
Chapter 4
yield return: Using .NET’s State Machine Generator
In This Chapter
![]() Understanding How yield return Works
Understanding How yield return Works
![]() Using yield return and yield break
Using yield return and yield break
“Always bear in mind that your own resolution to succeed is more important than any one thing.”
—Abraham Lincoln
Just a few short years ago, developers had to inherit from ReadOnlyCollectionBase or CollectionBase to implement strongly typed collections. If you wanted to define custom types, instead of using DataSets, then this was the way to go. With the introduction of generics, you no longer have to do that. However, until recently developers still had to write by hand all of the plumbing that created subtypes from those collections. Generally, this consisted of iterating over a loop, applying some filtering criteria, and then extracting only those objects into a new collection. This plumbing is routine and dull to implement (after a few hundred times). With yield return, you no longer have to write your own sublists.
Using the key phrase yield return, the .NET Framework (since 2.0) now code generates a state machine for us. The state machine is essentially an enumerable typed collection. The benefit is that you can focus on primary domain types and rest assured that support for subsets of this type are accessible through yield return or LINQ queries. In many cases, you will want to use LINQ queries for subsets, but yield return is worth exploring here.
This chapter looks at yield return and yield break. You’ll see how to use these constructs and take a peek at the code generated by these simple phrases.
Figure 4.1 You can drill down into the .NET Framework code if you really want to know how things work in .NET.
Understanding How yield return Works
The word yield by itself is not a keyword. This means we can still use yield as a variable, which might be helpful to financial people. However, yield return and yield break are key phrases.
Together, yield return is a compiler cue that tells the compiler to generate a state machine. Every time a line containing yield return is hit, the generated code will return that value. What happens is that the compiler generates an enumerator that adds the WhileMoveNext return-current plumbing without stack unwinding. This means that as long as there are more items to return, the stack is not unwound and finally blocks are not executed. When the last item is hit—when MoveNext returns false—the stack is unwound and finally blocks are executed.
The effect is that the function header looks like a function that returns an IEnumerable<T> collection of something. The key phrase yield return is an implementation of the iterator pattern, and it supports treating things simply like an iterable collection even if they are not.
Listing 4.1 shows a simple usage of yield return. GetEvens is used just like a collection and the yield return code generates an Enumerable class shown using Reflector in Figure 4.2.
Figure 4.2 An IEnumerable<T> class is generated when you use yield return as shown here in Lutz Roeder’s Reflector.
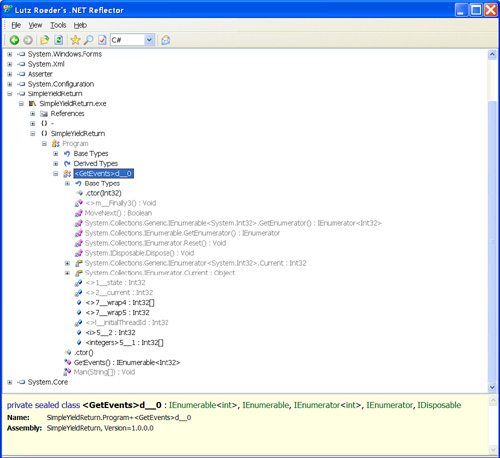
Listing 4.1 A Simple Demonstration of yield return
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace SimpleYieldReturn
{
class Program
{
static void Main(string[] args)
{
foreach(int i in GetEvens())
Console.WriteLine(i);
Console.ReadLine();
}
public static IEnumerable<int> GetEvens()
{
var integers = new[]{1, 2, 3, 4, 5, 6, 7, 8};
foreach(int i in integers)
if(i % 2 == 0)
yield return i;
}
}
}
The yield return key phrase enumerator also implements IDisposable and a try finally block implicitly exists (and is code generated) around the use of the generated enumerable object.
The yield return phrase is governed by these basic rules:
![]()
Yield return is followed by an expression where the expression has to be convertible to the type of the iterator.
