
Chapter 9. Parallel LINQ to Objects
Goals of this chapter:
• Discuss the drivers for parallel programming, and how Parallel LINQ fits that story.
• Demonstrate how to turn sequential queries into parallel queries using Parallel LINQ.
• Demonstrate how to create a custom parallel operator.
This chapter introduces Parallel LINQ to Objects. PLINQ introduces data parallelism into LINQ queries, giving a performance boost on multi-core and multiprocessor machines while making the results predictable and correct. This chapter also demonstrates how to build your own parallel operator.
Parallel Programming Drivers
Microsoft has invested heavily in .NET Framework 4 and Visual Studio 2010 to allow all developers to safely and easily embrace parallel programming concepts within applications. The main driver for the Parallel Programming model is simply that the era of massive doubling and redoubling of processor speed is apparently over, and therefore, the era of our code automatically doubling in speed as hardware improves is also coming an end. This breakdown in Moore’s Law (proposed by an Intel executive that predicted a doubling of CPU processor speed every two years), as it is commonly known, was brought to a screeching halt due to thermal and power constraints within the heart of a PC in the silicon processor that executes programs. To counter this roadblock and to allow computing speed to continue to scale, processor manufacturers and computer hardware designers have simply added more than one processor into the hardware that runs code.
However, not all programming techniques, languages, compilers, or developers for that matter automatically scale to writing multiple core compatible code. This leaves a lot of unused processing power on the table—CPU processing power that could improve responsiveness and user experience of applications.
Microsoft’s MSDN Magazine published an article titled “Paradigm Shift—Design Considerations for Parallel Programming” by David Callahan,1 which offers Microsoft’s insight regarding the drivers and approach Microsoft is taking in response to the need for parallel programming techniques. It begins by setting the scene:
...today, performance is improved by the addition of processors. So-called multicore systems are now ubiquitous. Of course, the multicore approach improves performance only when software can perform multiple activities at the same time. Functions that perform perfectly well using sequential techniques must be written to allow multiple processors to be used if they are to realize the performance gains promised by the multiprocessor machines.
And concludes with the call to action:
The shift to parallelism is an inflection point for the software industry where new techniques must be adopted. Developers must embrace parallelism for those portions of their applications that are time sensitive today or that are expected to run on larger data sets tomorrow.
The main take-away regarding parallel programming drivers is that there is no more free application performance boost just because of a hardware CPU speed upgrade; for applications to run faster in the future, programming techniques that support multiple processors (and cores) need to be the standard approach. The techniques employed must also not be limited in how many CPU cores the code was originally authored from. The application needs to detect and automatically embrace the available cores on the executing hardware (which will likely be orders of magnitude larger in processing power) whether that be 2 cores or 64 cores. Code must be authored in a way that can scale accordingly without specifically compiled versions.
History of Processor Speed and Multicore Processors
Looking back at processor history, there was a 1GHz speed processor in 2000, which doubled in speed in 2001 to 2Ghz, and topped 3GHz in 2002; however, it has been a long hiatus from seeing processor speed increasing at that rate. In 2008 processor clock speeds were only just approaching 4Ghz. In fact, when clock speed stopped increasing, so did manufacturer marketing the speed of processors; speed was replaced by various measures of instructions per second.2 Power consumption, heat dissipation, and memory latency are just some of the plethora of limiting factors halting pure CPU clock-speed increases. Another technique for improving CPU performance had to be found in order to keep pace with consumer demand.
The limit of pure clock-speed scaling wasn’t a surprise to this industry as a whole, and Intel engineers, who first published an article in the October 1989 issue of IEEE Spectrum (“Microprocessors Circa 2000”3) predicted the use of multicore processor architecture to improve the end-user experience when using PCs. Intel delivered on their promise in 2005, as did competing processor companies, and it is almost certain that any computer bought today has multiple cores built into each microprocessor chip, and for the lucky few, multiple microprocessor chips built into the motherboard. Rather than straight improvement in processor clock speed, there are now more processor cores to do the work. Intel in their whitepaper “Intel Multi-Core Processor Architecture Development Backgrounder”4 clearly defines in an understandable way what “multicore processors” consist of:
Explained most simply, multi-core processor architecture entails silicon design engineers placing two or more Intel Pentium processor-based “execution cores,” or computational engines, within a single processor. This multi-core processor plugs directly into a single processor socket, but the operating system perceives each of its execution cores as a discrete logical processor with all the associated execution resources.
The idea behind this implementation of the chip’s internal architecture is in essence a “divide and conquer” strategy. In other words, by divvying up the computational work performed by the single Pentium microprocessor core in traditional microprocessors and spreading it over multiple execution cores, a multi-core processor can perform more work within a given clock cycle. Thus, it is designed to deliver a better overall user experience. To enable this improvement, the software running on the platform must be written such that it can spread its workload across multiple execution cores. This functionality is called thread-level parallelism or “threading.” Applications and operating systems (such as Microsoft Windows XP) that are written to support it are referred to as “threaded” or “multi-threaded.”
The final sentence of this quote is important: “Applications and operating systems...that are written to support it...” Although the operating system running code almost certainly supports multi-threading, not all applications are coded in a fashion that fully exploits that ability. In fact, the current use of multi-threading in applications is to improve the perceived performance of an application, rather than actual performance in most cases—a subtle distinction to be explored shortly.
Multi-Threading Versus Code Parallelism
Multi-threading is about programming a specific number of threads to deal with specific operations. Parallel programming is detecting the number of processors and splitting the work of a particular operation across those known CPUs (processor times cores). Splitting work in applications across multiple threads does introduce a form of concurrency into applications; however, multi-threading doesn’t natively offer computational performance improvement (in most cases) and comes at a high price in code complexity when built using current programming paradigms.
The parallel programming goal is to make sure applications take advantage of multiple cores for improving computational performance and continue to improve performance as more cores are added over time. This doesn’t simply occur by making applications multi-threaded. In fact, badly implemented threading code can hurt performance. True code parallelism offers the same benefits as multi-threading offers, but in a way that aims to improve computational performance of applications, whilst safeguarding against common concurrency defects and issues.
Pure multi-threading is most commonly used to improve the perception of performance in an application. The classic example is for common web browser applications; web browsers like Internet Explorer, Firefox, Safari all download and display the pages’ HTML content first, while behind the scenes they are gathering and progressively displaying images as they download over time. Why? If it took 15 seconds to download an entire page and images, blocking the user interface from accepting a response until it is complete, end users would feel (deservedly) unsatisfied. Launching the retrieval of images on a separate background thread keeps the user-interface thread available for other user-input—“Cancel, I made a mistake” or “Changed my mind, go here instead” as examples.
Building applications with the snappiness multi-threading concepts offers is addictive, although it is often difficult to synchronize access to shared resources like the user’s input or in-memory data. The permutations of what thread finishes and starts before another and the difficulty of debugging these defects leads to many abandoned attempts at improving perceived performance. Comprehending how to do even the most simple multi-threading application task without spending hours finding random crashes and application freezes is challenging and very time-consuming and mentally taxing. (These types of defects are called race conditions, the cause of many famous software production problems, including the North American Blackout of 2003, which was partially attributed to a software application race condition.5)
The following are some problems with using threading alone for code parallelism:
• Complex to write—Race conditions are hard to envision and debug.
• The correct number of threads is best equal to the number of CPUs—However, this changes from machine to machine. How do I spread the work required across multiple threads? How many threads are optimal?
• What if not all work takes equal time to run?—This could leave some CPUs idle when they could be taking on work overloading another CPU.
• Threads are heavy—Threads take memory and time to set up, manage, and teardown. Create too many of them and applications can exhaust available resources. Threads are allocated 1MB of memory by default by the CLR, not the sort of overhead you blindly want to assign. (See blog posting on the issue by Joe Duffy.7)
The underpinnings for all parallelism features, including the parallel extensions and Parallel LINQ, are threads. However, these libraries abstract away the direct manipulation of threading and give developers an easier interface to code against. The Task Parallel Library and Parallel LINQ reusable libraries allow a lighter-weight way of scheduling work and having that work efficiently executed across multiple CPUs. Microsoft has retained all of the benefits introduced through multi-threading applications but solved the problems working at the CPU’s thread level.
Application multi-threading advantages:
• Maintaining application UI responsiveness during long-running processes.
