
As mentioned earlier, sharing knowledge and simplifying communication between team members is one of the most common reasons some scientists give names to architectures and designs.
Different kinds of architectures and designs exist, such as a single or multiple layered architectures and creational or behavioral design patterns. This book is not about architectures, so we will only provide an overview of the most used software and system architectures while trying to provide more details on performance concerns.
When talking about performance, many system designs are taken into account.
Most architectures created are layered architectures. A generic layered architecture splits different application modules at different levels (layers) that represent the distance from the application user. The following figure shows a layered architecture:

The preceding diagram shows what a generic web application or desktop application design might look like, according to a layered architecture. Layering is one of the older software architectures for OOP. It comes from a time when the critical requirement was to persist data and keep it safe somewhere. This is why the end user is at the opposite of the layer diagram. This approach adds decoupling because coupling only takes place from the top layer to the bottom layer.
Multiple modules can exist in the same layer, sharing the same stage of distance from the application user, because its parts are of the same behavioral module set (presentation, business, and so on). Otherwise, any cross-layer invocation can actually become a message exchange for decoupling needs. In-layer communication does not need to be decoupled, so any living object may talk to any associated object simply by invoking/using each one the brother instance's methods and properties that it needs.
Instead, when the communication breaks the boundary of the layer, we need to use the data transfer object (DTO) pattern, usually with plain old CLR object (POCO) objects. This kind of plumbing class serves as a container for data transfer, and a messaging scenario may actually use the request-reply pattern, which always expects a couple of DTOs, a request, and a response.
DTO, a design pattern as explained by Martin Fowler in his book Patterns of Enterprise Application Architecture, published by Addison-Wesley, has the objective of grouping data and reducing method calls. However, its main task is to reduce a round trip by frequently calling a remote system. It is also frequently used in design-by-contract programming (also known as contract programming) when dealing with interfaces as suggested by the interface-segregation principle in order to break the dependency and decouple the whole system.
As far as performance is concerned, the drawback of such a super-decoupled system is the need of other objects to convert or map (maybe with a data mapper pattern) different kinds of DTOs for all message purposes. Although the computational power in terms of CPU power needed to copy value-type data from one object to another is negligible, creating millions of object in memory may create an issue regarding memory usage and release. More critical is the huge cost standardization of such solutions may bring by reducing the availability of some specific language idioms, for instance, the ability to use IQueryable<T> idiom manipulations that will produce a single server-side executed query. Other instances are later discussed in this chapter. You will learn database querying later in Chapter 7, Database Querying.
As explained earlier, many decoupling techniques are available with layered architecture. The first is creating several contracts to break the knowledge of concrete implementation between associated layers. These contracts are obviously made with .NET interfaces and later implemented in concrete classes, where needed. As mentioned, never underestimate the cost of object creations/destructions and data copying that is generated by intensive data mapping. Though this will not cause a lot of CPU wastage, it will bring up a number of other issues. Later, in Chapter 3, CLR Internals, in the Garbage collection section, a deeper knowledge of this cost will become evident. However, in addition to this cost, think of all the idiom-based increased powerfulness that an architecture based on DTO exchanging with data mapping will simply avoid having at our availability.
A multilayered architecture may be released on a single tier (we usually say that this will flatten the architecture's physical setup) that usually also means a single server because of the restrictions in database balancing. A layered architecture has some pros, such as easy maintainability of layers and easy division of work in a team based on skills— from the upper layer skills of user experience, to the intermediate layer skills of good analysis, to the lower layer's need for expert database developers—it is easily understandable that scalability is still zero until we use a single tier. Latency depends only on DB latency itself. This means we can only optimize the I/O development module to try to take some advantage during this time. Throughput is also limited from one of the DBMS itself.
Flattening a 2-tier architecture will need a single physical tier.
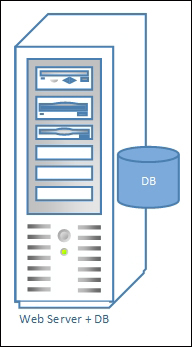
A flattened 2-tier architecture
Although a flattened release of a multilayered architecture is also available for 10-tier architectures, this must be avoided in any production environment. For testing purposes, however, it might be a cheap solution if we are low on space in our virtualization host. However, bear in mind that this choice will alter the similarity between the two environments, for instance powering up any latency time because of the network access time or the avoided network resource authentication time that is not actually required.
Note
An enterprise application is one that usually involves handling of big databases with several concurrent transactions, frequent data schema changes, customized business rules and logic, and huge integration needs with ubiquitous internal business-to-consumer (B2C) or business-to-business (B2B) legacy systems.
Most of the enterprise-dedicated applications of order management or customer relationship are made on this layered architecture. Obviously, the worst performance aspect in this scenario is the zero horizontal scalability. This is because this layered architecture is usually released on a 2-tier system, where many improvements in performance arise.
The following figure shows the classic 2-tier physical setup with multiple web servers (or desktop clients) that are using a single RDBMS as a data repository or a state repository:
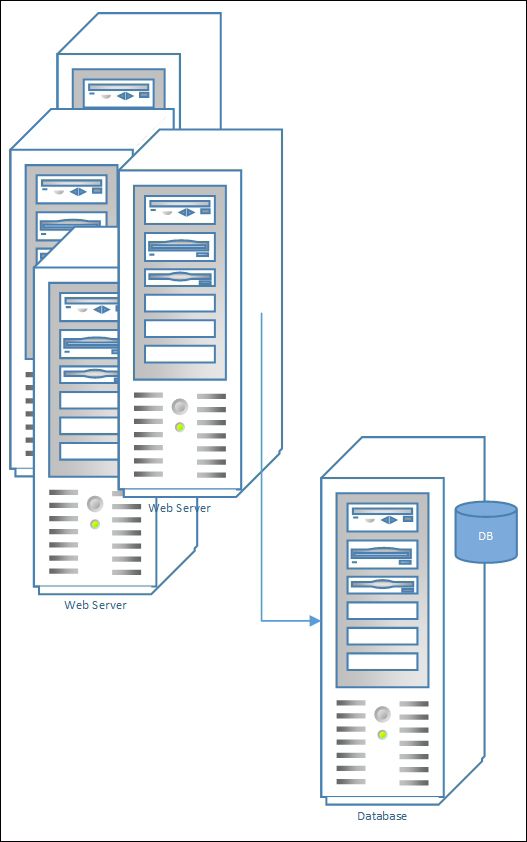
2-tiered architecture
By splitting the physical structure of the layered architecture, multiple groups of systems can be clustered to serve the same web application. This solution drastically changes the performance limitations of the whole architecture, by adding good scalability, although still limited by the unbalanced node (the database). Although this classic physical implementation of 2-tier architecture is the most common in enterprise or Small office Home office (SoHo) worlds, this solution usually bases its usage on the easiness of the solution and not on specific performance or reliability needs.
