
Within the .NET world, parallel programming is the art of executing the same job on a collection of data or functions by splitting the desired elaboration over all available computational resources.
This chapter will focus on .NET Task Parallel Library's (TPL) implementation of parallel computing, together with the Parallel Language Integrated Query (PLINQ) language.
This chapter will cover the following topics:
- Parallel programming
- Task parallelism with TPL
- Data parallelism with TPL
- Integrated querying with LINQ
- Data parallelism with PLINQ
The goal of any parallel programming is to reduce the whole latency time of the operation by using all the available local resources, in terms of CPU computational power.
Two definitions of parallelism actually exist. Task parallelism happens when we execute multiple jobs all together, such as saving data against multiple database servers.
Data parallelism, instead, happens when we split a huge dataset elaboration across all available CPUs, like when we have to execute some CPU demanding method against a huge amount of objects in the memory, like hashing data.
In the .NET framework, we have the ability to use both parallel kinds. Despite that, the most widely used kind of parallelism within the .NET framework's programming is data parallelism, thanks to PLINQ being so easy to use.
The following table shows the comparison between Task parallelism and Data parallelism:
|
Task parallelism |
Data parallelism | |
|---|---|---|
|
What does it parallelize? | ||
|
Performance boost |
Reduces overall execution time by executing multiple functions per time period |
Reduces overall execution time by splitting the same algorithm's execution across all the available CPUs |
|
Starting constraint |
The same initial data state |
The same data set |
|
Ending constraint |
Can end up all together in a synchronous or asynchronous way |
Must end up all together in a synchronous way |
|
Messaging |
If required, any task can message others or can await others with signaling locks, as seen in the Multithreading Synchronization section in Chapter 3, CLR Internals |
Usually nonexistent |
There is a tight coupling between multithreading (MT) programming and parallel programming. MT is actually a feature of programming languages that helps us by using low-level operating systems threads that give us the ability to run multiple code all at the same time.
Parallel programming, instead, is a high-level feature of programming languages, which will handle multiple operating-system threads autonomously, giving us the ability to split some jobs at a given time and later catch the result in a single point.
Multithreaded programming is a technique in which we work with multiple threads by ourselves. It is a hard-coded technique whereby we split the different logic of our applications across different threads. Opening two TCP ports to make a two-threaded network router is multithreading. Executing a DB read and data fix on a thread and a DB write on another thread is still multithreading. We are actually writing an application that hardly uses multiple threads.
In parallelism, instead, there is a sort of orchestrator, a chief of the whole parallel processing (usually the starting function or routine). The unified starting point, makes all parallel thread handlers share the same additional starting data. This additional data is obviously different from the divided main data that start up the whole parallel process, like a collection of any enumerable.
When dealing with multithreading programming, it is like executing multiple applications that live within the same process all together. They may also talk to each other with locking or signals, but they do not need to.
Task parallelism happens when we want to split different activities (functions or algorithms) that start from the same point with the same application state (data). Usually, these paralleled tasks end up all together in a task-group continuation. Although this common ending is not mandatory, it is maybe the most canonical definition for task parallelism within the .NET TPL. You should recognize that the choice of continuing with a single task or with multiple tasks, or waiting on another thread of tasks does not change the overall definition. It is always task parallelism.
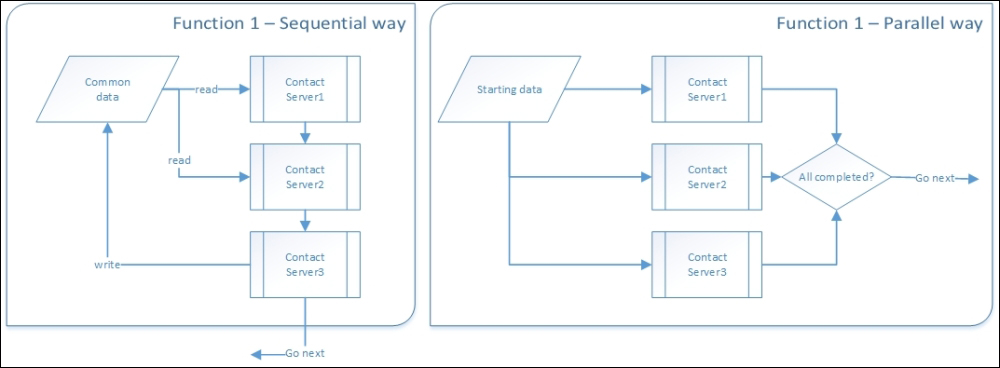
How task parallelism changes a sequential communication with multiple external systems
Any time we need to do different things all together with the same starting data, it is task parallelism. For example, if we need to save data across three different DBs all together, it is task parallelism. If we need to send the same text throughout a mail a file log and a database, those three asynchronous tasks are task parallelism.
Usually, these different things do not need to talk to each other. If this is a requirement, usual locks or (better) signaling locks may give us the ability to drive such multiple asynchronous programming in order to avoid race conditions in resource usage or data inconsistencies with multiple read/writes. A messaging framework is also a good choice when dealing with a multiple asynchronous task execution that needs some data exchanging outside the starting data state.
When using asynchronous programming with multiple tasks (refer to the Asynchronous Programming Model section in Chapter 4, Asynchronous Programming), it may be that we actually use multiple threads. Although this is task-based multithreading, this is not task parallelism because it misses a shared starting point and overall shared architecture. Parallelism is made by another abstraction level above the abstraction level of Task-based Asynchronous Pattern (TAP).
When we query a Delegate object that is executing some remote method asynchronously, we are actually using a thread-pool thread (we may also use those threads by scratch); we are still using simplified multithreading tools. This is not parallelism.
The art of executing the same function/method against a single (usually huge) dataset is called data parallelism. When working with a huge dataset, parallel programming can bring about an impressive time reduction of the execution of algorithms.
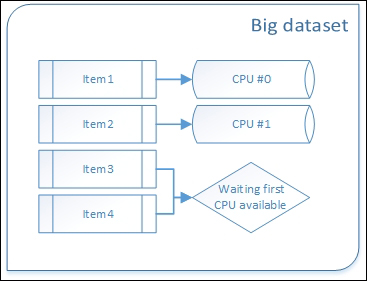
How data parallelism splits data items across CPUs
Within data parallelism, there are more rules; this is different from task parallelism, in which we can actually implement any logic when creating our parallelized functions. Most important of all is that all data must come from a single (usually huge) dataset. This principle is directly coupled to the set theory.
A set is a uniform group of items of the same type. In the .NET world, a set is any typed array, collection, or the same data type. Like in any relational database, a single table may contain only a homogenous group of items; the same thing happens when we talk about a set. Indeed, a relational table is actually derived from the set theory.
It is not enough to have multiple items all together to create a set. Actually, a set must have any number of items that can be handled as a single unique super-entity. All items that compose a set must be structured as a whole. This means that to practice correctly with data parallelism, a single object type must fill the set once (no duplications), and no logic will ever be admitted to interact with a single item composing a set if the same logic will not be executed against all other items. Another principle about a set is that items do not have any order. Although, they do have an identifier; otherwise, duplication could occur.