
Chapter 14. Retrospective
Retrospectives can be a powerful catalyst for change. A major transformation can start from a single retrospective.
Esther Derby and Diana Larsen, Agile Retrospectives -- Making Good Teams Great
We have finished all the features on our list. Here’s the cumulative list, lightly edited for clarity.
5 USD x 2 = 10 USD |
10 EUR x 2 = 20 EUR |
4002 KRW / 4 = 1000.5 KRW |
5 USD + 10 USD = 15 USD |
5 USD + 10 EUR = 17 USD |
1 USD + 1100 KRW = 2200 KRW |
Remove redundant tests |
Separate test code from production code |
Improve the organization of our tests |
Determine exchange rate based on the currencies involved |
Improve error handling when exchange rates are unspecified |
Improve the implementation of exchange rates |
Allow exchange rates to be modified |
Continuously integrate our code |
Does the act of crossing out every line in the list mean we’re done? Probably not. For one thing: change is the only constant in software. Even if we decide to not touch anything in our code because it’s fit for purpose, the things surrounding our code are bound to change over time. During the time it took to write this book, the following things changed in the ecosystem:
-
Go v 1.16 was released.
-
Node.js v 16 was released.
-
Python v 3.9.5 was released.
-
New versions of the GitHub actions setup-node and setup-python were released.
-
Most significantly, vaccines for COVID-19 were released and approved; changing yet again how we structure our lives, do our work, and conduct our social interactions — of which writing software is one aspect.
It is almost certain that by the time you read these words, other significant changes have happened in the myriad things that exist in the ecosystem in which our code lives.
Beyond the great unknown of the future, are there things about our code in the here-and-now that we could potentially improve.
Let’s take some time to recap what we did and reflect upon how we did it. We’ll frame our retrospective along these dimensions.
-
Profile, i.e. the shape of the code.
-
Purpose. This includes what the code does and — more importantly — does not do.
-
Process. How we got to where we are, what other ways might have been possible, and the implications of taking a specific path.
Profile
I use the term “Profile” to include both subjective aspects such as readability and obviousness, and their objective manifestations, namely complexity, coupling, and succinctness. In other disciplines, the word “form” is also used to describe analogous aspects.
In the Preface of this book, we defined simplicity as a key term in the definition of Test-Driven Development. We can measure the simplicity of our code now using some metrics.
Cyclomatic complexity
Cyclomatic complexity is a measure of the degree of branching and looping in code, which contributes to the difficulty in understanding it. This measure was defined by Thomas McCabe in a paper published in 1976. Later, McCabe and Arthur Watson developed this concept specifically in the context of a testing methodology. McCabe’s defintion of cyclomatic complexity’s — independent of the syntactical differences between languages and rooted in the organization of source code as a control-flow graph — is an approach that’s relevant to us as we analyze things from the vantage point of TDD.
In simplest terms: the cyclomatic complexity of a block of code is the number of loops and branches in the code plus one.
Tip
The Cyclomatic Complexity of a block of code with “p” binary decision predicates is “p + 1”. A “binary decision predicate” is any point in code where one of two paths can be taken, i.e. an branch or a loop on one boolean condition.
A block of code with no branches or loops — that is, one where control flows linearly from one statement to the next — has a cyclomatic complexity of one.
McCabe’s original paper recommended that developers should “limit their software modules by cyclomatic complexity instead of physical size”. McCabe provided an upper limit of 10 and pragmatically called this “a reasonable, but not magical, upper limit”.
Coupling
Coupling is a measure of interdependency of a block of code (e.g. a class or method) on other blocks of code. The two kinds of coupling are Afferent and Efferent coupling
- Afferent Coupling
-
This is the number of other components that depend on a given component.
- Efferent Coupling
-
This is the number of other components that a given component depends on.
Figure 14-1 shows a class diagram with various dependencies. For “ClassUnderDiscussion”, the afferent coupling is one and the efferent coupling is two.

Figure 14-1. Afferent and efferent coupling
Tip
Useful mnemonic: afferent coupling is indicated by the number of dependency arrows that arrive at a given component. Efferent coupling reflects the number of errors that exit from a given component.
A measure of stability of the code is the balance between afferent and efferent coupling. The instability of a component can be defined by the following formula:
That is: the instability of a component is a fraction between zero and one. Zero indicates a completely stable component that does not depend on anything else. This is virtually impossible for any component written in a general purpose language, since any such component would at minimum depend on components provided by the language (i.e. primitives or system classes). A value of one indicates maximum instability: such a component depends on other components and nothing depends on it.
