
When dealing with a huge dataset, non-functional requirements definitely become a primary concern. We cannot place our primary focus on a domain, leaving non-functional requirements as a secondary concern, because a single system that can fulfill a big data application's needs by itself simply does not exist.
When dealing with big data solutions, a lot of the work of a developer is predicting usage patterns and sizing the whole environment for correct short-term and long-term future usage. Never think of how to design and maintain the initial system size; always think of how to design and maintain it after a year or more of data throughput. The whole system must be able to grow not only in size but also in complexity; otherwise, the system will never fit the future needs of business and will soon become obsolete (because of the need for data type variety of previously seen tenets).
Let's make some usage predictions. For instance, let's consider a satellite antitheft-system that is always probing your position in the world. Such systems usually send data to the central data center from one to five times per hour, with a dataset of hundreds or more positions per instance.
A binary position packet is made up of a device ID, a UTC GPS fix, latitude, and longitude. This means 4 x 32-bit data fields for a sum of 16 bytes per position packet multiplied 120 times (2 positions per minute), which results in 1920 bytes per hour. Now, think of it as a car that runs for an average of 5 hours per day plus a lot of parking time, with obvious data-sending optimizations. This produces a size of 600 in-moving packets per day with a size of 9600 bytes per day in the network. Anyone could think it is easy to manage such network usage for any kind of Internet bandwidth. Of course, if you multiply such usage for 1000 cars (or more in the real world), this becomes 600,000 new packets per day in our database, with a constant network usage in the in-moving time of 9.15 MB/s.
Continuing our usage prevision, things start becoming a little harder to manage with a database of 219 million rows (600k x 365 days) per year, which means 3.26 GB (219 m x 16 bytes) of increased size per year (plus indexes). Keep in mind that that this preview is related to a small client market share of only 1000 cars, while in the real world, any car rental company that has thousands of cars must manage a database greater than the one that we have just predicted.
The first thing to keep in mind when designing fast-growing solutions is that the datatype choice is crucial for the life of the whole system. Using 32 bits instead of 16 bits in a single data-packet field means increasing the network usage for nothing. The same thing happens if we increase the database column size. Another drawback of the database design is the increased size of all indexes or keys using the wrong-sized column, with obvious increase in the index seek/scan time. Also, keep in mind that in such large databases, altering the column size later (by years in a production environment) means hours or days of system downtime for maintenance.
Another critical aspect is breaking dependencies from different system modules and tiers. Never directly make a synchronous database INSERT from a Web Service operation. Always decouple by using a persisted queue, such as the one used in Azure Service Bus. This makes it easier to design the whole system and adds the benefit of increasing the system's reliability and scalability.
When trying to use a relational database, the key to success for big data systems is planning multiple instances of splitting data of different functional types, or (if possible) balancing content across multiple available tables of the same logical database across multiple physical servers.
Another important design to implement often in big data solutions is the Reporting Database pattern, as described by Martin Fowler, a british software engineer. Within such suggested designs, there are database instances for data-insert and others, which are asynchronously filled, for data querying. The added feature here is the ability to denormalize or reshape data specifically for querying in the ETL workflow used to move asynchronous data to the query databases. Obviously, the usage of read-only databases also adds the great advantage of easily balancing database usage on multiple servers.
Note
To learn more about the Reporting Database pattern, visit http://martinfowler.com/bliki/ReportingDatabase.html.
It is easy to infer that cloud computing is the easiest way to handle big data solutions. Here, you have space to deploy all the different tiers of your application, persisted-queues to let tiers communicate with each other, huge space for databases, and easy access to the right number of virtual machines to be used in grid computing, if applicable to your needs.
