
Deviations from the CAPM
If the CAPM held, then discussion of various investment strategies related to (for example) style analysis, low volatility, sector rotation, momentum, and reversal, would be moot academic exercises. But the empirical evidence against CAPM is overwhelming with the tests, themselves, giving rise to a host of alternative portfolio strategies that are regarded as anomalies because they should not work in the equilibrium state described by CAPM.
The central questions are why the CAPM fails as a pricing relationship and what we learn about the relationships between risk and returns from these tests. The elegance of the CAPM model lies in the linear relationship between the expected return on any security and its covariance (beta) with the market rate of return, that is, the familiar relationship given by:
![]()
The asset's beta is determined by its covariance with the market return as a ratio to the market variance, that is, ![]() . The CAPM takes the empirical form given by:
. The CAPM takes the empirical form given by:
![]()
Expected returns are replaced by observed returns and appended with the pricing error term, εi, representing the firm's (asset's) specific risk. Specific risk is, of course, diversifiable but otherwise uncompensated. Only the firm's risk relative to the market portfolio—its systematic risk—is compensated and the price of that risk is given by its beta.
Typically, the empirical model is supplemented with an intercept and estimated using least squares in the following regression format:
![]()
If the CAPM holds, then it should explain the cross-section of returns in the sense that assets with higher betas will also have higher returns. Thus, the relationship between βi and ri (as given by the security market line) should be linear and the slope should be equal to the average excess market return with no intercept. Lintner (1965), and later Miller and Scholes (1972), published some of the early empirical studies rejecting the CAPM.
The basic methodology for these early studies used monthly returns for five-year periods on, say, the S&P 500 (proxy for the market portfolio), the one-month Treasury bill (risk-free rate), and the returns on a set of 100 stocks. In a first-pass regression, the set of individual security betas were estimated with 100 separate bivariate regressions. These constituted the estimates for the security characteristic line (SML). The SML is the graph of the linear relationship between individual returns and betas. In the second-pass regression, the set of average security excess returns were regressed on the beta estimates from the first-pass regression, that is,
![]()
The hypothesis tested was (γ0,γ1) = (0, ![]() that is, that the security market line would have slope equal to the market excess return and a zero intercept (no abnormal return). Adding specific risk estimates (from the SML regressions) gives us the following empirical model:
that is, that the security market line would have slope equal to the market excess return and a zero intercept (no abnormal return). Adding specific risk estimates (from the SML regressions) gives us the following empirical model:
![]()
where we test the hypothesis that the excess return is determined solely by systematic risk captured by β, and therefore that γ2 must be statistically zero. Lintner found the slope γ1 to be too flat (less than the average market excess return for the period under study) with a significant and positive intercept γ0. He also found that a significant part of the cross-sectional excess return is also explained by specific risk (γ2 > 0).
Still, it was hard to accept these implications, and attention turned to the statistical properties of the empirical methodology. In particular, it was noted that stock return volatility introduces measurement error into the estimates of the βi and that these bias the estimates of γ0 up and γ1 downward. The thought was that eliminating measurement error would bring the test results back in line with the predictions of the theory. They did not. Second, because the estimated βi are not independent of the errors in the second-pass regression, then the coefficient on the specific risk term γ2 is biased upward. Again, fixing this inconsistency would push the test results in the direction of the CAPM. This helped but the basic findings with respect to (γ0,γ1) went unchanged.
In their attempt to deal with measurement error and orthogonality problems, Black, Jensen, and Scholes (BJS) introduced a methodology based on the portfolio deciling that is standard practice today. Because this methodology also (inadvertently) illuminated many of the anomalies that drove style research, it is worth reviewing.
In the BJS methodology, the first-pass regression is used to generate the cross-section of βi based on, say, a trailing 60-month window of monthly returns for each stock. Stocks are then ranked by their betas and placed into deciles. Thus: (1) βs are estimated each year from a trailing 60-month sample, (2) firms are assigned a decile based on the size of their β estimate, (3) the 10 portfolio's betas are estimated for the forward period. Figure 8.1 illustrates this procedure.