For the “ClassUnderDiscussion” in Figure 14-1, the instability is 2/3.
Succinctness
Lines of code is a dangerous metric — especially across different languages. The expressive power of languages vary widely. An obvious reason for this is the presence or absence of certain linguistic features — key words, idioms, libraries, and patterns — in a particular language. Even something as trivial as formatting conventions can artificially increase or decrease the line count across languages. Consider the following two behaviorally identical “Hello World” programs, one in Go and one in C#
namespaceHelloWorld{classHello{staticvoidMain(string[]args){System.Console.WriteLine("Hello World!");}}}
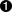
Declare namespace for program

Define a class to contain the method

Define the method that does the work

The line of code that prints “Hello World”, with a dependency on
System.Console.WriteLinemethod
packagemainimport"fmt"funcmain(){fmt.Println("Hello World!")}
Declare package for program
Include
fmtpackage as a dependencyDefine the method that does the work
The line of code that prints “Hello World” using the
Printlnmethod from thefmtpackage
It’s clear that it takes 10 lines of C# code to do that same work as 7 lines of Go code. Is this a fair or even meaningful comparison? No! Despite the structural similarities between the two languages — both require dependencies to be declared, a namespace to be defined, a “main” method that does the work, and a single line of code to print “Hello World" — there are sufficient differences to make a comparison of LOC silly. For another thing: C# requires a class within which the Main method must be defined, there is no such need for the Go main function. For another difference: Go requires that opening braces be put at the end of the lines where the method (or any other block, like an if of for statement) is defined. Contrastingly, C#’s conventions require that the opening brace be put by itself on a new line. This latter difference itself contributes to three extra lines of code in the C# program. 1
A better metric is to compare the lines of test code to the lines of production code in the same language. This normalizes for any language-specific quirks and conventions — especially as the code size increases and the line-count take on a statistical (as opposed to anecdotal) significance.
Purpose
Aesthetics are important, however, all code is written to meet some need. The extent to which it meets that need and the manner in which it does so are what I call “purpose”. In other disciplines, the word “function" — especially in contrast to “form" — is used. I’ve avoided using this term because of the risk of confusing an aspect of code with the software meaning of the word “function”.
The extent to which a piece of code meets its purpose can be looked at from two perspectives: does it do everything it’s intended to do? And does it do only what it should do? The latter is termed Cohesion, and the former Completeness.
Cohesion
Cohesion is a measure of “relatedness” of the code in a module. High cohesion reflects that the code in a module — method, class, or package — is closely related to each other.
Cohesion is a subjective measure. However, cohesion is of different types, some of which are more preferable than others. The most desirable form of cohesion is functional cohesion, which is when all parts of a module contributed to a single, well-defined task. At the other end of the spectrum is coincidental cohesion, which is when the parts of a module are grouped arbitrarily with no discernable singularity of purpose.
Completeness
Does our code do everything it should? Functionally, we finished all the items on our checklist — we crossed everything off. That’s one indicator of completeness.
How complete are our tests, though? Could we gain more confidence by writing additional tests? Consider these cases:
-
Overflow. This is the condition that results from storing a number that’s too large to be stored in a particular data type. Adding
Moneys or multiplying aMoneywith another number can cause overflow. -
Underflow. This is the condition that results from storing a number that’s too small (i.e. very close to zero). There aren’t enough significant digits to represent the number correctly. Dividing a
Moneyby a large number can cause underflow, as can the presence of a very small exchange rate. -
Division by zero. The result of dividing a nonzero number by zero is infinity. The result of dividing zero by zero is undefined.
None of these scenarios are currently tested and therefore the code is unable to deal with them. It’s compelling evidence that the code is incomplete. However, we know how to build these features: by driving them via tests.
Process
Both Profile and Purpose measure the code on various attributes of quality. The judge the result of the journey. In contrast, it is equally important to assess the Process of how we got to our code, including the various intermediate stages that may not have survived till the end. This is a judgment of the path we took along our journey.
What if we had started building our features in a different order than what was on our checklist? It’s quite possible, perhaps likely, that we would end up with a different implementation. For example: our Money entity has methods for multiplication and division, but not for addition. If we had implemented the feature “5 USD + 10 USD = 15 USD” in Chapter 1 instead of Chapter 3, we may have had and addition method in the Money entity.