With this physical architecture, latency suffers the added hop, but throughput and scalability balances this (very) small drawback very well.
Another very big difference that occurs when moving from a single-tier to n-tier (any tier amount) is the creation of a balance between applications/web servers.
The MVC pattern, which is one of the most widely diffused across various programming languages, is based on a classical layered architecture.
The MVC pattern is at the base of the ASP.NET MVC framework, one of the most used framework in any newborn web application powered by the .NET framework since its first release in 2009, Version 1.0. Previous ASP.NET versions, that was renamed to Web Forms, actually became obsolete without any addition from the developer group (if any still exists) and without any coverage in the official Microsoft learning courseware since the release of Visual Studio 2012. This made ASP.NET MVC the main web-programming framework for Visual Studio.
The MVC pattern is the first layered design pattern for user-interface based applications, made of three layers. Later, Model-View-Presenter (MVP) and MVVM joined the group, adding different or specific features from their creators.
The MVC pattern was born in 1988 and was first announced in the pages of The Journal of Object Technology. It divides the presentation layer into three main modules or sub-layers: the View is the module concerning the graphical user experience. The Controller is the module concerning the iteration flow from/to the application and the user; and the Model represents the entities needed to fulfill single/multiple Views. The following figure shows an MVC-based web application:
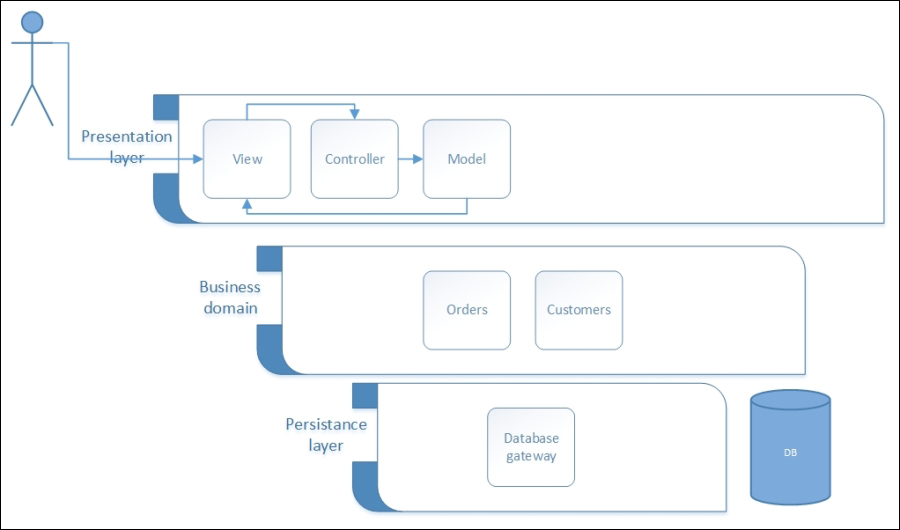
An MVC-based web application with all its layers in which the distinction between the business Model (from domain) and the user-experience oriented model (from MVC) is easily visible
Using the MVC design pattern in web application development needs more programming work, together with increased testability (because of the more decoupled architecture) in comparison to any Rapid Application Development (RAD) approach.
The concrete implementation of the two frameworks ASP.NET MVC and ASP.NET Web Forms behaves very differently in terms of performance.

A performance comparative between ASP.NET MVC and Web Forms
Regarding latency, the winner is the MVC-based framework. Web Forms have a verbose page life cycle that increases the page elaboration time with an empty form.
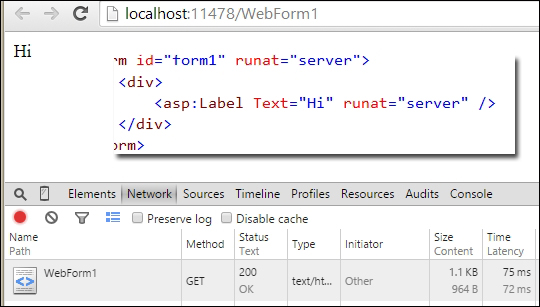
Rendering time of a Web Forms text label in 75 milliseconds
Without diving into the detail of the Web Forms page life cycle, it is enough to say that it must follow more than the simple steps that the MVC framework does. In ASP.NET MVC, any request simply routes from the MvcHandler class that creates a ControllerFactory class, this creates our controller, which invokes our action method by passing a model that was created by a ModelBinding and populated with any input data from the GET or POST request. Then, the controller does its job by executing the logic within the action and producing a new model to bind to the view.
In Web Forms, instead, there are more than 10 events for any page and the same for any child (nested) control. This means that the bigger a page is, the higher the number of wasted objects being created/destroyed and invoked events will be, thus increasing the latency time of rendering the whole page.
The same preceding page rendered as View in MVC in 6 milliseconds
ASP.NET MVC renders an empty view in not more than 7 milliseconds on my laptop (but in the first application load, the compilation time adds to the rendering time), while Web Forms render the same empty form in not less than 70 milliseconds. Although such absolute values are useless, relative values are the proof of the very different minimum latency times of the two frameworks. Regarding latency, on my laptop ASP.NET MVC is almost 10 times better than Web Forms!
Talking about scalability, MVC bases its architecture on a strong object-oriented design pattern that will guide the programmer to the most modularized application design, instead of the RAD guided approach of Web Forms.
I am not saying Web Forms cannot be used in a good MVP pattern or other layered (non-RAD) architectures, but this is actually not the average scenario. Thus, MVC-based web applications are supposed to become more scalable than Web Forms applications.
Analyzing scalability results in two solutions; this is a big difference that distinguishes MVC from Web Forms. The design of MVC is completely stateless, while a legacy Web Forms application will frequently make use of the session state, the ability to contain some navigational user data that lives in the memory of the web server(s).
