
Chapter 15. Building Higher-Level Application Patterns on Top of Kubernetes
Kubernetes is a complex system. Although it simplifies the deployment and operations of distributed applications, it does little to make the development of such systems easy. Indeed, in adding new concepts and artifacts for the developer to interact with, it adds an additional layer of complexity in the service of simplified operations. Consequently, in many environments, it makes sense to develop higher-level abstractions in order to provide more developer-friendly primitives on top of Kubernetes. Additionally, in many large companies, it makes sense to standardize the way in which applications are configured and deployed so that everyone adheres to the same operational best practices. This can also be achieved by developing higher-level abstractions so that developers automatically adhere to these principles. However, developing these abstractions can hide important details from the developer and might introduce a walled garden that limits or complicates the development of certain applications or the integration of existing solutions. Throughout the development of the cloud, the tension between the flexibility of infrastructure and the power of the platform has been a constant. Designing the proper higher-level abstractions enables us to walk an ideal path through this divide.
Approaches to Developing Higher-Level Abstractions
When considering how to develop a higher-level primitive on top of Kubernetes, there are two basic approaches. The first is to wrap up Kubernetes as an implementation detail. With this approach, developers who consume your platform should be largely unaware that they are running on top of Kubernetes; instead, they should think of themselves as consumers of the platform you supply, and thus Kubernetes is an implementation detail.
The second option is to use the extensibility capabilities built into Kubernetes itself. The Kubernetes Server API is quite flexible, and you can dynamically add arbitrary new resources to the Kubernetes API itself. With this approach, your new higher-level resources coexist alongside the built-in Kubernetes objects, and the users use the built-in tooling for interacting with all of the Kubernetes resources, both built-in ones and extensions. This extension model results in an environment in which Kubernetes is still front and center for your developers but with additions that reduce complexity and make it easier to use.
Given the two approaches, how do you choose the one that is appropriate? It really depends on the goals for the abstraction layer that you are building. If you are constructing a fully isolated, integrated environment in which you have strong confidence that users will not need to “break glass” and escape, and where ease of use is an important characteristic, the first option is a great choice. A good example of such a use case would be building a machine learning pipeline. The domain is relatively well understood. The data scientists who are your users are likely not familiar with Kubernetes. Enabling these data scientists to rapidly get their work done and focus on their domains rather than distributed systems is the primary goal. Thus, building a complete abstraction on top of Kubernetes makes the most sense.
On the other hand, when building a higher-level developer abstraction—for example, an easy way to deploy Java applications—it is a far better choice to extend Kubernetes rather than wrap it. The reason for this is two-fold. First, the domain of application development is extraordinarily broad. It will be difficult for you to anticipate all of the requirements and use cases for your developers, especially as the applications and business iterate and change over time. The other reason is to ensure that you can continue to take advantage of the Kubernetes ecosystem of tools. There are countless cloud-native tools for monitoring, continuous delivery, and more. Extending rather than replacing the Kubernetes API ensures that you can continue to use these tools and new ones as they are developed.
Extending Kubernetes
Because every layer that you might build over Kubernetes is unique, it is beyond the scope of this book to describe how you might build such a layer. But the tools and techniques for extending Kubernetes are generic to any construction you might do on top of Kubernetes, and, thus, we’ll spend time covering them.
Extending Kubernetes Clusters
A complete how-to for extending a Kubernetes cluster is a large topic and more completely covered in other books like Managing Kubernetes and Kubernetes: Up and Running (O’Reilly). Rather than going over the same material here, this section focuses on providing an understanding of how to use Kubernetes extensibility. Extending the Kubernetes cluster involves understanding the touch points for resources in Kubernetes. There are three related technical solutions. The first is the sidecar. Sidecar containers (shown in Figure 15-1) have been popularized in the context of service meshes. They are containers that run alongside a main application container to provide additional capabilities that are decoupled from the main application and often maintained by a separate team. For example, in service meshes, a sidecar might provide transparent mutual Transport Layer Security (mTLS) authentication to a containerized application.
