
Chapter 14. Running Machine Learning in Kubernetes
The age of microservices, distributed systems, and the cloud has provided the perfect environmental conditions for the democratization of machine learning models and tooling. Infrastructure at scale has now become commoditized, and the tooling around the machine learning ecosystem is maturing. It just so happens that Kubernetes is one of the platforms that has become increasingly popular among data scientists and the wider open source community as the perfect environment to enable the machine learning workflow and life cycle. In this chapter, we will cover why Kubernetes is a great place for machine learning and provide best practices for both cluster administrators and data scientists alike on how to get the most out of Kubernetes when running machine learning workloads. Specifically, we focus on deep learning rather than traditional machine learning because deep learning has fast become the area of innovation on platforms like Kubernetes.
Why Is Kubernetes Great for Machine Learning?
Kubernetes has quickly become the home for rapid innovation in deep learning. The confluence of tooling and libraries such as TensorFlow make this technology more accessible to a large audience of data scientists. What makes Kubernetes such a great place to run your deep learning workloads? Let’s cover what Kubernetes provides:
- Ubiquitous
-
Kubernetes is everywhere. All of the major public clouds support it, and there are distributions for private clouds and infrastructure. Basing ecosystem tooling on a platform like Kubernetes allows users to run their deep learning workloads anywhere.
- Scalable
-
Deep learning workflows typically need access to large amounts of computing power in order to efficiently train machine learning models. Kubernetes ships with native autoscaling capabilities that make it easy for data scientists to achieve and fine-tune the level of scale they need to train their models.
- Extensible
-
Efficiently training a machine learning model typically requires access to specialized hardware. Kubernetes allows cluster administrators to quickly and easily expose new types of hardware to the scheduler without having to change the Kubernetes source code. It also allows custom resources and controllers to be seamlessly integrated into the Kubernetes API to support specialized workflows, such as hyperparameter tuning.
- Self-service
-
Data scientists can use Kubernetes to perform self-service machine learning workflows on demand, without needing specialized knowledge of Kubernetes itself.
- Portable
-
Machine learning models can be run anywhere, provided that the tooling is based on the Kubernetes API. This allows machine learning workloads to be portable across Kubernetes providers.
Machine Learning Workflow
To effectively understand the needs of deep learning, you must understand the complete workflow. Figure 14-1 represents a simplified machine learning workflow.
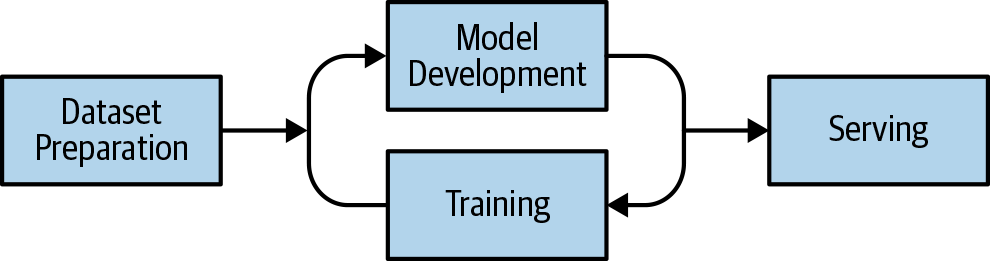
Figure 14-1. Machine learning development workflow
Figure 14-1 illustrates that the machine learning development workflow has the following phases:
- Dataset preparation
-
This phase includes the storage, indexing, cataloging, and metadata associated with the dataset that is used to train the model. For the purposes of this book, we consider only the storage aspect. Datasets vary in size, from hundreds of megabytes to hundreds of terabytes. The dataset needs to be provided to the model in order for the model to be trained. You must consider storage that provides the appropriate properties to meet these needs. Typically, large-scale block and object stores are required and must be accessible via Kubernetes native storage abstractions or directly accessible APIs.
- Machine learning algorithm development
-
This is the phase in which data scientists write, share, and collaborate on machine learning algorithms. Open source tools like JupyterHub are easy to install on Kubernetes because they typically function like any other workload.
- Training
-
This is the process by which the model will use the dataset to learn how to perform the tasks for which it has been designed. The resulting artifact of training process is usually a checkpoint of the trained model state. The training process is the piece that takes advantage of all of the capabilities of Kubernetes at the same time. Scheduling, access to specialized hardware, dataset volume management, scaling, and networking will all be exercised in unison in order to complete this task. We cover more of the specifics of the training phase in the next section.