There was a logical progression in the way we arranged our features: simple ones first. However, had we started by, say, building the addition feature with different currencies “5 USD + 10 EUR = 17 USD”, would have had to introduce exchange rates quite early. Where would we have put them? Probably in Money, since that’s still a reasonable first abstraction. Would we have recognized and extracted the Portfolio and Bank entities? It’s difficult to speculate, but I’m tempted to say it would have required more effort to identify multiple abstract concepts while building one feature.
Putting it all together
We have seen the three dimensions — Profile, Purpose, and Process — which we can use to analyze our code. Let’s project our code onto the the three dimensions and see what reflections we see.
Go
Profile
We can measure the cyclomatic complexity of our code by using a tool like gocyclo. This tool, itself written in Go, can be installed as an executable and then used to analyze the cyclomatic complexity of any Go code. If we run gocyclo . in our go folder, here are the most complex methods. Every other method has the minimal possible cyclomatic complexity of 1.
5stocks(Portfolio).Evaluate stocks/portfolio.go:12:13main assertNil money_test.go:129:13stocks(Bank).Convert stocks/bank.go:14:12main assertEqual money_test.go:135:1
We see that the most complicated method — Portfolio.Evaluate — has a cyclomatic complexity of 5. Even though this is well below the heuristic threshold of 10, it’s illustrative to see that this complexity could be reduced by using the extract method refactoring one or more times. For example: the creation of a failure messages could be extracted into a new method, which is then called from within Portfolio.Evaluate
func(pPortfolio)Evaluate(bankBank,currencystring)(*Money,error){...failures:=createFailureMessage(failedConversions)returnnil,errors.New("Missing exchange rate(s):"+failures)}funccreateFailureMessage(failedConversions[]string)string{failures:="["for_,f:=rangefailedConversions{failures=failures+f+","}failures=failures+"]"returnfailures}
Unchanged code in
Evaluate, omitted for brevityCall a private function to create failure message
Function
createFailureMessageextracted from within theEvaluatemethod
Is this better? It depends on your perspective. The cyclomatic complexity of Evaluate is lower (4), but the combined cyclomatic complexity of the two methods is now higher (6).
The Coupling between our code is low. Portfolio depends on Money and Bank. Bank depends on Money. The Test class — unavoidably — depends on all three. The only reasonable reduction in coupling we can do is to separate the tests into classes: TestMoney, TestPortfolio, and TestBank.
In terms of succinctness, Go provides a tool to check for suspicious code. It is the vet command, and it’s instructive to run the go vet ./... (the ellipses are to be typed literally) and notice the output. For our program, there are no warnings, which is how we should endeavor to keep all our programs. The vet command not only looks for superfluous code — useless assignments, unreachable code, for example — it also warns against common errors in Go constructs.
Purpose
Our Go code has good cohesion: three named types with well-defined responsibilities. The one criticism that can be laid at our doorstep is that, because there is no Add method in Money, the addition of amount s happens within Portfolio.Evaluate and not in Money.
What if we had a Money.Add method? We could simplify our Portfolio.Evaluate a bit, like shown here.
func(pPortfolio)Evaluate(bankBank,currencystring)(*Money,error){totalMoney:=NewMoney(0,currency)failedConversions:=make([]string,0)for_,m:=rangep{ifconvertedMoney,err:=bank.Convert(m,currency);err==nil{totalMoney=total.Add(convertedMoney)}else{failedConversions=append(failedConversions,err.Error())}}iflen(failedConversions)==0{return&totalMoney,nil}...}
Total is stored in a
Money, not in afloat64typeUsing the new
Money.Addmethod, assuming it has only one return valueReturning a
Moneypointer, as beforeRest of the method is identical, omitted for brevity
How would we test-drive the Money.Add method? We may find it propitious to adhere to this design:
-
The method should accept a single
other Moneyargument -
Its first return value should be
Moneytype, representing the sum of thisMoneyandother Money -
It should add the
other Moneyonly if the currencies ofotherand thisMoneymatch -
When the currencies of the two
Moneys differ, it should indicate the failure to add them, either through a seconderrorreturn value or bypanicing — mildly justifiable in this case because it’s only ever called fromPortfolio.Evaluatewhen currencies match after conversion
Process
We started by putting the Money and Portfolio code in a single source file and then separating them into two files in the stocks package. We then created Bank in this package later. Could we have identified this separation earlier, perhaps right at the beginning? Or conversely, could we have coded all of it in one giant file and separated them at the end? What if we didn’t separate code into discrete files at all?
