
Chapter 3
Voice in the User Interface
Andrew Breen, Hung H. Bui, Richard Crouch, Kevin Farrell, Friedrich Faubel, Roberto Gemello, William F. Ganong III, Tim Haulick, Ronald M. Kaplan, Charles L. Ortiz, Peter F. Patel-Schneider, Holger Quast, Adwait Ratnaparkhi, Vlad Sejnoha, Jiaying Shen, Peter Stubley and Paul van Mulbregt
Nuance Communications, Inc.
3.1 Introduction
Voice recognition and synthesis, in conjunction with natural language understanding, are now widely viewed as essential aspects of modern mobile user interfaces (UIs). In recent years, these technologies have evolved from optional ‘add-ons’, which facilitated text entry and supported limited command and control, to the defining aspects of a wide range of mainstream mobile consumer devices, for example in the form of voice-driven smartphone virtual assistants. Some commentators have even likened the recent proliferation of voice recognition and natural language understanding in the UI as the “third revolution” in user interfaces, following the introduction of the graphical UI controlled by a mouse, and the touch screen, as the first and second respectively.
The newfound prominence of these technologies is attributable to two primary factors: their rapidly improving performance, and their ability to overcome the inherent structural limitations of the prevalent ‘shrunken desktop’ mobile UI by accurately deducing user intent from spoken input.
The explosive growth in the use of mobile devices of every sort has been accompanied by an equally precipitous increase in ‘content’, functionality, services, and applications available to the mobile user. This wealth of information is becoming increasingly difficult to organize, find, and manipulate within the visual mobile desktop, with its hierarchies of folders, dozens if not hundreds of application icons, application screens, and menus.
Often, performing a single action with a touchscreen device requires multiple steps. For example, the simple act of transferring funds between a savings and checking accounts using a typical mobile banking application can require the user to traverse a dozen application screens.
The usability problem is further exacerbated by the fact that there exists great variability in the particular UIs of different devices. There are now many mobile device “form factors”, from tablets with large screens and virtual keyboards to in-car interfaces intended for eyes and hands-busy operation, television sets which may have neither a keyboard nor a convenient pointing device, as well as “wearable” devices (e.g., smart eyeglasses and watches). Users are increasingly attempting to interact with similar services – making use of search, email, social media, maps and navigation, playing music and video – through these very dissimilar interfaces.
In this context, voice recognition (VR) and natural language understanding (NLU) represent a powerful and natural control mechanism which is able to cut through the layers of the visual hierarchies, intermediate application screens, or Web pages. Natural language utterances encode a lot of information compactly. Saying, “Send a text to Ron, I'm running ten minutes late” implicitly specifies which application should be launched, and who the message is to be sent to, as well as the message to send, obviating the need to provide all the information explicitly and in separate steps. Similarly, instructing a TV to “Play the Sopranos episode saved from last night” is preferable to traversing the deep menu structure prevalent in conventional interfaces. These capabilities allow the creation of a new UI: a virtual assistant (VA), which interacts with a user in a conversational manner and enables a wide range of functionalities.
In the example above, the user does not need first to locate the email application icon in order to begin the interaction. Using voice and natural language thus makes it possible to find and manipulate resources – whether or not they are visible on the device screen, and whether they are resident on the device or in the Cloud – effectively expanding the boundary of the traditional interface by transparently incorporating other services.
By understanding the user's intent, preferences, and interaction history, an interface incorporating voice and natural language can resolve search queries by directly navigating to Web destinations deemed useful by the user, bypassing intermediate search engine results pages. For example, a particular user's product query might result in a direct display of the relevant page of her or his preferred online shopping site.
Alternately, such a system may be able to answer some queries directly by extracting the desired information from either structured or unstructured data sources, constructing an answer by applying natural language generation (NLG), and responding via speech synthesis.
Finally, actions which are difficult to specify in point-and-click interfaces become readily expressible in a voice interface, such as, for example, setting up a notification which is conditioned on some other event: “Tell me when I'm near a coffee shop.”
There are also other means of reducing the number of steps required to fulfill a user's intent. It is possible for users to speak their request naturally to a device without even picking it up or turning it on. In the so-called “seamless wake-up” mode, a device listens continuously for significant events, using energy-efficient algorithms residing on digital signal processors (DSP). When an interesting input is detected, the device activates additional processing modules in order to confirm that the event was a valid command spoken by the device's owner (using biometrics to confirm his or her identity), and it then takes the desired action.
Using natural language in this manner presupposes voice recognition which is accurate for a wide population of users and robust in noisy environments. Voice recognition performance has improved to a remarkable degree over the past several years, thanks to: an ever more powerful computational foundation (including chip architectures specialized for voice recognition); fast and increasingly ubiquitous connectivity, which brings access to Cloud-based computing to even the smallest mobile platforms; the development of novel algorithms and modeling techniques (including a recent resurgence of neural-network-based models); and the utilization of massive data sets to train powerful statistical models.
Voice recognition also benefits from increasingly sophisticated signal acquisition techniques, such as the use of steerable multi-microphone beamforming and noise cancellation algorithms to achieve high accuracy in noisy environments. Such processing is especially valuable in car interiors and living rooms, which present the special challenges of high ambient noise, multiple talkers and, frequently, background entertainment soundtracks.
The recent rate of progress on extracting meaning from natural utterances has been equally impressive. The most successful approaches blend three complementary approaches:
- machine learning, which discovers patterns from data;
- explicit linguistic “structural” models; and
- explicit forms of knowledge representation (“ontologies”) which encode known relationships and entities a priori.
As is the case for voice recognition, these algorithms are adaptive, and they are able to learn from each interaction.
Terse utterances can on their own be highly ambiguous, but can nonetheless convey a lot of information because human listeners apply context in resolving such inputs. Similarly, extracting the correct meaning algorithmically requires the application of a world model and a representation of the interaction context and history, as well as potentially other forms of information provided by other sensors and metadata. In cases where such information is insufficient to disambiguate the input, voice and natural language interfaces may engage in a dialog with the user, eliciting clarifying information.
Dialog, or conversation management, has evolved from early forms of “system initiative” which restricted users to only answering questions posed by an application (either visually, or via synthetic speech), to more flexible “mixed initiative” variants which allow users to provide relevant information proactively. The most advanced approaches apply formal reasoning – the traditional province of Artificial Intelligence (AI) – to eliminate the need to pre-define every possible interaction, and to infer goals and plans dynamically.
Whereas early AI proved to be brittle, today's state of the art systems rely on more flexible and robust approaches that do well in the face of ambiguity and produce approximate solutions where an exact answer might not be possible. The goal of such advanced systems is to successfully handle so-called “meta-tasks” – for example, requests such as “Book a table at Zingari's after my last meeting and let Tom and Brian know to meet me there”, rather than requiring users to perform a sequence of the underlying “atomic” tasks, such as checking calendars and making a reservation.
Thus, our broad view of the ‘voice interface’ is that it is, in fact, an integral part of an intelligent system which:
- interacts with users via multiple modalities;
- understands language;
- can converse and perform reasoning;
- uses context and user preferences;
- possess specialized knowledge;
- solves high-value tasks;
- is robust in realistic environments.
The elements of such a system, shown in Figure 3.1, are typically distributed across client devices and the cloud.
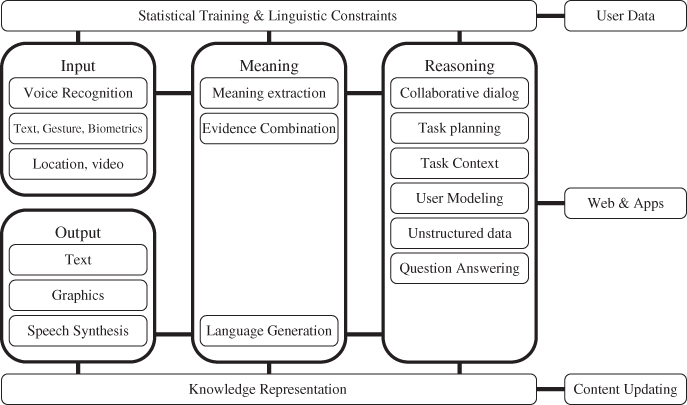
Figure 3.1 Intelligent voice interface architecture.
The reason for doing so includes optimizing computation, service availability, and latency, as well as providing users with a consistent experience across multiple clients with dissimilar characteristics and capabilities.
A distributed architecture further enables the aggregation of user data from multiple devices, which can be used to continually improve server- as well as device-specific recognition and NLU models. Furthermore, saving the interaction histories in a central repository means that users can seamlessly start an interaction on one device and complete it on another.
The following sections describe these concepts and the underlying technologies in detail.
3.2 Voice Recognition
3.2.1 Nature of Speech
Speech is uniquely human, optimized to allow people to communicate complex thoughts and feelings (apparently) effortlessly. Thus the ‘speech channel’ is heavily optimized for the task of human-to-human communication. The atomic linguistic building blocks of spoken utterances are called phonemes. These are the smallest units that, if changed, can alter the meaning of a word or an utterance. The physical manifestations of phonemes are “phones”; but a speech signal is not simply a sequence of concatenated sounds, like Morse code. We produce speech by moving our articulators (tongue, jaw, lips) in an incredibly fast and well-choreographed dance that creates a rapidly shifting resonance structure. Our vocal cords open and close between 100–300 times a second, producing a signal called the fundamental frequency or F0, which excites vocal tract resonances, resulting in a high bandwidth sound (e.g. 0–10 kHz).
At other times, the resonances are excited by turbulent noise created at constrictions in the vocal tract, such as the sound of [s]. The acoustic expression of a phoneme is not fixed but, rather, the realization is influenced by both the preceding as well as the anticipated subsequent phoneme – a phenomenon called coarticulation. Additional variability is introduced when speakers adjust their speech to the current situation and the needs of their listeners. The resulting speech signal reflects these moving articulators and sound sources in a complex and rapidly varying signal. Figure 3.2 shows a speech spectrogram of a short phrase.
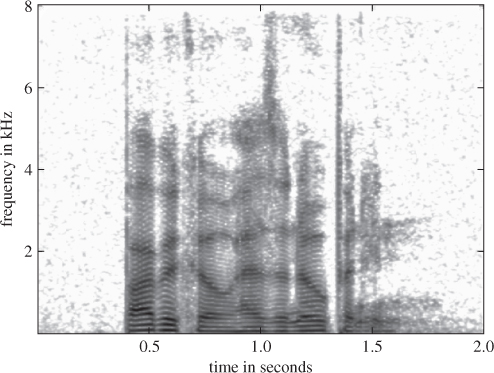
Figure 3.2 A speech spectrogram of the phrase “Barbacco has an opening”. The X-axis shows time, the Y-axis, frequency. Darkness shows the amount of energy in a frequency region.
Advances in speech recognition accuracy and performance are the result of thousands of person-years of scientific and engineering effort. Hence state-of-the-art recognizers include many carefully optimized, highly engineered components. From about 1990 to 2010, most state-of-the-art systems were fairly similar, and showed gradual, incremental improvements. In the following we will describe the fundamental components of a “canonical” voice recognition system, and briefly mention some recent developments.
The problem solved by canonical speech recognizers is typically characterized by Bayes' rule:
That is, the goal of speech recognition is to find the highest probability sequence of words, ![]() , given the set of acoustic observations,
, given the set of acoustic observations, ![]() . Using Bayes' rule, we get:
. Using Bayes' rule, we get:
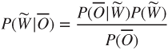
Note that ![]() does not depend on the word sequence
does not depend on the word sequence ![]() , so we want to find:
, so we want to find:
We evaluate ![]()
![]() using an acoustic model (AM), and
using an acoustic model (AM), and ![]() (
(![]() ) using a language model (LM).
) using a language model (LM).
Thus, the goal of most speech recognizers is to find the sequence of words with the highest joint probability of producing the acoustic observation, given the structure of the language.
It turns out that the system diagram for a canonical speech recognition system maps well onto this equation, as shown in Figure 3.3.
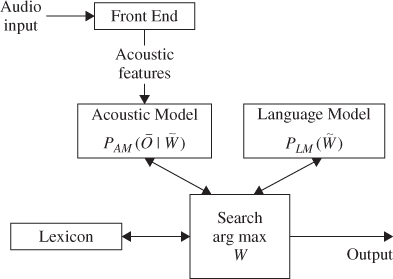
Figure 3.3 Components of a canonical speech recognition system.
The evaluation of acoustic probabilities is handled by the acoustic front-end and an acoustic model; the evaluation of probabilities of word sequences is handled by a language model; and the code which finds the best scoring word sequence is called the search component. Although these modules are logically separate, their application in speech recognition is highly interdependent.
3.2.2 Acoustic Model and Front-end
- Front-end: Incoming speech is digitized and transformed to a sequence of vectors which capture the overall spectrum of the input by an “acoustic front-end”. For years, the standard front-end was based on using a vector of mel-frequency cepstral coefficients (MFCC) to represent each “frame” of speech (of about 25 msec) [1]. This representation was chosen to represent the whole spectral envelope of a frame, but to suppress harmonics of the fundamental frequency. In recent years, other representations have become popular [2] (see below).
- Acoustic model: In a canonical system, speech is modeled as a sequence of words, and words as sequences of phonemes. However, as mentioned above, the acoustic expression of a phoneme is very dependent on the sounds and words around them, as a result of coarticulation. Although the context dependency can span several phonemes or syllables, many systems approximate phonemes using “triphones”, i.e., phonemes conditioned by their left and right phonetic context. Thus, a sequence of words is represented as a sequence of triphones. There are many possible triphones (e.g.
 ), and many of them occur rarely. Therefore the standard technique is to cluster them, using decision trees, [3], then create models for the clusters rather than the individual triphones.
), and many of them occur rarely. Therefore the standard technique is to cluster them, using decision trees, [3], then create models for the clusters rather than the individual triphones.
The acoustic features observed when a word contains a particular triphone are modeled as a Hidden Markov Model (HMM), [4] – see Figure 3.4. Hidden Markov models are simple finite state machines (FSMs), with states, transitions, and probabilities associated with the transitions. Also, each state is associated with a probability density function (PDF) over possible front-end vectors.
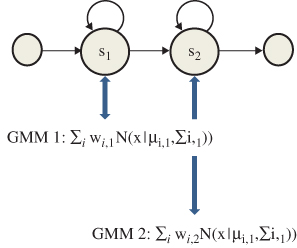
Figure 3.4 A simple HMM, consisting of states, probability distributions, and PDFs. The PDFs are Gaussian mixture models, which evaluate the probability of an input frame, given an HMM state.
The probability density function is usually represented as a Gaussian Mixture Model (GMM). GMMs are well studied, easily trained PDFs which can approximate arbitrary PDF shapes well. A GMM is a weighted sum of Gaussians; each Gaussian can be written as:
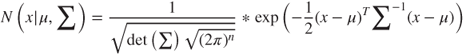
Where ![]() is an input vector,
is an input vector, ![]() is a vector of means, and
is a vector of means, and ![]() is the covariance matrix.
is the covariance matrix. ![]() and
and ![]() are vectors of length
are vectors of length ![]() , and
, and ![]() is a square matrix of dimension
is a square matrix of dimension ![]() and each GMM is a simple weighted sum of Gaussians, i.e.,
and each GMM is a simple weighted sum of Gaussians, i.e.,
3.2.3 Aligning Speech to HMMs
In the speech stream, phonemes have different durations, so it's necessary to find an alignment between input frames and states of the HMM. That is, given input speech frames, ![]() and a sequence of HMM states
and a sequence of HMM states ![]() , an alignment
, an alignment ![]() maps the frames monotonically into the states of the HMMs. So the system needs to find the optimal (i.e. highest probability) alignment A between the frames
maps the frames monotonically into the states of the HMMs. So the system needs to find the optimal (i.e. highest probability) alignment A between the frames ![]() and the HMM states.
and the HMM states.
This is often done using a form of the Viterbi algorithm [5].
For each hypothesized word sequence, the system looks up the phonemes that make up the pronunciation of each word from the lexicon, and then looks up the triphone for each phoneme in context, using decision trees. Then, given the sequence of triphones, the system looks up the sequence of HMM states. The acoustic probability of that hypothesis is the probability of the optimal alignment of these states with the input. An example of such an alignment is shown in Figure 3.5.
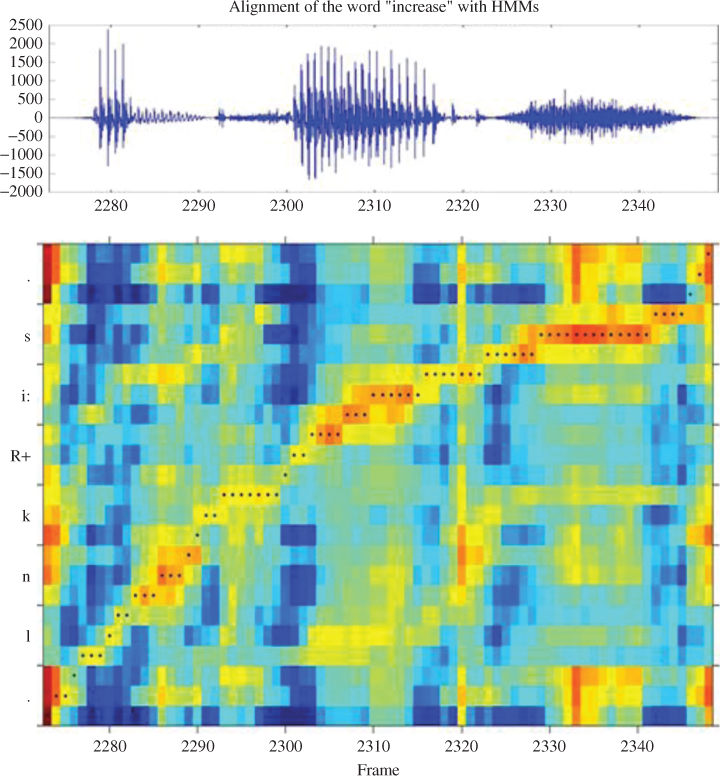
Figure 3.5 Viterbi alignment of a speech signal (x axis); against a sequence of HMMs (y axis); lighter areas indicate higher probabilities as assessed by the HMM for the given frame; dotted line shows alignment.