• Allows multiple requests or processes to be handled in relative isolation, that is, each input web request can be handled by a server on a different thread in isolation; if one fails, the others continue to function.
• Offload work can occur in the background—priority allows many applications to coexist sharing the available resources.
Application parallelism advantages:
• Same advantages as multi-threading offers.
• Computational performance is improved.
• Performance scales as more cores/processors are added without explicit user code to specify the hardware configuration.
Hopefully, you will see that multi-threading underpins all parallel programming techniques because it is the technology supported at a processor level. However, the perils (covered shortly) and complexity of actually utilizing threading to not only improve perceived performance, but actually reduce processing time, requires clever coding practices. Microsoft’s Parallel Extensions offer an approachable on-ramp for parallelizing general application code and goes a long way to addressing the common obstacles that surface when writing parallel applications.
Parallelism Expectations, Hindrances, and Blockers
Parallel program performance isn’t always a linear scaling based on the number of CPU cores, as will be shown shortly through examples. (Doubling the number of cores doesn’t halve the execution time.) There are many factors that contribute to supporting and hindering performance improvements using parallel programming techniques. It is important to understand these hindrances and blockers in order to leverage the full power of the toolset provided and to know when to invoke its power.
Amdahl’s Law—You Will Still Be as Slow as the Longest Sequential Part
Amdahl’s Law defines the fundamental maximum performance improvement that can be expected for parallel computing. Amdahl’s Law models the performance gain of a parallel implementation over its sequential counterpart. It simply states that the maximum parallel performance improvement is limited by the time needed by any sequential part of an algorithm or program.8
Amdahl’s formula is
Overall performance gain = 1 / ((1-P) + (P/Speedup))
(P = proportion supporting parallelization, Speedup = 2 for two CPUs, etc.)
It seems reasonable to determine that if a sequential program was spread across two cores, the maximum performance gain would be 2x. However, in reality, not all of the program can run in parallel, and the actual performance gain will be lower than 2x. How much lower? That depends on how much of the algorithm supports parallelization. If a sequential algorithm implementation takes one second, and 20% of the program is written to support parallel execution on a dual-core machine (2 CPUs), the maximum performance boost from parallelization would be 1/ ((1-0.2) + (0.2/2)) = 1.11 times improvement.
Amdahl’s Law is handy to put correct expectations around the benefit and time spent when optimizing an application. The more code you write to support parallelization (and therefore decrease the amount of sequential time), the closer to the theoretical maximum speedup you approach. (If you want to read more, seek out John L. Gustafson’s article that looks at the shortcomings and reevaluation of Amdahl’s Law with respect to massively parallel systems, like those becoming available now at http://www.scl.ameslab.gov/Publications/Gus/AmdahlsLaw/Amdahls.html.)
The key point is that to fully embrace parallelism and to achieve closer performance gains to the theoretical best possible performance (doubling for two processors, quadrupling for four, and so on), the algorithm and work partitioning should be designed to limit the sequential time required for a program.
Parallel Overhead—Finding the Ideal Work Partition Size
There is overhead in running an application across multiple CPUs. Some work is involved in forking, merging, and managing the partitioning of work that each thread (and eventually CPU) will execute. It should make sense that if the work being performed in parallel takes less time than the overhead of making that code execute in parallel, then the code will take longer to execute.
There is art in understanding what granularity work should be partitioned. Too small and you will actually harm performance; too big and you are not taking advantage of scheduling tasks across multiple CPUs. There is no substitute for testing performance tradeoffs using different granularity of work partitioning.
The key point here is that parallelism doesn’t come completely free; there is a sweet-spot for work partition size, and this needs to be considered when writing parallelized code. Testing and profiling is the only way to be sure the work time is more than the overhead for parallelizing that work.
Synchronization—Parallel Partitions Working as a Team
Sometimes code running on one CPU needs to access data from another. This synchronization harms performance because the object needed has to be locked, and other parallel execution paths might need to wait for that lock to be removed before they can proceed, so it gets very hard to predict actual performance gains.
The best possible performance can be achieved when tasks being performed in parallel have no shared data; they are completely isolated, and no synchronization locks are needed. This takes careful design and sometimes means creating parallel work at a different granularity or changing your algorithm approach in such a way that the only synchronization needs to occur at the completion of the task (rather than throughout).
The key point is to keep parallel tasks as autonomous and self-contained as possible. Any external synchronization will reduce performance or introduce hard-to-debug race conditions.
Data Ordering
Ordering and parallelism have a natural tension. When a dataset order cannot be impacted, the implementation of how parallel tasks are executed and the results merged narrows considerably, causing a performance decrease. In most cases, the parallel implementation will still be superior in performance to the sequential implementation, but for the best parallelization, try and limit order dependence.
The key point is that if ordering is required to be predictable, then parallel performance is traded. This can often be minimized by increasing the granularity of the task to run order dependent code in one task, or order dependent code executed sequentially after the parallel processing has been carried out.
Exceptions—Who Stops When Something Fails?
Exception that occurs in a parallel task offers great challenges. How this exception is trapped and where that exception is marshaled is problematic to design, predict, and implement. Sounds obvious, but avoid exceptions! You have to be prudent and carry out more precondition checking to handle exception cases in an organized fashion without resorting to throwing an exception or having one raised on your behalf.
Dealing with These Constraints
Dealing with and understanding the constraints of writing operational parallel code is an important skill. Microsoft’s Parallel Extensions offer solutions to the general challenges, but in order to successfully write code that performs exceptionally in a multicore environment, you often need to explicitly tell the executing framework what your requirements are for your specific case. For example, if the data order needs to be maintained, you need to tell the compiler that is the case. You will pay a performance penalty (maybe still faster than a sequential algorithm, maybe not), but for the final result to be correct, the compiler must be told to maintain the current data order.
Microsoft has addressed the issues of parallelizing data problems through a specific technology called Parallel LINQ. The technology tackles parallelizing data querying and manipulation in a coherent fashion without causing data corruption or incorrect results. It still has to abide by the constraints and limitations as listed here, but the heavy lifting and consistent programming pattern it provides reduces the variation in personal techniques.
LINQ Data Parallelism
LINQ queries are designed for working with sets of data and provide a convenient vehicle for taking the complexity out of coding data querying and manipulation tasks. Parallel LINQ to Objects is a set of standard query operators similar (almost identical) to the sequential standard query operators that are implemented using the Parallel Extensions for .NET 4, a library of data structures and thread-pool implementations that help a developer perform efficient parallelization. The implementation of these parallel standard query operator variants use the entire arsenal offered by the parallel framework extensions in order to improve the throughput of the LINQ queries; however, as will be quickly evident, it is not wise to just use these operators as direct replacements to their sequential counterparts in all cases.
To understand the benefit of Parallel LINQ queries, the following example shows the results and performance of a LINQ query before and after parallelization. The actual performance increase and CPU load during the sequential and parallel example are explored here for you to see that traditional sequential queries may not (and will not) use all of the CPU processing power natively. This CPU usage pattern will be contrasted against the CPU usage when Parallel LINQ is invoked.
Parallelizing a Query—Geonames Example
Geonames.org is an online geographic database of over eight million place names. The files are available for download under a Creative Commons license, and the website contains regional subsets of data and also a complete file of all place names (780MB when I downloaded it for this example). The files are in a specific tab-separated text structure, with over 15 columns of data, including elevation, name, and a two-letter country code. The example query will simply iterate this file and return a sorted list of all entries with an elevation greater than 8,000 meters.
Note
.NET 4 introduced new overloads into the File and Directory classes. File.ReadLines previously returned a string[] of all lines in a file. A new overload returns an IEnumerable<string>, which allows you to iterate a file (using this method, you could always iterate the file manually) without loading the entire file contents into memory. This helped a lot with our 780MB text file parsing.
Geonames Sequential LINQ
The LINQ query will iterate all the lines in a file containing all the Geonames content, looking for all places with an elevation greater than 8,000 meters and then ordering them from highest elevation to lowest elevation. Listing 9-1 shows the basic query to parse and query our target text file. (Full code and instructions for getting these samples working are available at http://hookedonlinq.com/LINQBookSamples.ashx. The Geonames AllCountries.txt text file is freely downloadable from Geonames.org at http://download.geonames.org/export/dump.) When this query is executed, the total CPU usage uneasily steadies around 55%, and 22.3 seconds later (this will of course be machine-dependent, including hard-drive speed), the results are returned. The Console output from this example is shown in Output 9-1.
Listing 9-1. Geonames parsing sequential LINQ query—CPU utilization is shown in Figure 9-1—Console output is shown in Output 9-1