Session state is a big bottleneck in scalability because it usually relies on the SQL Server as a persistence provider to contain and share session data between multiple servers that are involved in the same web application.
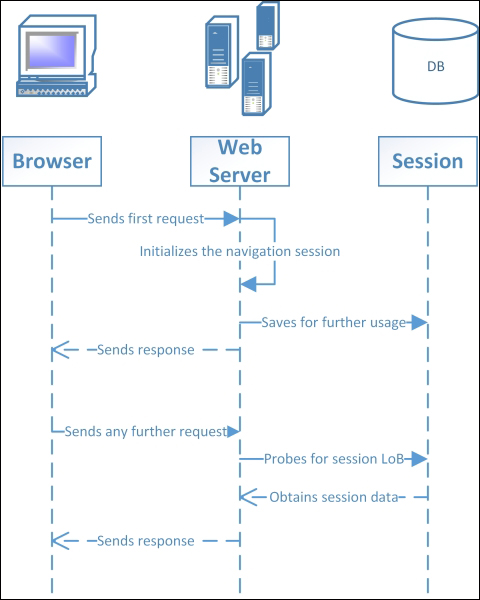
A sequence UML diagram of ASP.NET legacy SQL-based SessionState
Of course, some alternatives to using SQL Server persistence for session state do exist, such as the state server, an in-memory container with the limitation of the RAM available for the server. Another alternative that is greatly scalable from the state server is using a cloud-distributed cache provider, which is also available for local installations, that named AppFabric Cache. Using this kind of session provider will boost scalability, but obviously the choice of never using a session grants another level of scalability. It is like what was mentioned in the previous chapter about Amdahl's law. Although a powerful cache provider can give good results in session state persistence, it will also limit this capability, which will, in turn, limit the scalability of the whole architecture. Instead, without using the session state, this limit is virtually nothing when talking about state persistence because other factors limiting scalability could still exist.
A drawback exists in the sessionless approach of MVC. This is the throughput limitation and resource usage amplification due to the need of any request processed by the server to reload (what is usually in the session state) any related data from the persistence storage again. This is a subtle difference between the two designs, but it can make a significant difference in how they perform.
Talking about resource usage, I have to say that although MVC has a smaller footprint in comparison to the page's life cycle of a Web Forms application, the whole architecture needs more decoupling, and as mentioned previously, more decoupling means more abstraction and more mapping/conversion between objects. Another point against all such abstraction is the loss of idiom-based programming, such as the Entity Framework materialization or query building, because these are wasted by the DTO pattern being used by layered communication. When using an idiom-based approach, we can take advantage of technologies such as any dynamic expression tree construction that is available with LINQ (explained in the Querying approaches section in Chapter 7, Database querying). Instead, if we always have to populate a complete DTO, we create multiple DTOs, each for any different request operation, or we always create the DTO with all available data for any given entity. If we create multiple DTOs, we must face issues such as more coding and more requests needed for any case that a single DTO response gives the caller some useful information, but still misses something. If we create the DTO with all available data for the entity, we often waste CPU time and system resources by asking for lot of information, although a caller asks only for one particular piece of information. Obviously, using DTO is not a bad idea. However, simply put, it makes harder to create the right balance between DTO shape and number, which is not an easy task.
Here, a mixed design is desirable but would be hard to implement while respecting all principles of MVC pattern, layered architecture, SOLID, and OOP altogether.
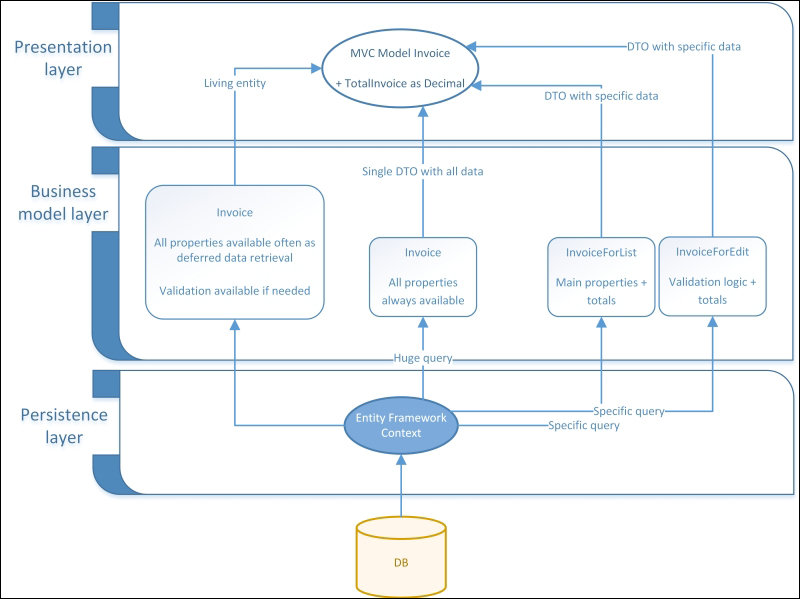
A comparative between an idiom-based approach (left) and a DTO-based approach (right)
As shown in the preceding diagram, a DTO-based approach can waste a lot of computational power, often without any need. Let's take the instance of an invoice materialization with no requirement to summarize the total amount or any other computation logic, such as client aggregations or product statistics and so on. To reduce this kind of limitation to DTOs, a solution could be to create different levels of DTOs of each entity with different details, or use the same type of DTO but with multiple de-persistence methods with the objective of materializing objects with probable empty properties. Another solution may be to use methods to work in an always-lazy calculation mode, sacrificing any massive reading of data.
The most balanced solution between data materialization cost and round-trip reduction is creating two or three business entities (or a single one with multiple DTOs). This solution avoids the extreme cost of using always the single fat DTO. It also avoids using the idiom-based entity, giving an increased ability to customize object materialization outside of the proper layer. This instance is also applicable outside of a persistence/de-persistence scenario.
A common solution to DTO materialization or data mapping is the wide use of caching techniques that can prevent requests from frequently penetrating the layers from the top-most layer to the deep persistence layer. This choice can help latency as well as throughput, but it makes the entire solution harder to maintain because of the difficulty of sharing a common cache object lifetime.
Talking about throughput, the MVC is the best solution because of the very small footprint of its page materialization life cycle, which produces a very low overhead during view rendering. This low overhead, if multiplied by the thousands of views rendered each day compared to the same job done by the classical Web Forms ISAPI, will give us an idea of more such resources that are used in effective throughput in MVC applications.