3.2.4 Language Model
The language model computes the probability of various word sequences and helps the recognition system propose the most likely interpretation of input utterances. There are two fundamentally different types of language models used in voice recognition systems: grammar-based language models, and stochastic language models.
Grammar-based language models allow some word sequences, but not others. Often, these grammars are application-specific, and support utterances relevant to some specific task, such as making a restaurant reservation or issuing a computer command. These grammars specify the exact word sequences which the user is supposed to utter in order to instruct the system. For example, a grammar for a reservation system might recognize sequences like “find a Chinese restaurant nearby”, “reservation for two at seven”, or “show me the menu”. The same grammar would probably not recognize sequences like “pepperoni pizza”, “economic analysis of the restaurant business”, or “colorless green ideas sleep furiously”.
The set of word-sequences recognized by a grammar is described by a formal grammar, e.g. a finite-state machine, or a context-free grammar. Often, these grammars are written in formalism like Speech Recognition Grammar Specification (SRGS) (see [6]). While it is easy to construct simple example grammars, writing a grammar that covers all the ways a user might like to specify an input can be difficult. Thus, one might say “nearby Chinese restaurant”, “please find a nearby Chinese restaurant”, “I'd like to eat Chinese”, or “Where can I find some dim sum?” All these sentences mean the same thing (to a restaurant ordering app), but writing a grammar that can cover all the choices can be onerous because of users' creative word choices.
Stochastic language models (originally used for free-text dictation) estimate the probability of any word sequence (but some are much more likely than others.) Thus, “Chinese restaurant” would have a reasonable probability; “restaurant Chinese” would have a somewhat smaller probability; and “nearby restaurant Chinese a find” would have a much lower probability. Attempts to write grammar-based language models to cover all the ways a user could generate English text have not been successful; so for general dictation applications, stochastic language models have been preferred. It turns out that it is much easier to make a robust, application-specific language model by using a stochastic LM, followed by NLU processing even for quite specific applications.
The job of stochastic language modeling is to calculate an approximation to ![]() , which is, by definition:
, which is, by definition:
A surprising development in speech recognition was that a simple approximation (the trigram approximation) works very well:
The trigram approximation holds that the likelihood of the next word in a sentence depends only on the previous two words, (and an n-gram language model is the obvious generalization for longer spans). Scientifically and linguistically, this is inaccurate: many language phenomena span more than two words [7]! Yet it turns out that this approximation works very well in speech recognition [8].
3.2.5 Search: Solving Crosswords at 1000 Words a Second
The task of finding the jointly optimal word sequence to describe an acoustic observation is rather like solving a crossword, where the acoustic scores constrain the columns, and LM scores constrain the rows. However, there are too many possible word sequences to evaluate directly (a 100,000 word vocabulary generates ![]() ten-word sentences). The goal of the search component is to identify the correct hypothesis, and evaluate as few other hypotheses as possible. It does this using a number of heuristic techniques. One particularly important technique is called a beam search, which processes input frames one by one, and keeps “alive” a set of hypotheses with scores near that of the best hypothesis.
ten-word sentences). The goal of the search component is to identify the correct hypothesis, and evaluate as few other hypotheses as possible. It does this using a number of heuristic techniques. One particularly important technique is called a beam search, which processes input frames one by one, and keeps “alive” a set of hypotheses with scores near that of the best hypothesis.
How much computation is required? For a large vocabulary task, on a typical frame, the search component might have very roughly 1000 active hypotheses. Updating the scores for an active hypothesis involves extending the alignment by computing acoustic model (GMM) scores for the current HMM state of that hypothesis, and the next state, and then updating the alignment. If the hypothesis is at the end of a word, (about 20 word-end hypotheses per frame), then the system also needs to look up LM scores for potential next words (about 100 new words per word ending). Thus, we need about 2000 GMM, 1000 alignment computations, and 2000 LM lookups, per frame. At a typical frame rate of 100 Hz, we are computing about 200 k GMMs, 200 k LM lookups, and 100 k alignment updates per second.
3.2.6 Training Acoustic and Language Models
The HMMs used in acoustic models are created from large datasets by an elaborate training process. Speech data is transcribed, and provided to a training algorithm which utilizes a maximum likelihood objective function. This algorithm estimates acoustic model parameters so as to maximize the likelihood of observing the training data, given the transcriptions. The heart of this process bootstraps an initial approximate acoustic model into an improved version, by aligning the training speech against the transcriptions and re-training the HMMs. This process is repeated many times to produce Gaussian mixture models which score the training data as high likelihood.
However, the goal of speech recognition is not to represent the most likely sequence of acoustic states, but rather to give correct word sequence hypotheses higher probabilities than incorrect hypotheses. Hence, various forms of discriminative training have been developed, which adjust the acoustic models so as to decrease various measures related to the recognition error rate [9–11].
The resulting acoustic models routinely include thousands of states, hundreds of thousands of mixture model components, and millions of parameters. Canonical systems used “supervised” training, i.e. used both speech and the associated transcriptions for training. As speech data sets have grown, there has been substantial effort to find training schemes using un-transcribed or “lightly labeled” data.
Stochastic language models are trained from large text datasets containing billions of words. Large text databases are collected from the World Wide Web, from specialized text databases, and from deployed voice recognition applications. The underlying training algorithm is much simpler than that used in acoustic training (it is basically a form of counting), but finding good data, weighting data carefully, and handling unobserved word sequences require considerable engineering skill. The resulting language models often include hundreds of thousands to billions of n-grams, and have billions of parameters.
3.2.7 Adapting Acoustic and Language Models for Speaker Dependent Recognition
People speak differently. The words they pick, and the way they say words is influenced by their anatomy, accent, education, and the intentional style of speaking (e.g., dictating a formal document vs. an informal SMS message).
The resulting differences in pronunciation may confuse a speaker-independent voice recognition system, which may not have encountered training exemplars with these particular combinations of characteristics. In contrast, a speaker dependent system which models a single speaker might achieve a higher accuracy than a speaker-independent system. However, users are not inclined to record thousands of hours of speech in order to train a voice recognition system, and it is thus highly desirable to produce speaker-dependent acoustic and language models by adapting speaker-independent models utilizing limited data from a particular user.
There are many kinds of adaptation for acoustic models. Early work often used MAP (maximum ![]() posteriori) training, which modifies the means and variances of the GMMs used by the HMMs. MAP adaptation is generally “data hungry”, since it needs to utilize training examples for most of the GMMs used in the system. More data-efficient alternatives modify GMM parameters for whole classes of triphones (e.g. MLLR, maximum likelihood linear regression [12]). Transformations can be applied either to the models or to the input features. While “canonical” adaptation is “supervised” (i.e. uses speech data with transcriptions), some forms of adaptation now are unsupervised, using the input speech data and recognition hypotheses without a person checking the correctness of the transcriptions.
posteriori) training, which modifies the means and variances of the GMMs used by the HMMs. MAP adaptation is generally “data hungry”, since it needs to utilize training examples for most of the GMMs used in the system. More data-efficient alternatives modify GMM parameters for whole classes of triphones (e.g. MLLR, maximum likelihood linear regression [12]). Transformations can be applied either to the models or to the input features. While “canonical” adaptation is “supervised” (i.e. uses speech data with transcriptions), some forms of adaptation now are unsupervised, using the input speech data and recognition hypotheses without a person checking the correctness of the transcriptions.
Language models are also adapted for users or tasks. Adaptation can modify either single parameters (i.e. adjust the counts which model data for a particular n-gram, analogous to MAP acoustic adaptation), or can effectively adapt clusters of parameters (analogous to MLLR). For instance, when building a language model for a new domain, one can use interpolation weights to combine n-gram statistics from different corpora.
3.2.8 Alternatives to the “Canonical” System
In the previous paragraphs, we have outlined the basics of a voice recognition system. Many alternatives have been proposed; we mention a few prominent alternatives in Table 3.1.
Table 3.1 Alternative voice recognition options
| Technique | Explanation | Reference |
| Combining AM and LM scores | ||
| Weighting AM vs. LM | Instead of the formula in equation II, with |
[8] |
| Alternative front ends | ||
| PLP | Perceptual linear predictive analysis: find a linear predictive model for the input speech, using a perceptual weighting. | [2] |
| RASTA | “Relative spectra”: a front end designed to filter out slow variations in channel and background noise characteristics. | [13] |
| Delta and double delta | Given a frame based front-end, extend the vector to include differences and second order differences between frames around the frame in question. | [14] |
| Dimensionality reduction | Heteroscedastic linear discriminant analysis (HLDA): given MFCC or other speech features, along with delta and double delta features, or “stacked frames” (i.e. a range of frames), using a linear transformation to decrease the dimension of the front end feature. | [15] |
| Acoustic modeling | ||
| Approximations to full covariance | Using the full covariance matrixes in HMM requires substantial computation and training data. Earlier versions of HMM used simpler versions of covariance matrixes such as “single variance”, diagonal covariance. | [16] |
| Vocal Tract Length Normalization | VTLN is a speaker-dependent technique which modifies acoustic features in order to take into account differences in the length of speakers' vocal tracts. | [17] |
| Discriminative training | ||
| MMIE | Maximum Mutual Information Estimation: a training method which adjusts parameters of an acoustic model so as to maximize the probability of a correct word sequence vs. all other word sequences. | [9] |
| MCE | Minimum classification error: a training method which adjusts parameters of an acoustic model to minimize the number of words incorrectly recognized. | [10] |
| MPE | Minimum phone error: a training method which adjusts parameters of an acoustic model to minimize “phone errors”, i.e., the number of phonemes incorrectly recognized. | [11] |
| LM | ||
| Back-off | In a classic n-gram model, it is very important to predict not only the probability of observed n-grams, but also n-grams that do not appear in the training corpus. | [18] |
| Exponential models | Exponential models (also known as maximum entropy models) estimate the probability of word sequences by multiplying many different probability estimates and other functions and weigh these estimates in the log domain. They can include longer range features than n-gram models. | [19] |
| Neural Net LMs | Neural network language models extend exponential models by allowing the indicator functions to be determined automatically via non-linear transformations of input data. | [20] |
| System organization | ||
| FSTs | In order to reduce redundant computation, it is desirable to represent the phonetic decision trees which map phonemes to triphones, the phoneme sequences that make up words, and grammars as finite state machines (called weighted finite state transducers, WFSTs), then combine them into a large FSM and optimize this FSM. Compiling all the information into a more uniform data structure helps with efficiency, but can have problems with dynamic grammars or vocabulary lists. | [21] |
3.2.9 Performance
Speech recognition accuracy has steadily increased in performance during the past several decades. When early dictation systems were introduced in the late 1980s, a few early adopters eagerly embraced them and used them successfully. Many others found the error rate too high and decided that speech recognition “wasn't really ready yet”. Speech recognition performance had a bit of a breakthrough in popular consciousness in 2010, when David Pogue, the New York times technology reporter, reported error rates on general dictation of less than 1% [22]. Most speakers do not yet show nearly this level of performance, but performance has steadily increased each year through a combination of better algorithms, more computation, and utilization of ever-larger training corpora. In fact, on one specialized task, recognizing overlapping speech from multiple speakers, a voice recognition system was able to perform better than human listeners [23].
Over the past decade, the authors' experience has been that the average word error rate on a large vocabulary dictation task has decreased by approximately18% per year. This has meant that each year, the proportion of the user population that experiences acceptable performance without any system training has increased steadily. This progress has allowed us to take on challenging applications such as voice search, but also more challenging environments, such as in-car voice control. Finally, improving accuracy has meant that voice recognition has now become a viable front end for sophisticated natural language processing, giving rise to a whole new class of interfaces.
3.3 Deep Neural Networks for Voice Recognition
The pattern of steady improvements of “canonical” voice recognition systems has been disrupted in the last few years by the introduction of deep neural nets (DNNs), which are a form of artificial neural networks (ANN). ANNs are computational models, inspired by the brain, that are capable of machine learning and pattern recognition. They may be viewed as systems of interconnected “neurons” that can compute values from inputs by feeding information through the network.
Like other machine learning methods, neural networks have been used to solve a wide variety of tasks that are difficult to solve using ordinary rule-based programming, including computer vision and voice recognition.
In the field of voice recognition, ANNs were popular during late 1980s and early 1990s. These early, relatively simple ANN models did not significantly outperform the successful combination of HMMs with acoustic models based on GMMs. Researchers achieved some success using artificial neural networks with a single layer of nonlinear hidden units to predict HMM states from windows of acoustic coefficients [24].
At that time, however, neither the hardware nor the learning algorithms were adequate for training neural networks with many hidden layers on large amounts of data, and the performance benefits of using neural networks with a single hidden layer and context-independent phonemes as output were not sufficient to seriously challenge GMMs. As a result, the main practical contribution of neural networks at that time was to provide extra features in tandem with GMMs, or “bottleneck” systems that used ANN to extract additional features for GMMs. ANN were used with some success in voice recognition systems and commercial products only in a limited number of cases [25].
Up until a few years ago, most state of the art speech recognition systems were thus based on HMMs that used GMMs to model the HMM emission distributions. It was not until recently that new research demonstrated that hybrid acoustic models utilizing more complex DNNs, trained in a manner that was less likely to get “stuck” in a local optimum, could drastically improve performance on a small-scale phone recognition task [26]. These results were later extended to a large vocabulary voice search task [27, 28]. Since then, several groups have achieved dramatic gains due to the use of deep neural network acoustic models on large vocabulary continuous speech recognition (LVCSR) tasks [27]. Following this trend, systems using DNNs are quickly becoming the new state-of-the-art technique in voice recognition.
In practice, DNNs used for voice recognition are multi-layer perceptron neural networks with up to 5–9 layers of 1000–2000 units each. While the ANNs used in the 1990s output the context independent phonemes, DNNs use a very large number of tied state triphones (like GMMs). A comparison between the two models is shown in Figure 3.6.

Figure 3.6 A standard ANN used for ASR in the 1990s vs. a DNN used today.
DNNs are usually pre-trained with the Restricted Boltzmann Machine algorithm and fine-tuned with standard back-propagation. The segmentations are usually produced by existing GMM-HMM systems. The DNN training scheme, shown in Figure 3.7, consists of a number of distinct phases.
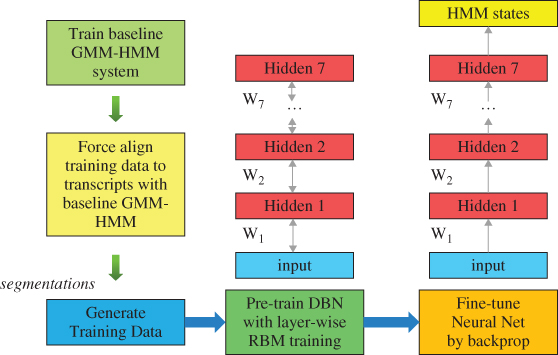
Figure 3.7 DNN training.
At run-time, a DNN is a standard feed-forward neural network with many layers of sigmoidal units and a top-most layer of softmax units. It can be executed efficiently both on conventional and parallel hardware.
DNN can be used for ASR in two ways:
- Using DNN to extract features for GMM (bottleneck features). This can be done by inserting a bottleneck layer in the DNN and using the activation of the units in that layer as features for GMM.
- Using DNN outputs (tied triphones probabilities) directly in the decoder (DNN-HMM hybrid model).
The first method enables quick improvements to existing GMM based ASR systems, with error rate reductions of 10–15%, but the second method yields larger improvements, usually resulting in an error reduction of 20–30% compared to state-of-the-art GMM systems.
Three main factors were responsible for the recent resurgence of neural networks as high-quality acoustic models:
- The use of deeper networks makes them more powerful, hence deep neural networks (DNN) instead of shallow neural networks.
- Initializing the weights appropriately and using much faster hardware makes it possible to train deep neural networks effectively: DNN are pre-trained with the Restricted Boltzmann Machine algorithm and fine-tuned with standard back-propagation; GPUs are used to speed-up the training.
- Using a larger number of context-dependent output units instead of context-independent phonemes. A very large output layer that accommodates the large number of HMM tied triphone states greatly improves DNN performances. Importantly, this choice keeps the decoding algorithm largely unchanged.
Other important findings which emerged in the DNN training recipes [27] include:
- DNNs work significantly better on filter-bank outputs than on MFCCs. In fact they are able to deal with correlated input features and prefer to use raw features than pre-transformed features.
- DNNs are more speaker-insensitive than GMM. In fact, speaker-dependent methods provide little improvement over speaker-independent DNNs.
- DNNs work well for noisy speech, subsuming many de-noising pre-processing methods.
- Using standard logistic neurons is reasonable but probably not optimal. Other units, like rectified linear units, seem very promising.
- The same methods can be used for applications other than acoustic modeling.
- The DNN architecture can be used for multi-task (e.g. multi-lingual) learning in several different ways and DNNs are far more effective than GMMs at leveraging data from one task to improve performance on related tasks.
3.4 Hardware Optimization
The algorithms described in the previous sections require quite substantial computational resources. Chip-makers increasingly recognize the importance of speech-based interfaces, so they are developing specialized processor architectures optimized for voice and NLU processing, as well as other input sensors.
Modern users complement their desktop computers and televisions with mobile devices, (laptops, tablets, smartphones, GPS devices), where battery life is often a limiting factor. These devices have become more complex, combining multiple functionalities into one single form factor, as vendors participate in an “arms race” to provide the next “must-have” bestselling device. Although users expect increased functionality, they have not changed their expectations for battery life: a laptop computer needs several hours of battery life; a smart phone should last a whole day without recharging. But the battery is part of the device, impacting both weight and size.
3.4.1 Lower Power Wake-up Computation
This has led to a need to reduce power consumption on mobile devices. Software can disable temporarily unused capabilities (Bluetooth, Wi-Fi, Camera, GPS, microphones) and quickly re-enable them when needed. Devices may even put themselves into various low-power modes, with the system able to respond to fewer and fewer actions. Think of Energy Star compliant TVs and other devices, but with more than just three (On-Off-Standby) states. How, then, does the system “wake up”? A physical action by the user, such as pressing a power key on the device, is the most common means today.
However, devices today have a variety of sensors that can also be used for this purpose. An infrared sensor can detect a signal from a remote control. A light sensor can trigger when the device is pulled out of a pocket. A motion sensor can detect movement. A camera can detect people. A microphone voice wakeup can detect voice activity or a particular phrase.