Output 9-1

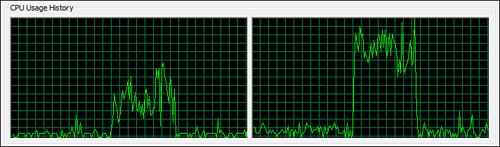
During the processing of the file, a capture of the CPU utilization graph shows that one core was doing most of the processing, and although it had peaks, the average CPU usage was well below what was available with dual cores, as shown in Figure 9-1. The average displayed throughout for both CPUs was 55%. The actual time will differ from computer to computer and run from run, but for this experiment, the numbers will serve as a comparative benchmark.
Figure 9-1. CPU utilization for Geoname sequential LINQ query—total time: 22.6 seconds.
Geonames Parallel LINQ
It is a very simple code change to turn a sequential query into a parallel query, although as is discussed later in this chapter, no one should blindly make all queries parallel. In most basic terms the extension .AsParallel() added to any IEnumerable<T> source will cause the parallel query operators to be invoked. Taking the query part from the code listed in Listing 9-1, the parallel-equivalent query utilizing Parallel LINQ is shown in Listing 9-2. (The only change is shown in bold.)
Listing 9-2. Geonames parsing parallel LINQ query—CPU utilization is shown in Figure 9-2—Console output is shown in Output 9-1

