
Introduction
Welcome! This book introduces the topics of Machine Learning (ML) and Deep Learning (DL) from a practical perspective. I try to explain the basics of how these techniques work and the core algorithms involved. The main focus is on building real‐world systems using these techniques. I see many ML and DL books cover the algorithms extensively but not always show a clear path to deploying these algorithms into production systems. Also, we often see a big gap in understanding around how these Artificial Intelligence (AI) systems can be scaled to handle large volume of data—also referred to as Big Data.
Today we have systems like Docker and Kubernetes that help us package our code and seamlessly deploy to large on‐premise or Cloud systems. Kubernetes takes care of all the low‐level infrastructure concerns like scaling, fail‐over, load balancing, networking, storage, security, etc. I show how your ML and DL projects can take advantage of the rich features that Kubernetes provides. I focus on deployment of the ML and DL algorithms at scale and tips to handle large volumes of data.
I talk about many popular algorithms and show how you can build systems using them. I include code examples that are heavily commented so you can easily follow and possibly reproduce the examples. I use an example of a DL model to read images and classify logos of popular brands. Then this model is deployed on a distributed cluster so it can handle large volumes of client requests. This example shows you an end‐to‐end approach for building and deploying a DL model in production.
I also provide references to books and websites that cover details of items I do not cover fully in this book.
How This Book Is Organized
The first half of the book (Chapters 1–5) focuses on Machine Learning (ML) and Deep Learning (DL). I show examples of building ML models with code (in Python) and show examples of tools that automate this process. I also show an example of building an image classifier model using the Keras library and TensorFlow framework. This logo‐classifier model is used to distinguish between the Coca‐Cola and Pepsi logos in images.
In the second half of the book (Chapters 6–10), I talk about how these ML and DL models can actually be deployed in a production environment. We talk about some common concerns that data scientists have and how software developers can implement these models. I explain an example of deploying our earlier logo‐classifier model at scale using Kubernetes.
Conventions Used
Italic terms indicate key concepts I want to draw attention to and which will be good to grasp.
Underlined references are references to other books or publications or external web links.
Code examples in Python will be shown as follows:
# This box carries code – mainly in Pythonimport tensorflow as tf
Results from code are shown as follows:
Results from code are shown as a picture or in this font below the code box.Who Should Read This Book
This book is intended for software developers and data scientists. I talk about developing Machine Learning (ML) models, connecting these to application code, and deploying them as microservices packaged as Docker containers. Modern software systems are heavily driven by ML and I feel that data scientists and software developers can both benefit by knowing enough about each other's discipline.
Whether you are a beginner at software/data science or an expert in the field, I feel there will be something in this book for you. Although a programming background is best to understand the examples well, the code and examples are targeted to very general audience. The code presented is heavily commented as well, so it should be easy to follow. Although I have used Python and specific libraries—Scikit‐Learn, and Keras—you should be able to find equivalent functions and convert the code to other languages and libraries like R, MATLAB, Java, SAS, C++, etc.
My effort is to provide as much theory as I can so you don't need to go through the code to understand the concepts. The code is very practical and helps you adapt the concepts to your data very easily. You are free (and encouraged) to copy the code and try the examples with your own datasets.
Tools You Will Need
My effort is to provide as much theory about the concepts as possible. The code is practical and commented to help you understand. Like most data scientists today, my preference is to use the Python programming language. You can install the latest version of Python from https://www.python.org/.
Using Python
A popular way to write Python code is using Jupyter Notebooks. It is a browser‐based interface for running your Python code. You open a web page in a browser and write Python code that gets executed and you see the results right there on the same web page. It has an excellent user‐friendly interface and shows you immediate results by executing individual code cells. The examples I present are also small blocks of code that you can quickly run separately in a Jupyter Notebook. This can be installed from http://jupyter.org.
The big advantage of Python is its rich set of libraries for solving different problems. We particularly use the Pandas library for loading and manipulating data to be used for building our ML models. We also use Scikit‐Learn, which is a popular library that provides implementation for most of the ML techniques. These libraries are available from the following links:
Using the Frameworks
Specifically, for Deep Learning, we use a framework for building our models. There are multiple frameworks available, but the one we use for examples is Google's TensorFlow. TensorFlow has a good Python interface we use to write Deep Learning code in Python. We use Keras, which is a high‐level abstraction library that runs on top of TensorFlow. Keras comes packaged with TensorFlow. You can install TensorFlow for Python from https://www.tensorflow.org.