This is accomplished through low-power, digital signal processing (DSP)-based “wake-up-word” recognition, which allows users to speak to devices without having first to turn them on, further reducing the number of steps separating user intent and desired outcome. For instance, the Intel-inspired Ultrabook is integrating these capabilities, responding to “Hello Dragon” by waking up and listening to a users' command or taking dictation.
The security aspect starts to loom large here. A TV responds to its known signals, regardless of the origin of the signal. Anyone who has the remote control is able to operate it – or, indeed, anyone with a compatible remote control. While a living room typically has at most one TV in it, a meeting room may have 20 people, all with mobile phones. For a person to attempt to wake up his or her phone and actually wake up someone else's would be most unwelcome! Hence, there needs to be an element of security through personalization. The motion sensor may only respond to certain motions. The camera sensor may only respond to certain user(s), a technology known as “Facial Recognition”, and the voice wakeup may only respond to a particular phrase as spoken by a particular user – “Voice Biometrics” technology.
3.4.2 Hardware Optimization for Specific Computations
These sensors all draw power, especially if they are always active, and when the algorithms are run on the main CPU they incur a substantial drain on the battery. Having a full audio system running, with multiple microphones, acoustic echo cancellation and beam forming, draws significant amounts of power. Manufacturers are thus developing specialized hardware for these sensor tasks to reduce this power load, or are relying on DSPs, typically running at a much lower clock speed than the main CPU, say at 10 MHz, rather than 1–2 GHz.
The probability density function (pdf) associated with a single n-dimensional Gaussian Model is shown above in equation (1.4) The overall pdf of a Gaussian Mixture Model is a weighted sum of such pdfs, and some systems may have 100,000 or more of these pdfs, potentially needing to be evaluated 100 times a second. Algorithmic optimizations (only computing “likely” pdfs) and model approximations (such as assuming the covariance matrix is diagonal) are applied to reduce the computational load. The advent of SIMD (single-instruction, multiple data) hardware was a big breakthrough, as it enabled these linear algebra computations to be done for four or eight features at a time.
The most recent advance has been the use of Graphical Processing Units (GPUs). Initially GPUs were used to accelerate 3D computer graphics (particularly for games), which make extensive use of linear algebra. GPUs help with the pdfs such as those described above, but have proved particularly effective in the computation of DNNs.
As discussed above, DNNs have multiple layers of nodes, and each layer of nodes is the output from a mostly linear process applied to the layer of nodes immediately below it. Layers with 1000 nodes are common, with 5–10 layers, hence applying the DNN effectively requires the calculation of 5–10 matrix-vector multiplies, where each matrix is on the order of ![]() , and this occurs many times per second. Training the DNN is even more computationally expensive. Recent research has shown that training on a very small amount of data could take three months, but that using a GPU cut the time to three days, a 30-fold reduction in time [28].
, and this occurs many times per second. Training the DNN is even more computationally expensive. Recent research has shown that training on a very small amount of data could take three months, but that using a GPU cut the time to three days, a 30-fold reduction in time [28].
3.5 Signal Enhancement Techniques for Robust Voice Recognition
In real-world speech recognition applications, the desired speech signal is typically mixed acoustically with many interfering signals, such as background noise, loudspeaker output, competing speech, or reverberation. This is especially true in situations when the microphone system is far from the user's lips – for instance, in vehicles or home applications. In the worst case, the interfering signals can even dominate the desired signal, severely degrading the performance of a voice recognizer. With speech becoming more and more important as an efficient and essential instrument for user-machine interaction, noise robustness in adverse environments is a key element of successful speech dialog systems.
3.5.1 Robust Voice Recognition
Noise robustness can be achieved by modifying the voice recognition process, or by using a dedicated speech enhancement front end. Today's systems typically use a combination of both.
State-of-the-art techniques in robust voice recognition include using noise robust features such as MFCCs or neural networks, and training the acoustic models with noisy speech data that is representative of the kinds of noise present in normal use of the application. However, due to the large diversity of acoustic environments, it is impossible to cover all possible noise situations during training. Several approaches have been developed for rapidly adapting the parameters of the acoustic models to the noise conditions which are momentarily present in the input signal. These techniques have been successfully applied – for instance to enable robust distant-talk in varying reverberant environments.
Speech enhancement algorithms can be roughly grouped into single- and multi-channel methods. Due to the specific statistical properties of the various noise sources and environments, there is no universal solution that works well for all signals and interferers. Depending on the application, the speech enhancement front-end therefore often combines different methods. Most common is the combination of single-channel noise suppression with multi-channel techniques such as noise cancellation and spatial filtering.
3.5.2 Single-channel Noise Suppression
Single-channel noise suppression techniques are commonly based on the principle of spectral weighting. In this method, the signal is initially decomposed into overlapping data blocks with a duration of about 20–30 milliseconds. Each of these blocks is then transformed to the frequency or subband domain using either a Short-Term Fourier Transform (STFT) or a suitable analysis filterbank. Next, the spectral components of the noisy speech signal are weighted by attenuation factors, which are calculated as a function of the estimated instantaneous signal-to-noise ratio (SNR) in the frequency band or subband. This function is chosen so that spectral components with a low SNR are attenuated, while those with a high SNR are not. The goal is to create a best estimate of the spectral coefficients of the clean speech signal. Given the enhanced spectral coefficients, a clean time domain signal can be synthesized and passed to the recognizer. Alternatively, the feature extraction can be performed directly on the enhanced spectral coefficients, which avoids the transformation back into the time-domain.
A large variety of linear and non-linear algorithms have been developed for calculating the spectral weighting function. These algorithms mainly differ in the underlying optimization criteria, as well as in the assumptions about the statistical characteristics of speech and noise. The most common examples for weighting functions are spectral subtraction, the Wiener filter, and the minimum mean-square error (MMSE) estimator [29]. The single-channel noise suppression scheme is illustrated by the generalized block diagram in figure 3.8. Figure 3.9 shows a spectrogram of the noisy phrase ‘Barbacco has an opening’ and the spectrogram of the enhanced signal after applying the depicted spectral weighting coefficients.
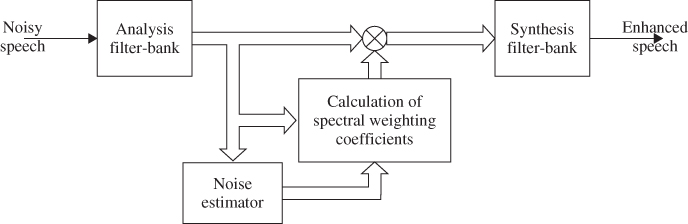
Figure 3.8 Block diagram of a single-channel noise suppression scheme based on spectral weighting.
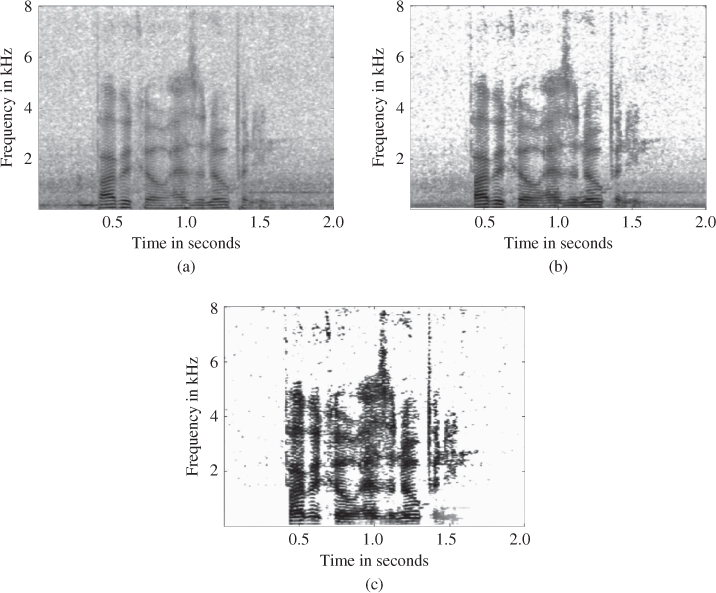
Figure 3.9 Time-frequency analysis of the noisy (a) and enhanced speech signal (b); time-frequency plot of the attenuation factor applied to the noisy speech signal (c).
Single-channel noise suppression algorithms work well for stationary background noises like fan noise from an air-conditioning system, a PC fan, or driving noise in a vehicle, but they are not very suitable for non-stationary interferers like speech and music. In a single-channel system, the background noise can mostly be tracked in speech pauses only, due to the typically high frequency overlap of speech and interference in the noisy speech signal. This limits the single-channel noise reduction schemes mainly to slowly time-varying background noises which do not significantly change during speech activity.
Several optimizations have been proposed to overcome this restriction. These include model-based approaches which utilize an explicit clean speech model, or typical spatio-temporal features of speech and specific interferers in order to segregate speech from non-stationary noise. Efficient methods have been developed to reduce fan, wind-buffets in convertibles [30], and impulsive road or babble-noise.
Another drawback of single-channel noise suppression is the inherent speech distortion of the spectral weighting techniques, which significantly worsens at lower signal-to-noise ratios. Due to the SNR-dependent attenuation of the approach, more and more components of the desired speech signal are suppressed as the background noise increases. This increasing speech distortion degrades recognizer performance.
3.5.3 Multi-channel Noise Suppression
Unlike single-channel noise suppression, multi-channel approaches can provide low speech distortion and a high effectiveness against non-stationary interferers. Drawbacks are an increased computational complexity, and that additional microphones or input channels are required. Multi-channel approaches can be grouped into noise-cancellation techniques which use a separate noise reference channel, and spatial filtering techniques such as beamforming (discussed below).
3.5.4 Noise Cancellation
Adaptive noise cancellation [31] can be applied if a correlated noise reference is available. That means that the noise signals in the primary channel (i.e. the microphone) and in the reference channel are linear transforms of a single noise source. An adaptive filter is used to identify the transfer function that maps the reference signal to the noise component in the primary signal. By filtering the reference signal with the transfer function, an estimate for the noise component in the primary channel is calculated. The noise estimate is afterwards subtracted from the primary signal to get an enhanced speech signal. The principle of adaptive noise cancellation is illustrated in figure 3.10. As signal and noise components superpose linearly at the microphone, the subtraction of signal components does not lead to any speech distortion, provided that uncorrelated noise components and crosstalk of the desired speech signal into the reference channel are sufficiently small.
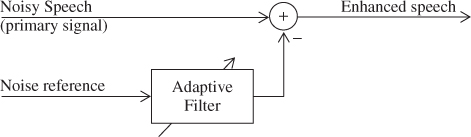
Figure 3.10 Basic structure of a noise canceller.
The effectiveness of noise cancellation is, in fact, highly dependent on the availability of a suitable noise reference which is, in turn, application-specific. Noise cancellation techniques are successfully applied in mobile phones. Here, the reference microphone is typically placed as far as possible from the primary microphone – typically on the top or the rear of the phone – to reduce leakage of the speech signal into the reference channel. Noise cancellation techniques are, on the other hand, less effective in reducing background noise in vehicle applications, due to diffuse characteristics of the dominating wind and tire noise. As a result, the correlation rapidly drops if the primary and reference microphone are separated more than a few centimeters, which makes it practically impossible to avoid considerable leakage of the speech signal into the reference channel.
3.5.5 Acoustic Echo Cancellation
A classic application for noise cancellation is the removal of interfering loudspeaker signals, which is typically referred to as Acoustic Echo Cancellation (AEC) [32]. This method was originally developed to remove the echo of the far end subscriber in hands-free telephone conversations. In voice recognition, AEC is used to remove the prompt output of the speech dialog system or the stereo entertainment signal from a TV or mobile application.
Analogously to the noise canceller described above, the electric loudspeaker reference is filtered by an adaptive filter to get an estimate of the loudspeaker component in the microphone signal. The adaptive filter has to model the room transfer function, including the loudspeaker and microphone transfer functions. As the acoustic environment can change quickly – for instance due to movements of persons in the room – fast tracking capabilities of the adaptive filter are of major importance to remove loudspeaker components effectively.
Due to its robustness and simplicity, the so-called Normalized Least Mean Square (NLMS) algorithm [33] is widely used to adjust the filter coefficients of the adaptive filter. A drawback of the algorithm is that it converges slowly if the interference has a high spectral dynamic, as in the case of speech or music. For this reason, the NLMS is often implemented in the frequency or subband domain. As the spectral dynamic in the individual frequency subbands is much lower than over the complete frequency range, the tracking behavior is significantly improved. Another advantage of working in the subband domain is that AEC and spectral weighting techniques like noise reduction can be efficiently combined.
3.5.6 Beamforming
When speech is captured with an array of microphones, the resulting multi-channel signal also contains spatial information about the sound sources. This facilitates spatial filtering techniques such as beamforming, which extract the signal from a desired direction while attenuating noise and reverberation from other directions. The application of adaptive filtering techniques [34] allows adjusting the spatial characteristics of the beamformer to the actual sound-field, thus enabling effective suppression, even of moving sound sources. The directionality of such an adaptive beamformer, however, depends on the number of microphones, which are often limited in practical devices to 2–3 due to cost reasons.
To improve the directionality the adaptive beamformer can be combined with a so called spatial post-filter [35]. The spatial post-filter is based on the spectral weighting techniques also applied for noise reduction, but uses a spatial noise estimate of the adaptive beamformer. Although spatial filtering can significantly reduce interfering noise or competing speakers, it can also be harmful if the speaker is not at the specified location. This makes it imperative to have a robust speaker localization system, especially in the mobile context, where the direction of arrival changes if the user moves or tilts a device.
A simple approach is to perform the localization acoustically, by simply selecting the direction in which the sound level is strongest [36]. This works reasonably well if there is a single speaker at a relatively close distance to the device, such as when using a tablet. A more challenging scenario arises in the context of smart TVs, or smart home appliances in general, where there may be several competing speakers at a larger distance. Such conditions prevent acoustic source localization from working reliably. In this situation, it may be preferable to track the users visually with the help of a camera and to focus on the speaker that is, for instance, facing the device. An alternative is to use gestures to indicate who the device should listen to.
As mentioned above, the speech enhancement front-end often combines several techniques to cope effectively with complex acoustic environments. Figure 3.11 shows an example of a speech enhancement front end enabling far-talk operation of a TV. In this system, acoustic echo cancellation is applied to remove the multi-channel entertainment signal, while beamforming and noise reduction are used to suppress interfering sources such as family members and background noises.
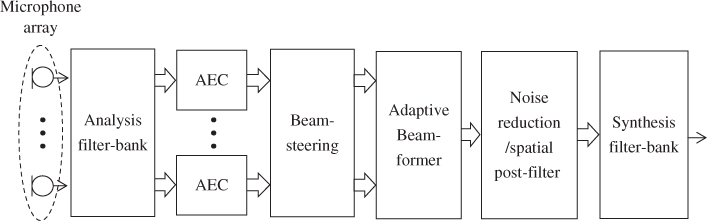
Figure 3.11 Combined speech enhancement front-end for far-talk operation of a TV.
3.6 Voice Biometrics
3.6.1 Introduction
Many voice-driven applications on a mobile device need to verify a user's identity. This is sometimes for security purposes (e.g. allowing a user to make a financial transaction) or to make sure that a spoken command was issued by the device's owner.
Voice biometrics recognizes a person based on a sample of their voice. The primary use of voice biometrics in commercial applications is speaker verification. Here, a claimed identity is validated by comparing the characteristics of voice samples obtained during a registration phase and validation phase. Voice biometrics is also used for speaker identification where a voice sample is matched to one of a set of registered users. Finally, in cases where a recording may include voice data from multiple people, such as during a conversation between an agent and customer, “speaker diarization” extracts the voice data corresponding to each speaker. All of these technologies can play a role in human-machine interaction and, particularly, when security is a requirement.
Voice biometrics will be a key component of mobile user interfaces. Traditional security methods have involved tedious measures based on personal identification numbers, passwords, tokens, etc., which are particularly awkward when interacting with a mobile device. Voice biometrics provides a much more natural and convenient method of validating the identity of a user. This has numerous applications, including everyday activities such as accessing email and waking up a mobile device. For “seamless wakeup”, not only must the phrase be correct, but it must be spoken by the owner of the device. This can preserve battery life and prevent unauthorized device access. Other applications include transaction validation for mobile banking and purchase authorization.
Research dedicated to developing and improving technologies for performing speaker verification, identification, and diarization has been making progress for the last 50 years. Whereas early technologies focused mainly on template-based approaches, such as Dynamic Time Warping (DTW) [37], these have evolved towards statistical models such as the GMM (discussed above in Section 1.5.2 [39]). More recent speaker recognition technologies have used the GMM as an initial step towards modeling the voice of a user, but then apply further processing in the form of Nuisance Attribute Projection (NAP) [40], Joint Factor Analysis (JFA) [41], and Total Factor Analysis (TFA) [42]. The TFA approach, which yields a compact representation of a speaker's voice known as an I-vector (or Identity vector) represents the current state of the art in voice biometrics.
3.6.2 Existing Challenges to Voice Biometrics
One of the primary challenges in voice biometrics has been to minimize the error rate increase attributed to mismatch in the recording device between registration and validation. This can occur, for example, when a person registers their voice with a mobile phone, and then validates a web transaction using their personal computer. In this case, there will be an increase in the error rate due to the mismatch in the microphone and channel used for these different recordings. This specific topic has received a great deal of attention in the research community, and has been addressed successfully with the NAP, JFA, and TFA approaches. However, new scenarios are being considered for voice biometrics that will warrant further research. Another challenge is “voice aging”. This refers to the degradation in verification accuracy as the time elapse between registration and validation increases [43]. Model adaptation is one potential solution to this problem, where the model created during registration is adapted with data from validation sessions. Of course, this is applicable only if the user accesses the system on a regular basis.
Another challenge to voice biometrics technology is to maintain acceptable levels of accuracy with minimal audio data. This is a common requirement for commercial applications. In the case of “text-dependent” speaker verification – where the same phrase must be used for registration and validation – two to three seconds (or ten syllables) can often be enough for reliable accuracy. Some applications, however, such as using a wakeup word on a mobile device, require shorter utterances for validating a user.