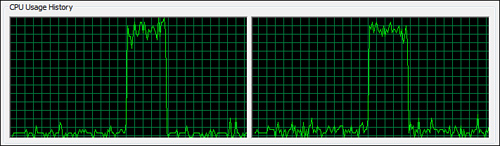
When the query in Listing 9-2 is executed, the total CPU usage steadies quickly to around 95%, and 14.1 seconds later as shown in Figure 9-2 (this will of course be machine-dependent, including hard-drive speed), the identical results to the sequential query are furnished. CPU core usage is much more balanced and even throughout the query’s execution, not perfectly even but far superior to the sequential version. Although the query didn’t run twice as fast (as might be expected on a dual-core machine), the speed improvement is significant and was solely achieve by adding an .AsParallel() to the sequential query.
Figure 9-2. CPU utilization for Geoname parallel LINQ query—total time: 14.1 seconds.
Falling short of the perfect doubling of performance in this case is due to the constraints spoken about earlier (Amdahl’s Law, ordering, and so on); there is overhead in managing the parallelization process and sorting and is to a large degree limited by the disk access speed. It is important to also realize that if this same test had been run on a quad-core processor, the results would have been closer to a four times increase in performance with no additional code changes. (Although never exceeding, and who knows when your hard-drive access speed limits improvement, the key point is no code changes are required to take advantage of more cores.)
Having seen this example, understanding what actually occurred behind the scenes to parallelize a LINQ helps you realize what queries will substantially be improved by adding the AsParallel extension to a data source and what queries will actually degrade in performance.
What Happens During a Parallel LINQ Query?
The general parallelization process for a query is to partition the work, hand off the work to worker processes running on different threads, and merge the results on completion. To achieve this general process, a query marked to execute as parallel goes through the following (much simplified here for clarity) process by the Parallel LINQ runtime:
- Query analysis (Will parallelism help?)
- Partitioning
- Parallel execution
- Merging the parallel results
Each of these steps is covered briefly here in order to help you understand how queries might be structured for best parallel performance.
Query Analysis
The first step when a LINQ query is passed to the Parallel LINQ execution engine is query analysis. The query pattern is examined to determine if it is a candidate for parallelization improvement with respect to time and memory resources. If it isn’t, then the query will be executed sequentially.
The runtime doesn’t look at the size of the data or how much code is in the delegate functions; it simply examines (at this time, but who knows in future updates) the shape of the query and determines if it is worth the parallel overhead. The query can be forced to execute in parallel (or not) if the conservative nature of the run-time decision process isn’t acceptable for a given case. To force a query to execute in parallel, add a WithExecutionMode extension to the ParallelQuery source. There are two values for the enumeration, default and ForceParallelism, which should not need further description.

There can be at most a single WithExecutionMode per query, even if that query is composed using the result of a previous query. Multiple WithExecutionMode extensions will cause a System.InvalidOperationException at runtime with the message:
The WithExecutionMode operator may be used at most once in a query.
Microsoft has said that they will continue to evolve the query assessment over time and devise new algorithms for improving the parallel performance of different query patterns that currently would fall back to sequential execution. Once the framework decides that a query is a candidate for parallelization, it moves onto partitioning the data, which is simply splitting the input data for efficient execution in chunks on multiple cores.
Partitioning Data
Parallel LINQ has a number of data partitioning schemes it uses to segment the data for different worker processes. For example, if an input source has one hundred elements, when this query is run on a dual-core machine, the Parallel LINQ execution engine might break the data into two partitions of 50 elements for parallel execution. This is a simplistic case, and in practice, partitioning the data is more complex, and the actual chosen partitioning scheme depends on the operators used in the query, among other factors.
The built-in partition schemes at the time of writing are called chunk, range, striped, and hash. Each of these data partitioning schemes suits a certain set of source data types and operator scenarios; the parallel runtime chooses the appropriate one and partitions the data for execution when a worker process asks for more work.
You are not limited to the partitioners Microsoft has built-in. They have allowed for custom partitioners to be written for a specific purpose; this topic is beyond the scope of this book, but search online for Partitioner<TSource> for details. To understand each of the built-in partitioners and to understand their relative strengths and weaknesses, each partitioning scheme is now briefly explained.
Range Partitioning
The range partitioning scheme breaks an input source data set into equal-sized ranges optimized for the number of threads determined available (best case: equal to the number of cores available). Range partitioning is chosen when the data source is indexible (IList<T> and arrays, T[]). For indexible sources like these, the length is known without having to enumerate the data source (to determine the count), and the number of elements per partition for parallel execution is simply calculated upfront.
This partitioning scheme offers great parallel efficiency, largely from not needing any synchronization between participating threads. Threads get a range of data assigned to them and can process that data without any interaction (incoming or outgoing) with other threads. The downside of this thread isolation is that other threads cannot help out if one thread gets behind in processing due to uneven utilization; on balance though, this partitioning scheme is efficient.
Chunk Partitioning
Chunk partitioning is used when a data source isn’t indexed (an IEnumerable<T> where the elements can’t be accessed by index and the count property cannot be ascertained without an enumeration of the entire data source).
Microsoft has optimized this partitioning scheme for a wide variety of queries, and although the exact algorithm isn’t known, the responsible team’s blog postings9 indicate that that the number of elements per partition is doubled after a certain number of requests and so on. This allows this partitioning scheme to be adaptable from sources with only a few elements to sources with many million elements, keeping each core filled with work, while still balancing their load to ensure the greatest chance of each core finishing close to the same time.
As mentioned previously, this partitioning algorithm can’t be as exact as range partitioning, and you should strive for using an indexible collection for your parallel data sources whenever possible.
Hash Partitioning
This partitioning scheme is for queries (containing operators) that need to compare data elements. For example, the following operators compare key hash values when they execute: Join, GroupJoin, GroupBy, Distinct, Except, Union, and Intersect. The intention of this partitioning scheme is that elements that share the same key hash-code value will be partitioned into the same thread. The alternative options of partitioning elements would require extensive and complex inter-thread synchronization and data sharing. This partitioning scheme reduces that overhead and enhances parallel performance for queries using these operators.
The downside however is that hash partitioning is complex and has a higher overhead than the partitioning schemes listed so far. However, it is the most efficient and viable option for query operators that need to compare hash codes to do their work, such as GroupBy and Join.
Striped Partitioning
Striped partitioning is used for standard query operators that process and evaluate from the front of a data source. SkipWhile and TakeWhile are the operators that use this partitioning scheme. Striped partitioning is only available when the data source is indexible (IList<T> and arrays, T[]) and assumes that each element needs to be processed almost sequentially in order to avoid launching off a significant amount of work that has to be thrown away at merge time. It achieves this by taking very small ranges at a time, processing these in parallel to gain some optimization, and then merging carefully based on the result of the While predicate.
Striped partitioning is a sample of where a specific partitioning scheme can be written to optimize specific operators.
Parallel Execution
Once data is partitioned, it is executed in parallel using the underlying Parallel Framework extensions. Exactly how this occurs is irrelevant for our discussion, although it is safe to say that Microsoft used all of the concurrency APIs, like the Task Parallel Library, Tasks, Work Stealing Scheduler, and the co-ordination data structures that have been discussed online and demonstrated at conferences. I’m sure more information will emerge online over time as to exactly how Microsoft built the parallel versions of the standard query operators. Later in this chapter a custom parallel operator is explained by example, and this offers some insight into how many of the operators might work.
Merging the Parallel Results
After each thread has completed, its results must be merged into the final result sequence (or value). Microsoft has allowed some control over when results are made available, either immediately after a partition is processed or buffering the results until all partitions have completed. This control is provided by using the WithMergeOptions extension and choosing a value of NotBuffered, AutoBuffered (the default), or FullyBuffered.
![]()
Some queries (or at least the parts of the query before and up to an ordering operator) cannot honor this setting, like Reverse and OrderBy, which need the entire result set buffered in order to carry out their tasks.
Although it might seem at first glance that Microsoft should have simply made all LINQ queries just execute in parallel, the issues of data ordering, exception handling, and race conditions (all of the parallelism blockers described earlier) make the explicit decision to parallelize important for the developer to consider. The next section explores another potential pitfall of simply making all queries parallel—not enough work being carried out.
It’s Not as Simple as Just Adding AsParallel
To invoke the parallel variations of the standard query operators, it can be as simple as adding an AsParallel extension to any IEnumerable<T> source collection, as shown in the following example:

The addition of the .AsParallel() in the query q1 invokes the parallel version of the LINQ standard query operators. If everything is working correctly, the queries should yield the same result. Here is the console output from iterating each query:

Surprised? The actual order is indeterminate, and every execution of query q1 could yield a different result (based on the partitioning scheme used and the number of cores available). Our query hasn’t specified that order is important, and although the normal standard query operators retain data order unless told otherwise (more by luck than convention—it’s just the way they were coded), the parallel variations do not guarantee order retention unless forced. This is to maximize parallel performance; however, the point is that improving query performance using Parallel LINQ isn’t as simple as running through your code adding AsParallel to every query, as this may introduce unintended result changes.
Making Order Out of Chaos—AsOrdered and Sorting
Is data ordering important? If a query is simply summing a value or processing each element, then maybe order isn’t important. In these cases the parallel runtime should be left alone to do its work unhindered. However, if order is in fact important during or for the final result, then control should be invoked by one of the following means:
• Add an orderby clause (as seen in q2 below) to force an order.
• Add an AsOrdered extension to tell the parallel runtime to leave the order as it is in the original source (as seen in q3 that follows).

The result of both ordering schemes are the same (in this case, only because the source collection was already in the desired order) and identical to the sequential version of the query as seen in query q previously:

These are very simple queries, and writing them for parallel execution doesn’t offer great customer performance gains; however, they do allow us to understand the impact of ordering. The following data shows the length of time taken to run 100,000 iterations on my dual core laptop, and these times are only meant to be read as relative to each other—the actual time is less important in this example.

As you can tell, parallelizing this query with only 11 elements and no where clause or significant element select processing was detrimental to performance by many times. Even increasing the number to 1,000 elements doesn’t demonstrate any improvement.
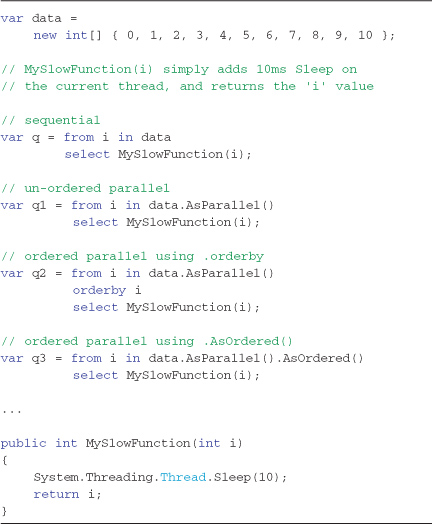
Performance improvement is most profound as query complexity and element count increases, especially in the actions that occur on each collection element. The previous example was very contrived and was introduced to demonstrate the indeterminate ordering and performance effects that just adding an AsParallel to a query can introduce. Listing 9-3 demonstrates how to make a simple query parallel; in this case, a function simply adds a thread sleep for 10ms for each element, but that function could carry out any type of processing per element.
Listing 9-3. Parallelizing a simple query that does “actual” work on each element
The execution time of 100,000 times for each of these queries demonstrates the performance improvement on a dual-core computer in the Beta version of .NET 4, shown in Table 9-1.
Table 9-1. Query Execution Times for the Queries Shown in Listing 9-3