When analyzing the availability scenario, in a long-range analysis, MVC is the absolute winner. However, in a short-range analysis, Web Forms can produce a good solution, with very little effort from the developer team. This is because of the RAD approach. Once upon a time, old books about Web Forms often said that RAD helps in saving time that will later become available to developers, with the suggestion to use such time for better business analysis.
Another thing to bear in mind about availability regarding ASP.NET MVC applications is that the increased number of layers needs better skilled and experienced developers. Although each layer will become easy to develop by addressing a single (or few) functional needs per instance, integrating all such modules in a well-architected application needs some experience.
Finally, regarding efficiency, MVC is again the winner compared to Web Forms because of the higher throughput it achieves with the same computational power.
Note
Model View Presenter (MVP) is not all that different from MVC. In MVP, the Presenter acts as a controller in the middle, between the View and the Model.
In MVC, requests from the View are sent to the Controller, which is in charge of understanding the request, parsing input data, routing such requests to the right action, and producing the right Model object to bind to the View.
On the other hand, the Presenter is more like an object-oriented code behind logic with the goal of updating the View with the Model data and reading back user actions/data.
The MVVM pattern is another descendant of the MVC pattern. Born from an extensive update to the MVP pattern, it is at the base of all eXtensible Application Markup Language (XAML) language-based frameworks, such as Windows presentation foundation (WPF), Silverlight, Windows Phone applications, and Store Apps (formerly known as Metro-style apps).
MVVM is different from MVC, which is used by Microsoft in its main web development framework in that it is used for desktop or device class applications.
The first and (still) the most powerful application framework using MVVM in Microsoft is WPF, a desktop class framework that can use the full .NET 4.5.3 environment. Future versions within Visual Studio 2015 will support built-in .NET 4.6. On the other hand, all other frameworks by Microsoft that use the XAML language supporting MVVM patterns are based on a smaller edition of .NET. This happens with Silverlight, Windows Store Apps, Universal Apps, or Windows Phone Apps. This is why Microsoft made the Portable Library project within Visual Studio, which allows us to create shared code bases compatible with all frameworks.
While a Controller in MVC pattern is sort of a router for requests to catch any request and parsing input/output Models, the MVVM lies behind any View with a full two-way data binding that is always linked to a View's controls and together at Model's properties. Actually, multiple ViewModels may run the same View and many Views can use the same single/multiple instance of a given ViewModel.
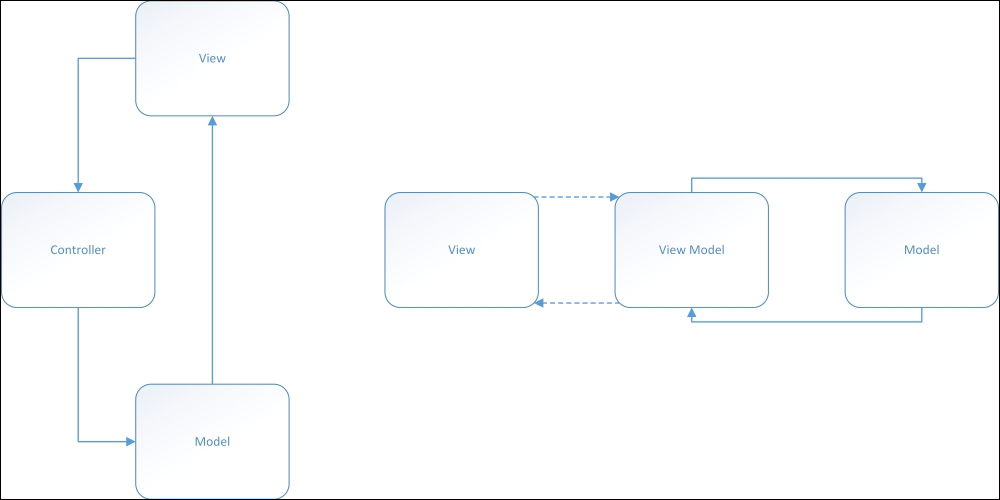
A simple MVC/MVVM design comparative
We could assert that the experience offered by MVVM is like a film, while the experience offered by MVC is like photography, because while a Controller always makes one-shot elaborations regarding the application user requests in MVC, in MVVM, the ViewModel is definitely the view!
Not only does a ViewModel lie behind a View, but we could also say that if a VM is a body, then a View is its dress. While the concrete View is the graphical representation, the ViewModel is the virtual view, the un-concrete view, but still the View.
In MVC, the View contains the user state (the value of all items showed in the UI) until a GET/POST invocation is sent to the web server. Once sent, in the MVC framework, the View simply binds one-way reading data from a Model. In MVVM, behaviors, interaction logic, and user state actually live within the ViewModel. Moreover, it is again in the ViewModel that any access to the underlying Model, domain, and any persistence provider actually flows.
Between a ViewModel and View, a data connection called data binding is established. This is a declarative association between a source and target property, such as Person.Name with TextBox.Text. Although it is possible to configure data binding by imperative coding (while declarative means decorating or setting the property association in XAML), in frameworks such as WPF and other XAML-based frameworks, this is usually avoided because of the more decoupled result made by the declarative choice.
The most powerful technology feature provided by any XAML-based language is actually the data binding, other than the simpler one that was available in Windows Forms. XAML allows one-way binding (also reverted to the source) and two-way binding. Such data binding supports any source or target as a property from a Model or ViewModel or any other control's dependency property.
This binding subsystem is so powerful in XAML-based languages that events are handled in specific objects named Command, and this can be data-bound to specific controls, such as buttons. In the .NET framework, an event is an implementation of the Observer pattern that lies within a delegate object, allowing a 1-N association between the only source of the event (the owner of the event) and more observers that can handle the event with some specific code. The only object that can raise the event is the owner itself. In XAML-based languages, a Command is an object that targets a specific event (in the meaning of something that can happen) that can be bound to different controls/classes, and all of those can register handlers or raise the signaling of all handlers.
