximization and minimization problems, respectively.
is a constant. The positive and negative signs in Eq. (2.151) are appropriate for the maximization and minimization problems, respectively.
If the function is to be maximized or minimized, the chromosomes will be ranked in descending or ascending order according to their objective values. Given a raw fitness ![]() to the best chromosome, the fitness of
to the best chromosome, the fitness of ![]() chromosome can be derived from the following expression
chromosome can be derived from the following expression
(2.152)
where ![]() is the decrement rate.
is the decrement rate.
This technique ensures that the average objective value of the population is mapped into the average fitness.
2.12.2.3 Parent selection
Parent selection, which emulates the survival-of-the-fitted mechanism in nature, means that a fitter chromosome can receive a higher number of offspring and thus has a higher chance of surviving in the subsequent generation [64]. Although in many ways, such as ranking, tournament, and proportionate schemes can be used to achieve effective selection [69], the key assumption is to give preference to fitter individuals.
For example, in the proportionate scheme, the growth rate ![]() of chromosome
of chromosome ![]() with a fitness value
with a fitness value ![]() can be defined as:
can be defined as:
(2.153)
where ![]() is the average fitness of the population.
is the average fitness of the population.
2.12.2.4 Genetic operation
Crossover is a recombination operator that combines the subparts of two parent chromosomes to produce offspring that contain some parts of both parents' genetic material [64]. The crossover operator is deemed to be the determining factor that distinguishes the GA from all other optimization algorithms.
A number of variations on crossover operations are proposed, such as one-point crossover, multipoint crossover, and mutation. The diagram illustration of genetic operation is shown in Fig. 2.5.

Mutation is an operator that introduces variations into the chromosome. The operation occurs occasionally, but randomly alters the value of a string position.
2.12.2.5 Replacement strategy
Two representative strategies [64] can be used for old generation replacement after offspring generation:
1. Generational replacement
Each population of size n generates an equal number of new chromosomes to replace the entire old population.
2. Steady-state reproduction
Only a few chromosomes are replaced once in the population. In general, the new chromosomes inserted into the population will replace the worst chromosomes to produce succeeding generation.
Generally, the typical implementation procedure of the GA can be summarized as:
1. Randomly generate an initial population ![]()
2. Compute the fitness ![]() of each chromosome
of each chromosome ![]() in the current population
in the current population ![]() ;
;
3. Create new chromosomes ![]() by mating current chromosomes and applying mutation and recombination as the parent chromosomes mate;
by mating current chromosomes and applying mutation and recombination as the parent chromosomes mate;
4. Delete numbers of the population to make room for the new chromosomes;
5. Compute the fitness of ![]() , and insert them into population;
, and insert them into population;
6. ![]() , if not (end-test) go to step 3, or else stop and return the best chromosome.
, if not (end-test) go to step 3, or else stop and return the best chromosome.
Although the global optimum solution can be found easily using the GA, some derivative algorithm, such as the hybrid GA and the cooperative co-evolutionary GA, have been proposed because of its poor local search optimization ability and premature convergence and random walk, and are gradually replacing the traditional GA.
2.12.3 GA Control Realization
In general, the GA is used in combination with other intelligent algorithms in the field of structural vibration control. For example, the GA is widely used as an effective additional feedback algorithm in neural network models and is generally used to find optimal parameters for the fuzzy logic control [70].
The membership functions of input and output variables and the fuzzy control laws can be optimized using GA with the decimal encoding system of the gene. The GA based on the hierarchical structure can optimize weights (including nodes threshold) of neural network with a high learning efficiency. The global search of GA can be used to optimize the fuzzy neural network's parameters off-line. The capability of parallel search with the GA can be used to dynamically optimize the structural parameters of the Back Propagation (BP) network.
The GA optimization approaches for determination of the near-optimal layout of control devices and sensors have also been investigated to improve the active control efficiency of the civil structural system [70]. In practice, the GA is used to find optimal control forces for any time step under earthquake excitation, and dynamic fuzzy wavelet neuro emulator is created to predict structural displacement responses from immediate past structural response and actuator dynamics [71].