
3
Library 3.0
Abstract
Library 3.0 is gaining popularity among research and academic library users faster than had been anticipated. In fact, it is currently deemed one of the most exciting advances in research and academic library development. The increasing popularity of Library 3.0 is attributed partly to its potential to provide an environment conducive to exploration, innovation, inspiration and personalisation. It emphasises context and not just the content of information service provision. Thus, it is anchored in a number of human factors, such as community, relationships, connection, conversation, personalisation, comfort, simplicity, play, progress and passion, which define progressiveness. Significantly, Library 3.0 is not about quick fixes but is a model which enables libraries to grow beyond being book-based and extend the information experience to wherever, however and whenever the users want it.
Keywords
Library 3.0 principles
apomediation
intelligent library
semantic web
quick reference code
Library 3.0 is ostensibly gaining wide acceptance faster than had been anticipated. As the model becomes ingrained in the lives of researchers and academic library users, it is deemed to be one of the most exciting advances in library development in this age (Belling et al., 2011). The increasing popularity of Library 3.0 among research and academic library users is partly attributed to its potential to provide an environment conducive to exploration, innovation and inspiration. By facilitating the personalisation of library services and experience, Library 3.0 provides a mechanism for solving the challenges facing users from their own perspectives.
The Library 3.0 approach emphasises that context, and not content, is ‘king’ in the emerging information mix. This is exemplified by the fact that despite using technology, Library 3.0 shifts focus from ‘whiz bang widgets, gadgets, shiny new tools or any other raw technology’ to human factors which influence the effective delivery of library services (Abraham, 2009: 28). These factors include community, relationships, connection, conversation, personalisation, comfort, simplicity, play, progress and passion. Abraham, (2009) further avers that these factors are at the heart of any progressive library. He explains that Library 3.0 is not about quick fixes but presents a model that enables libraries to grow up from the foundation of books and extend the information experience to where, how and when, the users want it.
Library 3.0 promotes a culture that anticipates, understands and supports positive change and risk-taking, which Nelson (2008) views as critical for any progressive library. Indeed, myriad changes are already being experienced in areas that constitute the core of librarianship. The widespread digitisation of information sources is one of these areas. For instance, Encyclopaedia Britannica is now available only in digital form after 224 years in print format. It is reported that it had too many pieces of information in its databases to fit any print medium, hence the need to digitise it (Kozlowski, 2012; Parmar, 2012). Similarly, Amazon.com has confirmed that it now sells more Kindle format and e-books than paper-based publications (Malik, 2012). Nicholas Negroponte, Chairman Emeritus of the Massachusetts Institute of Technology’s Media Lab and leader of the One Laptop Per Child effort to build low-cost laptops for education, has predicted that printed books will soon be rare luxury items, while e-books will become the norm (Young, 2010). A number of academic and research libraries have also been renovated in the recent past to create more room for seating, space for group work, cafés and technology pods. One common feature of the renovations is the massive reduction in the size and content of physical collections. For instance, the University of Denver moved four-fifths of its physical collection to an off-campus facility to create room for a welcoming and flexible ‘Academic Commons’ (Kiley, 2011; Schwartz, 2012). In Kenya, the Library of the Catholic University of East Africa digitised most of its services and collection in 2012 and has advertised for sale chairs, tables and bookshelves which it no longer requires. These reports indicate that the future of research and academic libraries will be a digital one. It is envisaged that this future will be flexible and adaptable to survive in an environment of constant and rapid change. Apart from its other benefits, such as convenience of use, digitisation reduces the possibility of disruptions and losses during natural disasters. In the State University of Haiti, for instance, eleven of twelve library buildings collapsed during the devastating earthquake of 2011, causing great damage to the library materials (Libraries Without Borders, 2011). Digitisation minimises such losses and facilitates rapid recovery.
The environment created by Library 3.0 effectively takes advantage of the benefits of the Internet which, as Chetty (2012) explains, stands to be the greatest information facility ever built in the history of humanity. He further estimates that there are over one hundred billion clicks per day online, approximately five trillion links between all Internet pages in the world, over two million emails sent per second from all around the planet; and that the Internet accounts for five per cent of all electricity used on the planet. At this rate, it would seem as if every object – living and non-living – will soon have its own page. Even without this extraordinary possibility, the result will be the gradual development of trillions of pages. Evidently, people’s ability to create information has increased beyond their capacity to manage it. There are several information access points and paths, making it difficult for users to navigate the information pathways. To benefit meaningfully from the emerging developments in information management, users need filters to select the information that best meets their needs. In fact, there will be several layers of filters, to ensure accuracy of searching. These filters will enable users to create more value than is currently possible. Library 3.0 provides tools and mechanisms that can help harness this great mass of information. It is impossible to manage this information and maximise its accessibility using conventional library methods.
3.1. Library 3.0 principles
The authors observed that no principles of Library 3.0 are suggested in the literature reviewed. Therefore, they propose the following:
3.1.1. The library is intelligent
Bailey (1991) describes intelligence as the ability to acquire new knowledge; refine procedures for dealing with a novel situation; know, understand, recognise and deal with novel problems; represent, map and access knowledge in memory; control various processes of intelligent behaviour; perform arithmetic operations; use problem-solving knowledge (reasoning); interact with and understand other people, machines and programmes; recognise natural language; and recognise visual images (visual perception). An intelligent library is self-renewing, flexible, functional, integrated, efficient, resilient, autonomous and sensitive (adaptive).
The library 3.0 model applies artificial intelligence systems to offer apposite and comprehensive services to library users. Library intelligent systems facilitate natural language processing, mapping of free-text terms to controlled vocabulary used by common library tools such as indexes, and flexible and heuristic retrieval strategies (Bailey, 1991; Wahono, 2000). Intelligent library systems can be applied to all library operations including cataloguing, indexing, information retrieval and reference (Bailey, 1991; Blyberg, 2007). Intelligent library systems enable library users working in the 3.0 environment to retrieve information easily, based on what they need – not necessarily on how they may express the need. Intelligent library systems do not respond to users’ queries by mere word matching. Rather, they use ontologies to analyse the query and provide appropriate responses based on what the user appears to mean. Intelligent library systems make libraries more interactive, accurate and user-friendly (Dent, 2007). For instance, using specialised self-service systems, users of intelligent library systems can borrow and return information resources at times that suit them.
Research and academic libraries working in 3.0 environments may also construct and make use of intelligent library buildings. An intelligent building is perceived as one that maximises the efficiency of its occupants while, at the same time, allowing effective cost management of its resources. It is an enthralling concept, a state-of-the-art library building using innovative design and constructional technology, offering clients systems that once only existed only in the imagination of futurists (Renes, 1999). A post on a blog published by the Library and Information Association of Mauritius (LIAM) in 2009 listed architect Harry Faulkner-Brown’s ‘Ten Commandments’ on the design and planning of library buildings. Faulkner-Brown gave these as follows. Buildings should be:
1. flexible with a layout, structure and services which are easy to adapt;
2. compact for ease of movement of readers, staff and books;
3. accessible from the exterior into the building and from the entrance to all parts of the building with an easy comprehensive plan needing minimum supplementary directions;
4. extendible to permit future growth with minimum disruption;
5. varied in the provision of reader spaces to give wide freedom of choice;
6. organised to facilitate maximum interaction between books and readers;
7. comfortable to promote efficiency of use;
8. maintaining an appropriate environment for the preservation of library materials;
9. secure to control user behaviour and loss of books;
10. economical to build and maintain with minimum resources in both finance and staff (Library and Information Association of Mauritius, 2009).
Renes (1999) explains that intelligent library buildings facilitate self-utilisation by users, promote efficiency, enhance the security of users and the collection, provide ample space for library activities and use technology optimally. Intelligent library buildings also facilitate users bringing their own technology, which they plug in and use on a seamless interface.
Intelligent research and academic libraries can also use biometrics to manage access to library facilities, services and collection. The use of biometrics to aid the identification of library users facilitates the realisation of one of the core library functions, that is, matching the right ‘reader’ with the right ‘book’, as suggested by Ranganathan in his ‘five laws of library science’. One of the biometric applications which can be applied in libraries is face-detection technology, which would enable research and academic libraries to authenticate their users, just as human beings can recognise other people based on facial features and other physical characteristics. The use of face-detection technology can enable libraries to identify library users and offer them services with minimal human intervention. The technology can also enable libraries to eliminate card-swapping amongst library users or the malicious use of lost access cards by unauthorised persons. Apart from facilitating fast access to library systems, face-detection technology also has the potential to enhance security and safety in research and academic libraries by controlling access effectively. The application of biometrics to authenticate library users also reduces the costs associated with the production of library access cards. Biometrics utilise personal library users’ features, which cannot be lost, shared, forgotten, falsified or guessed. This can be done by employing applications such as avatars, which can be personalised to represent library users in cyberspace. The use of avatars to personate library users facilitates the creation and use of a single digital identity of a user. Research and academic libraries can use avatars to personalise services to fit the needs of the users closely. Avatars may be used by research and academic libraries instead of actual photos, which some users resent and resist. Importantly, avatars, as talking heads, can be added to library websites to welcome users to the library or explain library resources and services to them. Such avatars liven otherwise dull library websites and provide unrestricted help to the users. Talking avatars are popular with young researchers and students.