The process we followed minutely affected the shape of our Go code. As a general rule, a process should be judged by the results it produces. In TDD, we have a significant lever to control the process: the pace as which we proceed. Our single-file production code had acquired two distinct abstractions — Money and Portfolio — by the end of Chapter 3. That’s why we modularized at that juncture. Now that you’ve finished the features, what do you think? Would you make a similar choice if you redo the code, perhaps to teach someone else?
JavaScript
Profile
To gather complexity metrics for our JavaScript code, we can use a tool like JSHint. JSHint comes in many guises, the home page provides an online editor in which you can paste JavaScript code and measure its complexity. For our purposes, the NodeJS package is more appropriate. JSHint can be installed globally by running npm install -g jshint at a command line.
To use jshint, we need to specify a couple of configuration parameters. The simplest way to do this is to create a file named .jshintrc in the js folder.
{"esversion":6,"maxcomplexity":1}
Specifying the version of EcmaScript to use
Setting the maximum cyclomatic complexity to the lowest possible value
Note that we have set the maxcomplexity to 1 — the lowest possible cyclomatic complexity for any method. This goal isn’t to meet this threshold: as mentioned earlier, 10 is a more typical value. The reason we set it to 1 here is to force jshint to ptint every method with a higher cyclomatic complexity as an error.
With this short .jshintrc file in place, we can simply run jshint from the command line in the js folder to examine which methods have a cyclomatic complexity that exceeds 1.
bank.js: line 13, col 12, Thisfunction's cyclomatic complexity is too high. (3)portfolio.js: line 13, col 42, This function's cyclomatic complexity is too high.(2)portfolio.js: line 11, col 13, Thisfunction's cyclomatic complexity is too high. (2)test_money.js: line 81, col 44, This function's cyclomatic complexity is too high.(2)test_money.js: line 89, col 30, Thisfunction's cyclomatic complexity is too high.(3)
We see that there a couple of methods with a cyclomatic complexity of three, and a few more with a complexity metric of two.
This validates a key claim of Test-Driven Development. The incremental and evolutionary style of coding that TDD encourages results in code with a more uniform complexity profile. Instead of one or two “superman” methods or classes, we get a better distribution of responsibility across our modules.
The coupling between our code is low. Both Portfolio and Bank depend on Money, which is a natural consequence of our domain. There is also a more subtle dependency from Bank to Portfolio. It’s subtle, because unlike Money, the Portfolio does not require an object of type Bank. The evaluate method in Portfolio requires a “bank like object" — that is, an object that implements a convert method. This is a dependency on an interface and not a specific implementation. This is different from how Portfolio depends on Money: there is an explicit call to new Money() in the evaluate method.
Important
When class A creates a new instance of class B, it is difficult to use Dependency Injection. However, if A only uses methods defined by B — i.e. A has an interface dependency on B — it is easier to use Dependency Injection.
We encountered Dependency Injection in Chapter 4 and Chapter 11. We can inject any object that implements a convert method to test Portfolio.evaluate — it doesn’t have to be an actual Bank object. Consider this strangely written but valid — and passing — test.
testAdditionWithTestDouble(){constmoneyCount=10;letmoneys=[]for(leti=0;i<moneyCount;i++){moneys.push(newMoney(Math.random(Number.MAX_SAFE_INTEGER),"Does Not Matter"));}letbank={convert:function(){returnnewMoney(Math.PI,"Kalganid");}};letarbitraryResult=newMoney(moneyCount*Math.PI,"Kalganid");letportfolio=newPortfolio();portfolio.add(...moneys);assert.deepStrictEqual(portfolio.evaluate(bank,"Kalganid"),arbitraryResult);}
Number of
Moneyobjects in our testEach
Moneyobject has a randomamountand itscurrencyis also made upA
Banktest doubleOverriden
convertmethod
Always return “π Kalganid”

The result is expected to be “π times
moneyCount" Kalganid
Assertion, which passes
We have created a silly implementation of a bank in our test. Silly from a business standpoint, yet completely valid from an interface perspective. This bank always returns “π Kalganid” from its convert method, regardless of any arguments it’s given. 2 This means that for each call to this convert method from Portfolio.evaluate, the Portfolio accumulates “π Kalganid”. Thus the final result is π times the number of Money objects, in Kalganid.