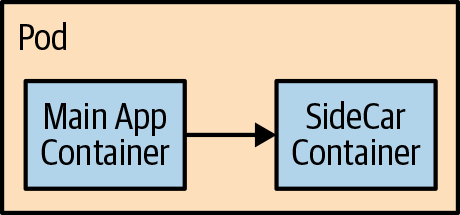
Figure 15-1. The sidecar design
You can use sidecars to add capabilities to your user-defined applications.
Of course, the entire goal of this effort was to make a developer’s life easier, but if we require that they learn about and know how to use sidecars, we’ve actually made the problem worse. Fortunately, there are additional tools for extending Kubernetes that simplify things. In particular, Kubernetes features admission controllers. Admission controllers are interceptors that read Kubernetes API requests prior to them being stored (or “admitted”) into the cluster’s backing store. You can use these admission controllers to validate or modify API objects. In the context of sidecars, you can use them to automatically add sidecars to all pods created in the cluster so that developers do not need to know about the sidecars in order to reap their benefits. Figure 15-2 illustrates how admission controllers interact with the Kubernetes API.
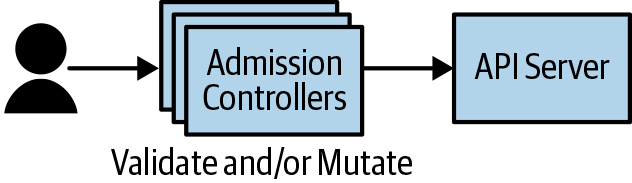
Figure 15-2. Admission controllers
The utility of admission controllers isn’t limited to adding sidecars. You can also use them to validate objects submitted by developers to Kubernetes. For example, you could implement a linter for Kubernetes that ensures developers submit pods and other resources that follow best practices for using Kubernetes. A common mistake for developers is to not reserve resources for their application. For those circumstances, an admission controller-based linter could intercept such requests and reject them. Of course, you should also leave an escape hatch (for example, a special annotation) so that advanced users can opt out of the lint rule, as appropriate. We discuss the importance of escape hatches later on in the chapter.
So far, we’ve only covered ways to augment existing applications and to ensure that developers follow best practices—we haven’t really covered how to add higher-level abstractions. This is where custom resource definitions (CRDs) come into play. CRDs are a way to dynamically add new resources to an existing Kubernetes cluster. For example, using CRDs, you could add a new ReplicatedService resource to a Kubernetes cluster. When a developer creates an instance of a ReplicatedService, it turns around to Kubernetes and creates corresponding Deployment and Service resources. Thus, the ReplicatedService is a convenient developer abstraction for a common pattern. CRDs are generally implemented by a control loop that is deployed into the cluster itself to manage these new resource types.
Extending the Kubernetes User Experience
Adding new resources to your cluster is a great way to provide new capabilities, but to truly take advantage of them, it’s often useful to extend the Kubernetes user experience (UX) as well. By default, the Kubernetes tooling is unaware of custom resources and other extensions and thus treats them in a very generic and not particularly user-friendly manner. Extending the Kuberentes command line can provide an enhanced user experience.
Generally, the tool used for accessing Kubernetes is the kubectl
command-line tool. Fortunately, it too has been built for extensibility.
kubectl plug-ins are binaries that have a name like kubectl-foo, where
foo is the name of the plug-in. When you invoke kubectl foo ...
on the command line, the invocation is in turn routed to an
invocation of the plug-in binary. Using kubectl plug-ins, you can define
new experiences that deeply understand the new resources that you have
added to your cluster. You are free to implement whatever kind of
experiences are suitable while at the same time taking advantage of the
familiarity of the kubectl tooling. This is especially valuable because
it means that you don’t need to teach developers about a new tool set. Likewise, you can gradually introduce Kubernetes-native concepts as the developers
advance their Kubernetes knowledge.
Design Considerations When Building Platforms
Countless platforms have been built to enable developer productivity. Given the opportunity to observe all of the places where these platforms have succeeded and failed, you can develop a common set of patterns and considerations so as to learn from the experience of others. Following these design guidelines can help to ensure that the platform you build is a successful one instead of a “legacy” dead end from which you must eventually move away.