Whereas leveraging the temporal information and using customized background modeling improve accuracy, this topic remains a challenge. Similarly, with “text-independent” speaker verification – where a user can speak any phrase during registration or validation – typically 30–60 seconds of speech is sufficient for reasonable accuracy. However, speaker verification and identification capabilities are often desired, with much shorter utterances, such as when issuing voice commands to a mobile device, having a brief conversation with a call-center agent, etc. The National Institute of Standards and Technology (NIST) has sponsored numerous speaker recognition evaluations that have included verification of short utterances [44], and this is still an active research area.
3.6.3 New Areas of Research in Voice Biometrics
Voice biometrics technologies have advanced significantly since their inception; however a number of areas require further investigation. Countermeasures for “spoofing” attacks (orchestrated with recording playback, voice splicing, voice transformation, and text-to-speech technology) provide new challenges. A number of such attacks have been recently covered in an international speech conference [45]. Ongoing work assesses the risk of these attacks and attempts to thwart them. This can be accomplished through improved liveness detection strategies, along with algorithms for detecting synthesized speech.
Voice biometrics represents an up-and-coming area for interactive voice systems. Whereas speech recognition, natural language understanding, and text-to-speech have had more deployment history, voice biometrics technology is rapidly growing in the commercial and Government sectors. Voice biometrics provides a convenient means of validating an identity or locating a user among an enrolled population, which can reduce identity theft, fraudulent account access, and security threats. The recent algorithmic advances in the voice biometrics field, as described in this section, increase the number of use-cases and will facilitate adoption of this technology.
3.7 Speech Synthesis
Many mobile applications not only recognize and act on a user's spoken input, but also present spoken information to the user, via text-to-speech synthesis (TTS). TTS has a rich history [46], and many elements have become standardized. As shown in Figure 3.12, TTS has two components, front-end (FE) and back-end (BE) processing. Front-end processing derives information from an analysis of the text. Back-end processing renders this information into audio in two stages:
- First, it searches an indexed knowledge base of pre-analyzed speech data, and finds the indexed data which most closely matches the information provided by the front-end (unit selection).
- Second, this information is used by a speech synthesizer to generate synthetic speech.
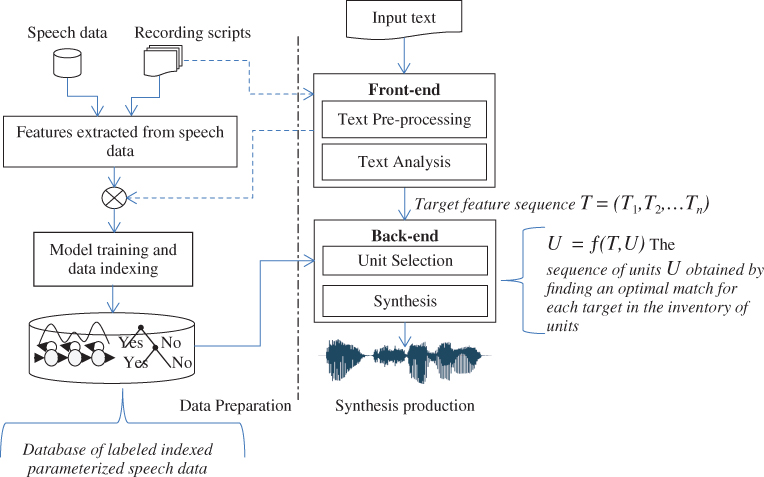
Figure 3.12 Speech synthesis architecture.
The pre-analyzed data may be stored as encoded speech or as a set of parameters used to drive a model of speech production or both.
In Figure 3.12, the front-end is subdivided into two constituent parts: text pre-processing and text analysis. Text pre-processing is needed in “real world” applications, where a TTS system is expected to interpret a wide variety of data formats and content, ranging from short, highly stylized dialogue prompts to long, structurally complex prose. Text pre-processing is application-specific, e.g. the pre-processing required to read out customer and product information extracted from a database will differ substantially from an application designed to read back news stories taken from an RSS feed. Also, a document may contain mark-up designed to aid visualization in a browser or on a page, e.g., titles, sub-headings. A pre-processor must re-interpret this information in a way which leads to rendered speech expressing the document's structure.
Text analysis falls into four processing activities: tokenization and normalization, syntactic analysis, prosody prediction and grapheme-to-phoneme conversion. Tokenization aids in the appropriate interpretation of orthography. For example, a telephone number is readily recognizable when written, and has a regular prosodic structure when spoken. During tokenization graphemes are grouped into tokens, where a token is defined as a sequence of characters belonging to a defined class. A digit is an example of a simple token, while a telephone number would be considered a complex token. Tokenization is particularly challenging in writing systems such as Chinese, where sentences are written as sequences of characters without white-space between words.
Text normalization is the process of converting orthography into an expanded standardized representation (e.g. $5.00 would be expanded into “five dollars”) and is a precursor to further syntactic analysis. Syntactic analysis typically includes part of speech and robust syntactic structure determination. Together, these processes aid in the selection of phonetic pronunciations and in the prediction of prosodic structure [47].
Prosody may be defined as the rhythm, stress and intonation of speech, and is fundamental to the communication of a speaker's intentions (e.g., questions, statements, imperatives) and emotional state [48]. In tone languages, there is also a relationship between word meaning and specific intonation patterns. The prosody prediction component expresses the prosodic realization of the underlying meaning and structure encoded within the text using symbolic information (e.g., stress patterns, intonation and breath groups) and sometimes parametric information (e.g., pitch, amplitude and duration trajectories). Parametric information may be quantized and used as a feature in the selection process, or directly within a parametric synthesizer, or both.
In most languages, the relationship between graphemes (i.e., letters) and the representation of sounds (the phonemes) is complex. In order to simplify the selection of the correct sounds, TTS systems first convert the grapheme sequence into a phonetic sequence which more closely represents the sounds to be spoken. TTS systems typically employ a combination of large pronunciation lexica and grapheme-to-phoneme (G2P) rules to convert the input into a sequence of phonemes. A pronunciation lexicon contains hundreds of thousands of entries (typically morphemes, but also full-form words) each consisting of phonetic representations of pronunciations of the word, but sometimes also other information such as part-of-speech. Pronunciations may be taken directly from the lexicon, or derived through a morphological parse of the word in combination with lexical lookup. No lexicon can be complete, as new words are continually being introduced into a language. G2Ps use phonological rules to generate pronunciations for out-of-vocabulary words.
The final stage in generating a phonemic sequence is post lexical processing, where common continuous speech production affects such liaison, assimilation, deletion and vowel reduction are applied to the phoneme sequence [49]. Speaker-specific transforms may also be applied to convert the canonical pronunciation stored in the lexicon or produced by the G2P rules into idiomatic pronunciations.
As previously stated, the back-end consists of two stages: unit selection and synthesis. There are two widely adopted forms of synthesis the most widely adopted of which is concatenative synthesis, whereby the selected sound fragments indexed by the units are optionally joined. Signal processing such as Pitch Synchronous Overlap and Add (PSOLA) may be used as an aid to smoothing the joins and to offer greater prosodic control at the cost of some signal degradation [47]. Parametric synthesis – for example, the widely used “HMM synthesis” approach – uses frames of spectrum and excitation parameters to drive a parametric speech synthesizer [50].
Table 3.2 highlights the differences between concatenation and parametric methods. As can be seen, concatenation offers the best fidelity at the cost of flexibility and size, while parametric synthesis offers considerable flexibility at a much smaller size but at the cost of fidelity. As a result, parametric solutions are typically deployed in embedded applications where memory is a limiting factor.
Table 3.2 Differences between concatenation and parametric methods
| Category | Concatenation synthesis | Parametric synthesis |
| Speech quality | Uneven quality, highly natural at best. Typically offers good segmental quality, but may suffer from poor prosody. | Consistent speech quality, but with a synthetic “processed” characteristic. |
| Corpus-size | Quality is critically dependent upon the size of the sound database | Works well when trained on a small amount of data |
| Signal manipulation | Minimal to none | Signal manipulation by default. Suitable for speaker and style adaptation. |
| Basic Unit topology | Waveforms | Speech parameters |
| System footprint | Simple coding of the speech inventory leads to a large system footprint | Heavy modeling of the speech signal results in a small system footprint. Systems are resilient to reduction in system footprint. |
| Generation quality | Quality is variable depending upon the length of continuous speech selected from the unit inventory. For example, limit domain systems, which tend to return long stretches of stored speech during selection, typically produce very natural synthesis. | Smooth and stable, more predictable behavior with respect to previously unseen contexts. |
| Corpus-quality | Need accurately labeled data | Tolerant towards labeling mistakes |
Unit selection [51, 52] attempts to find an optimal sequence of units ![]() from the pre-generated database which describes a target sequence
from the pre-generated database which describes a target sequence ![]() of features produced by the front-end for an analyzed sentence (Figure 3.12). Two heuristically derived cost functions are used to constrain the search and selection. These are unit costs (how closely unit features in the database match those of an element in the target sequence) and join costs (how well adjacent units match). Typically dynamic programming is used to construct a globally optimal sequence of units which minimizes the unit and join costs.
of features produced by the front-end for an analyzed sentence (Figure 3.12). Two heuristically derived cost functions are used to constrain the search and selection. These are unit costs (how closely unit features in the database match those of an element in the target sequence) and join costs (how well adjacent units match). Typically dynamic programming is used to construct a globally optimal sequence of units which minimizes the unit and join costs.
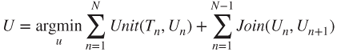
In HMM selection, the target sequence ![]() is used to construct an HMM from the concatenation of context clustered triphone HMMs. An optimal sequence of parameter vectors can be derived to maximize the following:
is used to construct an HMM from the concatenation of context clustered triphone HMMs. An optimal sequence of parameter vectors can be derived to maximize the following:
Where ![]() is the parameter vector sequence to be optimized,
is the parameter vector sequence to be optimized, ![]() is an HMM and
is an HMM and ![]() is the length of the sequence. In contrast to unit selection methods, which determine optimality based on local unit costs and join costs, statistical methods attempt to construct an optimal sequence which avoids abrupt step changes between states through a consideration of 2nd order features [50]. While still not widely deployed, there is also an emerging trend to hybridize these two approaches [53]. Hybrid methods use the state sequence to simultaneously generate candidate parametric and unit sequences. The decision on which method to select is made at each state, based on phonological rules for the language and an appreciation of the modeling power of the parametric solution.
is the length of the sequence. In contrast to unit selection methods, which determine optimality based on local unit costs and join costs, statistical methods attempt to construct an optimal sequence which avoids abrupt step changes between states through a consideration of 2nd order features [50]. While still not widely deployed, there is also an emerging trend to hybridize these two approaches [53]. Hybrid methods use the state sequence to simultaneously generate candidate parametric and unit sequences. The decision on which method to select is made at each state, based on phonological rules for the language and an appreciation of the modeling power of the parametric solution.
There are two fundamental challenges to generating natural synthetic speech. The first challenge is representation, which is the ability of the FE to identify and robustly extract features which closely correlate with characteristics observed in spoken language, and the companion of this, which is the ability to identify and robustly label speech data with the same features. A database of speech indexed with too few features will lead to poor unit discrimination, while an FE which can only generate a subset of the indexed features will lead to units in the database never being considered for training or selection. In other words, the expressive power of the FE must match the expressive power of the indexing.
The second challenge is sparsity, that is sufficient sound examples must exist to adequately represent the expressive power of the features produce by the FE. In concatenation synthesis, sparsity means that the system is forced to select a poorly matching sound, simply because it cannot find a good approximation. In HMM synthesis, sparsity results in poorly trained models. The audible effects of sparsity increase as the styles of speech become increasingly expressive. Sparsity can, to some extent, be mitigated through more powerful speech synthesis models, which are capable of generating synthetic sounds from high-level features. Recently, techniques such as CAT (Cluster Adaptive Training, [54]) and DNN (Deep Neural Networks [Zen et al., 2013 [55]]) are being used to make the best use of the available training data by avoiding fragmentation that compounds the effects of sparsity.
As suggested by Table 3.2, the commercial success of concatenation is due to the fact that high fidelity synthesis is possible, provided care is taken to control the recording style and to ensuring sufficient sound coverage in key application domains, when constructing the speech unit database. Surprisingly good results can be achieved with relatively simple FE analysis and simple BE synthesis. However, technologically, such approaches are likely to be an evolutionary cul-de-sac. While many of the traditional markets are well served by these systems, they are expensive and time-consuming to produce.
The growing commercial desire for highly expressive personalized agents is driving a trend towards trainable systems, both in the FE, where statistical classifiers are replacing rule-based analysis methods, and in the BE, where statistical selection and hybridized parametric systems are promising flexibility combined with fidelity [53]. The desire to synthesize complex texts such as news and Wikipedia entries more naturally is forcing developers to consider increasingly complex text analysis through the inclusion of semantic and pragmatics knowledge in the FE, and consequently, increasingly complex statistical mappings between these abstract concepts and their acoustic realization in the BE [54].
3.8 Natural Language Understanding
As we have suggested, speech is a particularly effective way of interacting with a mobile assistant. The user's spoken utterances constitute commands for specific system actions and requests for the system to retrieve relevant information. A user utterance is first passed to an automatic speech recognition module that converts it to text. The recognized text is then passed to a natural language understanding (NLU) module that extracts meaning from the utterance. In real-world situations, the recognized text may contain errors, and thus it is common practice to output a “top-N” list of alternative hypotheses or a results lattice to make it possible for the NLU to explore alternative candidate answers. Accurate meaning extraction is necessary for the system to perform the correct action or retrieve the desired information.
The complexity of the NLU module depends on the capabilities that the system offers to the user, and on the linguistic variation expected in the user's utterance. Many current spoken dialog systems are limited in the range of tasks that they can perform, and require relatively limited and predictable inputs from the user in order to carry out those tasks. For example, a restaurant reservation system needs to fill a certain number of slots (restaurant, time, number of people) in a standard action-template in order to make a reservation. Likewise, a television interface might only need a specification of a particular movie or show to determine which channel it can be viewed on and to put it up on the screen.
Some systems have a high degree of system initiative. They ask fully specified questions to fill in the necessary slots, and they expect answers to only the questions that were posed. For example, for the question, “who would you like to call?” a database lookup can fill in the phone number slot if the recognized text matches a known name. Or, for the question, “on what date is your flight?” a regular expression can be used to match the various ways a user could express a date.
3.8.1 Mixed Initiative Conversations
In [56], Walker & Whitaker observed that more natural conversations display mixed initiative. In human-to-human dialogs, one person may offer additional relevant information beyond what was asked, or else may ask the other person to change away from the current task. Dialog systems hoping to perform in a mixed-initiative setting must therefore prepare for utterances that do not directly provide the expected information. A restaurant system might ask “where do you want to eat?” when the user is focusing on the time and instead replies with “We want a reservation at 7.” The utterance is relevant to one of the restaurant-reservation slots, but not the one that the system was expecting. This requires an NLU component that can decode and interpret more complex inputs than simple direct-answer phrases.
There are also many ways in which a user can give a direct answer to a slot-filling question. For example, the user could respond to the question “where do you want to eat?” with a variety of restaurant characteristics, as illustrated in the first column of the following table:
| User utterance | Slot-value pairs |
| Thai Basil | Name: “Thai Basil” |
| An Indian restaurant | Cuisine: “Indian” |
| A restaurant in San Francisco | Location: “San Francisco” |
| I'd like to eat at that Michelin-starred Italian restaurant in San Francisco tomorrow at 8 pm | Cuisine: “Italian” Rating: “Michelin-starred” Location: “San Francisco” Date: “tomorrow” Time: “8 pm” |
The system needs to fill a high-level slot that identifies a particular restaurant, but the information may be provided indirectly from a collection of lower-level slot-values that narrow down the set of possibilities. Note that the responses can express different slots in different orders, with variation in the natural language phrasing. The last expression shows that a single response can provide fillers for multiple slots in a fairly elaborate natural language description. The target slot names are domain-specific; they typically correspond to column names in a back end database. Given a set of slot-value pairs, application logic can retrieve results from the back-end database.
The task of the NLU module is to map from utterances in the first column to their slot-value interpretations in the second column. The NLU module must handle the variations in phrasing and ordering, if it is to find the meaning with a high level of accuracy. A simple strategy for NLU is to match the utterance against a template pattern that instantiates the values for the slots:
| Query | Pattern template |
| Thai Basil | [name] |
| a Chinese restaurant | a [cuisine] restaurant |
| a Chinese restaurant in San Francisco | a [cuisine] restaurant in [location] |
In this simple approach, every phrase variation would require its own template. A more sophisticated pattern matcher could use regular expressions, context-free grammars, or rules in more expressive linguistic formalisms, so that a few rules could cover a large number of variations. In any case, these approaches need to resolve ambiguities that arise in the matching.
The templates or rules give the context in which specific entities or key phrases are likely to occur. The Named Entity Recognition (NER) task is often a separate processing step that picks out the substrings that identify particular entities of interest (the restaurant name and cuisine-type in this example). Machine learning approaches like the one in [57] are typically used for named entity detection. These techniques have been designed to handle variations in phrasing and ambiguities in the matching, but they require a large set of example utterances marked up with the correct slot-value pairs. The marked-up utterances are then converted into IOB notation, where each word is given one of the following kinds of tags:
| Tag type | Description |
| I | Inside a slot |
| O | Outside a slot |
| B | Begins a slot |
The ![]() and
and ![]() tags have a slot name associated with them. An example of an IOB-tagged utterance is:
tags have a slot name associated with them. An example of an IOB-tagged utterance is:
| IOB tags | O | B Cuisine | O | O | B Location | I Location |
| Utterance | An | Italian | Restaurant | In | San | Francisco |
The IOB-tagged utterances comprise the training data for the machine learning algorithm. At this point, the task can be regarded as a sequence classification problem. A common approach for sequence classification is to predict each label in the sequence separately. For each word, the classifier needs to combine features from the surrounding words and the previous tags to best estimate the probability of the current tag. A well-studied approach for combining evidence in a probabilistic framework is the conditional maximum entropy model described in [58]:
where ![]() and
and ![]() are the tag and available context (resp.) for the word at position
are the tag and available context (resp.) for the word at position ![]() . The
. The ![]() denote features that encode information that is extracted from the available context, which typically consists of a few previous tags, the current word, and a few surrounding words. The
denote features that encode information that is extracted from the available context, which typically consists of a few previous tags, the current word, and a few surrounding words. The ![]() are the parameters of the model; they effectively weight the importance of each feature in estimating the probability. A search procedure (e.g., Viterbi) is then used to find the maximum probability tag sequence.
are the parameters of the model; they effectively weight the importance of each feature in estimating the probability. A search procedure (e.g., Viterbi) is then used to find the maximum probability tag sequence.