Even though the test is peculiar, it illustrates the key concepts of “Test Doubles” and Interface Dependency.
Tip
A “Test Double” is a replacement for “real world” (i.e. production) code — method, class, or module — that’s substituted in a test so that the System Under Test uses this replacement code instead of the real code as a dependency.
It’s obvious that we could follow the pattern shown in the preceding test and rewrite all our tests for Portfolio.convert to use test doubles instead of the “real” Bank. The real question is: should we?
The answer is not obvious. As a general rule: use the path of least resistance. If the effort to introduce a test double is greater than using the real code, then use the real code. Otherwise, use a test double.
There is also a risk of using a test double: if there are non-obvious side effects between the system under test and the the dependency, a test double may inadvertently mask these side effects. Or the test double may introduce new side effects that are not present in the real code. Either way, there is a risk that testing with the test double may not be a faithful replica of testing with the “real” dependency in place.
Is there a way out of this? Using stateless code with a well-defined interface is a start. A method that is stateless — that is, one whose behavior depends completely on its parameters — is much easier to replace with a test double than a method which relies heavily on mutable state of surrounding objects that are not passed as parameters. 3
Purpose
The three classes in our JavaScript display singularity of purpose: a class for each key concept.
Is there something worth improving? There is a bit of a leaky abstraction in the try block in the Portfolio.evaluate method.
try{letconvertedMoney=bank.convert(money,currency);returnsum+convertedMoney.amount;}
Did you spot it? The conversion of money into a new currency yields a compact, self-contained object: convertedMoney. We then pry open this object to look at its amount and add it to a total … only for us to later put Humpty Dumpty back again when we return new Money(total, currency) at the end of the method!
How would our code look if the Money class had an add method? Specifically, how might we drive it through tests, and what would the refactored Portfolio.evaluate look like?
We can think of a few tests we may use to drive out the behavior of Money.add. Adding two Money objects in the same currency should work in a straightforward way, obeying the commutative law of addition of numbers. Adding two Money objects with different currencies should fail with an appropriate exception. We can justify this exceptional behavior on the grounds that adding multiple currencies requires us to maintain a Portfolio — which already carries the responsibility of conversion.
testAddTwoMoneysInSameCurrency(){letfiveKalganid=newMoney(5,"Kalganid");lettenKalganid=newMoney(10,"Kalganid");letfifteenKalganid=newMoney(15,"Kalganid");assert.deepStrictEqual(fiveKalganid.add(tenKalganid),fifteenKalganid;assert.deepStrictEqual(tenKalganid.add(fiveKalganid),fifteenKalganid;}testAddTwoMoneysInDifferentCurrencies(){leteuro=newMoney(1,"EUR");letdollar=newMoney(1,"USD");assert.throws(function(){euro.add(dollar);},newError("Cannot add USD to EUR"));assert.throws(function(){dollar.add(euro);},newError("Cannot add EUR to USD"));}
Test to verify directly adding two
Moneyobjects in same currencyTest to verify exception when attempting to add two
Moneyobjects with different currencies
After we write a Money.add method that fulfils the above tests, 4 we can use it to reduce the leaky abstraction in Portfolio.evaluate.
evaluate(bank,currency){letfailures=[];lettotal=this.moneys.reduce((sum,money)=>{try{letconvertedMoney=bank.convert(money,currency);returnsum.add(convertedMoney);}catch(error){failures.push(error.message);returnsum;}},newMoney(0,currency));if(failures.length==0){returntotal;}thrownewError("Missing exchange rate(s):["+failures.join()+"]");}
Using the
Money.addmethodThe initial value is a
Moneyobject, not a numberThe
totalcan be returned directly: it’s aMoneyobject
Is the cost of removing the leaky abstraction worth the extra method in Money class and the tests for it?
There isn’t a cut-and-dried answer for it. We could reason that the add method is a worthy companion to the times and divide methods already in Money and that preventing the Portfolio.evaluate method from prying into Money is a good thing. On the other hand, we could reason that Bank.convert already pries into both the currency and amount of the Money object it’s given; and that there’s no obvious way to remove that leaky abstraction without adding substantially more behavior to Money — at the expense of Bank, probably.
The contrasting answers are reflective of the element of subjectivity inherent in the notion of “fit for purpose”. It’s reasonable to have different opinions on the question of “what is the purpose of this class?” The code that results from the different opinions will also be different — invariably and unavoidably.