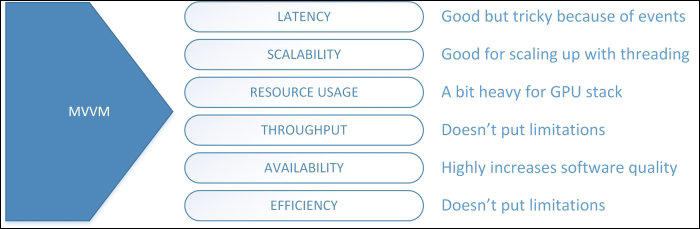
An MVVM performance map analysis
Regarding performance, MVVM behaves very well in several scenarios in terms of data retrieval (latency-driven) and data entry (throughput- and scalability-driven). The ability to have an impressive abstraction of the view in the VM without having to rely on the pipelines of MVC (the actions) makes the programming very pleasurable and give the developer the choice to use different designs and optimization techniques. Data binding itself is done by implementing specific .NET interfaces that can be easily centralized.
Talking about latency, it is slightly different from previous examples based on web request-response time, unavailable in MVVM. Theoretically speaking, in the design pattern of MVVM, there is no latency at all.
In a concrete implementation within XAML-based languages, latency can refer to two different kinds of timings. During data binding, latency is the time between when a VM makes new data available and a View actually renders it. Instead, during a command execution, latency is the time between when a command is invoked and all relative handlers complete their execution. We usually use the first definition until differently specified.
Although the nominal latency is near zero (some milliseconds because of the dictionary-based configuration of data binding), specific implementation concerns about latency actually exist. In any Model or ViewModel, an updated data notification is made by triggering the View with the INotifyPropertyChanged interface.
The .NET interface causes the View to read the underlying data again. Because all notifications are made by a single .NET event, this can easily become a bottleneck because of the serialized approach used by any delegate or event handlers in the .NET world.
On the contrary, when dealing with data that flows from the View to the Model, such an inverse binding is usually configured declaratively within the {Binding …} keyword, which supports specifying binding directions and trigger timing (to choose from the control's lost focus CLR event or anytime the property value changes).
The XAML data binding does not add any measurable time during its execution. Although this, as said, such binding may link multiple properties or the control's dependency properties together. Linking this interaction logic could increase latency time heavily, adding some annoying delay at the View level. One fact upon all, is the added latency by any validation logic. It is even worse if such validation is other than formal, such as validating some ID or CODE against a database value.
Talking about scalability, MVVM patterns does some work here, while we can make some concrete analysis concerning the XAML implementation. It is easy to say that scaling out is impossible because MVVM is a desktop class layered architecture that cannot scale. Instead, we can say that in a multiuser scenario with multiple client systems connected in a 2-tier or 3-tier system architecture, simple MVVM and XAML-based frameworks will never act as bottlenecks. The ability to use the full .NET stack in WPF gives us the chance to use all synchronization techniques available, in order to use a directly connected DBMS or middleware tier (which will be explained later in this chapter).
Instead of scaling up by moving the application to an increased CPU clock system, the XAML-based application would benefit more from an increased CPU core count system. Obviously, to profit from many CPU cores, mastering parallel techniques is mandatory. Chapter 4, Asynchronous Programming and Chapter 5, Programming for Parallelism will cover such thematic.
About the resource usage, MVVM-powered architectures require only a simple POCO class as a Model and ViewModel. The only additional requirement is the implementation of the INotifyPropertyChanged interface that costs next to nothing. Talking about the pattern, unlike MVC, which has a specific elaboration workflow, MVVM does not offer this functionality. Multiple commands with multiple logic can process their respective logic (together with asynchronous invocation) with the local VM data or by going down to the persistence layer to grab missing information. We have all the choices here.
Although MVVM does not cost anything in terms of graphical rendering, XAML-based frameworks make massive use of hardware-accelerated user controls. Talking about an extreme choice, Windows Forms with Graphics Device Interface (GDI)-based rendering require a lot less resources and can give a higher frame rate on highly updatable data. Thus, if a very high FPS is needed, the choice of still rendering a WPF area in GDI is available. For other XAML languages, the choice is not so easy to obtain. Obviously, this does not mean that XAML is slow in rendering with its DirectX based engine. Simply consider that WPF animations need a good Graphics Processing Unit (GPU), while a basic GDI animation will execute on any system, although it is obsolete.
Talking about availability, MVVM-based architectures usually lead programmers to good programming. As MVC allows it, MVVM designs can be tested because of the great modularity. While a Controller uses a pipelined workflow to process any requests, a ViewModel is more flexible and can be tested with multiple initialization conditions. This makes it more powerful but also less predictable than a Controller, and hence is tricky to use. In terms of design, the Controller acts as a transaction script, while the ViewModel acts in a more realistic, object-oriented approach.
Finally, yet importantly, throughput and efficiency are simply unaffected by MVVM-based architectures. However, because of the flexibility the solution gives to the developer, any interaction and business logic design may be used inside a ViewModel and their underlying Models. Therefore, any success or failure regarding those performance aspects are usually related to programmer work. In XAML frameworks, throughput is achieved by an intensive use of asynchronous and parallel programming assisted by a built-in thread synchronization subsystem, based on the Dispatcher class that deals with UI updates.
The 3-tier architecture is a layered architecture that is deployed across a physical multi-layered setup. This choice grants extreme layer reusability because each tier (logical representation of a physical layer able to multiple software layers) can participate in multiple applications, if properly developed.
The n-tier architecture is a generic multitier system architecture based on intensive multilayering. 3-tier is the smaller one, which is able to divide the three main tiers (presentation, business, persistence). It is possible to find solutions made of four tiers or six tiers. The architecture itself is the same as 3-tier. The only difference is the number of tiers containing business logic.
In its physical view, it is easily visible that the third tier is that of Web Services. This tier is responsible for containing any business logic by obtaining reusability and higher scalability rates.
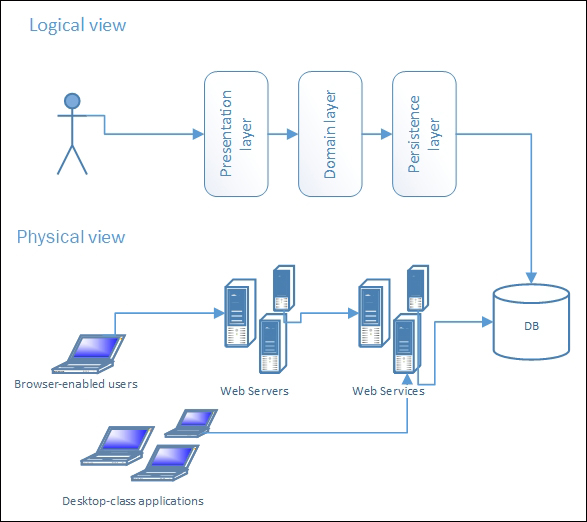
The 3-tier system architecture
Within n-tier architecture, layers are matched on a functional basis. They must share the intent, vision, or objective to be paired in the same tier. An example is the MVC layers paired in the presentation tier, all executing in the same web application running on the same web-server tier.