Another possible facet of intelligent libraries in research and academic institutions is location-based systems which enable users to search, access, and use information based on their current physical location. Such services could work like the Meetro social networking service, which enabled users to get information specific to their current physical location. Such users would also be informed of nearby facilities and other Meetro subscribers in their locale. Meetro users were also able to embed feeds from other social networking sites such as YouTube, Flickr and personal blogs through what has become known as profile aggregation. The service, which was closed down in 2007, facilitated socialising rather than just creating a collection of friends. Other services which would interest intelligent libraries include Placesite, which connects strangers with common interests, and Jambo, which also links people with common interests in a specific geographic location, such as a campus or library branch. Virtual social companions and hosts, such as Massachusetts Institute of Technology’s FitTrack, can ‘accompany’ and support library users at the point of need, just as a human librarian would (Rubin, Chen and Thorimbert, 2010).
Sciacchitano et al. (2006) suggest that finding resources in a facility with which one is not familiar can be a difficult task. Users of research and academic libraries often face this difficulty, especially in situations in which they are not familiar with what the libraries have to offer. This is especially common with new students, academic staff or researchers. Currently, most research and academic libraries use traditional methods to enhance navigation. These include static maps, directions posted on walls and other conventional signage. However, in Library 3.0, research and academic environments are increasingly facilitating greater mobility of always-connected computing devices, and users can employ hand-held devices to easily locate services and resources within a library. Such systems would aid library exploration and reduce search and retrieval times, as well as enrich the user experience (Chen, 2008). These services would transform conventional research and academic libraries into highly usable intelligent information facilities. Intelligent library systems also facilitate context-aware query processing, which enhances the semantic content of queries using lexicons and ontologies (Storey et al., 2008).
Radio frequency identification (RFID) technology can also be applied in research and academic library management to generate accurate collection statistics and facilitate the use of flexible shelving, document location and navigation, automatic and quick sorting of library materials, self-checkout and return of library materials, stock management, and security protection. Although Boss (2011) acknowledges that the use of RFID technology is not yet widespread in libraries, he reports that almost 2000 libraries in the United States of America were using the technology by mid-2011. Ward and Kranenburg (2006) report that several academic libraries in the United Kingdom, such as Glasgow, Middlesex and Nottingham Trent, had begun deploying RFID solutions as early as 2002. Abdou (2012) reported that by mid-2011 over sixty libraries in the Arab world – including Egypt, Tunisia, Libya and Morocco – had embraced RFID technology. RFID-based library management systems simplify library services and processes, particularly by reducing labour intensity. This technology provides high-efficiency service for librarians and convenience for readers (Lin, 2006). RFID technologies deployed in libraries enhance their customer care and public image; automate tedious routines and free staff time for other tasks; facilitate self-services, such as checkout and return of library materials, through automatic book drops; enhance occupational health and safety by reducing the direct involvement of library staff in manual tasks; improve speed of service delivery; reduce theft of library materials; and integrate user profiles with library systems and thus facilitate ease of identification and personalisation of services (Butters, 2008; Edwards and Fortune, 2008).
Research and academic libraries can also use agent technology to perform many functions in the library. An agent is a software programme that gathers information or performs some other service without the immediate presence of the user (Dent, 2007). For instance, agent software such as Copernic, BullsEye Pro, Dogpile and ProFusion can categorise, sort, filter and report search results on behalf of library users. Intelligent conversational agents can also be used to enhance face-to-face interaction between users and library services. Such agents can be used to facilitate a guided tour of the library collection and services, automated virtual reference and advisory services, digital collection management, and virtual story-telling, which can be useful in leading discussions (Rubin, Chen and Thorimbert, 2010). Intelligent agents can also provide customer relation services in libraries and answer frequently asked questions. Such systems may be enhanced to provide services in more than one language. The service can further be enriched through technologies which can interpret facial expressions and emotions in an effort to understand user needs and respond to them more accurately. Avatars, chatbots or talking heads can be used to enhance this experience (Allison, 2012). An example of these is the Sergeant Star (SGT STAR), which is a full-bodied animated character able to converse with any human being and respond to queries either in text or as speech. Another example is MAX, an animated museum guide at the Heinz Nixdorf Museum in Germany, which responds to queries with text and audio messages coupled with corresponding arm gestures and facial expressions (Rubin, Chen and Thorimbert, 2010). These technologies have the potential to make their interaction as indistinguishable from the real world as possible, so as to enhance their believability. Agents, in the form of digital teaching assistants, can also be used to support learning in academic libraries. This can be accomplished in conjunction with course management software such as Blackboard or WebCT (Dent, 2007). Agents can also support automated serials processing, interlibrary loan processing, acquisitions, circulation, patron information management, and cataloguing.
Attempts to develop intelligent libraries did not begin with the Library 3.0 model. Various librarians and vendors have been developing intelligent library systems for many years. These systems include REFSIM (REFerence SIMulator), which supported reference services in libraries (Vickery and Brooks, 1987; Parrot, 1989) and Intelligent Computer-Assisted Instruction, (ICAI), systems, providing library user education and training (Bailey, 1991). Pioneer intelligent library systems were largely experimental and had limited scopes of application. Although the pace of their development is still gradual, emerging intelligent libraries are expected to have more diversity, enhanced user-information interaction and opportunities for experience, making them more enjoyable. These improvements are expected to increase the systems’ potential to provide consistent services and free librarians from tedious and repetitive tasks (Rubin, Chen and Thorimbert, 2010; Allison, 2012). Language complexities, user acceptance and high costs, however, are some of the challenges which hamper the widespread deployment of intelligent libraries.
3.1.2. The library is organised
The information explosion (infobesity), the computer revolution, proliferation of new media and the push towards universal bibliographic control have jolted the foundations of conventional information management (Svenonius, 2000). The situation has been exacerbated by the growing ubiquity of the Internet and related communication technologies, which are placing more information management responsibilities on users. Whilst the Internet facilitates users in publishing and accessing more information, it also burdens them with the need to organise it if the full benefits of its availability are to be realised. Emerging information and communication technologies are acknowledged as valuable tools of information management, but they can also lead to an unprecedented information overload as thoughts are spread thin and scattered, in many respects. Herbert Simon, a pioneer advocate of attention economy, warned of information overload as early as 1971, when he stated that a wealth of information creates poverty of attention (Simon, 1971). His prediction appears to be fulfilled daily because of the information revolution. Typically, an individual has to deal with multiple information streams simultaneously. It is not strange to encounter someone chatting with more than two people on Skype, Instant Messenger or Google Chat, while also talking on a mobile phone and reading Twitter feeds at the same time. This information overload affects people’s ability to discriminate and process available data into useful information. This is largely because information is currently presented to its potential users in a scattered and overwhelming manner. Consequently users have to consume diverse pieces of information delivered via myriad platforms and devices to be able to make decisions. It is not unusual that one has to shuttle back and forth between applications, browsers or feeds to complete simple tasks. As Levasseur (2013) points out, this information consumption pattern is costly and unsustainable because as information continues to grow in quantity, scope and complexity, the pressure to manage it effectively also builds up (Robu, 2008). Kelly (2008) explains that findability is a key element of effective information management in the modern era and emphasises that when there are millions of books, millions of songs, millions of films, millions of applications, millions of everything requesting one’s attention – and most of it free – findability is a major determinant of whether the information will be used or not. The pressure to manage the vast information pathways effectively creates the need for innovative content management strategies that can cope with the prevailing ambiguity, heterogeneity and differences in perspectives (Morville and Rosenfeld, 2006) of the current information environment.
Effective information organisation involves classification. However, most information resources today exist within shared, complex and uncertain boundaries that change rapidly, making their permanent classification difficult. Effective information organisation also requires explicit description of the information to enhance how it is understood. Another important facet of information organisation, as pointed out earlier, is findability, the quality of being locatable or navigable. Information is organised to enable users to find the right answers to their questions easily. This is currently becoming more difficult, since information management is increasingly becoming decentralised with the role of librarians in labelling, organising and providing access to information being reduced remarkably as more and more users strive to manage their own information.
The Library 3.0 model is designed to turn the unorganised web of information into a systematic and usable body of knowledge by describing and linking every piece of data to enable ease of access. This approach also removes the need to duplicate data. The Library 3.0 model creates an information platform on which users, experts and librarians collaborate to create, sift and share credible information (Schultz, 2006). Library 3.0 information organisation strategies provide a way of unifying scattered information and accessing even the Invisible Web. Library 3.0 uses information organisation approaches that facilitate user participation, collaboration, usability, remixability and standardisation (Blyberg, 2007). It goes beyond mere key-word searches to knowledge-based information retrieval strategies that rely on relationships, connections and association to draw conclusions. This is achieved through ontology-rich semantic systems that facilitate intelligent and targeted information searching and discovery.
The basic foundation of information organisation in Library 3.0 is ontology, which represents knowledge as a set of concepts within a domain bound together in a web of relationships. Although ontologies are sometimes confused with taxonomies, the former are broader in scope than the latter. In fact, in some circumstances, taxonomies can be considered as subsets of ontologies. Ontologies are based on defined and controlled sets of vocabulary and relationships. Common components of ontologies include individuals, classes, attributes, relations, function terms, axioms and events. Ontologies enable information managers to specify meaning and leave no room for guessing. Thus ontologies provide a defined vocabulary to describe a domain as well as an explicit specification of its intended meaning. They capture a shared meaning of the domain and provide a formal and machine-manipulable model. They facilitate a shared understanding of the structure of information among human beings and software agents; enable reuse of domain knowledge; make domain assumptions explicit; distinguish domain knowledge from operational knowledge; and analyse domain knowledge (Sudarsun, 2007). On the other hand, taxonomies are hierarchical representations of concepts in terms of parent/child, class/subclass or broad/narrow relationships. Taxonomy is a classification, while ontology is a system of description going beyond mere classification.
