
When dealing with performance, a lot of little design concerns may improve or worsen the overall feel of the application. Let's look at the most used or misused techniques.
Caching data means reusing a temporary copy of such data for a short time period, reducing the need to contact a persistence storage or any external system, such as a service.
In respect to performance indicators, caching is something that boosts the throughput and latency of data retrieval by avoiding a round trip to an external server that is running a database. Meanwhile, caching increases client resource usage of CPU and memory. Storing temporary data in a cache is something that is fully handled by a caching framework that has the task of removing old data from the cache when the imposed timeout occurs, or when there is too much data within the cache and older (or less used) data must be removed in order to create space for any new data. This is why when lots of data is deliberately loaded and maintained in memory, to prevent future data loading at application start, we do not use cache. We simply load all data into the memory.
Since .NET 4.0, a new assembly containing caching services has been added to the framework (for old .NET editions, a cache framework was available in the System.Web namespace). The System.Runtime.Caching.MemoryCache class is used to manage an in-memory configurable data cache. A distributed cache service for on-premise or cloud services is available under the name AppFabric Cache.
Caching is a design technique that must work at the boundary of each layer where it is potentially needed. In multi-tier architectures, the cache is always used at the boundary of the tier.
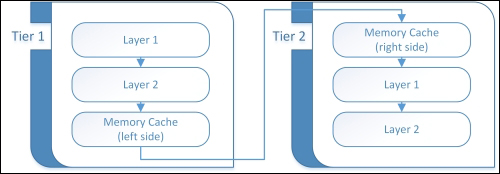
A boundary cache: one at tier 1 and one at tier 2
As visible in the preceding diagram, we find two cache proxies at boundaries of tiers. The one on the left side (at boundary exit) can avoid round trips on the network, along with avoiding data loading from the following tier. Caching at a boundary exit is possibly the biggest performance booster against indicators such as latency and throughput.
The one on the right side (at boundary entrance) can reduce the core logic, and eventually, core data gateways work when the response is already available. An instance of this kind of caching is the OutputCache of any ASP.NET application.
In enterprise-level applications, in which many requests are made with a lot of data to handle, it is a good idea to have the two cache levels working together to reduce any kind of already-done logic or data retrieval. This is commonly named multilevel cache.
Be cautious to cached item's lifetime, handled with absolute or relative expiration. Eventually, if a cached item changes it's value before it's cache expiration time then use object poisioning (it is the art of removing a data entry that is not good to be committed), especially in distributed cache systems. Also, take care of item assigned key, expecially when using a multilevel cache, because if such cache has heterogeneous data entries against the same key, a possible data inconsistency may arise.
The Integrated in-code querying support made by the LINQ framework in 2007 with .NET 3.0, changed the mind of developers completely when dealing with data. With these frameworks, any enumerable data available in .NET or externally with specific providers (such as a DB), is available to any object filtering/grouping/reshaping with a single unified querying language.
Task Parallel Library (TPL) and PLINQ (LINQ + TPL) did the same thing in 2010, adding parallel elaboration to any enumerable dataset. The TPL, which will be discussed later in Chapter 4, Asynchronous Programming, is the basis of all asynchronous programming model on .NET 4.0 or greater. Things such as asynchronous tasks or multicore asynchronous execution of any LINQ query definitely cuts the edge with legacy programming when dealing with computations and iterations.
Dividing thousands of items in to tens of threads may be the best choice when dealing with a very high throughput demanding code; the sooner the code terminates its job, the better it is.
When creating applications such as web or serviced types, where any user request comes across a new thread, creating so many computational threads per user can produce a worse performance than using normal LINQ instead of PLINQ. Such thread usage might let you finish the thread pool provision, further reducing the thread creation time drastically, along with the high resource cost of creating hundreds of threads.
Although definitely needed, such kinds of applications should avoid multiplying thread creation by using standard LINQ queries. A detailed overview about PLINQ and TPL will be available in Chapter 4, Asynchronous Programming.