Let's evaluate a practical satellite-based anti-theft system that is always connected, with advanced logistic management sized for 10,000 devices, and that can produce 6 million packets per day or more. We choose to release the solutions across the Microsoft Azure cloud provider. In the overall architecture design, we will consider using idioms and specific technology provider (Azure) oriented features to optimize all the performance aspects we can. Instead, exploiting maximum provider-specific solutions and technology is a primary requirement. Here, the main functional and non-functional requirements are as follows:
- Store a device packet positioned in a history table for three years:
- Develop a low-level binary server to read device packets
- Develop a data delete engine to purge data that is older than 3 years
- Asynchronously analyze and store device routes
- Always be aware of the last position of each device:
- Decouple last-position item storage from history to another table in order to avoid frequent SELECT operations on a huge table
- Notify system managers when a device goes out of the scope for more than 30 minutes on usual routes and more than 15 minutes on new routes
- Always be aware of device entering/exiting from any point of interest (POI)
- Show simplified device data for end users
- Show detailed device data for system managers
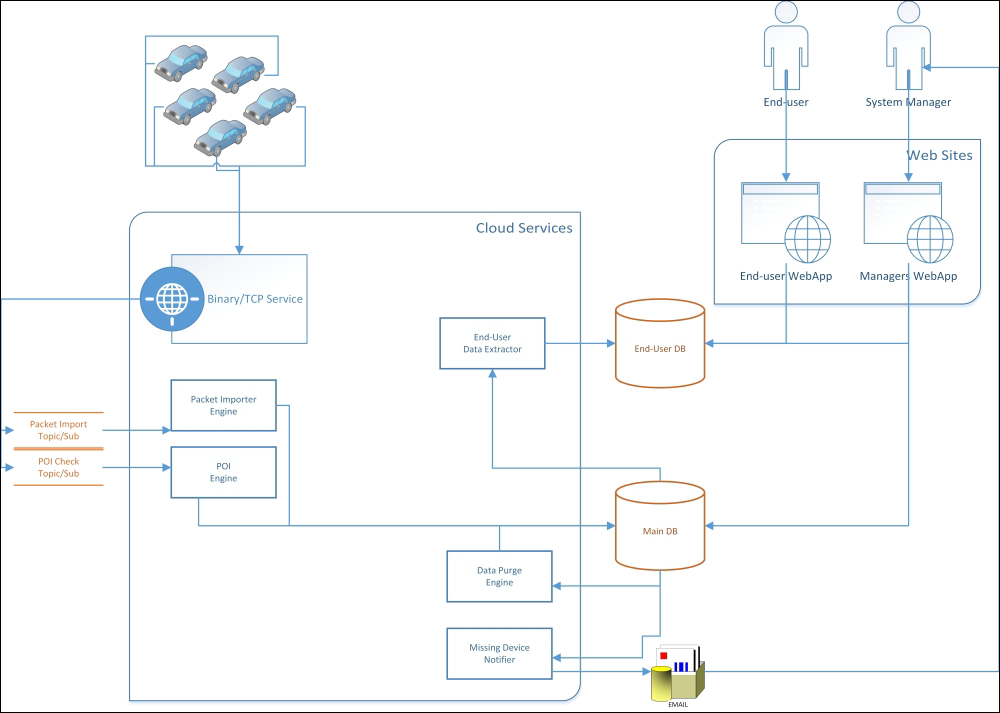
A decoupled big data solution, suited for Windows Azure
The preceding system architecture can handle thousands of incoming messages per second, flowing through the binary service released as Worker Role within the Microsoft Azure Cloud Services. The usage of the Service Bus Topic with two different subscriptions—one for the packet importer engine and one for POI engine—decouple the two different logic that handles different execution times. With this choice, the data-packet will flow into the history database as soon as possible, while the POI logic execution could even be executed a bit later. The primary concern for design here is to catch all messages. Instead, the primary concern regarding performance is the high scalability provided by the eventual scale-out of the VM count of the two engines, and obviously a high overall throughput in receiving device packets.
Tip
An Azure Service Bus Topic is a special FIFO queue with a single entrance and multiple exits. Those exits are called subscriptions because their usage is the same as publish/subscribe scenarios, where multiple receivers expect the same message from a single message queue. The usage is exactly the same as having multiple FIFO message queues with the commodity of sharing some configuration, plus the obvious (and important) benefit of not having to deal with multiple messages sent to the sender side, as a single copy of the message flows into the Topic. It will multiply the message across all subscribers by itself.
Later, the data packet will flow within the business logic lying in the Packet Importer and POI engines. Those will then create proper persistence objects, which will then flow within the main database (or multiple physical ones). This ends the overall workflow of the packet input.
Asynchronously, the Data Purge Engine will evaluate and, if needed, will clean up old data from the main database. Still asynchronously, the Missing Device Notifier will evaluate its logic against the persisted data, and if needed, it will notify system managers if something interesting or wrong is happening. Because this logic may became heavy to compute against a huge dataset, multiple VM instances will eventually be required here.
The End-User Data Extractor will execute the reporting database logic to produce simplified data for the end user by simplifying data structure and reducing data size. This is because the end-user database must contain three years of data by requirement; instead, the main database (or multiple physical instances) could even contain more data. This is our choice according to local laws. This logic may also become CPU-intensive, so here, multiple VM instances could be required.
At the end of the system, two web applications exist for the two main types of users. We could even create a single web application with multiple authorization roles, but this choice would produce trickier business logic with less ability to optimize the two different business and data access logic. Remember that in big data, this optimization is a primary concern. The logic centralization, instead, becomes a secondary concern. By the way, also remember that a lot of logic and modules are still shareable between those two web applications and packaged in libraries with our preferred granularity.
Although web applications will not require high computational power, they will access lot of data frequently, so a well-designed cache strategy is mandatory.
Tip
Microsoft Azure offers different cache providers and solutions. We can use AppFabric cache within our cloud services in specific VMs, or together with Worker/Web Roles VMs to save some money (and performance). The same cache is available in a managed multitenant offer by Azure itself with preconfigured size slots. The same offering is also available with the Redis cache engine. My personal tests showed that the two caches are similar in all primitive-data-based scenarios. Redis became better when using its special features, such as caching data lists or flags; AppFabric, instead, became better while handling huge datasets because of the higher memory size limit due to its balanced design (Redis has only an active/passive failover).