Ontologies facilitate semantic interoperability, in which people create content in a format that is open and reusable by others who can add on to it, reassemble it and ultimately build something new out of the pieces they are given (McDonnell, 2012). Ontologies are developed using Web Ontology Language (OWL), which gives explicit meaning to information, making it easier for machines to automatically process and integrate it. OWL enables the creation and application of a well-defined syntax, semantics, efficient reasoning support, expressive power and convenience of expression. These enable humans and machines to classify and interpret knowledge objectively and precisely. OWL builds on the Resource Description Framework (RDF) and the RDF Schema (RDFS), which generally describe the structure of information rather than its semantic relationships and meaning (Antoniou and van Harmelen, 2003). Ontologies can enhance information organisation by binding items of content to relevant metadata which enable the content to be findable, portable and adaptive to different platforms. Effective metadata accurately reflect the content substance, have attributes that organise content in an intuitive way, and are consistent across content types and topics (Halvorson and Rach, 2012).
Other information organisation concepts which can be useful in research and academic 3.0 environments are content curation and content aggregation. Content curation is the process of sorting through the vast quantities of information on the web and presenting it in a meaningful and organised manner. It involves sifting, sorting, arranging and publishing information in a way that best meets the interest and context of the users. Content aggregation, on the other hand, is the process of collecting content automatically from diverse sources on the web. This can be done through specialised software such as Really Simple Syndication (RSS) feeds or tailored algorithms that pull content based on specific key words or phrases (Halvorson and Rach, 2012). Research and academic libraries may use the curation and aggregation tools listed in Table 3.1 below.
Table 3.1
Curation and aggregation tools for research and academic libraries
| Tool | Potential use |
| Yahoo Pipes | to mash up different online data sources into one, then sorting and filtering it to meet library users’ information needs. Users do not have to visit each online data source independently, but get the aggregate of the content of the sites of interest. Yahoo Pipes can also enable library users to transform and enrich the content of their favourite online sources to yield customised and highly usable information resource. |
| CIThread | stands for Collective Intelligence Threading. Enables library users to identify, collect, organise and use valuable content from online sources. The library user indicates interest by specifying a set of key words that the application uses to identify relevant web content. An important feature of CIThread is its capacity to develop patterns of content use, which it then applies to refine and enrich searches. CIThread users are also able to publish their findings on other social media outlets. |
| Curata | This is a content curation engine which enables library users to search, organise and share online resources. One of Curata’s important features is a self-learning system which enables it to learn what library users like or dislike over time and automate the content curation process with little or no direct intervention from users. Curata constantly searches the web to discover fresh content as soon as it is posted. |
| CurationStation | This tool enables library users to set up automated searches, which scour all web content formats and types for specified content. The findings are presented together as a feed or any other content format the user prefers. Curation Station also enables users to share the curated content. |
| CurationSoft | This is desktop-based curation software enabling library users to curate content from various online sources and share it as blog posts. Library users can drag and drop CurationSoft content into any HTML editor. This makes it flexible and usable on many web platforms. |
| DayLife | Library users can use DayLife to discover, collect and share media articles and other products. It is hosted in the cloud, making it cost-effective and easy to set up and use. |
| Eqentia | This is a content curation software library users can use to mine, filter and share atomised and scattered topical content from social media platforms in real time. |
| OneSpot | Library users can use OneSpot to discover, use and share most popular content on topics or for communities of interest to them. |
| Scoop.it | This is a news curation tool which library users can find valuable in discovering new information, adding their own perspectives and sharing it in their communities in a newspaper format. |
| Storify | This is a social network service that enables library users to collect content from various sources in cyberspace, contextualise and publish it in a timeline or horizontal slide show. These timelines or shows can be searched by other library users with similar interests and embedded in other online information channels. |
| List.ly | This is a collaborative platform for creating lists. Library users can start a list on any of a wide array of topics, to which other users can add. Originators of lists in List.ly can moderate the posts of others to ensure credibility or suitability of content. Lists thus created can be shared or embedded in other information outlets in cyberspace. Regardless of where they are published, List.ly lists continue growing as users add new content. |
| Newsle | Library users may use Newsle to keep track of stories in cyberspace on their colleagues, friends or community members. This enables the library users to keep track of what people of interest to them publish, or what is published about them. They then have an opportunity to read the published stories. Users can also share the information through popular social media platforms such as Facebook or Twitter; and can rate the content on a scale. |
| Bundlepost | Social media content management system which library users and librarians can use to manage their social media content automatically. Bundlepost also enables users to warehouse all their social media content in one place, making it easy to search. |
| Triberr | This is a blog amplification platform that library users and librarians can utilise to build and support groups, known as tribes, by sharing or recommending information and links from blogs through Twitter, Facebook and LinkedIn. Each member of the tribe, based on common interests, shares their latest blog posts, which other members amplify by sharing them through their own networks. |
| This is a digital content-sharing platform which library users can utilise to share information by pinning images, videos and objects on their boards (like walls in Facebook). Library users and librarians can use Pinterest to share information resources or events. Users can re-pin images from other users’ pin-boards and sharing the information further. | |
| ContentGems | Formerly known as Intigi, ContentGems is a content curation platform through which library users can obtain aggregated content based on specified interests. The content thus accessed can be shared further through RSS feeds, blogs, Twitter and other social media outlets. Library users and librarians can also use the plan to connect to other people with whom they share common interests. |
| Feedly | This is a personalised news aggregator that collects news from a variety of online sources selected by the user. The user is able to customise and share the aggregated news as they wish. Library users and librarians can use Feedly to aggregate and share news items relating to library services and products. Library newsletters and other online publications can be circulated effectively through Feedly. |
| Dizkover | This is a social content discovery platform that enables members to discover popular and interesting items, as voted by other members. The credibility of the votes of members is achieved through a filtering system based on the members’ reputations. The content is organised in channels, which are created or contributed to by the members. Library users can use Dizkover to identify the trending issues in their areas of interest. Researchers, for instance, can use the platform to understand popular research topics and trends. They can also use it to identify credible research information based on the votes of users, preferably in appropriate research channels. Librarians can also use Dizkover to discover the information interests of the library users, based on the votes of the targeted members. They can also use the platform to identify experts on specific issues, based on their Dizkover reputations. These experts can then be engaged as apomediaries or reviewers of relevant information resources and services. |
| Aggregage | This is an automatic content curator, which aggregates information from online sources such as blogs, social media networks, discussion forums and other user-recommended sources. The content is curated based on user preferences, as demonstrated by their usage. Aggregage content is published as specialised topical web sites or online newsletters. Librarians can use Aggregage to curate and disseminate library publications on relevant issues and topics. The librarians can also use the curated content as the nuclei of specialised user communities that can enhance the reach and usability of library services and products. |
| Kweeper | Kweeper is a personalised online library which users utilise to collect and share content such as music, videos, news and other issues of interest. Library users can use the platform to build a personalised digital library that can be used to share with other users in their networks. Similarly, librarians can develop content that can be curated and shared by users on Kweeper. These Kweeper outlets can serve as mini-libraries to extend the reach of specific library services and products. Kweeper can also be used as a channel to market library services and products. It can also be used by librarians to identify the services and products most liked by the users. This information can be used as the basis of important decisions governing the design, development and deployment of library services and products. |
| Flipboard is a platform through which users can create online magazines whose content is curated from various digital sources. The content encompasses anything of interest to the curator. The magazines created through Flipboard can be shared by users with their followers. Librarians can use Flipboard to publish and distribute newsletters cost-effectively. Similarly, library users can utilise Flipboard to curate information of interest from innumerable sources easily. Thus, Flipboard can facilitate the collection and sharing of information on topical issues by library users and librarians. | |
| Zeef | This is a curated and ranked web collection of information created, collected or filtered by experts. The content is organised into subjects by experts who have a deep passion for the issues. Library users and librarians can act as subject experts and contribute or filter content that can be used by other information seekers. They can similarly benefit from content filtered by other experts on subjects of interest to them. In an environment of information overload, Zeef takes the burden of evaluating the credibility of content from the users to committed experts. This increases the speed of credible information searching, retrieval and use. |
| Meddle | This is a content marketing tool enabling the users to add comments on information items of interest. The annotated information resources can then be shared by the commentator through social networking media such as Twitter and blogs. Library users, as experts in the areas of interest, can identify and add value to useful information resources through Meddle. They can also share the enriched information resources with other users in their social networks who may also add their own comments on the resources, further enriching them. Librarians can also point users to credible information by adding relevant comments on the resources. |
| BlogBridge | This is a feeds aggregator which enables its users to discover, organise and read RSS feeds of interest to them. It is useful for persons who have subscribed to multiple RSS feeds and who may find it difficult to filter the content. Library users can utilise BlogBridge to discover valuable content without having to use tedious and less productive search techniques and tools. |
| Trapit | This is a curation application that enables its users to discover, engage with and share relevant content on the web. Trapit’s stated mission is to ‘raise the signal and lower the noise’ through contextual analysis of user preferences. Trapit maintains a vast library of vetted online content sources, which users can retrieve or add to. Trapit users can share the content they glean from the library through myriad communication channels and devices. Research and academic libraries can create Trapit accounts which they can use to select, trap and share credible content with their users. |
Research and academic library users working in 3.0 environments can also utilise a number of social networking solutions to organise the information they generate or use. Some of these may include bookmarking solutions, such as BlinkList, Delicious and StumbleUpon; highlighters, such as Clipmarks, Diigo and iLighter, which enable users to create digital clippings or highlight web content, and Hooeey, and Success Life Share, which can help users to organise their surfing history for research purposes. Other social networking solutions include Evernote, which enables users to capture and share moments or ideas; Instapaper, which can be used to save web pages for later reference; 280Daily, enabling users to summarise their daily activities into 280 text characters; Thoughtboxes, which can be used to organise and store thoughts on issues of interest; Skloog, which can enable research and academic library users to create shortcuts to bookmarks and favourite websites; and Netvibes, which users can apply to personalise their web experience.