One disclaimer. TensorFlow, although production‐ready, is under active development by Google. It releases new versions every two to three months, which is unprecedented for normal software development. But because of today's world of Agile development and continuous integration practices, Google is able to release huge functionalities in weeks rather than months. Hence the code I show for Deep Learning in Keras and TensorFlow may need updating to the latest version of the library. Usually this is pretty straightforward. The concepts I discuss will still be valid; you just may need to update the code periodically.
Setting Up a Notebook
If you don't want to set up your own Python environment, you can get a hosted notebook running entirely in the Cloud. That way all you need is a computer with an active Internet connection to run all the Python code. There are no libraries or frameworks to install. All this by using the magic of Cloud computing. Two popular choices here are Amazon's SageMaker and Google's Colaboratory. I particularly like Colaboratory for all the Machine Learning library support.
Let me show you how to set up a notebook using Google's Cloud‐hosted programming environment, called Colaboratory. A special shout‐out to our friends at Google, who made this hosted environment available for free to anyone with a Google account. To set up the environment, make sure you have a Google account (if not, you'll need to create one). Then open your web browser and go to https://colab.research.google.com.
Google Colaboratory is a free (as of writing this book) Jupyter environment that lets you create a notebook and easily experiment with Python code. This environment comes pre‐packaged with the best data science and Machine Learning libraries like Pandas, Scikit‐Learn, TensorFlow, and Keras.
The notebooks (work files) you create will be stored on your Google Drive account. Once you're logged in, open a new Python 3 notebook, as shown in Figure 1.

Figure 1: Opening a new notebook in Google Colaboratory
You will see a screen similar to the one in Figure 2, with your first Python 3 notebook called Untitled1.pynb

Figure 2: Click Connect to start the virtual machine
Once your notebook is connected to the Cloud runtime, you can add code cells and click the Play button on the slide to run your code. It's that simple. Once the code runs, you will see outputs popping up below the block. You can also add text blocks for informational material you want to include and format this text.
Figure 3 shows a simple example of a notebook with code snippets for checking the TensorFlow library and downloading a public dataset using the Pandas library. Remember that Python has a rich set of libraries that helps you load, process, and visualize data.
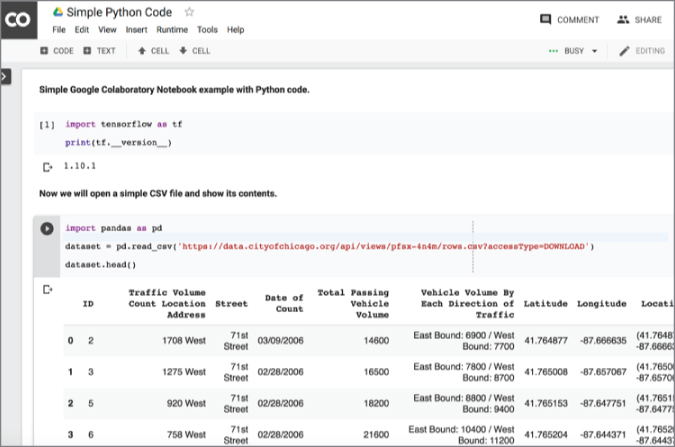
Figure 3: Example of running code in a notebook
Finding a Dataset
Look at the second code block in Figure 3; it loads a CSV file from the Internet and shows the data in a data frame. This dataset shows traffic at different intersections in the city of Chicago. This dataset is maintained by the city.
Many such datasets are available for free, thanks to the amazing data science community. These datasets are cleansed and contain data in good format to be used for building models. These can be used to understand different ML algorithms and their effectiveness. You can find a comprehensive list at https://catalog.data.gov/dataset?res_format=CSV. You can search by typing CSV and clicking the CSV icon to download the dataset or copy the link.
Google also now has a dedicated website for searching for datasets that you can use to build your models. Have a look at this site at https://toolbox.google.com/datasetsearch.
Summary
We will now embark on a journey of building Machine Learning and Deep Learning models for real‐world use cases. We will use the Python programming language and popular libraries for ML and DL, like Scikit‐Learn, TensorFlow, and Keras. You could build an environment from scratch and try to work on the code provided in this book. Another option is to use a hosted notebook in Google's Colaboratory to run the code. There are many open datasets that are freely available for you to experiment with model building and testing. You can enhance your data science skills with these datasets. I show examples of the same. Let's get started!