- Serving
-
This is the process of making the trained model accessible to service requests from clients so that it can make predictions based on the the data supplied from the client. For example, if you have an image-recognition model that’s been trained to detect dogs and cats, a client might submit a picture of a dog, and the model should be able to determine whether it is a dog, with a certain level of accuracy.
Machine Learning for Kubernetes Cluster Admins
In this section, we discuss topics you will need to consider before running machine learning workloads on your Kubernetes cluster. This section is specifically targeted toward cluster administrators. The largest challenge you will face as a cluster administrator responsible for a team of data scientists is understanding the terminology. There are myriad new terms that you must become familiar with over time, but rest assured, you can do it. Let’s take a look at the main problem areas you’ll need to address when preparing a cluster for machine learning workloads.
Model Training on Kubernetes
Training machine learning models on Kubernetes requires conventional CPUs and graphics processing units (GPUs). Typically, the more resources you apply, the faster the training will be completed. In most cases, model training can be achieved on a single machine that has the required resources. Many cloud providers offer multi-GPU virtual machine (VM) types, so we recommend scaling VMs vertically to four to eight GPUs before looking into distributed training. Data scientists use a technique known as hyperparameter tuning when training models. Hyperparameter tuning is the process of finding the optimal set of hyperparameters for model training. A hyperparameter is simply a parameter that has a set value before the training process begins. The technique involves running many of the same training jobs with a different set of hyperparameters.
Training your first model on Kubernetes
In this example, you are going to use the MNIST dataset to train an image-classification model. The MNIST dataset is publicly available and commonly used for image classification.
To train the model, you are going to need GPUs. Let’s confirm that your Kubernetes cluster has GPUs available. The following output shows that this Kubernetes cluster has four GPUs available:
$kubectl get nodes -o yaml|grep -i nvidia.com/gpu nvidia.com/gpu:"1"nvidia.com/gpu:"1"nvidia.com/gpu:"1"nvidia.com/gpu:"1"
To run your training, you are going to using the Job kind in Kubernetes, given that training
is a batch workload. You are going to run your training for 500 steps and use a single GPU. Create a file
called mnist-demo.yaml using the following manifest, and save it to your filesystem:
apiVersion:batch/v1kind:Jobmetadata:labels:app:mnist-demoname:mnist-demospec:template:metadata:labels:app:mnist-demospec:containers:-name:mnist-demoimage:lachlanevenson/tf-mnist:gpuargs:["--max_steps","500"]imagePullPolicy:IfNotPresentresources:limits:nvidia.com/gpu:1restartPolicy:OnFailure
Now, create this resource on your Kubernetes cluster:
$ kubectl create -f mnist-demo.yaml
job.batch/mnist-demo createdCheck the status of the job you just created:
$kubectl getjobsNAME COMPLETIONS DURATION AGE mnist-demo 0/1 4s 4s
If you take a look at the pods, you should see the training job running:
$kubectl get pods NAME READY STATUS RESTARTS AGE mnist-demo-hv9b2 1/1 Running03s
Looking at the pod logs, you can see the training happening:
$kubectl logs mnist-demo-hv9b2 2019-08-06 07:52:21.349999: I tensorflow/core/platform/cpu_feature_guard.cc:137]Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA 2019-08-06 07:52:21.475416: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030]Found device0with properties: name: Tesla K80 major:3minor:7memoryClockRate(GHz): 0.8235 pciBusID: d0c5:00:00.0 totalMemory: 11.92GiB freeMemory: 11.85GiB 2019-08-06 07:52:21.475459: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120]Creating TensorFlow device(/device:GPU:0)->(device: 0, name: Tesla K80, pci bus id: d0c5:00:00.0, compute capability: 3.7)2019-08-06 07:52:26.134573: I tensorflow/stream_executor/dso_loader.cc:139]successfully opened CUDA library libcupti.so.8.0 locally Successfully downloaded train-images-idx3-ubyte.gz9912422bytes. Extracting /tmp/tensorflow/input_data/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz28881bytes. Extracting /tmp/tensorflow/input_data/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz1648877bytes. Extracting /tmp/tensorflow/input_data/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz4542bytes. Extracting /tmp/tensorflow/input_data/t10k-labels-idx1-ubyte.gz Accuracy at step 0: 0.1255 Accuracy at step 10: 0.6986 Accuracy at step 20: 0.8205 Accuracy at step 30: 0.8619 Accuracy at step 40: 0.8812 Accuracy at step 50: 0.892 Accuracy at step 60: 0.8913 Accuracy at step 70: 0.8988 Accuracy at step 80: 0.9002 Accuracy at step 90: 0.9097 Adding run metadatafor99 ...
