
The D programming language contains value types, pointer types, and reference types. Each type has unique storage attributes and manifests a different functional lifetime. Additionally, type attributes can affect the lifetime of the associated declaration, occasionally in rather unique ways. The aim of this chapter is to explore the lifetime guarantees afforded to each kind of type and to elucidate some of the more specialized language behavior related to the lifetime of reference types.
Before diving into the particulars of specific data types, it may be useful to review how types are classified. D language types fall into three main categories:
Value: A value type is a type whose data is inextricably linked to the point of declaration. The size needed to store such a type is known at compile time and directly affects the footprint of the function or user-defined type (UDT) in which it is declared. D's basic data typesint, char, float, and so onare all value types, and each has specific size and storage requirements outlined by the language specification. |
| Pointer: As discussed in Chapter 2, a pointer type is a special kind of value type that represents a memory address. The size needed to store a pointer type is always the size of a memory address on the target system, regardless of the underlying data type to which the pointer refers. Because of this separation between variable and data, the lifetime of a pointer is unrelated to the lifetime of the data to which it refers. Thus, the garbage collection of a pointer variable affects only the address value, and not any underlying data to which the pointer may refer. |
Reference: A reference type is a special kind of pointer type that does not require the usual machinations to distinguish between operations on the address and operations on the underlying data. Like pointers, however, reference types occupy a small, fixed amount of space at the point of declaration (typically the same amount as a pointer, though this is not required), and the data resides elsewhere. Similarly, when a reference type is garbage-collected, the data or object it references is not, unless the reference type has the scope attribute (discussed in Chapter 3). |
The lifetime of a variable is a function of the scope in which it is declared. If a variable is declared within a function, for example, space will be allocated for that variable when the function is called and will be collected when the function returns. Similarly, variables declared within the scope of a struct or class definition are a part of each instance of that type.
However, sometimes you may find that certain data or functions must be unique to the type in which they are declared, rather than to each instance of that type. It is for this purpose that the storage class attributes are provided, as discussed in the next section.
A storage class attribute is attached to variables to tell the compiler how data associated with that declaration should be stored. In essence, a storage class dictates a variable's lifetime with respect to its declaration scope. D provides two storage classes that affect a variable's lifetime: auto and static.
auto dictates that a variable's lifetime is tied to that of the enclosing scope. In other words, the memory reserved for auto variables is collected automatically when program execution leaves that scope. Here is an example:
import tango.io.Stdout;
int autoFunc( int x )
{
auto int y;
Stdout.formatln( "y is {}, setting to {}", y, x );
y = x;
return y;}
void main()
{
int ret;
ret = autoFunc( 1 );
Stdout.formatln( "autoFunc returned the value of y, which is set to {}", ret );
ret = autoFunc( 2 );
Stdout.formatln( "autoFunc returned the value of y, which is set to {}", ret );
}Here, you can see that the value of y is not persistent across calls to autoFunc. Instead, space is allocated for y when autoFunc is called, and it is collected when autoFunc returns.
auto is the default storage class in D, so it is not necessary to precede variable declarations with auto. In practice, the most common use of an explicit auto storage class is for automatic type inference, as the presence of a storage class is necessary to indicate to the compiler that a statement is a declaration if the type qualifier is omitted.
static dictates that a variable's lifetime is tied to that of the module in which it is declared. The variable is initialized once when the module is loaded, and it is available until the module is unloaded. Here is an example:
import tango.io.Stdout;
int staticFunc( int x )
{
static int y;
Stdout.formatln( "y is {}, setting to {}", y, x );
y = x;
return y;
}
void main()
{
int ret;
ret = staticFunc( 1 );Stdout.formatln( "autoFunc returned the value of y, which is set to {}", ret );
ret = staticFunc( 2 );
Stdout.formatln( "autoFunc returned the value of y, which is set to {}", ret );
}Here, space is allocated for y when the module in which it is declared is loaded, and this space persists until the module is unloaded. Thus, the value of y is effectively persistent across calls to staticFunc. Static variables may be declared at any level and will behave the same way. However, static variables may be initialized only at the point of declaration if the initialization value can be computed at compile time. In other instances, a static constructor must be used, as explained next.
Attaching the static attribute to a constructor or destructor indicates that it should be associated with the lifetime of the enclosing module rather than with an instance of the enclosing type. In other words, static constructors are called when the module in which they are declared is loaded, and static destructors are called when the module is unloaded.