This design inverts the usage of references between classes. Usually, a class uses its references, thus becoming the orchestrator. Inversely, when using the IoC design, a class asks for any implementation of such a desired interface (contract) and waits for the factory to be able to find a suitable external class/component to fulfill this need.
Although this choice can lead to writing winning solutions for design (this depends on the taste of the architect dealing with such architecture), with great modularization and code reusability, and in respect to module reusability, this choice is a bit unpredictable regarding performances.
An application may perform well with a good (or fake for testing purposes) external module and badly with a bad one. It is hard to test something external that was made by someone else. It is also hard to test something that will be made in the future, maybe because in a couple of years, new external components will become available and possibly usable in such applications.
When dealing with such a problem, the performance engineer's job is to isolate the poorly performing modules within the whole application. This helps to identify the reason for such bad performance of the external module and helps maintain a secure application all around, limiting the exploitation made by the assembly injection or cracking.
Lazy loading is the art of never preloading data or simple class instances. Like caching that prevents duplicated logic from being executed, by saving the result, lazy loading prevents the execution of some logic or data retrieval until it is actually needed. For instance, Entity Framework (EF) definitely uses a lot of lazy loading in query execution and query compilation. Chapter 7, Database querying, will focus entirely on data retrieval with EF.
A lot of attention must be given to what logic or data should be delayed in a lazy environment. Never delay data that will be requested just a second later or in massive amounts.
Regarding performance impact, lazy loading the right data will boost the startup of the application or the response time of a web application. Some general improvement in latency will occur too if unnecessary data is loaded when not needed. Obviously, when an application is completely used by its users, loading all composing modules, any lazy data could be already loaded without altering any performance aspect, compared to a non-lazy approach.
Lazy loading first boosts latency time by trying to delay a secondary logic execution (or data retrieval) to some future time. The drawback happens specifically when a bad design occurs with intensive single data requests (instead of a single complete one) or multiple execution of the same logic for lots of items, without relying on any asynchronous or parallel technique. Lazy loading also alters the execution flow from an imperative instantiation time to a less predictable one. Debugging will suffer because of this.
On the contrary, there is pre-loading data. Although this feels like a legacy option, do not discard it for just this reason. All application level data that can be loaded only once can definitely be loaded at startup. This will increase at such a time, but with the right user acknowledgment, like an old-style initialization bar, the user will feel that the system is loading what is needed, and this is always a good practice, while until the end, such data will grant the best latency time as it wont incur any retrieval cost.
Usually, mixing caching with lazy or pre-emptive loading is always a bad choice because they have opposite goals. Caching is for slow-changing data, increasing initial latency and resource usage for a future improvement in throughput. Lazy loading, on the other hand, reduces (boost) initial latency by delaying tasks to a short timed future by drastically reducing the throughput of data retrieval, which usually lacks any optimization technique.
It is well known that coding is the love of any developer. It is like a special kind of craziness that takes control of the brain of any developer when a new solution, algorithm, or logic is actually made. Just like how when someone using Microsoft Word presses the Save button when they finish writing something new and important, a developer will try to save the application code when new code is inserted for future usage. Although any code may be reused by cutting and pasting, this is not code reusability.
Writing a good component or control is not easy because most of the code must be reusable. A good component must be autonomous, regarding any eventual implementation. The more autonomous and agnostic the code is, the easier it becomes for any future user of such a control.
For instance, Text Box is a text container. It does not matter if it's usually used for text and not for numbers; it also supports numbers, passwords, and so on. Whoever made the control had to test all possible usage scenarios, without supporting a single use case.
Well-performing code should usually be customized to your specific application or platform needs. Another big deal to face is that eventually, unbelievably complex code structures are made to achieve the best abstraction level without keeping in mind maintainability or any design/architectural guideline. This is where performance optimization cannot be applied. In a certain way, performance and agnosticism are opposites. This is not an always-true rule, but it is the most frequent situation.
This is why most component/control products on the market are usually extremely complex to use and slow at runtime, as some kind of customization in look or behavior is needed.