![]()
Yield return has to appear inside an iterator block; the iterator block can be in a method body, operator function, or accessor (property method).
![]()
Yield return can’t be used in unsafe blocks.
![]() Parameters to methods, operators, and accessors cannot be
Parameters to methods, operators, and accessors cannot be ref or out.
![]()
Yield return statements cannot appear in a catch block or in a try block with one or more catch clauses.
![]() And, yield statements cannot appear in anonymous methods.
And, yield statements cannot appear in anonymous methods.
Using yield return and yield break
A function that has a yield return statement can be used for all intents and purposes, such as an IEnumerable<T> collection, that is, a collection of some object type T. This means you get the benefit of enumerability of any type of object without writing the typed collection class and plumbing for each type.
Listing 4.2 contains a BinaryTree class—a logical tree structure where each node contains zero, one, or two child nodes—that uses yield return to traverse the tree in order. In case you need a refresher, a binary tree starts with one root node. Then, nodes are added based on whether the value to be inserted is less than or greater than the root. For example, if you insert 5, 1, and 8, the tree will contain a root of 5, a left child of 1, and a right child 8. Insert 13 and 8 will have a right child of 13, and so on. To support comparing the data values of the generic BinaryTree<T> class, it is defined so that all types T have to be IComparable. IComparable ensures that you have a uniform way to examine nodes as you insert items in the list.
Listing 4.2 An InOrder Traversal Binary Tree Using yield return
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Runtime.Serialization;
namespace BinaryTreeDemo
{
class Program
{
static void Main(string[] args)
{
BinaryTree<int> integers = new BinaryTree<int>();
integers.AddRange(8, 5, 6, 7, 3, 4, 13, 21, 1, 17);
// display conceptual tree
integers.Print();
Console.ReadLine();
Console.Clear();
// write in order
foreach(var item in integers.Inorder)
Console.WriteLine(item);
Console.ReadLine();
}
}
// 8
// /
// 5 13
// /
// 3 6 21
// / /
// 1 4 7 17
public class Node<T> where T : IComparable<T>
{
public T data;
private Node<T> leftNode;
public Node<T> LeftNode
{
get { return leftNode; }
set { leftNode = value; }
}
private Node<T> rightNode;
public Node<T> RightNode
{
get { return rightNode; }
set { rightNode = value; }
}
/// <summary>
/// Initializes a new instance of the Node class.
/// </summary>
/// <param name=“data”></param>
public Node(T data)
{
this.data = data;
}
public override string ToString()
{
return data.ToString();
}
}
public class BinaryTree<T> where T : IComparable<T>
{
private Node<T> root;
public Node<T> Root
{
get { return root; }
set { root = value; }
}
public void Add(T item)
{
if( root == null )
{
root = new Node<T>(item);
return;
}
Add(item, root);
}
private void Add(T item, Node<T> node)
{
if(item.CompareTo(node.data) < 0)
{
if(node.LeftNode == null)
node.LeftNode = new Node<T>(item);
else
Add(item, node.LeftNode);
}
else if( item.CompareTo(node.data) > 0)
{
if(node.RightNode == null)
node.RightNode = new Node<T>(item);
else
Add(item, node.RightNode);
}
// silently discard it
}
public void AddRange(params T[] items)
{
foreach(var item in items)
Add(item);
}
/// <summary>
/// error in displaying tree - 7 is overwritten 17!
/// </summary>
public void Print()
{
Print(root, 0, Console.WindowWidth / 2);
}
public IEnumerable<T> Inorder
{
get{ return GetInOrder(this.root); }
}
IEnumerable<T> GetInOrder(Node<T> node)
{
if(node.LeftNode != null)
{
foreach(T item in GetInOrder(node.LeftNode))
{
yield return item;
}
}
yield return node.data;
if(node.RightNode != null)
{
foreach(T item in GetInOrder(node.RightNode))
{
yield return item;
}
}
}
private void Print(Node<T> item, int depth, int offset)
{
if(item == null) return;
Console.CursorLeft = offset;
Console.CursorTop = depth;
Console.Write(item.data);
if(item.LeftNode != null)
Print(“/”, depth + 1, offset - 1);
Print(item.LeftNode, depth + 2, offset - 3);
if(item.RightNode != null)
Print(“\”, depth + 1, offset + 1);
Print(item.RightNode, depth + 2, offset + 3);
}
private void Print(string s, int depth, int offset)
{
Console.CursorLeft = offset;
Console.CursorTop = depth;
Console.Write(s);
}
}
}
The statement in Main, integers.Print, displays the logical version of the tree in the way that we conceptually think of it.