The second tier, as in 2-tier architecture, is the one containing all persistence layers.
The last tier, the one in the middle in the preceding diagram, is the one containing presentation-unaware business logic (logics regarding the presentation are usually interactive logics). Here, software modules such as a web service, a business rule engine, or a state machine workflow, are present to handle whatever the business requirements are. All such logics will run in the application-server tier.
The difference between layered structure and tiered structure is that the latter is a layered architecture with a specific physical layout (system architecture).
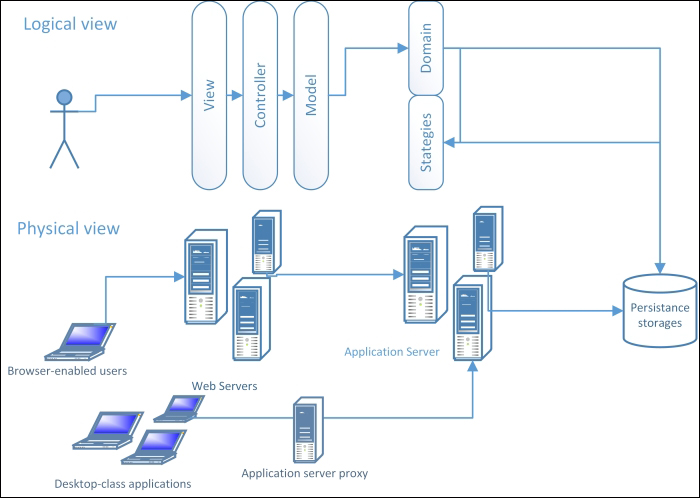
Another 3-tier system architecture containing an external system for business-rule processing (strategies)
In terms of performance, n-tier architecture gives its best in scalability because each tier, if appropriately designed, could scale individually. Bear always in mind that performance aspects such as network availability, throughput, and latency are a primary concern of 3-tier architecture.
Sometimes, a better result is achieved by isolating the tiers from the main network, apart from the tier that will need this explicit connection, by using a sub-network of grouped systems in a closed network. Because in 3-tier architecture network performances directly affect overall performance, it is a good choice to avoid using the network used to make tiers communicate with each other for other needs of the whole company. This solution reduces the usage of network resources by the addition of corporate network needs, as well as private network ones.
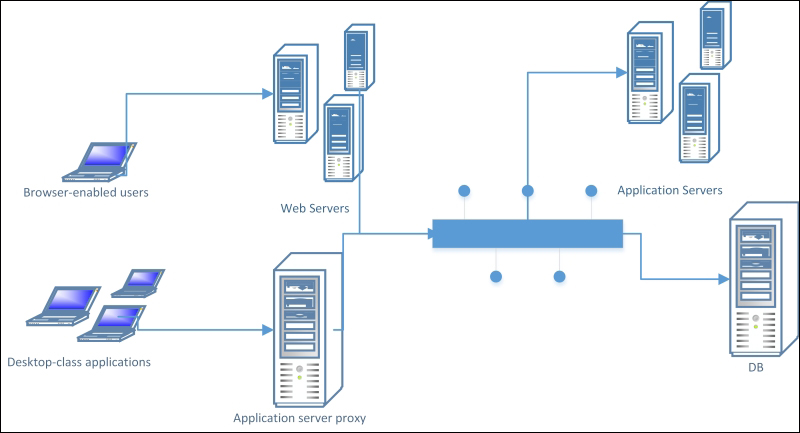
Regarding latency, the multiple round trips happening on the network at each tier cross will add visible delays if no cache systems are used (we will cover caching later in the Caching, when and where section of this chapter). Although this issue may be annoying, the great improvements made to other performance indicators usually balance this limitation.
Scalability, as mentioned, will improve greatly using 3-tier architecture, thanks to the ability to balance physical resource usage across multiple systems.
Although a bottleneck that is able to reduce scalability, is the persistence storage provider, usually a DBMS. Balancing the computational power of all systems participating in the architecture is easy to do. Instead, SQL-based persistence providers are usually difficult to balance. Regarding scalability, NoSQL databases are a winning choice compared to classic SQL-based databases.
Resource usage affects the size of the solution. This is why we should not use such architecture to drive simple or small applications. In other words, in small releases, n-tier architecture needs many virtual/physical systems, along with a lot of serialization and creation of DTOs during communication between modules of different tiers. If our target is a small software application, maybe the best architecture would be a 2-tier MVC based web application. Talking again about 3-tier architecture, although it enables us to release the whole solution in a single physical system with multiple virtual machines (or even a single virtual machine), the solution must be designed as a network-based architecture, otherwise eventually scaling out to multiple virtual machines will be impossible. Again, another heavy usage of resources is made by caching providers, which is massively used in 3-tier architecture because of the evident benefit in terms of response time and throughput.
Throughput is another key benefit of such architecture because of the great division made by software modules and layers in all tiers of the whole design. The only limitation is an internal network failure or congestion. It is not just about network bandwidth but also about network backbone availability (within switches), routing/firewall speed (of network appliances), and broadcast/multicast traffic that can saturate all network resources and their availability easily.
The architecture achieves high availability, thanks to the high scalability rate. Multiple nodes of any tier can be released and may work together to balance traffic and obtain a strong failover. The weak tier here is the persistence one that relies on internal persistence-provider solutions in order to achieve availability.
Efficiency is a secondary aspect of n-tier solutions and is a powerful architecture that should address a heavy task such as e-commerce, or a complex human workflow-based solution, such as escalation-based customer care for client services, and so on. High consumption of resources in terms of memory, processor, and network traffic are needed to let n-tier architecture run in the proper way. Therefore, if efficiency is your primary goal when searching for an architecture suited for your new application, simply use another onelike a 2-tier MVC application or any other 2-tiered architecture that has improved efficiency and latency compared to 3-tiererd architecture.