Research and academic libraries can also use Quick Reference (QR) codes – two-dimensional barcodes introduced in 1994 by Denso-Wave, a Japanese company – to direct users to library resources such as Uniform Resource Locators (URLs) of electronic data, instructional videos or useful websites, as well as applications or contact information from their mobile phones (Rouillard, 2008; Walsh, 2009). QR codes can also be used to provide virtual reference services through Short Message Service (SMS), directions to a physical library or virtual library tours, context-appropriate information resources, supplementary information, or to store information for future reference as well as other forms of user support at the point of need (Walsh, 2010). QR codes can be stored on library posters, bulletin boards, catalogues, staff directory pages, study-room doors, receipts, magazines or business cards. The use of QR codes removes the need for the user to memorise or type the URL of a resource. The fact that QR codes are scanned using mobile devices, which are steadily becoming ubiquitous in research and academic environments, also makes them handy for library users. QR codes are also decoded fast and save time in obtaining the information or help needed. Further, QR codes are low-cost, are easy to implement and use simple technology (Ashford, 2010). Walsh (2009) identifies a lack of appropriate knowledge and hardware devices (smartphones) to encode and decode QR codes effectively, lack of awareness of QR codes amongst librarians and users, and potential prohibitive data charges on users’ mobile phones as some of the challenges of applying QR codes in most research and academic libraries.
3.1.3. The library is a federated network of information pathways
Library 3.0 tools draw together diverse information sources and platforms to create a robust information network working seamlessly to facilitate fast, accurate and systematic information searching and retrieval (Belling et al., 2011; Chauhan, 2009). The 3.0 platform integrates disparate information channels, formats and environments to ensure availability, accessibility, searchability and usability of credible information (Chauhan, 2009). The search environment thus created is not only integrated but also comprehensive. Library 3.0 supports expressiveness and interoperability to create synergies between hitherto disparate information resources and systems. These synergies are achieved through federation of content, services and user identities enhanced by vertical searching and the interconnection of information islands to create a rich web of information pathways.
Content federation is a way of providing access to information stored in multiple and often disparate systems (Wilson et al., 2012). Research and academic libraries can accrue several benefits from content federation, since it removes the need for migrating information from legacy systems to points of access: rather, it manipulates content in its original location according to specified rules and terms of access. Federation can also help research and academic libraries to eliminate duplication of information resources or services which they can access from already existing sources. Significantly, federation provides a unified search experience through a single interface linking a plethora of content repositories which are interconnected in such a way that they work together seamlessly (Cameron, 2011). This seamlessness involves simultaneous real-time searching of multiple, diverse and distributed sources from a single search page. Federated search systems enable users to search a wide range of resources instantly and overcome the challenges occasioned by different login interfaces (and, perhaps, details); varied search features which display results differently; the need for specialised searching skills and language; and the inability of ordinary search techniques to access the Invisible Web (Belling et al., 2011). Search federators process queries for each of the information sources in a way that matches the source requirements; transmit the queries to all the sources at once; merge all the results obtained from the sources, and present the results together in a unified manner. Federators maintain no indices of their own but rely on the linked system capabilities. This enhances the findability of information. Federation of collections in Library 3.0 is enhanced through cloud computing systems which connect diverse device- and location-independent information tools. Thus information streams seamlessly to the library users from diverse sources with minimal effort from the users. Library 3.0 facilitates federated information searching through open standards, interoperability and extensibility (Libner, 2003). Essentially, the Library 3.0 model enables research and academic library users to search and retrieve information from a single personalised user-friendly interface.
Federation also makes use of stubs or smart shortcuts to link to rich reservoirs of information. Stubs are short programs which act as gateways to larger databases. They receive, process, and forward requests for information to the large databases, which then send back results to the users through the stubs. Undoubtedly, stubs save users time and yield better results, since content is generated and packaged in real time as the end user accesses it. Stubs also enhance the usability of large databases and information systems, which often intimidate research and academic library users.
In addition, service federation occurs in a situation where a group of service providers work closely together to provide a seamless service delivery to their combined customers. A good example of this is international telephony and Global System for Mobile (GSM) communication roaming. The end user of such services has a formal relationship with only one service provider but accesses the other providers seamlessly. Although research and academic libraries have been pooling services through diverse forms of cooperation and collaboration, service federation takes this to a higher level of engagement by providing tools and techniques facilitating the direct involvement of end users.
Also important to ensuring seamless access to rich information pathways in the research and academic library environment is identity federation. This is the provision of systems which enable users to utilise a single profile that is trusted by all the individual identity management systems. This scenario facilitates seamless authentication and interoperability across participating information systems and organisations. Research and academic libraries can achieve this through the establishment of a common set of policies, practices and protocols.
Vertical searching is another emerging technique through which research and academic libraries operating in a federated 3.0 environment can facilitate effective searching and retrieval of information. Vertical search (vearch) engines enable research and academic library users to conduct searches within particular niches and focus on specific segments of online data such as topics, industry, type of data, or location. This facility is quite useful because some of this information may not be found, or may be difficult to find, using conventional search methods. Owing to its guided focus, vertical searching yields greater precision and accuracy of results, which are critical for research and academic library users. One common vearch which is commonly used in research and academic libraries is PubMed. It facilitates searching for medical information resources. Similarly, research and academic library users can utilise the various specialised search facilities provided by search engines such as Google, which include images, maps, blogs, news, books and recipes, among others, to enrich their search experience. Yahoo! Subscriptions, a specialised search engine for premium content which is only accessible through subscription, may also belong in this category of vertical search facilities. However, it covers only general content, such as news and events, not scholarly material. It is noteworthy that while most search engines require users to narrow their searches to get more accurate results, vertical search engines automatically narrow search options for the users. For example, a search for the terms ‘black berry’ in a general search engine will mix results for the fruit and mobile phone. Conversely, a search for the same term on a vertical search engine for technology will yield only results for the mobile device; the same will also apply for a vertical search on fruits, which will yield only the relevant results. Research and academic libraries can also provide field-related search facilities, which restrict search terms to specific metadata fields such as author, title, domain, publisher, type of document, key words or abstract. This also enhances the findability of information, making the process more fruitful for research and academic library users, most of whom bear the burden of information overload.
Ordinary search engines use web crawlers which follow hyperlinks organised through standard protocol. This limits their capacity to locate information which may not be organised or presented using standard protocol. One important facet of web information which eludes such search engines is the ‘Deep Web’ (also known as the ‘Invisible Web’ and ‘Hidden Web’). It comprises content which is not indexed by any standard search engines and is only available to those at the forefront of technology. The Deep Web is perceived to be much more information-rich than the surface web, though estimations of its size vary considerably. Deep Web resources include dynamic content, unlinked content, private web requiring access authentication, contextual web (content varying according to the context of access), limited access content, and scripted content. The Deep Web is also perceived to encourage anonymity, which has led some to suggest that social crime also thrives in it. While ordinary search engines can crawl only the surface web, search federators drill down to the Deep Web, where specialised content resides, and yield high-quality results. Information from the Deep Web is largely primary data, which is extremely valuable in research and academic environments.
Federation can also enable research and academic libraries to connect islands of information (walled gardens) existing in their ecosystems. Islands of information are bodies of information collected incrementally over time by individuals or institutions, but which exist in an environment or format which does not facilitate their sharing or reuse. Islands of information are characterised by a lack of integration where each body of information is unique, used in a localised manner and not influenced by other bodies of information which may surround it. In this sense, islands of information are closed and often lack entry points. Such islands may exist as reports or documents on flash drives, hard disks or CDs, but which are not linked to any other body of information in the immediate environment. Apart from impeding the effective flow of information, these islands also create confusion and duplication (redundancy). Research and academic libraries working in a 3.0 environment add value to these islands by creating ‘continents’ of information by linking the islands together. This creates a rich information ecosystem that facilitates effective information management and sharing. Research and academic libraries can utilise a myriad of social networking and community building tools for this. However, librarians should be cautious and avoid creating monolithic information systems, which may be difficult to navigate.
Research and academic libraries exist in very complex environments. Most users are confused, if not intimidated, by the diverse information options available. The librarians can use federation in the context of the Library 3.0 model to create trusted and clear information pathways which enable library users to locate the information they need, when they need it and in the most appropriate format (Fulton, 2010). As discussed above, federation provides multiple pathways to information created, generated or stored in various collections and organisations. The pathways have signage which can aid information exploration, identification and use. It is also noteworthy that federation enables the institutions to remain independent and stable even as they support common access to the content they hold. This federated autonomy enables institutions to keep track of their documents and enhance their integrity. Federated content is analysed semantically and combined in ways that promote its access and use. This saves on cost, boosts productivity and enhances competitive advantage.