Static constructors are called in lexical order from the top to the bottom of the module, and static destructors are called in reverse lexical order. This order of processing guarantees that initialization dependencies are preserved within a module.
As you've learned in previous chapters, a D module is a file in which D code resides. Therefore, discussion of source files should be considered equivalent to discussion of modules. That said, it is preferable to think in terms of modules when evaluating program behavior because modules provide a means of encapsulation not unlike classesthey can contain constructors, destructors, and so on. With this in mind, a few issues must be considered with respect to procedural lifetime.
Note
It is possible to subvert the one-file-per-module design through careful use of the module statement, but this is an advanced trick with few practical applications.
When a module is loaded, its static constructors will be called in lexical order from the top to the bottom of the file, regardless of their declaration scope. Thus, the following example should display ABC when run.
module MyModule;
import tango.io.Stdout;
struct MyStruct
{
static this()
{
Stdout.formatln( "A" );
}
}
static this()
{
Stdout.formatln( "B" );
}
class MyClass
{
static this()
{
Stdout.formatln( "C" );
}
}
void main() {}Similarly, to ensure that dependent variables are cleaned up in the proper order, a module's destructors will be called in reverse lexical order when the module is unloaded. Thus, the following example should display CBA when run:
module MyModule;
import tango.io.Stdout;
struct MyStruct
{static ~this()
{
Stdout.formatln( "A" );
}
}
static ~this()
{
Stdout.formatln( "B" );
}
class MyClass
{
static ~this()
{
Stdout.formatln( "C" );
}
}
void main() {}While initialization within a module occurs relative to lexical order, an initialization order is defined only when importing two or more modules that have a dependency relationship and contain static constructors or destructors. For these sets of modules, their relative order of initialization is guaranteed to be performed relative to the dependencies defined by their import statements. For example, consider an application containing modules declared like so:
module E;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "E" );
}
module D;import E;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "D" );
}
module C;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "C" );
}
module B;
import C;
import D;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "B" );
}
module A;
import C;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "A" );
}
module Main;
import A;
import B;
import tango.io.Stdout;
static this()
{
Stdout.formatln( "Main" );}
void main()
{
Stdout.formatln( "Hello, World!" );
}Displayed graphically, the modules exhibit the dependency relationships shown in Figure 4-1.
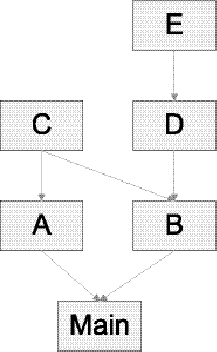
Given this set of modules, it should be clear that Main depends on A and B, A depends on C, B depends on C and D, and D depends on E. Because all the involved modules contain static constructors, you can be sure that E will be initialized before D, which will in turn be initialized before B; that C will be initialized before both A and B; and that A and B will be initialized before Main. Running this program produces the following output:
C A E D B Main Hello, World!
However, other permutations are possible, as long as they maintain the dependency rules described earlier.
All modules statically reachable during compilation will be loaded on program initialization and unloaded on program termination. However, it may be useful to know the order in which each step involved in initialization and termination takes place "behind the scenes" in a D application.
Like an object, a D program has initialization, execution, and termination states. Also, if program initialization fails, the execution and termination states are never reached. However, if the program has been initialized successfully, its termination sequence will be run, even if execution completes via an unhandled exception. This mimics the behavior of an object as well, since scoped objects will have their destructor called on scope exit, regardless of whether scope is exited via a normal return or via a thrown exception.
The initialization process of a D program begins by loading and initializing all modules in the program according to the dependency rules described in the previous section. Once all modules have been loaded, any available unit tests will be executed. Then the program is considered to be in an initialized state, and execution begins.
Program execution continues until all non-daemon threads (including the main thread) have returned, either via normal processing or via an unhandled exception. Once this occurs, the program is considered to be in the termination (or halting) state.
Note
A non-daemon thread is a thread whose isDaemon property is set to false. This value is false by default in Tango.
During program termination, all module destructors will be run according to the dependency rules outlined earlier, and then a normal garbage-collection cycle may occur to finalize any lingering objects. The program is then considered to have terminated, and any remaining resources will be unloaded as the process exits.
As you've learned, the static storage class is a means of extending the lifetime of data beyond that of the scope in which it is declared. But different types of non-static variables have varying lifetime characteristics when used as parameters to or return types of functions. The first of these are arrays.
