
Appendix 22.1: Covariance Matrix Estimation
Consider the simplest case with two return series ![]() for
for ![]() and
and ![]() for
for ![]() where
where ![]() . Truncation to S would imply that means be equal to their maximum likelihood estimates:
. Truncation to S would imply that means be equal to their maximum likelihood estimates:
(22.1) ![]()
Here, ![]() and
and ![]() are the sample MLE for the truncated sample of size S. Similarly, the MLE covariance matrix based upon S is equal to:
are the sample MLE for the truncated sample of size S. Similarly, the MLE covariance matrix based upon S is equal to:
(22.2) ![]()
where ![]() are scalars. The parameters
are scalars. The parameters ![]() and
and ![]() are typically replaced with their MLE counterparts based on the full sample of size T.
are typically replaced with their MLE counterparts based on the full sample of size T.
Consider now the likelihood function for these series, which can be written as a combination of the information unique to ![]() (that is, the observations in
(that is, the observations in ![]() not common to
not common to ![]() ) and the information common to both series, for example, the joint likelihood given by:
) and the information common to both series, for example, the joint likelihood given by:
(22.3) ![]()
![]()
The second part of the likelihood is the distribution of joint information while the first part describes the contribution to the likelihood function from the information unique to r1,t. The truncated estimator ignores the first half of the likelihood function. Ordinarily, one would maximize this likelihood with respect to E and V, but unfortunately these two sets of parameters do not appear in both halves of the likelihood. Stambaugh uses a result from Anderson (1957) that rewrites the joint likelihood as the product of a marginal ![]() and a conditional density
and a conditional density ![]() . Assuming returns to be multivariate normal, we get the familiar result that the conditional mean of
. Assuming returns to be multivariate normal, we get the familiar result that the conditional mean of ![]() (conditional on
(conditional on ![]() ) is equal to:
) is equal to:
(22.4) ![]()
where ![]() , is the regression coefficient of
, is the regression coefficient of ![]() on
on ![]() . If
. If ![]() and
and ![]() are positively correlated
are positively correlated ![]() and a return
and a return ![]() is observed to be above its mean
is observed to be above its mean ![]() , then
, then ![]() is adjusted downward from its unconditional value. (This is what statisticians mean by “regression toward the mean.”) Furthermore, the conditional covariance given by the multivariate normal is:
is adjusted downward from its unconditional value. (This is what statisticians mean by “regression toward the mean.”) Furthermore, the conditional covariance given by the multivariate normal is:
(22.5) ![]()
In the more general multivariate case, ![]() is a vector of returns on
is a vector of returns on ![]() assets all with
assets all with ![]() observations and
observations and ![]() is an
is an ![]() vector of returns on the shorter time series. In that case,
vector of returns on the shorter time series. In that case, ![]() and
and ![]() are mean return vectors of size
are mean return vectors of size ![]() and
and ![]() , respectively, so that E is an
, respectively, so that E is an ![]() vector,
vector, ![]() is:
is: ![]() is
is ![]() is
is ![]() and
and ![]() . Furthermore,
. Furthermore, ![]() is now a
is now a ![]() matrix of regression coefficients.
matrix of regression coefficients.
The objective is to derive estimates for these covariance matrices. To estimate the maximum likelihood estimators for the moments of the conditional density, regress ![]() on
on ![]() using S observations, saving the covariance matrix of the residuals as
using S observations, saving the covariance matrix of the residuals as ![]() . Likewise, estimate mean returns for
. Likewise, estimate mean returns for ![]() and
and ![]() using T and S observations, respectively. Then, applying the results in (22.3) and (22.4), adjust the truncated mean for
using T and S observations, respectively. Then, applying the results in (22.3) and (22.4), adjust the truncated mean for ![]() given in (22.1) by conditioning on the information in
given in (22.1) by conditioning on the information in ![]() :
:
Therefore, if the two returns series are positively correlated and the mean of the longer series exceeds its truncated mean, the mean for the shorter series is adjusted upward. That is, the truncated mean is most likely biased downward. Likewise, the truncated covariance matrices are adjusted according to (see Stambaugh):
![]()
thus
![]()
![]()
It is easy to show that ![]() is identical to
is identical to ![]() in equation (22.5). In equation (22.7), it is also true that the covariance between
in equation (22.5). In equation (22.7), it is also true that the covariance between ![]() and
and ![]() is a linear rescaling of the covariation in
is a linear rescaling of the covariation in ![]() with the magnitude depending on the strength of their covariation. Moreover, revisions to
with the magnitude depending on the strength of their covariation. Moreover, revisions to ![]() depend on the how much the covariation in the longer series changes over the time interval
depend on the how much the covariation in the longer series changes over the time interval ![]() .
.
Removing the Effects of Smoothing
Consider, for example, the appraised value P which is a moving average of current and past comps ![]() :
:
(22.8) ![]()
![]()
Rewrite the weights to be geometrically declining such that ![]() for some scalar value of
for some scalar value of ![]() . Let a = 1−w0. Note as well that
. Let a = 1−w0. Note as well that ![]() . Substituting into (8) yields:
. Substituting into (8) yields:
![]()
Now, replace P with its natural logarithm, lag one period, and subtract the resulting expression from (22.8), yielding a moving average of returns:
(22.9) ![]()
where ![]() . Obviously, returns are a weighted average of past market rates of return and this is the source of the smoothing. Solving (22.9) for
. Obviously, returns are a weighted average of past market rates of return and this is the source of the smoothing. Solving (22.9) for ![]() gives us:
gives us:
![]()
(22.10) ![]()
![]()
We seek the unsmoothed component ![]() , which is:
, which is:
(22.11) 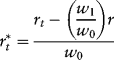
Thus, we use the observed smoothed returns to recover the market return. An estimator for ![]() can be obtained from an OLS regression of observed
can be obtained from an OLS regression of observed ![]() on its lagged value. This is a special case of an ARMA model for which the moving average component, under certain stationarity conditions, is invertible. An invertible infinite order moving average is equivalent to a first-order autoregressive (AR) model whose parameter is estimated using ordinary least squares. The series can then be unsmoothed and covariances estimated thereafter.
on its lagged value. This is a special case of an ARMA model for which the moving average component, under certain stationarity conditions, is invertible. An invertible infinite order moving average is equivalent to a first-order autoregressive (AR) model whose parameter is estimated using ordinary least squares. The series can then be unsmoothed and covariances estimated thereafter.
Notes
1. Much of this chapter appeared in Peterson and Grier 2006. Asset allocation in the presence of covariance misspecification. Financial Analysts Journal 62(4): 76–85.