Finally, you can see that the training has completed by looking at the job status:
$kubectl getjobsNAME COMPLETIONS DURATION AGE mnist-demo 1/1 27s 112s
To clean up the training job, simply run the following command:
$kubectl delete -f mnist-demo.yaml job.batch"mnist-demo"deleted
Congratulations! You just ran your first model training job on Kubernetes.
Distributed Training on Kubernetes
Distributed training is still in its infancy and is difficult to optimize. Running a training job that requires eight GPUs will almost always be faster to train on a single eight-GPU machine compared to two machines each with four GPUs. The only time that you should resort to using distributed training is when the model doesn’t fit on the biggest machine available. If you are certain that you must run distributed training, it is important to understand the architecture. Figure 14-2 depicts the distributed TensorFlow architecture, and you can see how the model and the parameters are distributed.
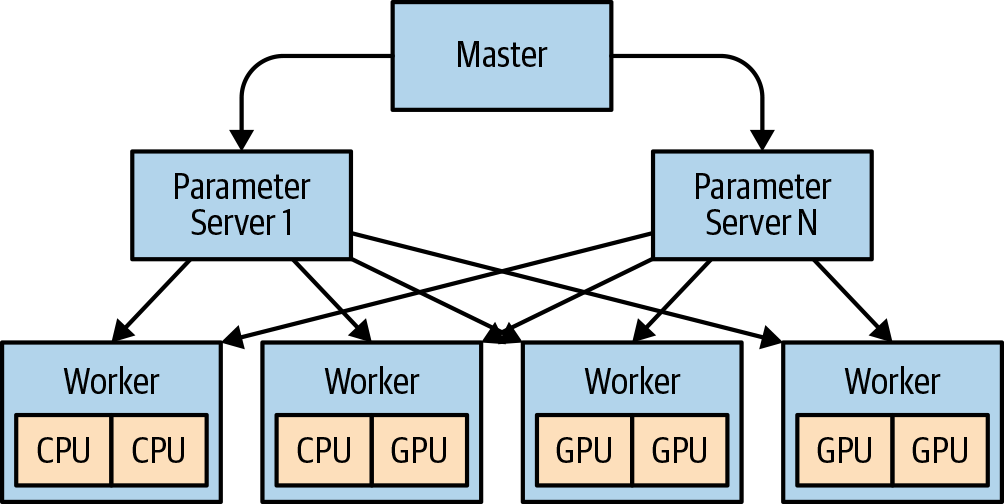
Figure 14-2. Distributed TensorFlow architecture
Resource Constraints
Machine learning workloads demand very specific configurations across all aspects of your cluster. The training phases are most certainly the most resource intensive. It’s also important to note, as we mentioned a moment ago, that machine learning algorithm training is almost always a batch-style workload. Specifically, it will have a start time and a finish time. The finish time of a training run depends on how quickly you can meet the resource requirements of the model training. This means that scaling is almost certainly a quicker way to finish training jobs faster, but scaling has its own set of bottlenecks.
Specialized Hardware
Training and serving a model is almost always more efficient on specialized hardware. A typical example of such specialized hardware would be commodity GPUs. Kubernetes allows you to access GPUs via device plug-ins that make the GPU resource known to the Kubernetes scheduler and therefore able to be scheduled. There is a device plug-in framework that facilitates this capability, which means that vendors do not need to modify the core Kubernetes code to implement their specific device. These device plug-ins typically run as DaemonSets on each node, which are processes that are responsible for advertising these specific resources to the Kubernetes API. Let’s take a look at the NVIDIA device plug-in for Kubernetes, which enables access to NVIDIA GPUs. After they’re running, you can create a pod as follows, and Kubernetes will ensure that it is scheduled to a node that has these resource available:
apiVersion:v1kind:Podmetadata:name:gpu-podspec:containers:-name:digits-containerimage:nvidia/digits:6.0resources:limits:nvidia.com/gpu:2# requesting 2 GPUs
Device plug-ins are not limited to GPUs; you can use them wherever specialized hardware is needed—for example, Field Programmable Gate Arrays (FPGAs) or InfiniBand.