Just like any other library technique, federation faces many challenges. Some of these are: difficulty with authentication (exposing each other’s copyrighted content, licenses, subscription); the realisation that true de-duplication is impossible; security challenges emerging from difficulties in mapping user credentials and access rights for each database; sometimes federated searches may take a little longer and this may not be suitable for modern library users who want fast service; lack of standardisation (each data source has its own language and needs translators to ‘talk’ to the other sources); access to some sources may change, requiring rewriting of codes; lack of standardisation of error handling (query term not available or connection timeout); complex relevancy scoring approaches; and user frustration, since some documents shown in the results may still not be accessible even after they are found (Curtis, 2009).
3.1.4. The library is apomediated
Apomediation is a new scholarly socio-technological term that characterises the process of disintermediation. Intermediaries are middlemen or ‘gatekeepers’, for example, health professionals giving ‘relevant’ information to patients, and ‘disintermediation’ means that they are bypassed. The former intermediaries are functionally replaced by apomediaries, that is, network or collaborative filtering processes (Eysenbach, 2008 [WebCite] and 2007b). The difference between an intermediary and an apomediary is that an intermediary stands ‘in between’ (Latin ‘inter-’, ‘between’) the consumer and information or a service, and is seen as absolutely necessary to get that information or service (Table 3.2). Intermediation has also been observed to affect the quality of the information users receive, because it is influenced heavily by the qualities of the intermediary. In contrast, apomediation means the action of agents (people, tools) who or which ‘stand by’ (Ancient Greek ‘apo’, ‘separate, away from’ and Latin ‘mediare’, ‘to mediate’) (Eysenbach, 2008; O’Connor, 2010) to guide a consumer to information or services or experiences of high quality, without being a prerequisite to obtain the information or service. The switch from an intermediation to an apomediation model has broad implications, for example, for the way people judge credibility, as hypothesised and elaborated elsewhere (Eysenbach, 2008). Apomediation seeks to bridge the gap created by disintermediation, the elimination of intermediaries in the information demand and supply chain, which implies that users may get lost in the vast reservoirs of information available in the infosphere. Users who lose their way in the infosphere may end up accessing inaccurate information, leading them to wrong conclusions and application. Apomediaries offer guidance to users to obtain trustworthy information using less traditional methods or sources. Essentially, apomediation is a shift from the reliance on gatekeepers to networked approaches for identifying, locating and using trustworthy information.
Table 3.2
Comparison between modes of mediation in libraries
| Attribute | Type of mediation | ||
| Intermediation | Disintermediation | Apomediation | |
| Philosophy | Standing between | Standing aloof | Standing by |
| Power (control) | Mediator | None | All participants |
| Guidance | Mediator | Crowd | Self |
| Mode of learning | Transfer (rich to reach) | Imitation | Diffusion |
| Quantity of knowledge | Scarcity | Overload | Abundance |
| Relationship | Hierarchical | Casual | Ambient intimacy |
| Mode of operation | Match-making | Creative chaos | Serendipity |
| Partnership | Cooperation | Coexistence | Collaboration |
| Type of knowledge | Impersonal | General | Personal (original) |
| Flexibility | Rigid | Chaotic | Flexible |
| Redundancy | Centralised | Decentralised | Distributed |
| Safety | Fear (of authority) | Uncharted | Trust |
| Costs | High | Medium | Low |
| Time for learning | Long | Medium | Short |
| Transparency | Low | Medium | High |
| Direction of learning | Upstream | Midstream | Downstream |
| Applicability | Prescriptive | Speculative | Experiential |

Eysenbach (2007) explains that apomediaries are tools and peers standing by to guide users to trustworthy information. Although apomediaries broker the interaction between information seekers and the information, they exercise no direct power over the information or how it is utilised by the users. They only guide users through their own self-directed activities. They are detached from the process and offer help only when and where it is needed. Apomediation, says Eysenbach, thrives in an environment where library users exhibit higher levels of maturity and autonomy, enabling them to appraise and contribute credible content. Therefore, apomediation can be mainstreamed in libraries by increasing information literacy through sustained user education and empowerment.
With the rising popularisation of social networks in which content is passed along by users, any user can act as an apomediary or informal knowledge broker, although the credibility and quality of information will vary (Eysenbach, 2008). One of the key qualities of an apomediary is trustworthiness, which Eysenbach (2007) suggests is bestowed by peers and opinion leaders. He further explains that in an apomediated environment, apomediary credibility is more important than source or message credibility. This concept seems to support the view of librarians that library users left alone, through disintermediation, may not make the best use of the library systems. Apomediaries do not leave users alone but also do not stand in between them and information. Apomediaries stand by users and guide them to information and services of high quality, without being overbearing (Eysenbach, 2008). The application by users of the advice, intervention and direction of apomediaries is largely optional. Apomediaries can influence action without being there in person or having a stake in the issue; they are peripheral mediators – hence ‘apo’ (‘distant’).
Apomediation signifies subtle content-filtering processes and techniques which lead library users to readily access authoritative information. Apomediaries provide cues and meta-information which enable information users to navigate the infosphere and locate credible information. Thus, apomediaries direct users from valueless information sources through a combination of collaborative and distributed tools and techniques that facilitate learning. Hetland (2011) explains that apomediation involves a voluntary collaboration between experts and amateurs in the generation, location, access and use of credible information. O’Connor (2010) suggests that social media play a significant part in apomediation.
Sapp and van Epps (2006) explain that librarians can apomediate by placing ‘hints’ that can lead the users to the right information pathway. Although apomediation is largely driven by peers, a librarian in a Library 3.0 environment can take up the role of apomediary as well. The role of a librarian in an apomediated environment has changed from gatekeeper to guide. One of the ways in which librarians can act as apomediaries in the Librarian 3.0 context is by offering help at the ‘point of failure’ (Saw and Todd, 2007). Librarians can also enhance apomediation by creating systems which enable users to locate credible information with least support, using various forms of signposting. Having been intermediaries, most research and academic librarians stand a good chance of being good apomediaries as well.
There are multiple apomediaries in any apomediated environment, hence the assertion of Schultz (2006) that in the Library 3.0 context, library users not only select information sources but also identify librarians who have the potential for and a history of consistently meeting their information needs. It is probable that the principles of natural selection may apply in apomediated environments, as credible apomediaries thrive while the less credible ‘die away’ naturally from lack of use.
Apomediaries do not have to be technical experts on the subject in question. At times, they may be persons who have experienced the situation at first hand. In health, for instance, an apomediary may be a survivor of a health condition. Such a person would offer valuable information to other persons with the same condition. This information is original and based on experience, making it more applicable and practical for people who are in situations similar to that of the apomediary. In the research and academic library environment, apomediaries could be classmates, researchers working on similar topics, laboratory technicians who have supported similar research or a librarian who has supported a similar information search or has the know-how to do so. The use of a networked and participatory review of information sources as opposed to expert review, as the case is in peer review, is also a form of apomediation. This approach enables the potential users of information to provide input in evaluating the suitability of particular information sources for them. Such an open review may go beyond an evaluation of the content only to other preferred elements such as form, size or usability of a good information source. One of the most common strategies of achieving participatory review in apomediated environments is tabulated credibility, which applies peer-generated ratings or recommendations of information sources.
Librarians can also apply the concept of infodemiology to identify and respond to users’ information needs. Infodemiology, also borrowed from the health discipline, is the science of the distribution and determinants of information in an electronic medium with the aim of informing users about public health policy. Eysenbach (2009) explains that health professionals can utilise infodemiology applications to analyse queries in search engines or monitor status updates on social media to predict disease outbreaks. Research and academic librarians can utilise similar approaches to determine most-searched-for key words or status updates to identify prevalent information needs. Infodemiology can also be used to identify points of failure in the information searching and retrieval process. This information can be used to evaluate how well the information needs have been met or otherwise and form the basis for any apomediation interventions.
Although O’Connor (2010) argues that apomediaries normally feel a sense of obligation to correct wrong information in their sphere of apomediation, information users are advised to confirm any information or recommendation obtained in an apomediated context before adopting it. Personal relevance as well as correct interpretation and contextualisation are all important elements that determine the usability of any apomediated information.
Concerns that apomediation may create a new information divide have been expressed (Keselman et al., 2008; Casilli, 2011). These concerns have been based on the fear that apomediation can create closed communities which may not just hoard information but may also use it unethically. Therefore, libraries adopting apomediation should create and sustain effective multidirectional information loops that are inclusive and transparent. These would facilitate the generation, use and reuse of abundant information.
The future relationship between intermediation and apomediation in research and academic libraries is still unknown. It is not possible to predict whether apomediation will ultimately replace intermediation completely. In the short term, however, it is expected that most research and academic libraries will adopt apomediation and less intermediation or disintermediation.
3.1.5. The library is ‘my library’
The need to personalise library services, as a means of satisfying user needs effectively, has been constant in the history of libraries. Because of the relatively small numbers of users they served, librarians in former times perhaps just tried to remember the face and interests of each user and endeavoured to offer as much personalised service as was then possible. However, the need for deeper personalisation has become more apparent in the recent past owing to the emergence of information technologies, which have provided greater opportunities for librarians to tailor services and products to the users.