One limitation of n-tier architecture is that the whole system is still a single monolithic application. It is also modularized, layered, divided in tiers to achieve hardware-linked resource configuration per tier, and so on, but the whole system is a single software, a single (although big) application. That is why some genius thought of the Service Oriented Architecture (SOA).
The service orientation happens when we stop thinking of it as a completely monolithic application, and begin thinking of it as an information system made by the combined usage of multiple small applications.
These small applications that name services are containers of logics with the same functional scope. Although a service does not contain any data by itself, any service has its own persistence storage (or multiple)—a persistence storage is never available to multiple services. The data availability must cross within a service and not behind it.
Services do not have any graphical representation; they are used by other services or end-user applications (with a UI) that need access to service data and logic. In SOA vocabulary, these external applications are used to invoke requests and retrieve response messages from services. Those serialized DTOs that move across the network names are Messages.
An important thing to bear in mind is that when talking about SOA, there are no multiple layers released across multiple tiers. In SOA, we definitely have multiple small applications that together compose a huge information system. This does not mean that a single service cannot be developed with a layered architecture by itself. In fact, this is usually what actually happens.
In SOA, there are also special services with the task of grouping data by other smaller services (service facade) or special services to maintain, or for service discoverability, such as a corporate Enterprise Service Bus (ESB).
The following diagram provides a simplified representation of an SOA design with a direct service access, a routed service access by an ESB, and a service aggregator access through a service facade:
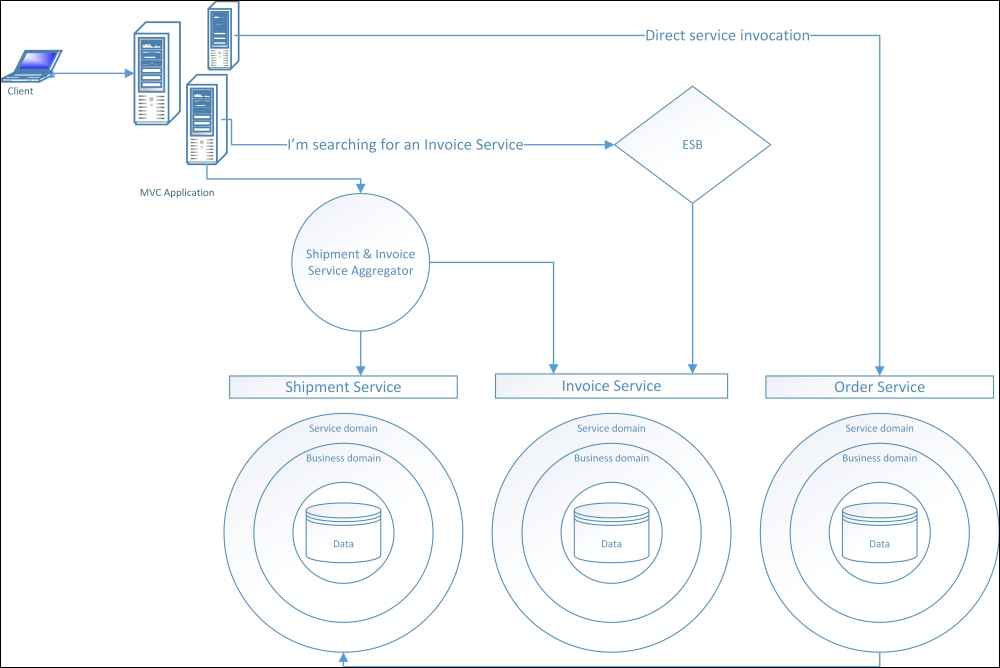
An SOA environment
The most visible unlike SOA and n-tier is that although SOA uses a layered approach, this is confined within the boundaries of any service that acts as a container of the whole logic in terms of the functional behavior of such services.
Another great difference is that different from any other architecture, here, each service has its own data. Any other service needing the same data can only access it by invoking the other service. Thus, this approach increases some latency time, and by utilizing some network resources, it will greatly increase the availability of the whole solution because such integration between logic is done at the service level and not at the raw data level.
Principles of SOA are similar to SOLIDs. A brief description of the most widely accepted standard, as defined by Thomas Erl in his book SOA Principles of Service Design, published by Prentice Hall, is provided in the next section.
Services within the same service inventory are in compliance with the same contract design standard. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
Defining a contract, as is done for the interface segregation principle of SOLID, helps in sharing the knowledge of how to use the service, what the service expects on request, and what the service will give as a response, with the difference of adding a network-related standard (as simple object access protocol or SOAP—an XML-based protocol—on HTTP).
This principle is the basis on which all the others principles lie because without a standardized communication and meta-communication (the ability to exchange descriptive information about service design), no autonomous network calls can be placed.
Service contracts impose low consumer coupling requirements and are themselves decoupled from their surrounding environment. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
Loose coupling is the goal of any OOP-based principle. For SOA, it is exactly the same. This principle states that between the service consumer (a client or another service) and the service, a neutral contract with neutral DTO classes must exist. This choice will break any form of coupling between the client and the service and between the service inner logic and outer DTOs. Never expose a real Domain object because it is too powerful and too coupled to internal needs.
This principle helps maintain a neutral layer of objects, that is, the DTOs (already seen in SOLID), which will also help grant a decoupled contract again, in time. When multiple versions of the same service become available in time, new DTOs will be available to fulfill updated service contracts without a direct connection with internal business objects.
Service contracts only contain essential information and information about services is limited to what is published in service contract. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
The decoupling principle states that a service must actually be a kind of a black box in the consumer's eyes. The less a consumer knows about the service being used, the more such a service becomes abstract and changeable with other versions or implementations. In SOA, the radical change of the whole service with all that is behind it is actually possible with almost no changes at the consumer level. This is one of the strongest benefits of using SOA.
Services contain and express agnostic logic and can be positioned as reusable enterprise resources. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
A service is like a network printer or a network storage server. It is definitely a resource. It does not belong to any single application; it is an application itself. It is like any physical resource, always available to any one (human or machine) that needs it within the company network and sometimes, with appropriate security outside the company, in scenarios such as B2B and B2C (usually through a service proxy).
The service reusability principle also slightly states that the ownership of the logic and data behind a service must not be bypassed by anyone.