Process
In the beginning, all our source code was in one file. We introduced separation of concerns in Chapter 4 and used it to partition our code into modules in Chapter 6. The Bank class was introduced in Chapter 11. It’s likely that our code would have turned out differently had we followed another path. Could it have been better?
If we were to solve the problem again, we may separate the tests from the production code earlier — perhaps as soon as we have one green test. Early separation of concerns can have benefits: it forces us to make our dependencies explicit and think critically about what each module exports. This can lead to better encapsulation (i.e. information hiding).
Can you think of shortcomings in our JavaScript code? Which steps during the incremental growth of our code caused them? And were there any stages where we could have corrected them?
Python
Profile
The Python ecosystem provides a choice of tools and libraries to measure the complexity of code. Flake8 is one such tool. Flake8 combines the static analysis capabilities of several other tools. That’s why it provides a lot of features, including testing for cyclomatic complexity using the mccabe module.
Flake8 can be installed using the Python package manager. The command python3 -m pip install flake8 is all that’s needed. Once installed, running flake8 in a folder with Python source files, such as the py folder in our TDD_PROJECT_ROOT, will scan the code for all violations and warnings. To limit the output to warnings of a specific kind, we can use the well-defined Flake8 error codes. For example, the command flake8 --select=C will display only cyclomatic complexity violations as detected by the mccabe module. Since the default complexity threshold is 10, we will not see any warnings if we run the above command. To get any output, we have to set a lower complexity threshold.
Let’s try flake8 --max-complexity=1 --select=C on our Python code and see what comes up.
./bank.py:12:5: C901'Bank.convert'is too complex(3)./portfolio.py:12:5: C901'Portfolio.evaluate'is too complex(5)./test_money.py:75:1: C901'If 75'is too complex(2)
We see that Portfolio.evaluate and Bank.convert are the two methods with the highest complexity. However, both are well within the heuristic limit of 10 recommended by McCabe. This is a vindication of one of the claims of Test-Driven Development: that it yields code with lower complexity.
Could we improve the readability of the code in some tangible way? Consider the Portfolio.evaluate method and how we test for the presence of failures:
defevaluate(self,bank,currency):...iflen(failures)==0:returnMoney(total,currency)...
Checking if
failuresis empty to determine whether aMoneyobject should be returned
We’re checking for the presence of failures by seeing if its length is zero. Is there a simple way we could use?
It turns out that there is. In Python, empty strings evaluate to false, so we can simplify the two checks.
...ifnotfailures:returnMoney(total,currency)...
An empty string evaluates to
false, allowing us to usenot failuresin both lines of code
Tip
In Python, any object can be tested for its truth value, and empty sequences or collections are treated as false.
Using language idioms is another way to simplify code, even if it doesn’t reduce the cyclomatic complexity metric. Keeping things consistent with linguistic norms ensures that our code subscribes to the principle of least surprise.
Purpose
Our Python code shows fidelity to its purpose: each of the three main classes does one thing and does it reasonably well.
There is a leaky abstraction in Portfolio.evaluate that sticks out like a sore thumb. This method is too nosey about the internals of the Money class. Specifically: it probes into each Money object returned by Bank.convert and keeps track of the amount attribute. Then, at the end of the method, it creates a new Money object with this cumulative total.
Could we make Money a shier object that doesn’t need to be examined so intimately by the Portfolio.evaluate method? We could, if we could add Money objects directly and not just their amount fields.
We can do that by overriding a hidden method whose signature is __add__(self, other).
Tip
In Python, to override the + operator for a particular class, we must implement the __add__(self, other) method for that class.
We can test-drive the behavior of the __add__ method through this test.
deftestAddMoneysDirectly(self):self.assertEqual(Money(15,"USD"),Money(5,"USD")+Money(10,"USD"))self.assertEqual(Money(15,"USD"),Money(10,"USD")+Money(5,"USD"))self.assertEqual(None,Money(5,"USD")+Money(10,"EUR"))self.assertEqual(None,Money(5,"USD")+None)
We want to be able to add two Money objects as long as they have the same currency. Otherwise, we want to return None. To ensure that the commutative property of addition holds, we verify that adding two Money objects in either order yields the same result.
The following implementation of Money.__add__ fits the bill.
def__add__(self,a):ifaisnotNoneandself.currency==a.currency:returnMoney(self.amount+a.amount,self.currency)else:returnNone
To further streamline our code, we can redesign Bank.convert so that two values: a Money and a key for any missing exchange rate.