Scheduling idiosyncrasies
It’s important to note that Kubernetes cannot make decisions about resources that it does not have knowledge about. One of the things you might notice is that the GPUs are not running at capacity when you are training. You are therefore not achieving the level of utilization that you would like to see. Let’s consider the previous example; it exposes only the number of GPU cores and omits the number of threads that can be run per core. It also doesn’t expose which bus the GPU core is on, so that jobs that need access to one another or to the same memory might be colocated on the same Kubernetes nodes. These are all considerations that might be addressed by device plug-ins in the future but might leave you wondering why you cannot get 100% utilization on that beefy GPU you just purchased. It’s also worth mentioning that you cannot request fractions of GPUs (for example, 0.1), which means that even if the specific GPU supports running multiple threads concurrently, you will not be able to utilize that capacity.
Libraries, Drivers, and Kernel Modules
To access specialized hardware, you typically need purpose-built libraries, drivers, and kernel modules. You will need to ensure that these are mounted into the container runtime so that they are available to the tooling running in the container. You might ask, “Why don’t I just add these to the container image itself?” The answer is simple: the tools need to match the version on the underlying host and must be configured appropriately for that specific system. There are container runtimes such as NVIDIA Docker that remove the burden of having to map host volumes into each container. In lieu of having a purpose-built container runtime, you might also be able to build an admission webhook that provides the same functionality. It’s also important to consider that you might need privileged containers to access some specialized hardware, which also affects the cluster security profile. The installation of the associated libraries, drivers, and kernel modules might also be facilitated by Kubernetes device plug-ins. Many device plug-ins run checks on each machine to confirm that all installations have been completed before they advertise the schedulable GPU resources to the Kubernetes scheduler.
Storage
Storage is one of the most critical aspects of the machine learning workflow. You need to consider storage because it directly affects the following pieces of the machine learning workflow:
-
Dataset storage and distribution among worker nodes during training
-
Checkpoints and saving models
Dataset storage and distribution among worker nodes during training
During training, the dataset must be retrievable by every worker node. The storage needs are read-only, and, typically, the faster the disk, the better. The type of disk that’s providing the storage is almost completely dependent on the size of the dataset. Datasets of hundreds of megabytes or gigabytes might be perfect for block storage, but datasets that are several or hundreds of terabytes in size might be better suited to object storage. Depending on the size and location of the disks that hold the datasets, there might be a performance hit on your networking.
Checkpoints and saving models
Checkpoints are created as a model is being trained, and saving models
allows you to use them for serving. In both cases, you need storage
attached to each of the worker nodes to store this data. The data is
typically stored under a single directory, and each worker node is
writing to a specific checkpoint or save file. Most tools expect the
checkpoint and save data to be in a single location and require
ReadWriteMany. ReadWriteMany simply means that the volume can be
mounted as read-write by many nodes. When using Kubernetes PersistentVolumes, you will need to determine the best storage platform for your
needs. The Kubernetes documentation keeps a
list
of volume plug-ins that support ReadWriteMany.
Networking
The training phase of the machine learning workflow has a large impact on the network (specifically, when running distributed training). If we consider TensorFlow’s distributed architecture, there are two discrete phases to consider that create a lot of network traffic: variable distribution from each of the parameter servers to each of the worker nodes, and also the application of gradients from each worker node back to the parameter server (see Figure 14-2). The time it takes for this exchange to happen directly affects the time it takes to train a model. So, it’s a simple game of the faster, the better (within reason, of course). With most public clouds and servers today supporting 1-Gbps, 10-Gbps, and sometimes 40-Gbps network interface cards, generally network bandwidth is only a concern at lower bandwidths. You might also consider InfiniBand if you need high network bandwidth.
While raw network bandwidth is more often than not a limiting factor, there are also instances for which getting the data onto the wire from the kernel in the first place is the problem. There are open source projects that take advantage of Remote Direct Memory Access (RDMA) to further accelerate network traffic without the need to modify your worker nodes or application code. RDMA allows computers in a network to exchange data in main memory without using the processor, cache, or operating system of either computer. You might consider the open source project Freeflow, which boasts of having high network performance for container network overlays.