As you learned in Chapter 2, D provides two kinds of arrays with similar semantics but distinct characteristics:
| Static array: This type of array is called static because its size is fixed at compile time and may not change. |
| Dynamic array: This type of array is called dynamic because its size is not specified and therefore may be changed arbitrarily at runtime. |
These two kinds of arrays exhibit the essential characteristics of a value and a reference type, respectively, but there are some subtle differences that should be noted.
Note
Some languages use the terms fixed-length arrays and variable-length arrays. The terms dynamic and static are used here instead to be consistent with the D language specification. The term static here applies to whether the array may be resized, and has no relation to the static storage class in D.
Static arrays are value types, and as such, their footprint exists entirely at the point of declaration. If a static array is declared within a function call, its data will be rendered invalid when execution leaves the function, and declaring a static array within the body of a struct or class directly affects the memory required for an instance of that type. Static arrays are identified by a size qualifier in the appropriate dimension of an array declaration. Here is an example:
int[4] varA; int[2][4] varB;
In these declarations, varA is a static array that contains four int values, and varB is a two-dimensional static array that contains four static int arrays, each with room for two values. The memory reserved for static arrays matches exactly the size of the contained type multiplied by the number of elements in the array.
Unlike other value types, however, static arrays may not be used as return values for functions, and they are passed to functions by reference. Here is an example:
import tango.io.Stdout;
void alter( char[7] param )
{
param[] = "7654321";
}
void main()
{
char[7] message = "1234567";
Stdout.formatln( "{}", message );
alter( message );
Stdout.formatln( "{}", message );
}Because static arrays are value types, you might expect space to be reserved for param, and the current contents of message to be copied into this space when alter is called, thus localizing the operations performed on param to the scope of alter. This is not the case, however. All arrayseven static arraysare actually passed by reference, and therefore the example prints "1234567" followed by "7654321."
In practice, the effect a length specifier has for array parameters is to restrict the type of data passed into the function and to dictate whether the array may be resized. It has no effect on whether that parameter is passed by value or by reference.
The length of dynamic arrays is not fixed, and the memory to which a dynamic array refers may be shared with other dynamic arrays, it may reside on the stack, and so on.
Combined with the garbage-collection feature in D, dynamic arrays are often called slices to suggest that they may represent an arbitrary sequence, or slice, of data. In addition (and suggested by the slice terminology), dynamic arrays are not required to reference an entire array in order to preserve it from garbage collection. Such use of dynamic arrays lends a great deal of expressiveness to the language, and it can result in surprising performance gains by substantially reducing the number of memory allocations required for common operations.
Dynamic arrays are identified by the omission of a size qualifier in the appropriate dimension of an array declaration. Here is an example:
int[] varA; int[4][] varB;
In these declarations, varA is a dynamic array of int values, and varB is a dynamic array of static arrays, each containing a sequence of four int values. The memory reserved for dynamic arrays is equivalent to two pointer values from which the length of the array and a pointer to the array data may be obtained via the length and ptr properties, respectively.
As expected, dynamic arrays are passed by reference when used as function parameters. Dynamic arrays may be used as return values as well, and it is here that unexpected behavior may arise if you are not cautious. It was previously stated that dynamic arrays may refer to any sequence of memory. But what if that memory was not dynamically allocated? Consider the following example:
import tango.io.Stdout;
char[] getMessage()
{
char[5] buf = "hello";
char[] ret = buf;
return ret;
}
void main()
{
char[] msg = getMessage();
Stdout.formatln( "{}", msg );
}When execution enters the getMessage function, space is reserved on the stack for buf, and the string "hello" is copied into that space. When buf is assigned to ret, however, ret merely obtains a reference to this datano copying takes place. Thus, when execution leaves the scope of getMessage, the data space reserved for buf is collected, and the value portion of ret is copied and returned. Remember, however, that the value portion of a reference type is merely the reference itself, so msg is assigned a reference to data that no longer exists. The common term for such a variable is a dangling reference, and any use of msg prior to its reassignment to a valid data region will result in undefined behavior, which is essentially a technical term for "something bad" (usually data corruption or program failure).
Much as dynamic arrays may be used to reference data declared in an arbitrary scope, delegates may refer to functions declared in an arbitrary scope. And like dynamic arrays, data declared within a scope surrounding the referenced function may have a lifetime that is different from that of the reference itself.
Note
References to functions declared at module scope are referred to as function pointers, and are represented by the function keyword. In the future, however, delegates will likely be able to refer to all function types.