The parallel queries did operate faster, as expected. In this case, on a dual-core process, the results were generally slightly less than double. There is overhead in parallelizing, and a key advantage of this code is that with nothing more than the addition of an AsParallel extension to the sequential query, it would likely run close to (but slightly less than) four times faster on a quad-core and eight times on an eight-core processor, and so on, depending on how loaded the CPU is at runtime.
The AsParallel and AsSequential Operators
The AsParallel operator attached to the source of a LINQ query turns a sequential query into a parallel query. (Parallel means the overload operator extending ParallelQuery<T> is called rather than the overload extending IEnumerable<T>.) The AsSequential operator on the other hand, returns the query from that point forward to calling the sequential operators (the IEnumerable<T> overload rather than the ParallelQuery<T>). Put simply, these extension methods allow you to opt-in and opt-out of using the Parallel LINQ extensions from within a query expression itself.
To maximize the efficiency of LINQ queries, it is sometimes necessary for the developer to take control over what parts of a query are parallel and which parts aren’t. Some operators exclude the query from seeing any parallel performance improvement, and in order to allow Parallel LINQ to operate on other parts of a query, some developer intervention is required.
When to Use the AsSequential Operator
The ability to control what parts of a query are sequential and what parts are executed parallel allows you to isolate parts of a query that run slower when executing concurrently. This is often the case when queries are composed (one query used as the source of another). When composing queries in this way, it can be useful to force one part to be sequential while another is parallel. A good strategy is to carefully consider which parts of a query benefit from parallelization, and isolate the sequential portion of any query at the end by inserting it after an AsSequential operator.
Remembering back to the early sections of this chapter where the Parallel LINQ process was described, the initial step in an analysis of the LINQ query is to determine if parallelization is a good fit. This process entails looking at the operators called in a query, and if certain operators are called (particularly on non-indexed collection types), then those queries are executed sequentially. You can use the AsSequential operator to isolate those operators and achieve a greater use of parallelization in the areas that benefit.
The exact rules about when Parallel LINQ will decide to execute a query as sequential (even though you specified an AsParallel) is likely to change as Microsoft adds more capabilities into their analysis and operators in the future. At the time of writing, the easiest way to see this occur is to use the Take operator on an IEnumerable<T> sequence (in our case, the anonymous projected result from a query). The following query would execute as sequential if source was an unindexed collection:
var q = source.AsParallel().Take(5);
To demonstrate this phenomenon, consider the following query, which should run parallel given it has an AsParallel extension. However, Listing 9-4 shows a query that due to the Take operator, execution will be carried out sequentially and no improvement in execution speed from the sequential version occurs (both around 30 seconds).
Listing 9-4. This query will operate sequentially without isolating the Take operator in this case—see Listing 9-5 for how to fix this situation

For the main part of the query in Listing 9-4 to execute as parallel, it is necessary to isolate the Take operator in the query by preceding it with an AsSequential operator. This increases the performance of this query substantially, dropping over seven seconds from the sequential time. (On a dual-core machine, these times are meant to be indicative.) The optimized version of this query is shown in Listing 9-5.
Listing 9-5. Isolating the Take operator with AsSequential shows an improvement over the sequential query

The indicative performance of each of these queries can be measured as
![]()
This short example demonstrates the need to be diligent about understanding what impact some operators have on the ability to just add an AsParallel to a query. Developers must be diligent about profiling and measuring query performance when invoking the parallel operators.
Two-Source Operators and AsParallel
There are a number of operators in LINQ that take two data sources:
• Concat
• Except
• GroupJoin
• Intersect
• Join
• SequenceEqual
• Union
• Zip
When parallelizing queries that use any of these binary operators, both data sources must be marked with the AsParallel operator (and optionally with AsOrdered) to avoid a runtime exception being raised. Early versions of the Parallel LINQ extensions didn’t enforce this dual opt-in process, and it was difficult to specifically control the ordering semantics of those queries. Forcing the developer to explicitly control the ordering semantics bridges this gap and makes queries predictable.
Failing to specify the second data source as parallel causes an obsolete warning during compilation with instructions on how to resolve the issue. Microsoft decided to make this condition obsolete by marking the overload taking the second data source of IEnumerable<T> with an [Obsolete] attribute and by throwing a System.NotSupportedException when called; the method signatures are shown in Listing 9-6. This messaging is intended to help the developers understand what they need to do in order to parallelize these operators.
Listing 9-6. Calling binary operators with Parallel LINQ requires that both sources are ParallelQuery<T> types