It is not desirable to collect training data that mentions every possible value for the slots. Furthermore, features that include explicit words do not directly generalize to similar words. For these reasons, machine-learned approaches often use external dictionaries. If a word or phrase exists as a known value in a dictionary, the model can use that knowledge as a feature. Both [57] and previously [59] use maximum entropy models to combine contextual features and features from external resources such as dictionaries. More generally, words can automatically be assigned to classes based on co-occurrence statistics as shown in [60], and features based on these word classes can improve the generalization capability of the resulting model, as shown in [61].
Recent neural net approaches such as [62] attempt to leverage an automatically derived mapping of words to a continuous vector space where similar words are expected to be “close”. Features in this approach can then directly make use of particular coordinates of these vector representations.
The conditional random field (CRF), described in [63] is another model for sequence classification that produces a single probability for the entire sequence of labels, rather than one label at a time. See [64] for an example of CRFs applied to named entity detection.
3.8.2 Limitations of Slot and Filler Technology
A mobile assistant can complete many tasks successfully, based only on values that the NER component identifies for the slots of an action template. Regarding the slot values as a set of individual constraints on elements in a back-end database, systems often take their conjunction (e.g. “Cuisine: Italian” and “Location: San Francisco”) as a constraint on the appropriate entries (“Zingari's”, “Barbacco”) to extract from the back-end. This rudimentary form of natural language understanding is not enough if the user is allowed to interact with more flexible utterances and more general constraints.
Consider the contrast between “an Italian restaurant with live music” and “an Italian restaurant without live music”. These mention the same attributes, but because of the preposition they describe two completely different sets of restaurants. The NLU has to recognize that the prepositions express different relations, that “without” has to be interpreted as a negative constraint on the fillers that can fill the Name slot and not a specific set of restaurants. Prepositions like “with” and “without”, and other so-called function words, are often ignored as stop-words in traditional information retrieval or search systems, but the NLU of a mobile assistant must pay careful attention to them.
Natural languages also encode meaning by virtue of the way that the particular words of an utterance are ordered. The description “an Italian restaurant with a good wine list” does not pick out the same establishments as “a good restaurant with an Italian wine list”, although presumably there will be many restaurants that satisfy both descriptions. Here the NLU must translate the order of words into a particular set of grammatical relations or dependencies, taking into account the fact that adjectives in English typically modify the noun that they immediately precede. These relations are made explicit in the following dependency diagrams.
Figure 3.13 represents the output of a dependency parser, a stage of NLU processing that typically operates on the result of a name-entity recognizer. A dependency parser detects the meaningful relationships between words, in this case showing that “Italian” is a modifier of “restaurant”, that the preposition “with” introduces another restriction on the restaurant, and that “good” modifies “wine list”.

Figure 3.13 Dependency diagram 1.
Dependency parsers also detect relationships within full clauses, identifying the action of an event and the participants and their specific roles. The subject and object labels shown in the Figure 3.14 restrict the search for movies to those in which Harry is saved by Ron and not the other way around. The grammatical patterns that code dependencies can be quite complicated and can overlap in many ways. This is a potential source of alternative interpretations in addition to the ambiguity of named-entity recognition, as shown in Figure 3.15.

Figure 3.14 Dependency diagram 2.

Figure 3.15 Dependency diagram 3.
According to the grammatical patterns of English, the “after” prepositional phrase can be a modifier of either “book” or “table”. The interpretation in the first case would be an instruction to do the booking later in the day, after the meeting. The second and more likely interpretation in this context is that the booking should be done now for a table at the later time. A dependency parser might have a bias for one of the grammatical patterns over the other, but the most plausible meaning might be based on information available elsewhere in the dialog system – for example, in an AI and reasoning module that can take into account a model of this particular's past behavior or knowledge of general restaurant booking conventions.
Machine learning approaches have also been defined for dependency parsing [65, 66]. As for named entity recognition, the task is formulated as a classification problem, driven by the information in a large corpus annotated with dependency relations. One technique considers all possible dependencies over the words of the sentence and picks the maximum spanning tree, the collection of dependencies that scores best against the training data [67]. Other techniques process a sentence incrementally from left to right, estimating at each point which of a small set of actions will best match the training data [68]. The actions can introduce a new dependency for the next word or save the next word on a stack for a later decision.
There are also parsers that produce dependency structures or their equivalent by means of large-scale manually written grammars [69–71]. These are based on general theories of language and typically produce representations with much more linguistic detail. Also, they do not require the construction of expensive annotated corpora and are therefore not restricted by the phenomena that such a corpus exemplifies. However, they may consume more computational resources than statistically trained parsers, and they require more linguistic expertise for their development and maintenance. These considerations may dictate which parsing module is most effective in a particular mobile assistant configuration.
Dependency structures bring out the key grammatical relations that hold among the words of a sentence. But further processing is necessary for the system to understand the concepts that the words denote and to translate them into appropriate system actions. Many words have multiple and unrelated senses that the NLU component must be able to distinguish. It is often the case that only one meaning is possible, given the tasks that the mobile assistant can perform. The word “book” is ambiguous even as a verb (make a reservation vs. put someone in jail), but the first sense is the only plausible one for a reservation-making assistant. It takes a little more work to disambiguate the word “play”:
- Who played Serena Williams?
- Who played James Bond?
The same word has the “compete-with” sense in the first question and the “act-as” meaning in the second. Which sense is selected depends on the type of the object. The compete-with sense applies if the object is an athlete, the act-as is selected if the object denotes a theatrical character. Disambiguation thus depends on named entity recognition (to find the names), reference resolution (to identity the entities that the names refer to), and parsing (to assign the object grammatical relation). In addition, disambiguation depends on ontological reasoning: the back-end knowledge component knows that Serena Williams is a tennis player, tennis players are classified as athletes, and that category matches the object-type condition only of the compete-with sense.
The reasoning needed for disambiguation is not tied to just looking up the categories of names. Category information for definite and indefinite descriptions is also needed for disambiguation, as in:
- Who played the winner of the French Open?
- Who played a Stradivarius?
The first case needs information about what sorts of entities are winners of sporting events, namely athletes; the second case requires information about what a Stradivarius is, namely a stringed instrument. This information can then be fed into a module that can traverse the ontology to reason, for example, that stringed instruments are objects that make sounds and thus match the object-type condition for play in the sense of making music.
These examples fit within RDFS [72], a small ontology language used in conjunction with RDF, the “resource description framework” [73] for representing simple information about entities in the Semantic Web. RDFS permits representation of types of object (as in Serena Williams is a tennis player and a person), generalization relationships between these types (as in a tennis player is an athlete), and typing for relationships (as in a winner is a person).
More complex chains of reasoning can also be required for disambiguation, including combining information about multiple entities or descriptions. In these more complex cases, a more powerful ontology language may be required, such as the W3C OWL Web Ontology Language [74]. OWL extends RDFS with the ability to define categories (such as defining a man as a male person) and providing local typing (such as the child of a person being a person). Ontological reasoners are a special case of the more general knowledge representation and reasoning capabilities that may be needed not only to resolve more subtle cases of ambiguity, but also for the planning and inferences that underlie more flexible dialog interactions (see section 3.10.6). These may require the ability to perform more intricate logical deductions (e.g., in first-order predicate logic) at a much higher computational cost than relatively simple ontology-based reasoning.
Certain words in a user input take their meaning from the context in which they are uttered. This is the case for pronouns and other descriptions that refer to entities mentioned earlier in the conversation. If the system suggests a particular restaurant that satisfies all of the requirements that the user has previously specified, the user may further ask “Does it have a good wine list?” The system then must recognize (through a process called anaphora resolution – see Mitkov, [75]) that the intended referent of the pronoun “it” is the just-suggested restaurant. The user may even ask “What about the wine list?”, a question that does not contain an explicit pronoun but yet is still interpreted as a reference to the wine list of the suggested restaurant. The linkage of the definite description (“the wine list”) to the particular restaurant depends on information from an ontology that lists the parts and properties of typical restaurants.
There are other words and expressions that do not refer to entities previously mentioned in the conversation. Rather, they point directly to objects or aspects of the situation in which the dialog takes place. Demonstrative pronouns (this, that, those …) and other so-called indexical expressions (now, yesterday, here, there …) fall into this class. If the dialog takes place while the user is driving in a car, the user may point to a particular restaurant and ask, “Does that restaurant have a good wine list?” In this case the dialog system must recognize that the user is making a pointing gesture, identify the target of that gesture as the indicated restaurant, and offer that information to the NLU component so that it can assign the proper referent to the “that” of the user's utterance.
Other aspects of the dialog context (e.g., current location and time) must similarly be taken into account if the user asks “Are there any good restaurants near here?” or “What movies are starting an hour from now?” These examples show that a dialog system must be able to manage and correlate information of different modalities coming in from different channels. One tool for handling and synchronizing multi-modal information is EMMA, the W3C recommendation for an extensible multi-modal annotation mark-up language [76].
3.9 Multi-turn Dialog Management
An NLU module of the form discussed above can suffice for a single-turn dialog system, in which the user interaction is complete after a single utterance. However, in multi-turn dialog systems, the NLU must interpret a user utterance in the context of the questions, statements, and actions of the system, as well as the previous user utterances. This requires that the system needs to be able to recognize and track the user's intent throughout the dialog.
It is useful to divide the space of user intents into dialog intents and domain intents [77]. Dialog intents signal the start of a sub-dialogue to clarify, correct, or initiate a new topic and they are domain-independent. Domain intents signal the user's desire to inform the system or demand a specific system's action. As argued by Young (1993) [77], both types of intents need to be modeled and tracked through the course of a complex, multi-turn dialog.
An approach to intent tracking is referred to as dialog state tracking [78]. Each user's utterance is first processed by the NLU module to find (via classification) the dialog intent (inform/ask/correct) and the domain intent (play/record movies, reserve tables), and to extract the slot-value pairs from the utterance. Extracted information (which includes probabilities to model uncertainty) from the current utterance is fed to a dynamic model (such as a Dynamic Bayesian Network) as an observation. Belief updating via Bayesian update is then employed to help remove or reduce uncertainty based on the system's belief state prior to the current utterance.
| System | Where would you like to eat? |
| User | An Italian restaurant in San Francisco. |
| System | I found several Italian restaurants in San Francisco. Here they are… |
| User | Actually I prefer a Chinese restaurant tonight at 7. |
| System | I found several Chinese restaurants in San Francisco with tables available at 7 pm tonight. Here they are… |
In this example, in order to interpret the last user utterance correctly, a dialog state tracker classifies the utterance as a correction intent and hence overwrites the cuisine type mentioned in the previous utterance. As a result, the system is able to combine the cuisine, date, and time slots from the last user utterance with the location from the first user utterance. Such a system architecture is attractive, as it is robust in dealing with the uncertainty and ambiguity inherent in the output of a speech recognition/NLU pipeline.
While tracking dialog intents is necessary for dealing with the natural flow of spoken dialog, recognizing the domain intents is also needed so that the system is aware of the user's ultimate goal and can take actions to fulfill it. The user's domain intents are often complex and organized in a hierarchical manner similar to an AI plan [79]. Therefore, various hierarchical structures, ranging from and-or task networks [79] to probabilistic hierarchical HMMs [80], have been proposed to model complex intents. Robust probabilistic modeling of complex intents, while moving beyond slot-value pairs, requires even more expressive representations that can combine both probabilistic and logical constructs. Such a hybrid modeling approach is an active current research area in AI [81].
Based on the state of the dialog, the system must adjust its expectations and find a suitable response. Dialog managers like RavenClaw [82] are used to guide the control flow so that the system prompts for the information that is necessary for the system to complete its tasks. Dialog managers in mixed-initiative settings must use the NLU module to detect task changes at unexpected times in the conversation. Complex dialogs also require an error recovery strategy.
Thus, natural language understanding in dialog needs to happen in close collaboration with a dialog management strategy. As we have observed, utterance complexity can range from simple words or phrases that exactly match a known list, all the way to open-ended utterances that give extra information or ask to switch tasks at unexpected times. Accurate NLU modules handle linguistic variation using a combination of training data and manually specified linguistic resources, including dictionaries, grammars, and ontologies. One of the challenges for the NLU module is to interpret properly utterances that are only fragments of full sentences, simple words or phrases. The utterance “9 am” would be understood as filling the departure-time slot in a flight-reservation dialog if the system had just asked “When do you want to leave?”, but the arrival-time slot for the question “When do you want to arrive?” The dialog manager holds the state of the dialog and can provide the dialog-context information that may simplify the task of interpreting fragmentary inputs.
An early, simple proposal for communicating contextual information to the NLU component is for the dialog manager to predict a set of linguistic environments that will help the NLU to “make sense” of the user's next utterance [83]. If the system has asked “When do you want to leave?” then the dialog manager can provide the declarative prefix “I want to leave at…” to concatenate to the front of whatever the user says. If the user's reply is “9 am”, the result after concatenation is a full, interpretable sentence to which a complete meaning can be assigned, according to the normal patterns of the language. In a mixed initiative setting, the user is not constrained to give a direct or minimal answer to the system's question, and so the dialog manager can provide a set of alternative prefixes in anticipation of a range of user utterances:
- [I want to leave] “at 9 am”
- [I want to leave on] “Tuesday at 9 am”
The claim of this approach is that there are a small set of linguistic patterns that provide the environment for a natural and meaningful user response to a query; it would be very odd and confusing, even to a human, if the user responded to this question with “Boston” instead of a time or date. Of course, the user may choose not to address the question at all and to provide other information about the trip or even to shift to another task. The natural utterance in that case will be a full sentence, and the dialog manager can anticipate that with the empty linguistic environment:
- [] “I want a flight to Boston”
This is one way in which the dialog manager and the NLU component can be partners in determining the meaning of a user's next utterance. The dialog manager can feed expectations, based on the current state of the dialog, forward to the NLU in a way that may simplify the overall system, while also leading to more appropriate dialog behaviors.
The output of the NLU module provides the information that the dialog manager needs to determine the user's intents and desires (e.g. search for a restaurant in the area, watch a movie, book a flight, or simply get information on the first president of the United States). The dialog manager also takes into account the system's capabilities (e.g., access to a local TV listing, ability to control Netflix, or access to real time traffic information and ability to give driving directions), the user's behaviors and preferences, and the interaction history.
If the user's intents and desires can be satisfied, then the system simply performs the appropriate domain action. Otherwise, its task is to figure out “what to say next” according to a dialog strategy [84] in order to get more information from the user and eventually satisfy the user's needs. Once the question of “what to say” is answered, the natural language generation (NLG) module takes over and answers the question of “how to say it” (i.e., decide the best way to communicate it to the user).
Even though the dialog manager is such an essential component of a spoken dialog system, the research and implementation community differs on its definition and necessary functionalities. However, it is agreed that a dialog manager should minimally cover two fundamental aspects of an interaction system, namely to keep track of the dialog state and to decide the next course of action.
There are many different ways that these two functionalities can be implemented. Most commercial systems and some research systems largely rely on some form of Finite State Machine (FSM) [84]. The FSM approach requires every change in the dialog to be explicitly represented as a transition between two states in the network, and assumes that the user inputs can be restricted or directed by the system prompts. This means that the dialog manager is not very flexible and cannot handle unexpected situations. It is not practical for a more complex system to adopt such an approach, because one would have to specify fully all of the possible choices in every turn of the dialog. Furthermore, such an approach makes it almost impossible to have any degree of mixed initiative.
These deficiencies give rise to the Functional Model approach [85–88]. This is essentially an extension to the traditional FSM that allows the finite state machine to assume any topology, to invoke any arbitrary action at each state, and to assume any arbitrarily complex pre-condition on the transitions. These extensions make it possible to allow for over-specified user utterances, which is a form of mixed-initiative. In contrast, the information State Update approach [89, 90, 82] uses frames or tree structures as control mechanisms, while also allowing for unexpected user utterances. However, the conversations that are handled by any of these systems are usually of the slot-filling type. The system only asks users questions when a parameter of the required task is not specified.
In order to handle more complex tasks that involve collaborative problem solving, intelligent assistants, and tutorial dialogs, the dialog system is often implemented with planning technologies [91, 92]. More recently, statistical systems using machine learning approaches, more specifically Reinforcement Learning (RL) approaches, have become more prevalent in the research community. These approaches model a dialog strategy as a sequential decision-making process called Partially Observable Markov Decision Process (POMDP). Frampton and Lemon (2009) [93] give a comprehensive overview of the research efforts aimed at employing RL in spoken dialog systems.
These approaches give the developers a precise formal model for data-driven optimization instead of depending on strategies by experts with expertise and intuition. They also provide possibilities for generalization to unseen states and adaptation to unknown contexts. However, they have been criticized for the large amount of data needed to train for the dialog strategies and the need for more principled techniques to construct the state space, reward function and objective function used for strategy optimization. There is also a lack of understanding of how the learned policy from such a system can be intuitively understood by humans and modified if needed. Furthermore, the complexity of solving a POMDP often limits the richness of the dialog system representation.
More recent studies in the area begin to address these issues, such as using hierarchical RL to reduce the size of the state space [94]. Another strategy is to learn a simulated environment from a small collection of “Wizard of Oz” data, making it possible to employ RL techniques without extensive human-human dialog data [95].
Recent years have seen the commercial deployment of spoken dialog systems that are used by large populations on a day-to-day basis, particularly because of their distribution on mobile devices. However, these systems still lack many important functionalities. They can perform certain predefined tasks very well, based on slot-filling conversations, but they often revert either to generic web search or domain-specific search for particular services (restaurants, phone contacts, movies).