One of the approaches in personalising library services was the ‘MyLibrary’ concept, which emerged in the early 2000s. It was triggered by users’ demands for greater levels of personalisation in a similar style to that of the services that various service providers such as search engines (MyYahoo!) and the media (MyCNN) were offering their clients on various Internet platforms. These digital platforms provided users with an environment to personalise the services through unparalleled customisation, interactivity, interfaces and user support (Sanchez et al. 2001). Because library users became accustomed to getting such customisable services, they began to demand similar services from the library (Cohen et al., 2000). They wanted library services which were uniquely tailored for their personal needs and circumstances while still giving them the opportunity to interact with other library users and to form or join groups to enrich their library experience (Storey, 2004).
Personalisation of library services is achieved through the design, management and delivery of content based on known, observed and predictive information. Sanchez et al. (2001) explain that personalisation enables users to create, own and maintain individualised information spaces which contain multiple media, own devices, personal schedules, visualisation tools and other user agents. Frias-Martinez et al. (2009) add that personalisation of library services is achieved through adaptability and adaptivity mechanisms. They maintain that adaptability mechanisms enable users to adapt the content, layout and navigation support to their preferences by themselves, while the adaptivity tools facilitate library systems to automatically adapt to the needs and interests of users, based on observed user behaviour.
Library 3.0 is the culmination of the efforts of librarians to facilitate library users in personalising library services, spaces, products, staff and experience. Library 3.0 tools enable librarians and library users to create appropriate personal and professional profiles that help to tailor library services and products to their own needs. Some of the personalised services may not even be official or universal (Cohen et al., 2000). On the Library 3.0 platform no two users are exactly the same and neither can their usage be. Personalisation recognises the reality that a librarian cannot organise library resources into categories that are intuitive for every user. Apart from fitting the library into the lives of the users more accurately, personalisation also helps users to filter information and cope with the information overload (Storey, 2004); facilitates accurately-targeted marketing of library products, services and staff (Cohen et al., 2000); enables research and academic library users, especially students, to move seamlessly from personal to group spaces and between group spaces (Sanchez et al., 2001) with their personal library ‘effects’; stimulates loyalty by transforming the users into long-term faithful partners (Holmström, 2002); and assures personal and professional privacy and thus enables the users to control their space (Holmström, 2002).
Library 3.0 systems apply adaptability and adaptivity mechanisms such as adjustable user interfaces and mechanisms to configure systems to users’ preferences, as well as customised system updates to offer enhanced personalisation of library services, space and products. Other common tools to personalise user experience in research and academic libraries include applications that facilitate portable hyperlink bookmarking; personalised current awareness, alerts, reminders and bulletin boards; customisable user interfaces; personal online pages; individualised search profiles; and integration of library spaces with other personal communication suites on email, Facebook, chat or Twitter platforms. Cloud computing technology (library in the cloud) can also be used in a 3.0 environment to personalise library services. This is because cloud technology is changing the way people read, store, use or share data. For instance, cloud technology enables portable devices like mobile phones which have less storage and processing capacity to act as powerful machines in the hands of users. Furthermore, cloud computing enables users to synchronise their data regardless of the access device they use. For example, if a user is reading a book from Amazon on one device and changes to another, the same book is opened on the same page (Hoivik, 2012). Cloud computing also removes the burden of complex and expensive system acquisition and configuration from the shoulders of small libraries. Thus cloud computing is taking anywhere, any time access to library services to another level, and offers greater potential for realising it.
On one hand, personalisation in research and academic libraries inculcates user loyalty, enhances user control, improves user participation self-sufficiency, facilitates better understanding of users’ needs and how to meet them effectively, introduces flexibility, facilitates cost-effectiveness in delivering services, improves usability, and enhances user satisfaction. On the other hand, personalisation can be costly, may trigger unrealistic user demands, and may expose the library to more risks.
3.2. Comparing Library 3.0 with the other library service models
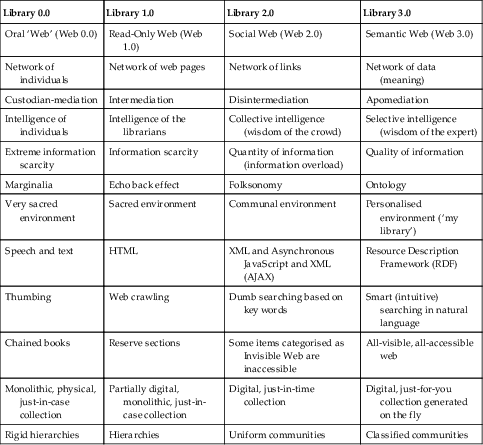
As mentioned in Chapter 2, four main library versions – Library 0.0, Library 1.0, Library 2.0 and Library 3.0 – have emerged so far. It is generally accepted that Library 0.0 and 1.0 models represent the conservative traditional library in which users are passive. Library 2.0 represents a major departure from the conservative library service model and emphasises the participation of users to the extent that librarians are eclipsed. Library 3.0 in some respects seems to be a hybrid between the 1.0 and 2.0 models and reasserts the role of librarians in the information value chain as apomediaries. Apart from the above four models, Library 4.0, dubbed ‘the aesthetic library’, is currently being mooted. Schultz (2006) explains that it will be a luxurious ‘WiFree’ space for meditation, relaxation and the generation of ideas. There is general consensus that none of the library service models can entirely replace the others. Rather, they complement and absorb one another.
Nonetheless, there are remarkable differences between these library service models and Library 3.0. Here is a summary of some of these differences:
3.2.1. Library 0.0 and Library 3.0
On one hand, Library 0.0 is the oldest and most common library model. It is conservative and traditional and exhibits minimal application of technology. Its performance is largely defined by just-in-case monolithic physical collection and site-based service. Library 0.0 users rely heavily on librarians to mediate access and use of the services and products. Library 0.0 applies rigid routines within established hierarchies, structures and procedures. The Library 0.0 space is ‘sacred’ and total silence is expected therein. On the other hand, Library 3.0 is just emerging and has yet to gain common acceptance. It uses a wide range of technology applications and tools to create a networked environment in which library services are offered through apomediation. Library 3.0’s virtual and physical spaces are defined largely by the users, who sometimes share or personalise them depending on the prevailing need. The use of the physical or virtual Library 3.0 spaces is varied and liberal; for example, noise zones are provided. In spite of their differences in approach and history, both Library 0.0 and Library 3.0 emphasise credibility of information.
3.2.2. Library 1.0 and Library 3.0
Library 1.0 applies the read-only Web 1.0. Although it is traditional and conservative in approach, Library 1.0 exhibits minimal digitisation of library services and products offered through varying degrees of intermediation. This library service model emphasises the expertise of the librarians and limits user participation to negotiating queries within defined boundaries between users and librarians. The services and products offered in a typical 1.0 library are fixed with clear terms of use. Typical 1.0 libraries maintain monolithic proprietary systems as well as linear and hierarchical processes. The focus of services in Library 1.0 is on information resources, not information. The services are delivered uniformly (one size fits all). In contrast, Library 3.0 applies Web 3.0 which offers the users diverse opportunities to contribute to the library services and products through apomediation. There are no fixed boundaries between the spaces and roles of users and librarians in a typical Library 3.0 environment, which facilitates seamless collaboration in meeting the needs of users. Library 3.0 collections are fluid, distributed and often generated on the fly by users, experts and librarians through apomediation anchored on multidirectional processes. Both models emphasise the quality of information and have mechanisms to ensure users access and utilise only credible information sources, albeit differently; in 1.0, through intermediation and in 3.0, through apomediation.
3.2.3. Library 2.0 and Library 3.0
Library 2.0 is very close to Library 3.0, except that the former is anchored on disintermediation, while the latter works through apomediation. Similarly, Library 2.0 provides a network of hyperlinks to information sources retrieved through key words, while Library 3.0 provides links to meaningful data identified through smart searching approaches. Library 2.0 thrives on abundant quantities of information, while Library 3.0 focuses on the quality of information. Nonetheless, both library service models facilitate user participation and innovative dynamism, as well as the development and use of collaborative communities. They also use a combination of liberal virtual and physical spaces. Both library service models use just-in-time library collections which are largely in digital format.
Table 3.3 summarises some of the similarities and differences between library service models.
Table 3.3
Comparison of library service models
| Library 0.0 | Library 1.0 | Library 2.0 | Library 3.0 |
| Oral ‘Web’ (Web 0.0) | Read-Only Web (Web 1.0) | Social Web (Web 2.0) | Semantic Web (Web 3.0) |
| Network of individuals | Network of web pages | Network of links | Network of data (meaning) |
| Custodian-mediation | Intermediation | Disintermediation | Apomediation |
| Intelligence of individuals | Intelligence of the librarians | Collective intelligence (wisdom of the crowd) | Selective intelligence (wisdom of the expert) |
| Extreme information scarcity | Information scarcity | Quantity of information (information overload) | Quality of information |
| Marginalia | Echo back effect | Folksonomy | Ontology |
| Very sacred environment | Sacred environment | Communal environment | Personalised environment (‘my library’) |
| Speech and text | HTML | XML and Asynchronous JavaScript and XML (AJAX) | Resource Description Framework (RDF) |
| Thumbing | Web crawling | Dumb searching based on key words | Smart (intuitive) searching in natural language |
| Chained books | Reserve sections | Some items categorised as Invisible Web are inaccessible | All-visible, all-accessible web |
| Monolithic, physical, just-in-case collection | Partially digital, monolithic, just-in-case collection | Digital, just-in-time collection | Digital, just-for-you collection generated on the fly |
| Rigid hierarchies | Hierarchies | Uniform communities | Classified communities |
3.3. The potential of Library 3.0 for research and academic libraries
Research and academic libraries provide platforms for research, study, social activity and discovery. These libraries currently face the challenge of having to meet the needs of more users with less time and fewer resources. The situation is exacerbated by the increasing quantity of content in the research and academic infosphere. Consequently, research and academic libraries now have to prove their value to their institutions more than ever. Library 3.0 offers research and academic libraries tools and approaches that have the potential to enable librarians to meet and even exceed the expectations of users. To realise it, librarians must be ready to explore the potential of this new model and be unafraid to try it in their libraries. Some of the potential benefits of Library 3.0 to research and academic library communities are discussed in the sections below.