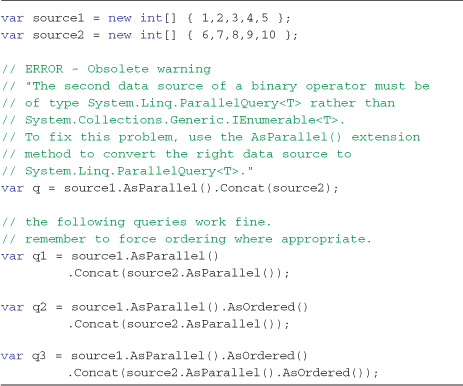
Listing 9-7 demonstrates how to correctly call a binary operator when using ParallelQuery collections as the two input sources and shows the error message displayed when both sources aren’t of ParallelQuery type.
Listing 9-7. Using binary operators with Parallel LINQ
Writing Parallel LINQ Operators
Convention would dictate that whenever a sequential LINQ operator is written, a parallel operator should be considered to support the Parallel LINQ programming pattern users will come to expect based on the support of the other standard query operators (not a definite requirement, but should be considered). Not all operators will significantly benefit from parallelization, and without an understanding of a specific operator, it’s hard to capture explicit guidance in this area. The following types of operators make exceptionally good candidates for parallelization:
• Order-independent operators that iterate an entire source collection, for example, Where.
• Mathematical aggregate functions such as Sum.
• Operators that can yield partial results before the entire source collection has been processed by that operator (allowing the next operator to begin before all data is furnished by the previous operator).
Other operator types could still benefit from parallel implementations, but the overhead is high, and the linear scaling of performance versus number of CPU cores will reduce.
Parallel Operator Strategy
Implementing parallel operators in a raw form can be challenging. At the lowest level, you can use the Task Parallel Library as the basis for underlying algorithms, but you should exhaust all other avenues for operator implementation first. Here is some general guidance when attempting to build a parallel extension method operator:
• Try and compose your operator using the current Parallel LINQ operators.
• Use the aggregate extension method operator whenever possible (demonstrated shortly).
• Build the operator using the Task Parallel Library looping constructs System.Threading.Parallel.For and System.Threading.Parallel.ForEach.
• This should be rarely necessary—build your operator using the Task Parallel Library Task class directly.
Before going down any of these paths, however, you should optimize the sequential algorithm as much as possible. The sequential algorithm will form the basis for the parallel implementation.
To demonstrate the process for writing a new parallel operator, a statistical extension method for calculating the variance and the standard deviation of an integer data source are shown. Parallel queries are especially suited for queries over large numeric data sets, and aggregating statistical values is a common business requirement for scientific and financial software.
Building a Parallel Aggregate Operator—Sample Standard Deviation
To demonstrate making a parallel operator, we will implement a statistical function for standard deviation, which is a measure of variance for a set of data. In order to build this operator, you follow the general development steps:
- Create and test a sequential algorithm.
- Optimize the sequential algorithm as much as possible.
- Create and test the parallel algorithm.
- Add error-handling condition guard code. (This can be done at any stage.)
Creating the Sequential Algorithm
Like many computing problems nowadays, our first port of call is to search the Internet for algorithms and reference material. A quick search of Wikipedia shows that variance and standard deviation can be calculated using the following formulas:
![]()
Note
This isn’t a statistics guide; I’m using the sample variance and standard deviation formula [the difference being the division of n or (n-1)]. I chose the sample variance because I get to demonstrate how to handle more error conditions later. If you use this code, check whether your situation needs the population equations or the sample equations for variance and standard deviation—Wikipedia has pages of discussion on this topic!
Focusing on building the Variance operator first allows most of the mathematics to be isolated to a single function (standard deviation is simply the square-root of this value). This strategy simplifies the StandardDeviation operator to a Math.Sqrt() function on the result of the Variance function.
The most basic sequential Variance operator function to start with, built using the aggregate standard query operator, is shown in Listing 9-8.
Listing 9-8. Simple sequential variance calculation

After testing the operator shown in Listing 9-8 through unit tests to ensure proper mathematical results, optimizing performance can begin. A simple execution time profile of the code was undertaken by measuring the time taken to calculate the variance on a data set size of 100,000 elements 1,000 times. The results of this can be seen in Table 9-2. I also tested the data source being an indexed array and an IEnumerable<T> to isolate if there were any performance issues with both types of input data source. The results were 17 to 20 seconds, and with this baseline, optimization and refactoring can begin.
Table 9-2. Performance Refactoring on Sequential Variance Operators. Source Was an Array or an IEnumerable of 100,000 Integers—the Variance Was Calculated 1,000 Times Each Test

Optimize the Sequential Algorithm
The Variance operator functionally works and follows the most basic equation implementation possible. However, the Math.Pow() method is extremely expensive, as we are just squaring a single value. An easy refactoring is to use simple multiplication instead, and the resulting performance increase is dramatic (approximately four times, as shown in Table 9-2). Listing 9-9 shows the refactoring required making this optimization.
Listing 9-9. First optimization of the sequential operator—remove the Math.Pow function

It should always be a goal to minimize the enumerations of the source collection whenever possible. In our current incarnation of the Variance operator, there are two loops through the collection. The first in the aggregate function and the second in the call to Count in the final aggregation argument. If the source collection is indexed, then this call might be avoided, but if it isn’t, the Count extension method has no choice but to iterate the entire source and count as it goes. We can do better.
The Aggregate operator can use any type as a seed. If we use an array as that type (double[]), we can store multiple values in each element loop. In this case, we can keep the running total of elements (count), the running sum of the element values (sum), and also the sum of the squares (sum of squares). This enables us to do a single pass through the values and have all the required data to calculate the variance value in the final Selector function of the Aggregate query operator.
Listing 9-10 shows the final refactoring, although a little more complex than its predecessors, it operates much faster as seen in Table 9-2.
Listing 9-10. Optimized sequential Variance operator code, the basis of our parallel implementation
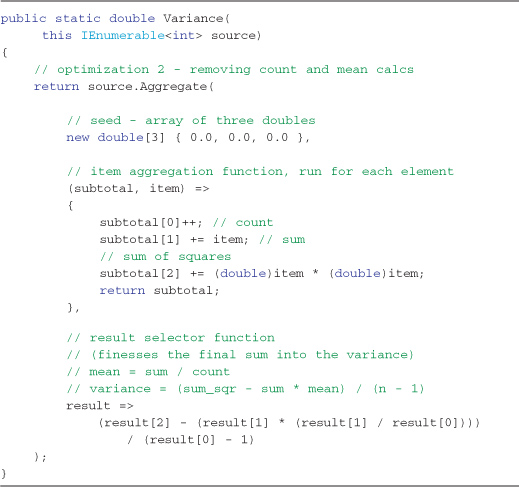
As Table 9.2 shows, the performance benefits gained by optimizing the sequential algorithm are substantial—more substantial than relying on parallel optimizations alone.
Now that the Variance operator has been written, the StandardDeviation operator simply builds upon the result as shown in Listing 9-11. This example also demonstrates the generally accepted pattern of defining an overload that takes a value Selector function—this follows the pattern set forth by the supplied aggregation standard query operators and is recommended.
Listing 9-11. Sequential implementation of the StandardDeviation operator

Create and Test the Parallel Operator
It is a straightforward adaption from the sequential code that is built using the Aggregate standard query operator to derive the parallel operator using the Parallel LINQ Aggregate standard query operator. A Parallel LINQ operator is an extension method of the ParallelQuery<T> type, rather than the IEnumerable<T> type.
The Parallel Aggregate standard query operator has an extra argument not present on its sequential counterpart. You read earlier that data is partitioned and acted upon by different threads of execution during parallel query execution. This necessitates that each thread’s result must be merged with the other threads’ results in order for the aggregation to be mathematically sound. We need to supply this Combine Accumulator function (for each thread result), in addition to the Update Accumulator function (each element).
Listing 9-12 shows the standard query operators with no error guards or handling (we get to that in a moment). If you compare it to the optimized sequential operator in Listing 9-10, you can see the subtle changes. We continue to use our single pass aggregation function, but we update it to work in a concurrent world. The changes made were as follows:
• IEnumerable<T> was replaced by ParallelQuery<T> for this extension method. Any query that operates over a source.AsParallel will be routed to this extension method overload rather than the sequential overload.
• The seed array is created using a factory function; this allows each partition to create (by calling this function) and operate on its own seed array in isolation, avoiding any contention between threads during the aggregation process.
• The Combine Accumulator function can just add (sum each element with the same element by index position) the left and right side arrays.
Listing 9-12. The parallel Variance and StandardDeviation extension methods