Figure 8.1 The Black-Jensen-Scholes Methodology
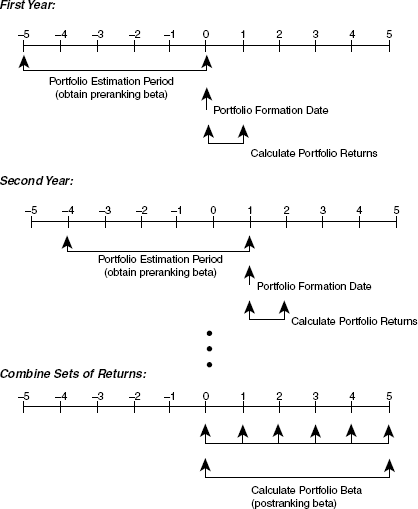
Ranking βs and combining stocks into deciles provides the diversification that essentially aggregates away the impact of the measurement error as well as the effects of specific risks. The BJS study used all available NYSE returns for the period 1931 to 1965 (Black et al. 1972). To the disappointment of many, their results were not much different—the SML was still too flat with a positive intercept but it also appeared that the decile approach diversified away the statistical impact of the unsystematic risk on excess returns. Subsequent attention was focused sharply on what these failures now seemed to imply about the characteristics of the cross-section of stocks.
The BJS methodology illuminated several key relationships.
Fama and MacBeth (1973) use the BJS methodology expanded to 20 portfolios to include a squared beta term to test for nonlinearities (there weren't any) and still find that the slope of the SML is too flat with significantly positive intercept. In time, more evidence of anomalous behavior was published:
Fama and French (1992) sorted on size and then on beta and found that after controlling for size, the relationship between beta and return is negative. They concluded that the firm's size and book-to-market ratio together capture the cross-sectional variation in returns. In a word, Fama and French argue that beta is not compensated. This was the paper that spawned the style index work related to value (HML) and size (SMB); various indices sorted on these characteristics can be found on French's website.
The notion of beta not being compensated brings into question portfolio efficiency as we know it. Specifically, if all portfolios located on the efficient frontier are mean-variance efficient, but higher risk (beta) portfolios do not earn higher returns, then can we hold lower variance portfolios and earn essentially the same return as more risky positions do? Haugen and Baker (1991) question the claim that capitalization-weighted portfolios are indeed efficient, arguing that for a host of reasons (short-sale restrictions, inability to reliably estimate mean returns), large index holdings cannot be efficient except under very restrictive assumptions. Theirs is an argument not unlike Roll's, which questions the premise that we are indeed looking at the so-called market portfolio, for example, that the exclusion of alternatives and human capital render capitalization portfolios inferior to what the CAPM assumes investors are benchmarking to. Clarke, de Silva, and Thorley (2006) take this concept further, arguing that mean blur (our inability to measure precisely mean returns) makes it practically impossible to properly implement the Markowitz mean-variance criteria. The true minimum variance portfolio (the left-most point on the efficient frontier), however, is independent of our notions of mean returns; it is formed independently of expected returns or a targeted portfolio return. Clarke, de Silva, and Thorley (CST) therefore challenge the efficiency assumption of the market portfolio and, by studying the performance of the minimum variance portfolio over time, conclude that it delivers a lower volatility market portfolio–like return. Using the CRSP database, they study the 1,000 largest capitalization stocks over the time from January 1968 to December 2005 and construct a covariance matrix using principal component (PC) analysis on 60 months of excess returns over the one-month Treasury yield (the PC analysis allows them to identify various risk factors that aid in the formation of their optimal portfolios). The minimum variance portfolios is the solution to the quadratic programming problem (i is a conformable vector of ones for summing)
![]()
Subject to:
![]()
The portfolio that solves this is given by:
![]()
Thus, the minimum variance portfolio is solely a function of the covariance matrix V. It should be noted, however, that this is not the true minimum variance portfolio since CST impose long-only constraints. They also explore cases that selectively impose market neutrality constraints with respect to market capitalization (size), book to market (value), and momentum (prior year less prior month return) as well as the implications of different return frequencies (daily returns). Their basic findings are that (1) minimum variance portfolios generate returns that are at least as high as the cap-weighted portfolio but with (2) significantly lower risk and that (3) the minimum variance portfolios display a value and small-size bias. Thomas and Shapiro (2009) confirm and strengthen the robustness of the Haugen and Baker as well as the CST findings using the BARRA USE3L model in place of PC. Blitz and van Vliet (2007) don't even use a risk model to select their stocks; rather, each month they simply construct equally weighted decile portfolios by ranking stocks on the past three years’ volatility using weekly returns (using FTSE World Developed Index). They show that stocks with low historical volatility have higher risk-adjusted returns using either Sharpe ratios or CAPM alphas and extend the CST results to a global universe, where they find particularly strong global performance (with a strong negative alpha for U.S. stocks).