Specialized Protocols
There are other specialized protocols that you can consider when using machine learning on Kubernetes. These protocols are often vendor specific, but they all seek to address distributed training scaling issues by removing areas of the architecture that quickly become bottlenecks, for example, parameter servers. These protocols often allow the direct exchange of information between GPUs on multiple nodes without the need to involve the node CPU and OS. Here are a couple that you might want to look into to more efficiently scale your distributed training:
Data Scientist Concerns
In the previous discussion, we shared considerations that you need to make in order to be able to run machine learning workloads on your Kubernetes cluster. But what about the data scientist? Here we cover some popular tools that make it easy for data scientists to utilize Kubernetes for machine learning without having to be a Kubernetes expert.
-
Kubeflow is a machine learning toolkit for Kubernetes. It is native to Kubernetes and ships with several tools necessary to complete the machine learning workflow. Tools such as Jupyter Notebooks, pipelines, and Kubernetes-native controllers make it simple and easy for data scientists to get the most out of Kubernetes as a platform for machine learning.
-
Polyaxon is a tool for managing machine learning workflows that supports many popular libraries and runs on any Kubernetes cluster. Polyaxon has both commercial and open source offerings.
-
Pachyderm is an enterprise-ready data science platform that has a rich suite of tools for dataset preparation, life cycle, and versioning along with the ability to build machine learning pipelines. Pachyderm has a commercial offering that you can deploy to any Kubernetes cluster.
Machine Leaning on Kubernetes Best Practices
To achieve optimal performance for your machine learning workloads, consider the following best practices:
-
Smart scheduling and autoscaling. Given that most stages of the machine learning workflow are batch by nature, we recommend that you utilize a Cluster Autoscaler. GPU-enabled hardware is costly, and you certainly do not want to be paying for it when it’s not in use. We recommend batching jobs to run at specific times using either taints and tolerations or via a time-specific Cluster Autoscaler. That way, the cluster can scale to the needs of the machine learning workloads when needed, and not a moment sooner. Regarding taints and tolerations, upstream convention is to taint the node with the extended resource as the key. For example, a node with NVIDIA GPUs should be tainted as follows:
Key: nvidia.com/gpu, Effect: NoSchedule. Using this method means that you can also utilize theExtendedResourceTolerationadmission controller, which will automatically add the appropriate tolerations for such taints to pods requesting extended resources so that the users don’t need to manually add them. -
The truth is that model training is a delicate balance. Allowing things to move faster in one area often leads to bottlenecks in others. It’s an endeavor of constant observation and tuning. As a general rule of thumb, we recommend that you try to make the GPU become the bottleneck because it is the most costly resource. Keep your GPUs saturated. Be prepared to always be on the lookout for bottlenecks, and set up your monitoring to track the GPU, CPU, network, and storage utilization.
-
Mixed workload clusters. Clusters that are used to run the day-to-day business services might also be used for the purposes of machine learning. Given the high performance requirements of machine learning workloads, we recommend using a separate node pool that’s tainted to accept only machine learning workloads. This will help protect the rest of the cluster from any impact from the machine learning workloads running on the machine learning node pool. Furthermore, you should consider multiple GPU-enabled node pools, each with different performance characteristics to suit the workload types. We also recommend enabling node autoscaling on the machine learning node pool(s). Use mixed mode clusters only after you have a solid understanding of the performance impact that your machine learning workloads have on your cluster.
-
Achieving linear scaling with distributed training. This is the holy grail of distributed model training. Most libraries unfortunately don’t scale in a linear fashion when distributed. There is lots of work being done to make scaling better, but it’s important to understand the costs because this isn’t as simple as throwing more hardware at the problem. In our experience, it’s almost always the model itself and not the infrastructure supporting it that is the source of the bottleneck. It is, however, important to review the utilization of the GPU, CPU, network, and storage before pointing fingers at the model itself. Open source tools such as Horovod seek to improve distributed training frameworks and provide better model scaling.
Summary
We’ve covered a lot of ground in this chapter and have hopefully provided valuable insight into why Kubernetes is a great platform for machine learning, especially deep learning, and the considerations you need to be aware of before deploying your first machine learning workload. If you exercise the recommendations in this chapter, you will be well equipped to build and maintain a Kubernetes cluster for these specialized workloads.