More important, GetInOrder checks to see if the current node’s LeftNode is not null. While the LeftNode is not null, we walk to the farthest LeftNode using recursion and yield return. As soon as we run to the end of the LeftNode objects, we return the current node, which is the leftmost node, that node’s parent, and the right node. The process of following left edges and displaying left, parent, right ensures that the items are returned in order no matter what order they appeared and were added to the binary tree.
One drawback to the recursive implementation is that each call to GetInOrder creates an instance of the generated IEnumerable<T> object, so very large trees would create a large number of these object instances.
If we reverse the position of the LeftNode checks and the RightNode checks, we would get the ordered items from greatest to smallest.
To see different logical views of the tree and verify that GetInOrder always returns the items from smallest to largest, try changing the order of the items in the integers.AddRange method.
Profiling Code
If you want to see how code like that in Listing 4.2 performs, including how many objects are created and how long various function calls take, profile the application by following these steps:
1. Select Developer, Performance Wizard.
2. Choose the application to profile and click Next.
3. Specify the Instrumentation profiling method in the Performance Wizard.
4. Click Finish.
5. In the Performance Explorer, select the profiling project and click the Launch with Profiling button.
6. Let the program run through to completion and double-click on the performance report in the Performance Explorer (see Figure 4.3).
Figure 4.3 The view of the performance summary; select the type of view from the Current View drop-down list.
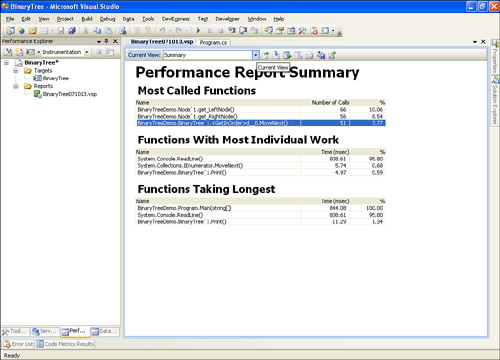
If you want to see how calls to the IEnumerable<T> generated class constructor were made, select Functions from the Current View. Instances of the code-generated enumerable collection should look something like <GetInOrder>d__0..ctor(int32).
You can use the results from the profiling session to see exactly what your code is doing and how long things are taking.
Using yield break
If, for some reason, you want to terminate a yield return before the last item is reached, use the yield break phrase. Listing 4.3 shows the proper use of the yield break phrase. The code breaks when the depth of GetInOrder recourses more than four times, printing only the top four levels of the tree.
Listing 4.3 Terminating a yield return Iterator with yield break
int depth = 0;
IEnumerable<T> GetInOrder(Node<T> node)
{
if(depth++ > 4) yield break;
if(node.LeftNode != null)
{
foreach(T item in GetInOrder(node.LeftNode))
{
yield return item;
}
}
yield return node.data;
if(node.RightNode != null)
{
foreach(T item in GetInOrder(node.RightNode))
{
yield return item;
}
}
}
Summary
The phrases yield return and yield break were introduced in .NET 2.0. yield return creates a code-generated, typed enumeration, and yield break terminates the iteration before the last item. You can still use yield return and yield break (and use yield as a keyword) in .NET 3.5, but essentially this behavior is an evolutionary step on the way to LINQ queries. For the most part, where you want an IEnumerable<T> collection, you can shorten the code by simply using a LINQ query.