Services exercise a high level of control over their underlying runtime execution environment. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
This principle definitely enforces the service's single ownership against its core logic and data by dictating that the more a service is isolated by other systems (for instance, it does not call any other service), the more it becomes autonomous. The more a service is autonomous, the more it can be composed of other services to fulfill higher level logic needs or simply to group complex logic behind a single (and easy to invoke) call in what is exposed as a service facade or a service proxy, usually exposed in B2B and B2C solutions.
Services minimize resource consumption by deferring the management of state information when necessary. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
In SOA, the communication state, such as the session state of classic ASP.NET, is useful to reduce network traffic and round trips, providing the ability to reach a more complex interaction level without the need to include anything in a request (for example, as we did in non-SOA compliant services such as RESTfuls).
This principle also states that state information duplication should never happen when a multiple cross-service level access takes place.
For instance, if we are invoking a service that needs accessing three other services that will all need accessing their persistence storage or other helper services, such as an audit service and some other one, with SOA we have the ability to make the request only to the first service while waiting for the whole response. Meanwhile, behind the scenes, the first service will start a session state of the whole operation. All services participating in the same session will be able to access all such data without a direct data exchange between services. Usually, a distributed caching service or session state is the container of all such shared user data.
During a service operation execution, each service should contain only its own state information, relying on the whole session state for any cross-service request.
Services are supplemented with communicative meta-data by which they can be effectively discovered and interpreted. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
A service is a company resource, such as an employee, a printer, or anything else available to the company to reach its goals. So just like an employee has his internal email address or phone number available to every colleague within the company, a service must be found by any application that could ever need it. The principle states that a company service registry, such as an address book of services, must exist. Such a registry (ESB) must contain any available information about the service, such as name, physical address, available contracts, and related versions, and must be available to anyone in the company. Modern ESBs also add functions of DTO conversion in order to achieve version compatibility or to improve compatibility against external standards that are not directly implemented within our services. Other common features include request routing (with priority support), message audit, message business intelligence, and response caching. Within Microsoft's offering, an ESB is available as an optional feature for the BizTalk Server, under the name of BizTalk ESB Toolkit.
Discoverability is a strong principle to boost service orientation because it helps to see the service as a resource and not as a software module or application piece.
Services are effective composition participants, regardless of the size and complexity of the composition. | ||
| --Thomas Erl, SOA Principles of Service Design | ||
This principle states that a service must be able to act as an effective composition member of services. This is because an agnostic service can be used to solve different problems, and because a service composition brings the separation of concerns to another level, giving the composition the ability to resolve very difficult problems with the participation of the whole system with a little additional work.
This principle may be the soul of the whole principle list. It explains the goal of the entire paradigm. Although services live as autonomous applications, they exist to integrate other services. Indeed, regarding SOA, an information system is definitely a composition of services.
Regarding performance, it is clear that SOA consumes more resources than the n-tier architecture does. The most widely used standard to drive SOA services is the Simple Object Access Protocol (SOAP). SOAP is based on XML messages that rely on HTTP/POST messaging. This makes all such services definite web services. SOAP supports all the SOA needs, but with a high cost in terms of message size and protocol complexity.
With .NET 3.0, Microsoft introduced
Windows Communication Foundation (WCF), which adds support to multiple service communication standards such as SOAP, REST, and the newly NetTcpBinding class that extends the old .NET Remoting API (a remote-proxy based protocol for distributed programming on TCP—an updated version of Common Object
Request Broker Architecture (CORBA)) making it able to fulfill all SOA needs. With the ability to support multiple service endpoints (with different protocols), WCF opens the way to a new era of low-footprint SOA services. Switching from SOAP to the NetTcpBinding largely reduces network traffic and latency time without any drawbacks, in terms of SOA principles. Unfortunately, this standard is not entirely compatible with no-.NET applications. Obviously, with an ESB converting the messages, such issues disappear.
Developing a performing SOA-driven application needs skilled developers and extensive optimization at multiple levels. Most communication across a network occurs whenever a message flows between services. Moreover, a lot of message validation and business rules are executed at service boundary level, before a service accepts any request and before a client (an application or the service itself) accepts any response from another node. Kindly consider that because of the whole design of the architecture, low latency is never available because of the high number of logical and physical steps any message must pass through to reach the target destination, both as a request and as a response.
High scalability, rather than latency, is definitely a killer feature of SOA. Such an autonomous design for any service produces the maximum scalability level for any service node. The whole architecture itself is made to fulfill thousands of requests from/to any node in the whole design. The eventual bottleneck here is the network itself. Only an extremely well performing network may drive a huge SOA information system. Another key aspect of such a scalability level is persistence decoupling. Although this may create some data duplication, such as the same IDs doubled in each single persistence system, if applicable, it also enables real scaling of such persistence systems. Because of not being bonded to a single (huge and centric) DBMS any more but to multiple different instances made with heterogeneous technologies, addressing the best persistence system depending the kind of data, should be persisted.
Resource usage, as explained, is the Achilles heel of SOA. A saying about SOA is that if you cannot drive SOA because it is missing its hardware resources, SOA is not the right architecture for your company! An SOA system is always a huge system, as the mainframe was a huge system for banking needs 40 years ago (and still is). Maybe SOA is the most complex and powerful architecture for enabling distributed systems to fulfill hundreds or thousands of requests per second of a different kind and complexity level, but such system complexity has some basic requirements, such as high systems resources.
Throughput is another killer feature of SOA because of the quasi-unlimited scalability of the whole system and the extreme modularization that helps in optimizing the code at the core of a service for its only needs. This kind of design also helps maintain the availability of any service because of the great autonomy of each node against other nodes. In addition, testing is easy to drive here because of the great decoupling between nodes that exchanges messages to be substituted with mock (fake data for testing purposes) messages.
Another key feature of SOA is the governance of the whole solution. It is easy to analyze traffic on a per message basis, per functional area basis, per service basis with information regarding consumer metadata, message version, service contract version, and so on.
All such analysis data may be grouped to get an exhaustive overview of the whole system and business without having to fit that logic within a business service, because its agnostic design never should. Information such as the average total amount of an invoice or product price doesn't need to flow from the invoice service to a business analysis workflow; the corporate ESB could simply route this message to the two nodes together. With this, each one could know about the existence of the other.
With Efficiency, the resource consumption of the design is usually a great indicator of the ability of the system to process a huge amount of messages. Keep in mind, as said about resource usage, that SOA has some technical requisites that avoids using easy or small systems. SOA definitely suits complex, huge, or high transaction-rate information systems well.