An idiom is a specific technical implementation of a feature provided by a single framework.
For instance, a .NET interface is an idiom because in a lot of other programming languages, it just does not exist. With such interfaces, a lot of designs and paradigms become available. What if we want to write an easily portable (between different languages) application? We would lose all such creational availability.
Entity Framework offers many idioms, such as the ability to have an object-oriented expression tree that represents the query as an object through the IQueryable interface. More details can be found in in Chapter 7, Database Querying. Any instance of an object query based on such an interface is able to give anywhere, until executed, the ability to alter the query that will be executed, maybe changing requested data or modifying request filters, like in an object-oriented dynamic SQL. Another instance is using EF (an agnostic ORM framework) to add thousands of inserts, instead of using an SQL Client provider's specific feature such as the Bulk Insert. The ability to use any database is a great design goal, but giving a boost of 10 times the insertion time is actually a goal, too.
An agnostic code is some kind of really reusable and application or target unaware code. Agnostic code cannot use any idioms. This is the price to be paid for such reusability.
As seen earlier, in terms of mobile platform architectures, agnostic code is easily movable between platforms or projects. Although a shared assembly is also usable by all platforms, why do we let the more powerful system pay for the limitation of the smaller one? We definitely need to make the right choice regarding our specific priority here.
Coding without wasting rows is usually something good for each aspect. It shows the developer's skills, along with the understanding of the business problem. An extremely short code, such as when playing a code-golf challenge, may also produce some drawbacks.
Generally, although short coding may reduce debugging easiness and code understanding to other developers, it may improve better performance results. A single huge LINQ query versus a multiple-step one usually produces better SQL (if applicable) or a better in-memory query.
It's also true that the CLR virtual machine (the details are given in the next chapter) optimizes some code execution to improve code speed at runtime, but such speed can be wasted by a simple academically-styled code that greatly improves the main tenability. Sure, this can happen; but at what price?
Short coding with several comments may be the right balance for real-world programming.
In the Microsoft programming world, remote computation never had its time. Web services helped a lot, but add a server class system is usually only a bit more powerful than a desktop class system, so we have had to wait for the mobile devices era to need this kind of logic again. Microsoft's Cortana (voice-assistant) or Apple's Siri is a direct example of this design.
The remote computation occurs when we use the device as a console for a more powerful system. In the example of the two vocal assistants, the device uses its microphone and speaker to get the request from the user and then give back the answer in the form of an audio wave.
Local devices cannot process vocal analysis at the same time with the same accuracy and updatability of a remote system that is always available to users through an Internet connection.
Remote computation virtually extends the throughput of any device, because as time changes, new resources are added to the cloud provider that is playing the vocal assistant, along with server-side optimizations eventually.
When we have to face great computational goals, we may use the same solution by using cloud systems or legacy intranet systems. Usually, a secondary, smaller, and weaker edition of the same system is already released at the client's level to maintain the availability of the whole system because of eventual Internet congestion, or simply due to unavailability.
We have seen cloud architectures and abilities at different points in this chapter.
The choice to use a cloud provider as a system to drive our application is usually based on expected client needs. On premise applications, this might work fine if there is a finite number of clients that usually use a certain kind of logic within corporate level system capabilities. What if we need to load a huge dataset that exceeds internal system capabilities for only two days? Using a cloud provider, we can use an extremely enterprising class of virtual hardware for a few hours.
Talking about performance, a cloud provider has virtually infinite scalability and availability, along with very good efficiency and throughput. Latency and resources usage are based entirely on our design, but features systems as distributed cache and FIFO queues are available immediately via a cloud provider. Asking for these features in a legacy company may need time and lot of IT management effort. In addition, scaling a web server is easy in every company's internal data center by buying some network balancer, while letting scale (in high availability) an SQL Server or an MSMQ cluster virtually without limits is not so easy at all!
Several performance benefits are available through using a cloud provider, along with any new features available in the future through this winning technology.