There are virtually no collaborative planning or problem-solving capabilities to extend system behavior to handle difficult or unpredicted inputs, or inputs that require clarification and refinement through a sequence of flexible, multi-turn interactions with the user that take into account more of the history and context of the dialog. The dialog research community is experimenting with new technologies and new system configurations that will support much more natural and effective conversational agents in a broader range of domains and settings. These systems will appear in the not too far distant future, as new techniques for integrating machine learning, artificial intelligence and reasoning, user-interface design, and natural language understanding are developed.
3.10 Planning and Reasoning
In this section, we will examine some of the deeper levels of processing that will play an increasingly important role in future dialog systems. These include deeper semantic analysis, discourse representation, pragmatics, and knowledge representation and reasoning. We will begin by highlighting some of the technical challenges in the context of a running example, followed by a brief overview of the relevant state-of-the-art.
3.10.1 Technical Challenges
Consider the following mock dialog with an automated Virtual Assistant (VA) of the future:
- Bob> Book a table at Zingari's after my last meeting and let Tom and Brian know to meet me there.
- VA> Sorry, but there aren't any tables open until 9 pm. Would you like me to find you another Italian restaurant in the area at about 6:30 pm?
- Bob> Can you find a table at a restaurant with a good wine list?
- VA> Barbacco has an opening. It's in the Financial District but the travel time is about the same.
- Bob> Ok. That sounds good.
Utterance (1) is ambiguous in terms of the time of the requested reservation: should it take place after the meeting or should it be performed now? Resolution of this ambiguity requires background commonsense knowledge that needs to be represented by the system: reservations should be done as early as possible, otherwise the space in a restaurant might fill up. There are default assumptions that are also necessary to correctly interpret this exchange: the referenced “last meeting” is today's last meeting and not tomorrow's.
The reasoning here involves an appeal to general principles of communication [96]. People tend to be as informative as needed; if the person wanted the dinner tomorrow, he would have said so. However, this is again no more than a defeasible assumption, as it need not always hold; imagine the dialog having been prefaced with some discussion about what the person had planned for tomorrow. Similarly, the interpretation of the prepositional phrase, “after my last meeting” must be handled in a similar fashion, as tomorrow or the day after, for example, would also satisfy that constraint.
Of course, the above inferences regarding the time of the planned dinner are only approximate; a scheduler will need more exact information. The system could explicitly ask for the time, but a truly helpful assistant should make an effort to “fill in the blanks” as much as possible; here, the system should attempt to create some reasonable expectation regarding the best time for the dinner. Toward that end, the VA can try to base its reasoning on knowledge of past behavior; it may know that Bob works until 5 pm and that he typically spends 30 minutes on email before leaving work. Such information would reside in a user model of typical behavior that, as we shall see, should likely also include information about the user's desires or preferences. In addition, the system should factor in travel time based on possible locations of whatever restaurant is chosen. Finally, the identity of Tom and Brian must be ascertained. This is information that, again, would be kept in a user model of friends and phone numbers.
It is worth highlighting the important general principle that this utterance illustrates – the dialog system must be able to take a variety of contextual factors into account as it engages with the user. These include elements of the conversational history, as we have indicated before, but also many non-conversational aspects of the user and the situation in which the dialog takes place. Appropriate system behavior in different settings may depend, for example, on the time of day, the user's physical location, current or anticipated traffic conditions, music that the user has recently listened to or movies that have been recently watched. The dialog system must receive and interpret signals from a variety of sensors and must maintain a history not only of the conversation, but also of previous events and actions.
In utterance (2), we see that the initial search for a restaurant satisfying the expressed and implied constraints fails. An uninformative response such as “No” or “I could not find a restaurant for you” would hardly be helpful. A pragmatically more informative response is provided here in terms of a gloss of the reasons for the failure, and then an attempt to propose alternatives. Alternatives can be sought by relaxing some of the less important constraints; in this case, the specification of the type of restaurant and the time of the dinner are relaxed. This activity should be the responsibility of a dialog management module that guides the system and user to reach agreement on an executable set of constraints, while accessing the user model as much as possible to capture the relative importance of the constraints.
In utterance (3), we have what is known in the literature as an indirect speech act [97–99], which is discussed in more detail in section 3.13.3. If we take the utterance literally, it can be answered with a simple yes or no. However, neither would be very satisfying; the utterance, in fact, is a disguised request to perform an action. The action implicitly referred to is the dinner reservation. With respect to management of the dialog, notice that the user himself has implicitly responded to the question posed in (2). This again falls out of general principles of communication having to do with conciseness of expression. Since the user does not disagree, there is an implicit confirmation and, in the process, a new constraint is exposed by the user – the availability of a good wine list. At some point, these constraints must be collected to drive a search. This requires that the interpretation of utterances should be properly constrained by the relevant previous utterances. In (3), it means that the request should be interpreted as a request to find an Italian restaurant with a good wine list. At this point, a number of relevant databases and websites can be brought to bear on the search.
As the dialog progresses to (4), the VA informs the user that it has dropped one of the earlier constraints (“restaurant in the area”) in preference to others, such as “the same travel time”, “Italian restaurant”, and “tonight”, through the same sort of process employed during the processing of utterance (2). Bob then confirms the proposal in (5) and the dialog ends. The VA can now go to an appropriate online website to make the reservation and send the requested emails to Tom and Brian. However, the duties of a good assistant are not yet complete. It must be persistent and proactive, monitoring the plan for unexpected events such as delays and responding in a helpful manner.
Given these technical challenges, what follows is an overview of some of the most common approaches found in the literature to address these problems.
3.10.2 Semantic Analysis and Discourse Representation
Much of the dialog that involves virtual assistance is about actions that need to be taken in the world. From the perspective of semantic and discourse levels of analysis, one approach is to reify events and map the syntactic structure into a first order logical representation in which constant symbols stand for particular events (say, the assassination of Kennedy) that can have properties (e.g., a “killing”) and relations to other events. Consider the fragment, “Can you find me a restaurant”, of utterance (3). The following formula represents such a translation:
This can be glossed as saying that the variable ![]() represents a surface request (see below) whose agent is Bob and the request is in terms of
represents a surface request (see below) whose agent is Bob and the request is in terms of ![]() , an event of type “find” performed by agent VA(a virtual assistant is also sometimes called a Personal Assistant, PA). The object of the “finding” event is
, an event of type “find” performed by agent VA(a virtual assistant is also sometimes called a Personal Assistant, PA). The object of the “finding” event is ![]() , which is a restaurant. The advantage of such a representation is that one can conjoin additional properties of an event in a declarative fashion: for example, one can add additional constraints, such as that the restaurant be Italian: italian
, which is a restaurant. The advantage of such a representation is that one can conjoin additional properties of an event in a declarative fashion: for example, one can add additional constraints, such as that the restaurant be Italian: italian ![]() . One problem, however, is that from a logical perspective the addition of such a constraint must be done by re-writing the entire formula, as the constraint must occur within the scope of the existential quantifiers.
. One problem, however, is that from a logical perspective the addition of such a constraint must be done by re-writing the entire formula, as the constraint must occur within the scope of the existential quantifiers.
One solution to this problem has been proposed by Discourse Representation Theory (DRT), according to which a dynamic model of the evolving discourse is maintained in structures that can be augmented with new information. The figure below shows such a Discourse Representation Structure (DRS) for the complete utterance (3). The “box” illustrated in Figure 3.16 lists a set of reference markers corresponding to the variables that we have mentioned: ![]() , and
, and ![]() , followed by a set of conditions involving those variables. Such structures can be augmented with new information and then, if desired, translated into a first order logic form for more general reasoning (as shown to the right).
, followed by a set of conditions involving those variables. Such structures can be augmented with new information and then, if desired, translated into a first order logic form for more general reasoning (as shown to the right).
| ∃e1∃e2∃x∃y.surface_request(e1,e2)∧agent(e1,Bob) ∧agent(e2,PA)∧find(e2)∧restaurant(x)∧object(e2,x) ∧food(x,Italian)∧open(x,t)∧has(x,y)∧wine(y)∧good(y) |
Figure 3.16 Discourse Representation Structure and statement in first order logic for “Can you find me an Italian restaurant with a good wine list?”
3.10.3 Pragmatics
There are many pragmatic issues that arose during the analysis of our target user-VA interaction. One particularly succinct expression of a set of general maxims that conversational agents should adhere to was proposed by the philosopher Grice [96]. These maxims state that a speaker should:
- Be truthful.
- Be as informative (but not more so) as necessary.
- Be relevant.
- Be clear, brief and, in general, avoid ambiguity.
How these maxims are to be captured computationally is, of course, a major challenge. They also represent only desirable default behavior; agents can violate them and, in the process, communicate something by doing so [100]. These maxims also reflect the efficiency of language – the fact that one can communicate much more than what is explicitly said. We saw an example of this in that utterance (3) needed to be interpreted relative to the prevailing context, in order to correctly ascribe to the user a request to find an Italian restaurant with a good wine list (and at the desired time and date).
The proper treatment of speech acts is also a central topic in pragmatics. Speech acts are utterances that are best interpreted as actions that can change the world somehow (specifically, the beliefs and intentions of other agents) as opposed to having a truth value based relative to a state of affairs. In the case of our VA, speech acts must be translated into intentions or commitments on the part of the VA to do something for the user. Often, the intention is not explicit but must be inferred. A simple example of the need for such inferences can be found in the above exchange; it probably escaped the reader that nowhere in the dialog does the user specify that he or she wants to eat dinner at the restaurant. This might appear to be a trivial observation, but if the VA decided to make a reservation at a restaurant which, for example, only served meals during the day or drinks at night, that choice would not satisfy the user's desires.
In the initial DRS for utterance (3), we have that the utterance was interpreted as a request to find a restaurant but, through a process of intention recognition, this is transformed to the structure shown in Figure 3.17. This represents a request to reserve the restaurant, the actual intent of the utterance. The plan recognition process works backwards from the find action and reasons that if a user wants to find a restaurant, it is probably because he wants to go to the restaurant, and if he wants to go to the restaurant a plausible precondition is having a reservation. In the helpful role that the VA plays, that translates to a task for the system to reserve the restaurant for the user.
Figure 3.17 Intent structure for “Can you find me an Italian restaurant with a good wine list?”
In additional to logic-based approaches to plan recognition [91, 92], probabilistic methods have been developed which can explicitly deal with the uncertainty regarding the system's knowledge of the (inner) mental state of the user [80].
3.10.4 Dialog Management as Collaboration
Many approaches have been put forward for managing a dialog and providing for assistance. Most approaches are grounded in the observation that dialogs commonly involve some associated task. A dialog, then, is a collaborative activity between two agents: a give-and-take in which the agents are participating in a task and, in the process, exchange information that allows them to jointly accomplish the task. The major approaches might be divided in the following way:
- Master-slave sorts of approaches, in which the interaction is tracked and managed relative to a set of pre-defined task hierarchies (which we will call recipes), sometimes with the speech acts represented explicitly.
- Plan-based approaches, which model the collaboration as a joint planning process in which a plan is a rich structure in which a recipe might not be defined a priori but constructed at run time.
- Learning approaches that attempt to acquire prototypical dialog interactions.
We will expand a bit on plan-based approaches, as they provide an attractive approach for also modeling the collaborative support that a VA needs to provide.
Plan-based models to dialog understanding architect an agent – be it a human, a computer system or a team – in terms of the beliefs, desires and intentions of an agent. Without going into philosophical details, it is enough to think of beliefs as capturing the information that a user has in a particular situation (for example, the availability of a table at a particular restaurant or the route to a particular location). Of course, an agent's beliefs can be wrong, and one of the responsibilities of the VA is to try to detect any mis-information that the user might have (e.g., he might incorrectly think that a particular restaurant is in another part of town). In a dialog setting, the agent's beliefs might reference those objects that are most “salient” or currently under discussion (e.g., “the Italian restaurant” that I am going to is “Zingari”).
Desires reflect the user's preferences (e.g., the user might prefer Italian over Chinese food; or the user might prefer to travel by freeway whenever possible). Intentions capture what the agent is committed to. For example, the system might be committed to making sure that the user gets to the restaurant in time for the reservation. It will therefore persistently monitor the status of the user's progress toward satisfying that intention.
One important role of a virtual assistant is to assist a user in elaborating the high-level intentions or plans that the user has communicated to the VA, using elements from a library of task recipes. Once a plan is elaborated upon, the resulting set of potential options (if there is more than one) are examined, and the one that has higher payoff (or utility, for example, get the user to the restaurant on time) is chosen for action.
3.10.5 Planning and Re-planning
Planning makes use of recipes that, as we said, encodes alternative means for performing actions. In our mock dialog, suppose that are three ways of making a reservation: online by going to Opentable, going to the restaurant website, or calling the restaurant directly. The user and the system would then jointly try to fill in the details to those recipes or compose them in some way. Each agent brings with it complementary capabilities and responsibilities. The dialog, then, captures the contributions that each makes or proposes to make toward advancing that joint goal.
Recipes include logical constraints on constituent nodes. They can be either deep structures defined a priori and instantiated for a particular goal, or they can be shallow decompositions which can be composed during the planning process. Figure 3.18 illustrates examples of the latter type in the context of our example. Building a complex structure out of these at planning time allows for more flexibility in accommodating unexpected contingencies.

Figure 3.18 Recipe structure.
3.10.6 Knowledge Representation and Reasoning
The system's knowledge about, for example, types of restaurants, travel times, and beverages and menus for restaurants are stored in a knowledge representation. First order logic, a very expressive knowledge representation, is one of the many options. For tractability, alternatives include ontology-based description logics that have been explored in connection with the Semantic Web. These are particularly effective for many examples of word-sense disambiguation, as mentioned in section 3.8.2. In some cases, specialized knowledge representations might be needed for temporal relations, default knowledge, and constraints, and these may require specialized reasoners.
Throughout, we have been referring to a user model of preferences. Preferences are directly related to the agent's desires. Preferences can be offered by a user, elicited by the VA, or learned by observation. They can be expressed either qualitatively, in terms of an ordering on states of the world, or numerically in terms of utilities. For example, we might have a simple user model that states that a user likes Peet's coffee. However, more interesting are statements which express comparative preferences, as in preferring Peet's over Starbucks. These are often called ceteris paribus preferences, as they are meant to capture generalizations, all other things being equal. Exceptions need to be dealt with, however. For example, one might also prefer espresso over American drip coffee, and from that one might want to be able to conclude that one would prefer Starbucks over a café (such as Peet's) with a broken espresso machine, that being the exceptional condition. As these preferences are acquired from the user, they must be checked for consistency, as the user might accidentally state circular or inconsistent preferences. If so, the system should engage the user in a dialog to correct such problems.
3.10.7 Monitoring
Let us continue the above scenario as follows.
- [VA notices that it is: 5:30 pm and Bob has not left the office, cannot get to the restaurant on time. MA phones Bob, via TTS]
- VA> Bob, you're running late. Should I change the reservation?
- Bob> Yes, I'll leave in about 30 minutes.
- [VA replans: Barbacco is not available later. Based on stored preferences, VA reserves at another similar restaurant.]
- VA> Barbacco could not extend your reservation, so I reserved a table for you at Capannina. They have a good wine list. I'll also let Tom and Brian know. Is that OK?
- Bob> Yes. Thanks.
- [VA sends text messages to Tom and Brian, sets up another monitor]
At the end of the original scenario, the VA sets up a monitor (a conditional intention) to make sure that the plan involving the choice of restaurant, reservation and dinner attendance can be completed. The intention is relative to the VA's beliefs. The conditional intention should be checked at every time step to see if it is triggered by some changing circumstances. In this case, if the VA comes to believe that Bob has not left his meeting by the expected time, then it should form the intention to replan the reservation activity.
In the remainder of the scenario, that is exactly what happens: the VA notices that Bob has not left the meeting. It checks the restaurant and finds that the reservation cannot be extended and so, as part of helpful collaborative support, it looks for alternative restaurants based on its knowledge of Bob's requirements for dinner and his preferences: the area of the restaurant, the type of food and the wine list. It locates a substitute, Capannina, which, although not in the same area, has the same travel time. It goes ahead and drops the location constraint, goes ahead and books the restaurant and lets Brian and Tom know about the changes.
3.10.8 Suggested Readings
This section has provided only a cursory overview of the relevant areas of research. The interested reader can refer to the following for supplementary information.
- A good overview of commonsense reasoning, first order logic, techniques such as reification and alternative event representations can be found in the text of Davis (1990) [101]. In addition, the proceedings of the bi-annual conference on Logical Formalizations of Commonsense Reasoning will provide the reader with the most current work in this area [102].
- A Good presentation of DRT can be found in Kamp and Reyle (1993) [103] and Gamut (1991) [104]. A related approach is Segmented Discourse Representation Theory, SDRT [105]. A good overview of the field of pragmatics can be found in Levinson (1983) [106], including detailed discussions on Grice's Maxim's of conversation [96]. Details on speech acts can be found in [97, 99]. The proceedings of the annual conferences on plan recognition provide a good overview of alternative approaches.
- Good introductions to the field of knowledge representation can be found in introductory texts [107, 101]; more recent research in this area, including default reasoning, can be found in the proceedings of the annual KR conferences [108]. An overview of description logics can be found in [109]. Utility theory as related to the representation of preferences is also discussed in [107]. A number of tools have been developed for representing preferences [110].
- Seminal papers on plan-based approaches to dialog processing include [111, 112]. The information-based approach to dialog processing is presented in [113]. Recent work in dialog processing can be found in [114]
3.11 Question Answering
General questions are bound to arise in interactions with the kind of virtual assistant described earlier. For example, a user might well ask “Are there any restaurants that serve vegetarian food near here?” as a prelude to deciding where to make a reservation. Answering the question need not involve the system in taking any task actions beyond finding the relevant information, but these Question Answering (QA) interactions can be an important part of formulating or refining the task.
Question answering has a long history as a stand-alone task, from natural language interfaces to databases [115], through supporting intelligence analysts [116], to the recent success of IBM's Watson/DeepQA system playing Jeopardy! against human champions [117]. But, as mentioned, question answering also plays a natural role, embedded as part of broader spoken language dialog applications. For example, a user might want to ask about the start time of the movie they plan to watch before deciding on a time for a dinner reservation; or the system might decide for itself that it needs to get this information, in order to check that the user's choice of time is compatible with their other stated plans. Successfully answering a question requires all of the NL components (recognition, parsing, meaning, and reasoning) for the key steps:
- Question analysis: what is the questioner looking for?