Support Exporting to a Container Image
When building a platform, many designs provide simplicity by enabling the user to simply supply code (e.g., a function in Function as a Service [FaaS]) or a native package (e.g., a JAR file in Java) instead of a complete container image. This approach has a great deal of appeal because it lets the user stay within the confines of their well-understood tools and development experience. The platform handles the containerization of the application for them.
The problem with this approach, however, comes when the developer encounters the limitations of the programming environment that you have given them. Perhaps it’s because they need a specific version of a language runtime to work around a bug. Or it might be that they need to package additional resources or executables that aren’t part of the way you have structured the automatic containerazation of the application.
No matter the reason, hitting this wall is an ugly moment for the developer, because it is a moment when they suddenly must learn a great deal more about how to package their application, when all they really wanted to do was to extend it slightly to fix a bug or deliver a new feature.
However, it doesn’t need to be this way. If you support the exporting of your platform’s programming environment into a generic container, the developer using your platform doesn’t need to start from scratch and learn everything there is to know about containers. Instead, they have a complete, working container image that represents their current application (e.g., the container image containing their function and the node runtime). Given this starting point, they can then make the small tweaks necessary to adapt the container image to their needs. This sort of gradual degradation and incremental learning dramatically smoothes out the path from higher-level platform down into lower-level infrastructure and thus increases the general utility of the platform because using it doesn’t introduce steep cliffs for developers.
Support Existing Mechanisms for Service and Service Discovery
Another common story of platforms is that they evolve and interconnect with other systems. Many developers might be very happy and productive in your platform, but any real-world application will span both the platform that you build and lower-level Kubernetes applications as well as other platforms. Connections to legacy databases or open source applications built for Kubernetes will always become a part of a sufficiently large application.
Because of this need for interconnectivity, it’s critically important that the core Kubernetes primitives for services and service discovery are used and exposed by any platform that you construct. Don’t reinvent the wheel in the interest of improved platform experience, because in doing so you will be creating a walled garden incapable of interacting with the broader world.
If you expose the applications defined in your platform as Kubernetes Services, any application anywhere within your cluster will be able to consume your applications regardless of whether they are running in your higher-level platform. Likewise, if you use the Kubernetes DNS servers for service discovery, you will be able to connect from your higher-level application platform to other applications running in the cluster, even if they are not defined in your higher-level platform. It might be tempting to build something better or easier to use, but interconnectivity across different platforms is the common design pattern for any application of sufficient age and complexity. You will always regret the decision to build a walled garden.
Building Application Platforms Best Practices
Although Kubernetes provides powerful tools for operating software, it does considerably less to enable developers to build applications. Thus, it is often necessary to build platforms on top of Kubernetes to make developers more productive and/or Kubernetes easier. When building such platforms, you’ll benefit from keeping the following best practices in mind:
-
Use admission controllers to limit and modify API calls to the cluster. An admission controller can validate (and reject invalid) Kubernetes resources. A mutating admission controller can automatically modify API resources to add new sidecars or other changes that users might not even need to know about.
-
Use
kubectlplug-ins to extend the Kubernetes user experience by adding new tools to the familiar existing command-line tool. In rare occasions, a purpose-built tool might be more appropriate. -
When building platforms on top of Kubernetes, think carefully about the users of the platform and how their needs will evolve. Making things simple and easy to use is clearly a good goal, but if this also leads to users that are trapped and unable to be successful without rewriting everything outside of your platform, it will ultimately be a frustrating (and unsuccessful) experience.
Summary
Kubernetes is a fantastic tool for simplifying the deployment and operation of software, but unfortunately, it is not always the most developer-friendly or productive environment. Because of this, a common task is to build a higher-level platform on top of Kubernetes in order to make it more approachable and usable by the average developer. This chapter described several approaches for designing such a higher-level system and provided a summary of the core extensibility infrastructure that is available in Kubernetes. It concluded with lessons and design principles drawn from our observation of other platforms that have been built on top of Kubernetes, with the hope that they can guide the design of your platform.