3.3.1. Personalisation
Library 3.0 gives research and academic libraries the tools and approaches to offer personalised services to their users. Personalisation enables libraries to offer services that are tailored to match specific user needs. This benefit is achieved, for instance, through personalised content, context and user interface. Personalisation in the Library 3.0 environment is also achieved through the provision of customisation tools, which enable users to create profiles and experiences which are unique to their needs and preferences. Library 3.0 also provides adaptable and adaptive systems that facilitate personalisation with minimal intervention from users or librarians. Such systems learn the preferences of the users and automatically make provisions for meeting them. 3.0 libraries also achieve personalisation by allowing users to bring and plug in their own devices. This provides an integrated experience that takes care of the users’ personalised data, history, preferences and interests. Those research and academic libraries that have embraced the Library 3.0 model do not treat their users as ‘masses’, but as individuals with specific needs and preferences. Personalisation moves library services and products from just-in-case through just-in-time to just-for-you paradigms. This approach does not only create user loyalty but also enhances the effectiveness of these libraries in meeting the information needs of the users and generating a favourable return on investment. Offering personalised services in research and academic libraries also provides a means of combating information overload and leads to improved productivity.
3.3.2. Convenience
Convenience is a significant information choice factor in the emerging research and academic library environment. Most research and academic library users want to access and use library services and products with minimal effort. The need for convenience has been compounded by the abundance of information that is steadily inundating research and academic library users. Griffiths and King (2008) explain that convenience is one of the four critical criteria information seekers use to choose a resource. They identify the other three as cost, quality and trustworthiness of the information resource. Connaway, Dickey and Radford (2011) explain that anecdotal evidence seems to suggest that information seekers can sacrifice quality of content to convenience of use. They further point out that this seems to be especially so with younger information seekers. Griffiths and King (2008) conducted a user study, which revealed that library users commonly chose the Internet as an information resource based on its perceived convenience of use rather than the quality of its content. A similar conclusion was reached by Hardesty (2000), who averred that students often accept convenient information, whether appropriate or not, at the expense of relevant but less convenient information. Lee, Hayden and MacMillan (2004) explain that some students find reference services offered in public spaces inconvenient. Such students do not feel free to ask their questions candidly. They recommend that library services should be delivered in convenient locations that are not only accessible but also private.
Convenience in research and academic libraries can be enhanced by improving users’ familiarity with the information resources, perceived ease of use, and physical proximity, among other factors. Library 3.0 tools and techniques provide research and academic librarians with the means to make their services and products conveniently accessible to users. Convenience in 3.0 platforms is achieved through portability of services, provision of seamlessly integrated services, simplification of services and products, physical proximity, comfort in physical library facilities, self-service functionalities, personalisation and library service features which enable multitasking. The provision of convenient services in research and academic libraries has the potential to enhance the usage and effectiveness of these libraries. It also has the potential to make the libraries the preferred information destination for researchers, students and academic staff – not just a last resort – knowing that they often have time constraints and alternative information sources competing with the libraries. Convenient library services also cut the costs to the users of accessing the services and project the library as responsive and caring.
3.3.3. Enhanced findability
Findability can be defined as the ability of library users to locate the information they are looking for. It is the quality of information resources of being locatable or navigable; the degree to which a relevant information resource is easy to discover and retrieve (Morville, 2005b). Findability is improved through appropriate information architecture and user interface design. Findability provides intuitive interaction between potential users of information and the resources they are interested in through multiple pathways tailored to the specific users and uses.
It is a given that only information resources that can be found stand a chance of yielding any value for their potential users or providers. If a resource cannot be found, then it is essentially worthless, regardless of its intrinsic value. Consequently, the findability of relevant information is becoming increasingly important as the amount of available information increases. Findability is a critical concern in research and academic libraries, since they hold, or provide access to, huge collections of digital and physical information resources. Consequently, many library users spend most of their time searching through the clutter of information unsuccessfully, or even replicating information that already exists, just because they are not aware of it. Similarly, users spend a lot of time reviewing large sections of information resources, only to discover that they are irrelevant. Thus, library users spend the least time undertaking the primary objective of using a library – consuming the right information.
One of the important determinants of findability is precision, which is defined as the fraction of all the retrieved information resources that are relevant to the specific information need. Effective findability leads to high precision. Also important to findability is recall, which is measured by the fraction of the documents relevant to a query retrieved, compared to all available relevant documents. Take, for example, a student searching for information on climate change in an institutional repository that has fifty relevant documents. If the search yields forty documents, of which only twenty are on the subject, then the precision of the search is 20/40, which is the number of the relevant documents retrieved divided by the number of all the documents retrieved. Precision is the probability that a retrieved document is relevant. The recall of the search, however, is 20/50, which is the number of the relevant documents found divided by the number of all the relevant documents which should have been found. Thus, recall is the probability that a relevant document will be retrieved by a query from a pool of resources. The findability of information resources is enhanced by using appropriate pointers; presenting the information in the format most suitable to the users; taking information to where the users already ‘hang out’, which are also the locations (physical and virtual) in which most valuable information connections are likely to be made; as well as linking all available information resources – including the Invisible Web – and giving them a chance to be found.
Library 3.0 has the potential to bring to realisation what Morville (2005a) calls ‘ambient findability’, which is the ability to find anything and anyone at any time, anywhere. Library 3.0 also puts libraries at the centre of ambient findability by facilitating the work of users in finding what they need – whether digital, physical or in between – through superior search approaches; information organisation, categorisation and labelling; federation and interlinking of resources, institutions and individual users; serendipitous connectability. Mishra (2009) describes the latter as unpredictable or random connection of all formats of content and users, both online and offline, in emotionally powerful ways; a rich discovery environment facilitated by multiple mechanisms to find out and link library information and users; and social recommendation and exploration of information.
Mishra (2008) also discusses the concept of practical obscurity, which seems to be the opposite of ambient findability. Practical obscurity, he says, is the perception of some that whatever anyone does, even in public, remains private, because there are too many people to track down individually. He points out, however, that the emerging findability enablers in the current connected generation have reduced the viability of practical obscurity. He cites the Internet as one of the technologies which renders practical obscurity impractical by enabling the sharing of personal details, views and feelings in the form of text, photographs, video or status updates on social media and other digital platforms. For instance, one can get very intimate information from individual Facebook walls, where many people share anecdotes of their love life, anxieties, heartbreaks, schedules and excitements. Similarly, friends and strangers who access these platforms connect to these people’s emotions as if they knew them personally. Unfortunately, such information and the results of such connections, once digitised and disseminated, may never be removed easily from cyberspace.
In spite of the prevalence of these seemingly ubiquitous connectivity enablers, some of their ‘side effects’ actually hamper findability. One of these is the concept of the ‘echo chamber’. This is the content recommendation system based on past use, which just ‘echoes’ back to the user their own ideas and opinions, instead of bringing something new. This ‘echo back’ effect restricts the world view of the individual and keeps them chained to the same set of ideas, people and resources. The echo effect creates ‘walls’ which separate information users and resources instead of linking them. Fernandes (2011) explains that the echo effect results in people creating safe bubbles around themselves, in which only their preferred information resources and ideas are constantly echoed to them, and thus excluding the vast sets of alternatives. Essentially, people surround themselves with familiar people, ideas and perspectives. This creates less permeable walls, which restrict the discovery, learning and sharing of new information or ideas. Library 3.0 counters the echo effect by providing connectivity platforms, which encourage the generation, application and perfection of diverse ideas, perspectives and orientations.
3.3.4. Content credibility
Credibility is the measure of believability of an information source. Credibility is expressed through qualities such as trustworthiness and expertise. The credibility of information resources encompasses quality exemplified through accuracy, comprehensiveness, ease of use, format, authority and timeliness; contextualisation; scholarly corroboration; and plausibility demonstrated through approval and acceptance, auditability, objectivity and relevance. In this era of relative ease of publishing, research and academic library users have to constantly deal with serious content credibility crises. They constantly have to make judgments about whether the information resources they access are useful or relevant to their needs, and how much so.
Libraries have traditionally encouraged the use of credible information resources by establishing and promoting the application of credibility evaluation criteria (authorship, purpose, objectivity, novelty, convenience of use, reasonableness, currency, relevant and verifiable references, reliability, balance, coverage and publisher, among others), direct mediation by librarians, cross referencing, rigorous collection selection procedures, expert review or a combination of most – if not all – the strategies above. Research and academic library users are increasingly seeking and applying credibility evaluation approaches that are simple but productive.