- Locate information relevant to the answer.
- Determine the answer and the evidence for the answer.
- Present the information to the questioner.
All of these steps have to be able to situate the meaning and answers in terms of the questioner, their preferences and their world. “Will there be time to get to the movie?” requires knowing the questioner's schedule.
3.11.1 Question Analysis
Analysis of a question may involve not only determining what the question is asking, but also why the question is being asked. “Are there any restaurants that serve vegetarian food near here?” is technically a question with a yes or no answer, but a useful answer would provide some information about what restaurants are available. “Useful answer” depends on the asker's intent (if all they are trying to do is confirm previous information, then “yes” is the appropriate answer, not a complete description of the information). Determining the asker's intent depends on the conversation, the domain, and knowledge of the world (in this case, it is necessary to know the asker's location).
Question analysis typically determines the key terms in the question and their relations. The key terms (entities) are usually the nouns. Relations can be the main predicate (which largely signals the asker's intent) or constraints on the answer. For example, for “Are there any restaurants that serve vegetarian food near here?” the intent is a list of restaurants that meet the constraints of serving vegetarian food and are near the asker's current location; “restaurants”, “vegetarian food” and “here” are the entities.
Common simple questions can be handled with patterns (“What time is <event>?”), but are not robust to variations and less common linguistic patterns. Parsing (see Section 3.8.2) is a common approach but subtle constructions of language can be hard to parse accurately, and thus parsing is typically complemented by statistical entity- and intent-detection (see Section 3.8.1). Dictionaries of known entities (such as lists of movie actors, medication names, book titles, political figures, …) can also be effective to locate common types of entities, particularly for specific domains.
3.11.2 Find Relevant Information
Once the intent(s) and the entities have been determined, we locate information that might be relevant to the intent. For the example, for “Are there any restaurants that serve vegetarian food near here?” we could look in databases of restaurants, look in a business directory based on the asker's location, or do a general Internet search. From those results, we can compile a list of restaurants that meet the constraints (“have vegetarian dishes on the menu” and “near current location”).
Much information exists only in structured form (tables or databases, such as historical player information for baseball teams, while other kinds of information exists only in unstructured form (documents in natural language, such as movie plot summaries). Accessing information in structured sources requires precise question analysis (the asker may not know how the database designer created the field names, so the question analysis needs to map the semantics of the question to the database fields). Accessing unstructured information with search (either on the Internet or in a specific set of source documents) requires less precision, but leads to many more potential items that could be answers, making it harder to select the correct answer.
3.11.3 Answers and Evidence
Most work on QA has focused on “factoid” answers, where the answer to a question is succinctly encapsulated in a single place in a document (e.g. What is the capital of Peru? “Lima is the Peruvian capital.”) There has been less work on non-factoid answers [118], especially ones that have to be put together from evidence coming from more than one place (e.g., text passages from different parts of the same document, text passages from different documents, combinations of structured data and raw text).
The evidence supporting both factoid and non-factoid answers may differ substantially from the language of the user's question, which has led to recent interest in acquiring paraphrase information to drive textual inference [119]. Non-factoid answers arise either from inherently complex questions (Why is the sky blue, but often red in the morning and evening?), or from qualified answers to simple questions (When can I reserve a table at Café Rouge: if it's a table for 2, at 7 pm; a table for 4 at 7:30; at table for more than 4 at 8:30; or, Café Rouge is closed today).
3.11.4 Presenting the Answer
Having assembled the evidence needed to provide an answer, the system must find a way of presenting it to the user. This involves strategic decisions about how much of the evidence to present, and tactical decisions about the best form of presenting it [120]. These decisions are informed by the answer medium (spoken, text on a mobile display). However, for QA embedded in dialog applications, the background goals (question under discussion) have a significant impact on strategic decisions. At the tactical level for generating NL, possibly dispersed text passages must be stitched together in a coherent and natural way, while NL answers from structured data must either be generated from the data, or textual search carried out to find text snippets to present or support the answer.
Since machine learning systems can potentially benefit and adapt from getting feedback on their actions, capturing user reactions to system answers is desirable. However, this is not likely to succeed if the feedback has to be given in an unnatural and obtrusive way (e.g., thumbs up/down on answers). Instead, more subtle clues to success or failure need to be detected (e.g., the user repeating /reformulating questions, abandoning tasks, the number of steps required to complete a task [121]).
3.12 Distributed Voice Interface Architecture
Users increasingly expect to be able to perform the types of tasks discussed in the preceding sections on a growing array of devices. While their display form factors and CPU power differ, these devices all have substantial on-board computation, displays, and are all connectable to the Web. Users also have an expectation of a consistent experience and a continuity of interactions across smartphones, tablets, Ultrabooks, cars, wearables, and TVs. For example, a user may query his or her smartphone – or smart watch or glasses – “What's the score of the Celtics game?” and, upon arrival at home, instruct the TV to “Put the game on”.
To achieve such a continuity of functionality and the interaction model, the voice interface framework needs to be flexibly distributable across devices and the Cloud. This permits the optimization of computation, availability (if connectivity fails), and latency, as well as making the user's preferences and interaction history available across these devices. In order to resolve the command “Put the game on”, the TV-based interface would access the Cloud-based user profile and conversation history, adapt it during use, and update it back on the server after the session ends, making it available for access from the next device with which the user interacts.
3.12.1 Distributed User Interfaces
Devices like phones or TVs often form hubs for other mobile devices, which may have less computational capacity, but which may provide a more effective and direct interface to the user, supplementing or replacing the UI of the hub device. For example, a phone may be connected to smart glasses, a connected watch, and a wireless headset, distributing the task of channeling information between the user and the device making more effective, natural, and pleasant use of the peripherals.
As discussed earlier in section 3.8.2, the various modalities may overlap and complement one another. Consider for instance a graphical representation on a map of all towns named ‘Springfield’, displayed in response to the user entering a navigation destination. Pointing to the correct target, she specifies “this one”, with gesture recognition identifying the position of the target, and the spoken command conveying the nature of the directive and the time at which the finger position is to be measured.
As the manufacturers of these devices vie for predominance of their particular platforms, users are dividing their attention and interact with multiple devices every day. This has exacerbated the need for a ‘portable’ experience – a continuity of the functionality, the interaction model, the user's preferences and interaction history across these devices.
A pan-device user profile will soon become essential. This stored profile will contain general facts learned about the user, such as a preference for a specific music style or news category, information relevant in the short term such as the status of an ongoing airline reservation and booking dialogue, and also information relevant to voice recognition, such as acoustic models. Devices will use voice biometrics to recognize users, access a server-based user profile, adapt it during use, and update it back on the server after the session ends, making it available for access from the next device with which the user interacts.
A user might search for restaurants on his smartphone, which would then be stored in his or her user profile. Later, on a desktop PC, with a larger screen available, he or she might choose one venue. Getting into his or her car, this location would be retrieved by the onboard navigation from the user profile and, as the recent dialogue context is also available via the profile, a simple command like ‘drive to the restaurant’ is sufficient to instruct the navigation system.
In this model, the human-machine interface design no longer focuses on the interaction between the human and a particular machine. The machine's role is turning into a secondary one: it becomes one of many instantiations of a common, multi-device strategy for directly linking the user to data and services.
A common construct for this type of abstracted interface is the ‘virtual assistant’, which mediates between the user and information and services. Such an assistant has access to a server-based user profile which aggregates relevant information from all devices favored by the user. The manifestation of the assistant may itself be personalized, so that it exhibits the same TTS voice, speaking style and visual guise, to ensure the cross-device dialog forms a continuous, personalized experience. The user thus no longer focuses on interacting with hardware, but on being connected to the desired information, either directly or through the virtual assistant. The interaction model shifts from the use of a human-machine interface to a personalized human-service interface.
Just as the UI can be distributed across multiple interaction sessions on multiple devices, the services may also be spread out across multiple devices and sources. Again, the hardware moves to the background as the UI groups functionality and data by domains, not by device.
Consider, for example, an automotive music app that has access to music on the car's hard drive juke box, an SD memory card, a connected phone, and internet services. A user experience designer may elect to make content from all these sources available in one homogeneous set, so a request “play some jazz” yields matching music from all the sources.
3.12.2 Distributed Speech and Language Technology
For speech and language UIs, the location of the processing is largely determined by the following considerations:
- Capacity of the platform: CPU, memory, and power profile.
- Degree of connectivity: the speed, reliability and bandwidth of the connection, and additional costs for connectivity, e.g., data plan limits.
- The type and size of models needed for voice recognition and understanding of the application's domains. For example, are there 100,000 city names that need to be recognized in a variety of contexts, or only a few hundred names in a user's contact list?
The following device classes exemplify the spectrum of different platforms:
- PCs: ample CPU and memory, continuous power supply. Typically connected to the internet. Native domains: commands to operate software and PC, text dictation.
- Mobile phones and tablets: limited CPU and memory, battery-driven. Often connected to the internet, connection may be more costly and not stable (e.g., when coverage is lost).
- Cars: limited CPU and memory, continuous power supply. Often connected to the internet, connection may be more costly and not stable.
- TVs: limited CPU and memory, continuous power supply. Often connected to the internet, not every user might connect the TV.
- Cloud servers – vast CPU and memory resources feeding multiple interactions at the same time. Connected to the internet and other large data sources.
Increased connectivity has given rise to hybrid architectures that blur the lines between traditional embedded versus server-based setups and also lead to a number of functions and domains that are expected on all personal devices – for instance, information search, media playback, and dictation.
When considering how to allocate tasks in a distributed architecture, the mantra used to be do the processing where the data is – which, with growing connectivity bandwidth, is no longer a requirement but still a good guideline. UI consistency is also an essential aspect; say the natural language or dialogue components run entirely on a remote server. If a data connection is lost, it is easy for the user to understand that connected data services like web search are interrupted, but it may not be clear that the capacity to converse in a natural language dialogue is also no longer available.
In a speech and language UI, the embedded, “on-board” speech recognition typically handles speech commands to operate the given device. This may be using a grammar-based command-and-control type recognizer or a small statistical language model (SLM) enabling natural language processing. Contemporary mobile platforms, however, reach their limits when attempting to recognize speech with SLMs filled with large slot lists with tens of thousands of city names. This task would thus be carried out by a server-based recognizer. In many cases, it is advisable to perform recognition both on the embedded platform and on the server at the same time, compare the confidences of the results, and then select the best one, to avoid latencies one would incur if only triggering the server speech recognition after a low-confidence onboard outcome.
Other tasks that may reside on the onboard recognizer are wake-up-word detection, possibly in combination with voice biometrics – to activate a device and authenticate the user, respectively, speech activity and end point detection to segment the audio, and speech recognition feature extraction, so that only the features rather the full audio need to be transferred to the recognition server.
The user profile is beneficial for storing personal preferences relevant for dialogue decisions, speaker characteristics and vernacular for acoustic and language modeling. It can also hold biometrics information so that the user's identity can be verified to authorize use of a service or access of data. This is most powerful if the profile is available to the user from any device, but it should also be functional if the device loses connectivity, e.g., when a car drives through a tunnel. This is solved by a master user profile in the Cloud with synchronized copies on local devices, or by making the phone the hub for the profile, as it accompanies the user at most times.
Storing such a profile on a server also offers the advantage that the group of these profiles forms an entity of its own containing a vast amount of information, and allows deriving statistics of the user population or parts thereof. A news service may be interested in finding the trending news search keywords found in all logs connected to the group of profiles. A music web store could query the group of profiles for the artists most commonly requested by male listeners aged 18–25 in the state of California.
Often, profiles of different users are connected to each other, say, because users A and B are in each other's email address book or linked via a social network. If this information is stored in the user profile, the group of connected profiles spans a large graph that, for instance, could allow a user's virtual assistant to conduct queries such as, “do I have any friends or friends of friends that are in the town I'm currently visiting?” or “what music are my friends listening to?” Even more so than with server-based recognition and logging, when storing data in user profiles, privacy and data security are a key matter for designing and operating the server infrastructure.
Lastly, on the output side, the TTS (text-to-speech) and language generation usually run on the user's device, unless a high-quality voice requires more memory than available locally, or if an entire app is hosted and a server solution is more convenient to develop and maintain.
3.13 Conclusion
Interacting with voice-driven NLU interfaces on a broad variety of devices spanning smartphones, tablets, TVs, cars and kiosks is becoming a routine part of daily life. These interfaces allow people to use complicated functions on their devices in a simpler and more natural way. Rather than issuing a series of atomic commands, a user can increasingly express his or her overall intent in natural language, with the system determining the underlying steps. Such natural language interactions are becoming practical in an increasing number of environments: on the street; in an automobile; in the living room; and on new devices.
All of this new functionality begs the question of how to best incorporate natural language understanding into today's visual interfaces. There is a broad range of possible approaches, including the “virtual assistant” category, which had a banner year in 2013, with Apple's Siri, Samsung's S-Voice, Dragon Assistant, Google Now, and nearly 60 other offerings on the market.
The assistant can be viewed as a separate entity, one which is primarily conversational and with a personality. It interprets a user's input and mediates between the user, the native user interface of the device, and a variety of on- and off-board applications. In some cases, the assistant even renders retrieved information in a re-formatted fashion within its own UI – and in this sense acts as a lens and filter on the Web.
An alternative design, which may be termed “ambient NLU”, retains the look-and-feel of native device and application interfaces, but “embeds” context-sensitive NLU. By speaking to this interface, the user can retrieve information as well as open and control familiar-looking applications. The system engages in conversation when needed to complete multi-turn transactions or resolve ambiguity. Rather than being front-and-center, the NLU aims to be unobtrusive, efficient and open. To the extent possible, it accomplishes tasks based on a single utterance and never limits from where the user can get information. In contrast to the assistant that aims to help the user address the shortcomings of the existing UI, ambient NLU holds the promise of becoming an inherent part of an improved UI.
In either case, voice and language understanding are now viewed as a new fundamental building block – a new dimension added to the traditional visual UI that permits access and manipulation of assets that may not be visible, located either on the device or in the cloud. Over the next few years, we will see active exploration of the best way to make use of these new dimensions, and a rapid revision of the current “shrunken desktop” metaphor as designers experiment with new ways of structuring the experience.
This voice revolution has been driven by ongoing, incremental improvements in many component technologies, and the improvements have accelerated in the last few years. There has been a continuous growth in the number of situations where the system “just” works. This performance increase has been due to progress on many complementary fronts, including:
- voice recognition technology, particularly DNNs;
- signal acquisition enhancements;
- improved TTS and voice biometrics modeling;
- meaning extraction combining structural methods with machine learning;
- conversational dialog, probabilistic plan recognition, knowledge representation and reasoning;
- question answering.
Many factors have contributed to this progress:
- Increases in available computational power, including special purpose computation devices.
- Increases in size of available training corpora.
- Improvements in statistical modeling.
- Thousands of person years of engineering effort.
Despite this progress, many challenges remain. Or, to put it more positively: we can expect further improvements over the next years. Creating conversational agents with a deep understanding of human language is a both a challenge and a promise.
Acknowledgements
The authors would like to thank Dario Albesano, Markus Buck, Joev Dubach, Nils Lenke, Franco Mana, Paul Vozila, and Puming Zhan for their contributions to this chapter.
References
- 1. Davis, S., Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech and Signal Processing 28(4), 357–366.
- 2. Hermansky, H. (1990). Perceptual linear predictive (PLP) analysis of speech. The Journal of the Acoustical Society of America 87, 1738.
- 3. Bahl, L., Bakis, R., Bellegarda, J., Brown, P., Burshtein, D., Das, S., De Souza, P., Gopalakrishnan, P., Jelinek, F., Kanevsky, D. (1989). Large vocabulary natural language continuous speech recognition. International Conference on Acoustics, Speech, and Signal Processing, 1989 (ICASSP-89).
- 4. Rabiner, L. (1989). A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE 77(2), 257–286.
- 5. Ney, H., Ortmanns, S. (2000). Progress in dynamic programming search for LVCSR. Proceedings of the IEEE 88(8), 1224–1240.
- 6. Hunt, A., McGlashan, S. (2004). Speech recognition grammar specification version 1.0. W3C Recommendation. http://www.w3.org/TR/speech-grammar/.
- 7. Chomsky, N. (2002). Syntactic structures. Mouton de Gruyter.
- 8. Jelinek, F. (1997). Statistical methods for speech recognition.: MIT press.
- 9. Bahl, L., Brown, P., De Souza, P., Mercer, R. (1986). Maximum mutual information estimation of hidden Markov model parameters for speech recognition. IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP '86.
- 10 McDermott, E., Hazen, T.J., Le Roux, J., Nakamura, A., Katagiri, S. (2007). Discriminative training for large-vocabulary speech recognition using minimum classification error. IEEE Transactions on Audio, Speech, and Language Processing 15(1), 203–223.
- 11. Povey, D., Woodland, P.C. (2002). Minimum Phone Error and I-Smoothing for Improved Discrimative Training. International Conference on Acoustics, Speech, and Signal Processing (ICASSP).
- 12. Leggetter, C.J., Woodland, P.C. (1995). Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models. Computer Speech & Language 9(2), 171–185.
- 13. Hermansky, H., Morgan, N. (1994). RASTA processing of speech. IEEE Transactions on Speech and Audio Processing 2(4), 578–589.
- 14. Furui, S. (1986). Speaker-independent isolated word recognition based on emphasized spectral dynamics. IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP'86.
- 15. Kumar, N., Andreou, A.G. (1998). Heteroscedastic discriminant analysis and reduced rank HMMs for improved speech recognition. Speech Communication 26(4), 283–297.
- 16. Sim, K., Gales, M. (2004). Basis superposition precision matrix modelling for large vocabulary continuous speech recognition. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing, 2004. (ICASSP'04).
- 17. Lee, L., Rose, R.A. (1998). Frequency warping approach to speaker normalization. IEEE Transactions on Speech and Audio Processing 6(1), 49–60.
- 18. Kneser, R., Ney, H. (1995). Improved backing-off for M-gram language modeling. 1995 International Conference on Acoustics, Speech, and Signal Processing, ICASSP-95.