Consider the getMessage example in the previous section. There, a reference to a function's local data was passed out of the scope in which that data was valid, causing unpredictable behavior if that reference were ever used. Delegates behave much the same way. Here is an example:
import tango.io.Stdout;
alias void delegate() Operation;
void perform( Operation op )
{
op();
}
Operation func()
{
int x = 0;
void putAndIncrement()
{
Stdout.formatln( "x is {}", x++ );
}perform( &putAndIncrement );
return &putAndIncrement;
}
void main()
{
Operation op = func();
perform( op );
}In this program, the function putAndIncrement is declared within the scope of func and therefore has access to the variables declared within func, as well as to those in surrounding scopes. This is fine for the call to perform that occurs within the scope of func, because execution has not yet left the scope of func, and therefore any data it contains is valid. So, the first call to perform should print x is 0 to the console. But then a reference to putAndIncrement is returned as a delegate, and execution leaves the scope of func, causing the data it contains to be collected. At this point, any further reference to x invokes undefined behavior.
Note
A recent addition to D 2.0 provides experimental support for full closures. This should eliminate all the issues described here by dynamically generating a copy of the referenced calling context if needed.
One important issue to be aware of is that delegates do not reference variable data directly, but rather reference the calling context in which these variables are declared. So the problem with putAndIncrement was not that x is a value type so much as that the calling context no longer exists. Consider the following program, which substitutes a reference type for x:
import tango.io.Stdout;
alias void delegate() Operation;
void perform( Operation op )
{
op();
}
Operation func()
{
char[] message = "hello";void putMessage()
{
Stdout.formatln( message );
}
perform( &putMessage );
return &putMessage;
}
void main()
{
Operation op = func();
perform( op );
}This program will print hello to the console, as expected, and then enter the realm of undefined behavior, just like the previous program. To help clarify why this is so, assume that a calling context is something like a struct, and it is this to which the delegate refers. So when func returns, the context struct is collected, and the delegate no longer has any way to reference data local to func.
Lazy expressions are a convenience type for delaying the evaluation of an expression used as a function parameter. Their primary advantage over the use of delegate literals is that the user of a function with lazy arguments doesn't need to be aware that some of the parameters may not be evaluated immediately, while the use of delegate literals makes this explicit.
It is important to note that lazy expressions are merely a convenient method for working with a specific kind of delegate, and they are represented as delegates internally by the compiler. For this reason, the behavior of lazy expressions should be considered identical to that of delegates in the same context. Fortunately, lazy expressions are not implicitly convertible to delegates, so it is difficult to use them in a dangerous manner.
By default, dynamic memory allocations performed in D via new, by manipulation of the length property for arrays, and by array operations such as concatenation and appending of elements are provided by a garbage-collecting allocator. D imposes no functional requirements on the actual garbage-collector implementation, but typically, a garbage collector will periodically identify memory blocks that are no longer referenced by the application, finalize these blocks if appropriate for the data they contained, and then reuse the freed memory for future allocations.
Concerning the lifetime of types, the important issue is that the collection of a given memory block is not guaranteed to occur in a timely manner, and some blocks may be missed entirely. While this may be an unnecessarily grim proclamation concerning the reliability of automatic garbage collection, it is an important issue to be aware of in times where the observable lifetime of data is important. In practice, the safest approach is to avoid reliance on a destructor to clean up limited resources unless the object's lifetime is explicitly managed either manually or via the scope attribute.
As one basic example, consider an object that represents a file:
class File
{
this( char[] name )
{
fd = open( name );
}
~this()
{
close( fd );
}
private int fd;
}Further, assume that the operating system on which this program runs allows a process to maintain a maximum of ten open files at a time. If a program operates on a large number of individual files and simply discards the objects when done (instead of destroying them explicitly with delete), it is conceivable that the program could reach a state where no more file descriptors are available and yet the garbage collector has not yet collected any file objects, even though some may be available for collection.
In short, it is not safe to assume that the garbage collector knows more about what needs to be done than you do yourself. If any object owns a limited resource, consider managing its lifetime explicitly rather than relying on the garbage collector to take care of things in a timely manner. It is also a good habit to get used to D's scope attribute (discussed in Chapter 3) and scope statement (discussed in Chapter 2) to simplify the management of such objects. By doing so, your applications will be more reliable and more efficient.
This completes our discussion of the lifetimes associated with the different D types. Understanding the language's behavior is this regard will help you to avoid many problems. In the next chapter, you'll learn about D's templates, which are powerful programming tools.