. If the exchange rate is found, a valid Money object is returned. The second return value is None
. If the exchange rate is undefined, the first return value is None. The second return value is the missing exchange rate key.
Here are the refactored tests that we can use for this redesign.
deftestConversionWithDifferentRatesBetweenTwoCurrencies(self):tenEuros=Money(10,"EUR")result,missingKey=self.bank.convert(tenEuros,"USD")self.assertEqual(result,Money(12,"USD"))self.assertIsNone(missingKey)self.bank.addExchangeRate("EUR","USD",1.3)result,missingKey=self.bank.convert(tenEuros,"USD")self.assertEqual(result,Money(13,"USD"))self.assertIsNone(missingKey)deftestConversionWithMissingExchangeRate(self):bank=Bank()tenEuros=Money(10,"EUR")result,missingKey=self.bank.convert(tenEuros,"Kalganid")self.assertIsNone(result)self.assertEqual(missingKey,"EUR->Kalganid")
When conversion works the first return value is a valid
Moneyobject,and
Noneis the second return valueWhen the exchange rate is undefined,
Noneis the first return value,and the second return value is the missing exchange rate key
The modified Bank.convert method — not shown here — no longer throws any exception. 5
With this implementation in place, we can refactor the Portfolio.evaluate method.
defevaluate(self,bank,currency):total=Money(0,currency)failures=""forminself.moneys:c,k=bank.convert(m,currency)ifkisNone:total+=celse:failures+=kifnotfailureselse","+kifnotfailures:returntotal
Not only is the resultant Portfolio.evaluate method shorter and more elegant, it also has a lower cyclomatic complexity. Run flake8 --max-complexity=1 --select=C and verify for yourself!
Process
We wrote our first tests and the first bits of production code all in one file. By the time we got to separating code in modules in Chapter 7, we had three classes: two corresponding to the domain concepts of Money and Portfolio and one class for our tests. Later, we introduced the third domain class of Bank in Chapter 11. How did the order in which we developed the features influence the resultant code?
One significant effect of the direction we took was the introduction (in Chapter 3) and subsequent removal (in Chapter 10) of the lambda expression in Portfolio.evaluate method. Could we reintroduce the brevity and refinement of the lambda expression? It would require reimagining our code, but it could be done. Recall the structure of the lambda function from Chapter 8, slightly changed here to use Bank.convert method (instead of the self.__convert that existed in Chapter 8):
total=functools.reduce(operator.add,map(lambdam:bank.convert(m,currency),self.moneys),0)
The limitation of lambdas is that we cannot write conditional code in how they’re applied. However, what if we we accumulated, through the add operator, both the converted Money objects and any missing exchange rates returned by the multiple calls to the Bank.convert method?
It is doable — it requires changes to the signature of Bank.convert and an overriden __add__ method than can add a (Money, string) tuple. Is it advisable to do so?
There isn’t a right or a wrong answer to this question. Software is meant to be read much more often than it’s written. Would the resultant code be easier to read? We can and should write it first before forming too strong an opinion. However, even after writing it, we shouldn’t expect a definitive answer on which style — with or without the lambda — is “better”. The element of subjectivity remains even after we sift our code through the measurable metrics of complexity, cohesion, and coupling.
Where We Are
We are at the end of our TDD journey in this book. However, this isn’t the end.
You’re encouraged to look at updated source code in the accompanying repository for updates and things not covered in depth in this text.
You also have the opportunity to engage with other readers on alternate ways to solve the problem and on how to extend it.
As for your longer journey in forming a habit so that you test-drive most if not all your code, this is just a beginning.
1 The reason Go requires that the open brace be on the same line is more than merely aesthetics; it’s rooted in how the language’s compiler figures out where one statement ends and another begins. https://golang.org/doc/faq#semicolons
2 Notice that the convert method here doesn’t even define any arguments, since it’s going to ignore them, anyway. Recall from Chapter 6 that JavaScript does not enforce any rules on the number or types of parameters that are passed to a function, regardless of the function definition.
3 The methods most difficult to replace with test doubles are those that rely on global state — another reason why globals are to be avoided like zombies during the apocalypse!
4 The Money.add function is “left as an exercise for the reader" — a phrase no workbook should be without. There is an implementation in the github repository, for the curious (or irritated) subset!
5 The source code for the modified Bank.convert method, along with all other changes, is available in the online repository.