- 19. Chen, S.F. (2009). Performance prediction for exponential language models. Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics.
- 20. Kuo, H.-K., Arisoy, E., Emami, A., Vozila, P. (2012). Large Scale Hierarchical Neural Network Language Models. INTERSPEECH.
- 21. Pereira, F.C., Riley, M.D. (1997). 15 Speech Recognition by Composition of Weighted Finite Automata. Finite-state language processing, 431.
- 22. Pogue, D. (2010). TechnoFiles: Talk to the machine. Scientific American Magazine 303(6), 40–40.
- 23. Hershey, J.R., Rennie, S.J., Olsen, P.A., Kristjansson, T.T. (2010). Super-human multi-talker speech recognition: A graphical modeling approach. Computer Speech & Language 24(1), 45–66.
- 24. Bourlard, H.A., Morgan, N. (1994). Connectionist speech recognition: a hybrid approach. Vol. 247. Springer.
- 25. Gemello, R., Albesano, D., Mana, F. (1997). Continuous speech recognition with neural networks and stationary-transitional acoustic units. International Conference on Neural Networks.
- 26. Mohamed, A., Dahl, G.E., Hinton, G. (2012). Acoustic Modeling Using Deep Belief Networks. IEEE Transactions on Audio, Speech, and Language Processing 20(1), 14–22.
- 27. Hinton, G., Li, D., Dong, Y., Dahl, G.E., Mohamed, A., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T.N., Kingsbury, B. (2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. Signal Processing Magazine 29(6), 82–97.
- 28. Dahl, G.E., Dong, Y., Li, D., Acero, A. (2012). Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Transactions on Audio, Speech, and Language Processing 20(1), 30–42.
- 29. Loizou, P.C. (2013). Speech enhancement: theory and practice. CRC press.
- 30. Hofmann, C., Wolff, T., Buck, M., Haulick, T., Kellermann, W.A. (2012). Morphological Approach to Single-Channel Wind-Noise Suppression. Proceedings of International Workshop on Acoustic Signal Enhancement (IWAENC 2012).
- 31. Widrow, B., Stearns, S.D. (1985). Adaptive signal processing. Vol. 15. IET.
- 32. Breining, C., Dreiscitel, P., Hansler, E., Mader, A., Nitsch, B., Puder, H., Schertler, T., Schmidt, G., Tilp, J. (1999). Acoustic echo control. An application of very-high-order adaptive filters. Signal Processing Magazine 16(4), 42–69.
- 33. Haykin, S.S. (2005). Adaptive Filter Theory, 4/e. Pearson Education India.
- 34. Griffiths, L.J., Jim, C.W. (1982). An alternative approach to linearly constrained adaptive beamforming. IEEE Transactions on Antennas and Propagation 30(1), 27–34.
- 35. Wolf, T., Buck, M. (2010). A generalized view on microphone array postfilters. Proc. International Workshop on Acoustic Signal Enhancement, Tel Aviv, Israel.
- 36. DiBiase, J.H., Silverman, H.F., Brandstein, M.S. (2001). Robust localization in reverberant rooms. In: Microphone Arrays. Springer. 157–180.
- 37 Furui, S. (1981). Cepstral analysis technique for automatic speaker verification. IEEE Transactions on Acoustics, Speech and Signal Processing 29(2), 254–272.
- 38. Furui, S. (1981). Comparison of speaker recognition methods using statistical features and dynamic features. IEEE Transactions on Acoustics, Speech and Signal Processing 29(3), 342–350.
- 39. Reynolds, D.A., Quatieri, T.F., Dunn, R.B. (2000). Speaker verification using adapted Gaussian mixture models. Digital signal processing 10(1), 19–41.
- 40. Solomonoff, A., Campbell, W.M., Boardman, I. (2005). Advances In Channel Compensation For SVM Speaker Recognition. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005 (ICASSP '05).
- 41. Kenny, P., Boulianne, G., Ouellet, P., Dumouchel, P. (2007). Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio, Speech, and Language Processing 15(4), 1435–1447.
- 42. Dehak, N., Kenny, P.J., Dehak, R., Ouellet, P., Dumouchel, P. (2011). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing 19(4), 788–798.
- 43. Mistretta, W., Farrell, K. (1998). Model adaptation methods for speaker verification. Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing.
- 44. Speaker Recognition Evaluation (2013). http://www.itl.nist.gov/iad/mig/tests/spk/.
- 45. Evans, N., Yamagishi, J., Kinnunen, T. (2013). Spoofing and Countermeasures for Speaker Verification: a Need for Standard Corpora, Protocols and Metrics. SLTC Newsletter.
- 46. Klatt, D.H. (1987). Review of text-to-speech conversion for English. Journal of the Acoustical Society of America 82(3), 737–793.
- 47. Taylor, P. (2009). Text-to-speech synthesis. Cambridge University Press.
- 48. Ladd, D.R. (2008). Intonational phonology. Cambridge University Press.
- 49. Ladefoged, P., Johnstone, K. (2011). A course in phonetics. CengageBrain.com.
- 50. Yoshimura, T., Tokuda, K., Masuko, T., Kobayashi, T., Kitamura, T. (1999). Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synthesis.
- 51. Hunt, A.J., Black, A.W. (1996). Unit selection in a concatenative speech synthesis system using a large speech database. Proceedings of 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP-96.
- 52. Donovan, R.E. (1996). Trainable speech synthesis, PhD Thesis, University of Cambridge.
- 53. Pollet, V., Breen, A. (2008). Synthesis by generation and concatenation of multiform segments. INTERSPEECH.
- 54. Chen, L., Gales, M.J., Wan, V., Latorre, J., Akamine, M. (2012). Exploring Rich Expressive Information from Audiobook Data Using Cluster Adaptive Training. INTERSPEECH.
- 55. Zen, H., Senior, A., Schuster, M. (2013). Statistical parametric speech synthesis using deep neural networks. International Conference on Acoustics, Speech, and Signal Processing, ICASSP-13. Vancouver.
- 56. Walker, M., Whittaker, S. (1990). Mixed initiative in dialogue: An investigation into discourse segmentation. Proceedings of the 28th annual meeting on Association for Computational Linguistics.
- 57. Florian, R., Hassan, H., Ittycheriah, A., Jing, H., Kambhatla, N., Luo, X., Nicolov, N., Roukos, S., Zhang, T. (2004). A Statistical Model for Multilingual Entity Detection and Tracking. HLT-NAACL.
- 58. Berger, A.L., Pietra, V.J.D., Pietra, S.A.D. (1996). A maximum entropy approach to natural language processing. Computational Linguistics 22(1), 39–71.
- 59. Borthwick, A., Sterling, J., Agichtein, E., Grishman, R. (1998). Exploiting diverse knowledge sources via maximum entropy in named entity recognition. Proc. of the Sixth Workshop on Very Large Corpora.
- 60. Brown F, deSouza V, Mercer RL, Pietra VJD, Lai JC. (1992). Class-based n-gram models of natural language. Computational Linguistics 18, 467–479.
- 61. Miller, S., Guinness, J., Zamanian, A. (2004). Name tagging with word clusters and discriminative training. HLT-NAACL 337–342.
- 62. Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., Kuksa, P. (2011). Natural language processing (almost) from scratch. The Journal of Machine Learning Research 12, 2493–2537.
- 63. Lafferty J, McCallum A, Pereira FC. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data.
- 64. Finkel, J.R., Grenager, T., Manning, C. (2005). Incorporating non-local information into information extraction systems by Gibbs sampling. Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics.
- 65. Ballesteros, M., Nivre, J. (2013). Going to the roots of dependency parsing. Computational Linguistics 39(1), 5–13.
- 66. Kübler, S., McDonald, R., Nivre, J. (2009). Dependency parsing. Morgan & Claypool Publishers.
- 67 McDonald, R., Pereira, F., Ribarov, K., Haji
 , J. (2005). Non-projective dependency parsing using spanning tree algorithms. Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing.
, J. (2005). Non-projective dependency parsing using spanning tree algorithms. Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. - 68. Nivre, J. (2008). Algorithms for deterministic incremental dependency parsing. Computational Linguistics 34(4), 513–553.
- 69. Riezler, S., King, T.H., Kaplan, R.M., Crouch, R., Maxwell III, J.T., Johnson, M. (2002). Parsing the Wall Street Journal using a Lexical-Functional Grammar and discriminative estimation techniques. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.
- 70. Flickinger, D. (2000). On building a more efficient grammar by exploiting types. Natural Language Engineering 6(1), 15–28.
- 71. Callmeier, U. (2002). Preprocessing and encoding techniques in PET. Collaborative language engineering. A case study in efficient grammar-based processing. Stanford, CA: CSLI Publications.
- 72. Brinkley, D., Guha, R. (2004). RDF vocabulary description language 1.0: RDF schema. W3C Recommendation. Available at http://www. w3. org/TR/PR-rdf-schema.
- 73. Manola, F., Miller, E., McBride, B. (2004). RDF primer. W3C recommendation; 10, 1–107.
- 74. Hitzler, P., Krötzsch, M., Parsia, B., Patel-Schneider, P.F., Rudolph, S. (2009). OWL 2 Web Ontology Language primer. W3C recommendation 27, 1–123. http://www.w3.org/TR/owl2-primer/
- 75. Mitkov, R. (2002). Anaphora resolution. Vol. 134. Longman, London.
- 76. Johnson, M. (2009). EMMA: Extensible MultiModal Annotation markup language. http://www.w3.org/TR/emma/.
- 77. Young, S.R. (1993). Dialog Structure and Plan Recognition in Spontaneous Spoken Dialog. DTIC Document.
- 78. Williams, J.D. (2013). The Dialog State Tracking Challenge. SIGdial 2013. http://www.sigdial.org/workshops/sigdial2013/proceedings/index.html.
- 79. Ferguson, G., Allen, J.F. (1993). Generic plan recognition for dialogue systems. Proceedings of the workshop on Human Language Technology. Association for Computational Linguistics.
- 80. Bui, H.H. (2003). A general model for online probabilistic plan recognition. IJCAI.
- 81. Domingos, P., Lowd, D. (2009). Markov logic: An interface layer for artificial intelligence. Synthesis Lectures on Artificial Intelligence and Machine Learning 3(1), 1–155.
- 82. Bohus, D., Rudnicky, A.I. (2009). The RavenClaw dialog management framework: Architecture and systems. Computer Speech & Language 23(3), 332–361.
- 83. Bobrow, D.G., Kaplan, R.M., Kay, M., Norman, D.A., Thompson, H., Winograd, T. (1977). GUS, a frame-driven dialog system. Artificial intelligence 8(2), 155–173.
- 84. Pieraccini, R., Huerta, J. (2005). Where do we go from here? Research and commercial spoken dialog systems. 6th SIGdial Workshop on Discourse and Dialogue.
- 85. Pieraccini, R., Levin, E., Eckert, W. (1997). AMICA: the AT&T mixed initiative conversational architecture. Eurospeech.
- 86. Pieraccini, R., Caskey, S., Dayanidhi, K., Carpenter, B., Phillips, M. (2001). ETUDE, a recursive dialog manager with embedded user interface patterns. IEEE Workshop on Automatic Speech Recognition and Understanding, 2001 (ASRU'01).
- 87. Carpenter, B., Caskey, S., Dayanidhi, K., Drouin, C., Pieraccini, R. (2002). A Portable, Server-Side Dialog Framework for VoiceXML. Proc. Of ICSLP 2002. Denver, CO.
- 88. Seneff, S., Polifroni, J. (2000). Dialogue management in the Mercury flight reservation system. Proceedings of the 2000 ANLP/NAACL Workshop on Conversational systems – Volume 3. Association for Computational Linguistics.
- 89. Larsson, S., Traum, D.R. (2000). Information state and dialogue management in the TRINDI dialogue move engine toolkit. Natural language engineering 6(3–4), 323–340.
- 90. Lemon, O., Bracy, A., Gruenstein, A., Peters, S. (2001). The WITAS multi-modal dialogue system I. INTERSPEECH.
- 91. Rich, C., Sidner, C.L. (1998). COLLAGEN: A collaboration manager for software interface agents. User Modeling and User-Adapted Interaction 8(3–4), 315–350.
- 92. Blaylock, N., Allen, J. (2005). A collaborative problem-solving model of dialogue. 6th SIGdial Workshop on Discourse and Dialogue.
- 93. Frampton, M., Lemon, O. (2009). Recent research advances in Reinforcement Learning in Spoken Dialogue Systems. Knowledge Eng. Review 24(4), 375–408.
- 94 Lemon, O., Liu, X., Shapiro, D., Tollander, C. (2006). Hierarchical Reinforcement Learning of Dialogue Policies in a development environment for dialogue systems: REALL-DUDE. BRANDIAL'06, Proceedings of the 10th Workshop on the Semantics and Pragmatics of Dialogue.
- 95. Rieser, V., Lemon, O. (2011). Reinforcement learning for adaptive dialogue systems. Springer.
- 96. Grice, H.P. (1975). Logic and conversation. Syntax and Semantics, Vol. 3: Speech Acts, 41–58.
- 97. Searle, J.R. (1969). Speech acts: An essay in the philosophy of language. Vol. 626. Cambridge University Press.
- 98. Austin, J. (1962). How to do things with words (William James Lectures). Oxford University Press.
- 99. Cohen, P.R., Perrault, C.R. (1979). Elements of a plan-based theory of speech acts. Cognitive science 3(3), 177–212.
- 100. Lenke, N. (1993). Regelverletzungen zu kommunikativen Zwecken. KODIKAS,/ CODE 16, 71–82.
- 101. Davis, E. (1990). Representations of commonsense knowledge. Morgan Kaufmann Publishers Inc.
- 102. Commonsense Reasoning (2013). Commonsense Reasoning ∼ Home; http://www.commonsensereasoning.org/.
- 103. Kamp, H., Reyle, U. (1993). From discourse to logic: Introduction to model theoretic semantics of natural language, formal logic and discourse representation theory. Springer.
- 104. Gamut, L. (1991). Logic, Language and Meaning, volume II, Intentional Logic and Logical Grammar. University of Chicago Press, Chicago, IL.
- 105. Lascarides, A., Asher, N. (2007). Segmented discourse representation theory: Dynamic semantics with discourse structure. Computing meaning, 87–124. Springer.
- 106. Levinson, S.C. (1983). Pragmatics (Cambridge textbooks in linguistics).
- 107. Russell, S.J., Norvig, P., Canny, J.F., Malik, J.M., Edwards, D.D. (1995). Artificial intelligence: a modern approach. Vol. 74. Prentice Hall, Englewood Cliffs.
- 108. KR, Inc. (2013). Principles of Knowledge Representation and Reasoning. http://www.kr.org/.
- 109. Baader, F. (2003). The description logic handbook: theory, implementation, and applications. Cambridge university press.
- 110. Boutilier, C., Brafman, R.I., Domshlak, C., Hoos, H.H., Poole, D. (2004). CP-nets: A tool for representing and reasoning with conditional ceteris paribus preference statements. J. Artif. Intell. Res.(JAIR) 21, 135–191.
- 111. Grosz, B.J., Sidner, C.L. (1986). Attention, intentions, and the structure of discourse. Computational linguistics 12(3), 175–204.
- 112. Allen, J. (1987). Natural language understanding. Vol. 2. Benjamin/Cummings Menlo Park, CA.
- 113. Traum, D.R., Larsson, S. (2003). The information state approach to dialogue management. Current and new directions in discourse and dialogue, 325–353. Springer.
- 114. SIGdial: Special Interest Group on Discourse and Dialog (2013). http://www.sigdial.
- 115. Woods, W.A., Kaplan, R.M., Nash-Webber, B., Center, M.S. (1972). The lunar sciences natural language information system: Final report. Bolt Beranek and Newman.
- 116. AQUAINT (2013). Advanced Question Answering for Intelligence. http://www-nlpir.nist.gov/projects/aquaint/
- 117. Ferrucci, D.A. (2012). Introduction to This is Watson. IBM Journal of Research and Development 56(3.4), 1:1–1:15.
- 118. Surdeanu, M., Ciaramita, M., Zaragoza, H. (2011). Learning to rank answers to non-factoid questions from web collections. Computational Linguistics 37(2), 351–383.
- 119. De Marneffe, M.–C., Rafferty, A.N., Manning, C.D. (2008). Finding Contradictions in Text. ACL.
- 120. Demberg, V., Winterboer, A., Moore, J.D. (2011). A strategy for information presentation in spoken dialog systems. Computational Linguistics 37(3), 489–539.
- 121. Diekema, A.R., Yilmazel, O., Liddy, E.D. (2004). Evaluation of restricted domain question-answering systems. Proceedings of the ACL2004 Workshop on Question Answering in Restricted Domain.
- Further reading
- Allen, J., Kautz, H., Pelavin, R., Tenenberg, J. (1991). Reasoning about plans. Morgan Kaufmann San Mateo, CA.
- Allen, J.F. (2003). Natural language processing.
- Chen, C.H. (1976). Pattern Recognition and Artificial Intelligence: Proceedings of the Joint Workshop on Pattern Recognition and Artificial Intelligence, Held at Hyannis, Massachusetts, June 1–3, 1976. Acad. Press.
- Dayanidhi, B.C.S.C.K., Pieraccini, C.D.R. (2002). A portable, server-side dialog framework for VoiceXML.
- Graham, S., McKeown, D., Kiuhara, S., Harris, K.R. (2012). A meta-analysis of writing instruction for students in the elementary grades. Journal of Educational Psychology 104, 879–896.
- Kautz, H.A. (1991). A formal theory of plan recognition and its implementation. In Reasoning about plans. Morgan Kaufmann Publishers Inc.
- Lascarides, A. (2003). Logics of conversation. Cambridge University Press.
- Perrault, C.R., Allen, J.F. (1980). A plan-based analysis of indirect speech acts. Computational Linguistics 6(3–4), 167–182.
- Roche, E., Schabes, Y. (1997). Finite-state language processing. The MIT Press.
- Schlegel, K., Grandjean, D., i Scherer, K.R. (2012). Emotion recognition: Unidimensional ability or a set of modality- and emotion-specific skills. Personality and Individual Differences 53(1), 16–21.