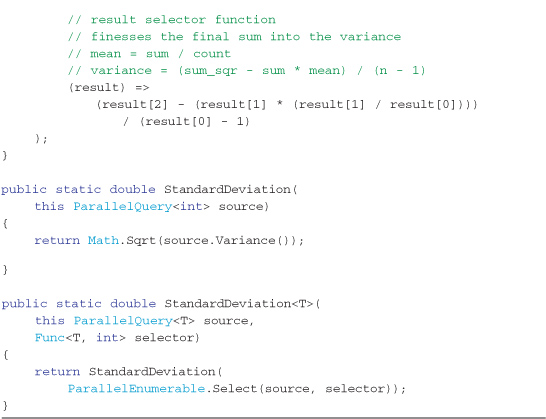
Table 9-3 documents the simple profiling carried out over the sequential and parallel algorithms, for both a simple array and an IEnumerable<T>. These numbers will change depending on your machine—this test was carried out on a dual-core processor. You will notice that the parallel IEnumerable<T> algorithm was actually slightly slower than its sequential counterpart (even when forced parallel using the WithExecutionMode extension). There is not enough work being done here to counteract the cost of accessing the enumerable (that is, locking it, retrieving elements from it, releasing the lock, processing those elements, and going back for more).
Table 9-3. Performance Refactoring on Sequential StandardDeviation Operators. Source Was an Array or an IEnumerable of 100,000 Integers—the Standard Deviation Was Calculated 1,000 Times Each Test.

This test was carried out on the Beta 2 version of the .NET 4 framework, and I’m interested to see how final performance tuning of the Parallel LINQ algorithms makes this number improve by release time. You can rerun these numbers at any time by downloading the sample code from the HookedOnLINQ.com website (http://www.hookedonlinq.com/LINQBookSamples.ashx).
Adding Error Handling
Having written our operators, handling input and specific error cases need to be introduced. The following input source conditions need to be considered, tested, and handled accordingly:
• The source argument is null—throw an ArgumentNullException for the source argument.
• The source argument is an empty array—return zero.
• The source argument contains only one element—return zero.
Choosing to return zero for an empty array and an array with a single element is very specific to this operator and my particular specification. Generally, an InvalidOperationException is thrown, but for a statistical measure of variance, I decided to avoid an exception in this case. Microsoft Excel returns a #DIV/0! error for a single element sample standard deviation calculation, which I find unfriendly, albeit arguably more correct.
The null source error is easily handled with an initial check coming into the variance extension method, as we saw extensively in Chapter 7, “Extending LINQ to Objects.” The error check is accomplished by adding the following code:
![]()
Although the single check before the initial variance calculation for a null source is acceptable (being unavoidable), the check for zero or a single element in the source requires some thought. Adding a check before the aggregation function, similar to the following example, might cause an entire enumeration of a source array if that source is not an indexed collection, but an IEnumerable<T>:
![]()
When we build parallel operators, we are doing so to improve performance, and looping over data sources should be limited to as few times as possible (one time ideally). Our algorithm using the Aggregate operator offers us an ideal solution. The final Selector function has access to the cumulative count determined in the aggregation loop. We can use a ternary operator to check for zero or one element at that time and return a value of zero in that case. We have avoided an extra loop and have catered to the two conditions we want to isolate with a single conditional check. That final Selector function looks like this:
![]()
This code is functionally equivalent to the following if conditional statement:

Listing 9-13 shows the final StandardDeviation and Variance operators, including the accepted error handling code. The changes are minor (indicated in bold); an additional check for a null source and the final Selector function having logic to handle no source elements.
Listing 9-13. Final parallel StandardDeviation and Variance operators including error handling code


Summary
This chapter explained what you can expect from and how to code LINQ queries that support multi-core processors and multiple CPU machines. This has always been possible, but the complexity caused difficult-to-debug programs and hard-to-find bugs. Parallel LINQ makes coding queries that support parallelism both easier and more predictable.
Writing your own parallel operators is no more difficult than writing a good sequential operator (when building on top of existing operators), and when a programming task is going to operate on large collection sizes of data, an investment in time is worth making.
The final take-away and warning (a pattern throughout this chapter) is that an improvement in performance by using Parallel LINQ in a query should not be taken for granted. Profiling and comparing the results is always necessary in order to ensure any significant performance improvement is actually being achieved.
References
1. Callahan, David. “Paradigm Shift—Design Considerations for Parallel Programming,” MSDN Magazine: October 2008, http://msdn.microsoft.com/en-us/magazine/cc872852.aspx.
2. http://en.wikipedia.org/wiki/Instructions_per_second.
3. Gelsinger, Patrick P., Paolo A. Gargini, Gerhard H. Parker, and Albert Y.C. Yu. “Microprocessors, Circa 2000” IEEE Spectrum: October 1989, http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=40684 http://mprc.pku.edu.cn/courses/architecture/autumn2007/mooreslaw-1989.pdf
4. Whitepaper: “Intel Multi-Core Processor Architecture Development Backgrounder,” http://cache-www.intel.com/cd/00/00/20/57/205707_205707.pdf.
5. http://en.wikipedia.org/wiki/2003_North_America_blackout.
6. http://en.wikipedia.org/wiki/Race_condition.
7. Joe Duffy blog posting, “The CLR Commits the Whole Stack,” http://www.bluebytesoftware.com/blog/2007/03/10/TheCLRCommitsTheWholeStack.aspx.