Library 3.0 provides platforms that allow the credibility of information sources to be evaluated constantly through a combination of social (peers) and expert (technical experts and librarians) dimensions. This evaluation is enhanced through the establishment of social networks and putting members in specialised groups (bounding), which enables them to make evaluative judgments and verify the credibility of information resources in their domains. Similarly, such platforms enhance the participation of members, who feel obligated to correct any errors. These platforms are also considered by their members as the safe and trusted spaces from which most of the participating members begin their information-seeking before venturing to other locations. These spaces are not necessarily filled by professional peers; some comprise family members or social acquaintances. It is also becoming apparent that most users find it more efficient and productive to ask for information from trusted persons than other sources. Asking human sources for information is also natural and saves the time of the information seekers. These users are learning from experience that it is actually harder to get credible content from the other sources and are steadily turning to trusted human sources. This realisation concurs with the findings of the information-seeking behaviour studies conducted at the University of Bath in the United Kingdom in the 1970s, which concluded that researchers trust colleagues and informal information channels more than other sources of information (Canavan, 2003). Librarians working with Library 3.0 tools and techniques should strive to be among these trusted human sources of information for researchers, academic staff and students using research and academic libraries. The librarians should use Library 3.0 tools and techniques to provide timely services so as to keep the users from sacrificing content credibility by resorting to fast but potentially untrustworthy sources. As Lankes (2007) suggests, librarians should realise that human beings did not progress from the Stone Age because they ran out of stones but because better tools emerged. Sticking with the traditional tools is like trading modern tools such as iPods for stone or bone artefacts. Unreasonable as it may seem, many librarians are still holding on to their ‘stones’ in myriad ways.
3.3.5. Fast service
As discussed elsewhere in this chapter, research and academic library users are very concerned about the speed and convenience of service, to the extent that in some circumstances they are willing to compromise the quality of information resources in favour of increased speed of access. The need for fast library services is growing because users, especially part-time researchers or students, have limited time to devote to library usage. Librarians have become aware that they need to help save the time of users now more than ever. Research and academic library users, just like other library users, desire and appreciate instant gratification. Therefore the speed of service is one of the key determinants of how effectively research and academic libraries meet their vision and mission.
The Library 3.0 model offers research and academic libraries tools and techniques that facilitate the fast delivery of library services and products. Such tools and techniques include library outreach services, enabling user access to library services anywhere and at any time; seamless connectivity to library materials and to other users using personal devices; stable library services facilitated by distributed systems riding on cloud computing; enhanced searching, findability, retrieval and use of credible content, which save the user’s time; digitisation, which enables better storage, findability, sharing and reuse of library collection; content generation tools harnessing the potential of prosumption; integration of human sources to offer pinpointed information services through apomediation; the formation and use of versatile communities facilitating collaboration between empowered users and service providers, and inclusion of specialised tools as add-ons (for search, web content organisation, shortcuts, link checking and citation management) in common web browsers as a means to facilitate fast access to the services.
Similarly, the Library 3.0 approaches enable research and academic libraries to reduce what Mellon (1986) describes as ‘library anxiety’, which is exemplified by users being intimidated by the sheer size of a library, as well as a lack of knowledge about how to locate relevant resources and services. Library users experiencing library anxiety basically do not know how and where to begin using their libraries and generally exhibit high levels of feelings of inadequacy and inferiority (Onwuegbuzie, Jiao and Bostick, 2004). The use of the Library 3.0 model also enables libraries to simplify their services and thus boost user confidence in accessing library services effectively. Further, the provision of personalisation features enables anxious users to create services with which they are comfortable. Personalisation, through Library 3.0, also provides safe virtual or offline spaces in which users can work privately, at their own pace and with ease. Reduction of library anxiety increases speed of access to library services.
3.3.6. Infotainment
The term ‘infotainment’ emerged in the broadcasting industry and is a portmanteau word made from ‘information’ and ‘entertainment’. It is used to denote material that is intended to both inform and entertain in an effort to enhance popularity with audiences (Stockwell, 2004). Several audience studies indicate that infotainment media channels and programmes are more popular with audiences and attract a higher number of adverts than ordinary news channels (Graber, 1994; Brants, 1998; Anderson, 2004).
The term was seemingly first used in librarianship in September 1980 at the inaugural joint conference of the Association of Special Libraries and Information Bureaux (ASLIB), the Institute of Information Scientists and the Library Association in Sheffield, United Kingdom, by a group of British information scientists – calling themselves infotainers – who presented a comedy show at the professional conference, ostensibly to provide fun and levity (Tara, 2008).
The rise of infotainment stems from the fact that library users are no longer drawn by library collections or space alone. Conversely, they are drawn by the experience offered by the virtual and physical spaces of a library in which it is comfortable and fun to work. This gratifies their need for adventurous and engaging library experience. Infotainment is also anchored on the understanding that library services or products are not commonly consumed in isolation. Library users are social in their day-to-day lifestyles and many would like a social experience in the libraries. Based on the understanding that books and coffee go together just like movies and popcorn, library users desire to maximise their library presence by seeking both information and entertainment. Libraries that offer such an experience are used effectively. For instance, Rippel (2003), citing North, Hargreaves and McKendrick (1999), explains that having slow background music in reading areas draws more users to libraries. Library 3.0 enables libraries to create infotainment zones with television sets, piped music, video games, audio visual facilities, comedy shows, puppetry, instructional videos, slideshow screenshots, storytelling, 3-D animations and social meeting areas with comfortable furniture which have the potential to increase the number of visits to research and academic libraries. Library 3.0 tools can also facilitate the use of assistive technologies, such as the provision of magnifying lenses in reading areas, scanner readers for converting text to computer-generated audio, audio loops for users who need hearing aids, and adaptive workstations with height-adjustable furniture, which enhance the comfort of using the library materials or space.
3.3.7. Effective marketing
The realisation that libraries cannot merely operate from a come-and-get-it environment emerged several years ago. Kumbar (2004) explains that as early as 1876, Samuel Swett Green, a founding figure of the American public library movement, was advocating improved personal relations between librarians and readers. Nonetheless, this ‘marketing’ concept did not gain wide popularity among librarians because it was viewed negatively (Lindsay, 2004; Singh, 2009). Kumbar (2004) explains that the negative perception of marketing in libraries may be attributed to the assumption that marketing is manipulative, unprofessional and unnecessary; in many cases, marketing was mistakenly thought to be synonymous with advertising. The situation was exacerbated by the fact that most libraries did not have the resources to support marketing initiatives. Boden and Davis (2006) assert that the situation is changing gradually owing to the realisation that, in the face of the myriad competing alternative sources for supplying information, the marketing of libraries is no longer a luxury but a necessity. Marketing implies a purposive endeavour to understand the needs of present and potential users and comprehensive knowledge of the characteristics and limitations of products developed for the market. Deliberate and sustained efforts should be made to reach out to the potential library community, create an awareness of the services available and ensure the effective use of library resources through a variety of approaches (Schmidt, 2007). Consequently, a growing number of research and academic libraries are creating marketing functions in their staffing structures, with some even employing full-time marketing personnel. The need to market libraries, in the fuller sense defined above, will continue to grow and become more apparent as external competition and internal expectations steadily rise.
The Library 3.0 model provides a platform through which library users and librarians are able to market (partnership marketing) library services and products by word of mouth, especially through social media, relationship marketing, liaison and engagement, branding and outreach, as well as targeting of services, thus raising the library’s profile and creating awareness of its services. Similarly, the Library 3.0 model enables libraries to offer competitive services which attract and retain more users; to expand the resource pool available to the library, for instance, by inviting users to bring their own devices and thus assisting the library to offer its services cost-effectively; supporting users to optimise their library usage through apomediation and personalisation; projecting a new image as a progressive, caring and innovative institution and thus breaking from past negative stereotypes; enhancing the visibility of the library and capitalising on its ability to provide a good information experience, which is superior to Google, and presenting libraries as indispensable institutions in modern society.
3.3.8. Rebirth of librarians
The debate on whether or not librarians are still relevant in the modern infosphere has been ongoing for some time now, with some people suggesting that libraries and librarians have actually become obsolete in the wake of the information revolution; typical of this is the view propounded in 1979 by Dennis Lewis (1980), then head of ASLIB. Proponents of the view that libraries are becoming obsolete justify it by pointing to the fact that some libraries are being closed. It is noteworthy, however, that most of the libraries that have been closed are public libraries. It is also noteworthy that while some libraries are being closed, others are being opened. Therefore, the notion that closure of libraries is a global phenomenon is not entirely accurate. Nonetheless, some libraries – including research and academic libraries – are under threat of closure owing to lack of adequate funding, competition from alternative information sources, rising user expectations and technolust, as well as a growing need for value-added services and products.
The Library 3.0 model offers librarians tools and techniques to grow the value of libraries as a means of professional survival. In some respects, it provides alternative ways for librarians to continue to exist and play emerging roles as apomediaries providing stress-free, effective and simple access to credible information from the existing vast, but largely inappropriate, content in the infosphere. The Library 3.0 model provides options beyond the traditional books, collection development, lending and borrowing or rigid physical spaces that were the hallmarks of previous library service models. To maximise the potential a Library 3.0 environment offers, librarians should have a passion for service excellence, self-motivation and initiative. They should also be flexible, collaborative, teachable and liberal. They need to realise that information searching and use in modern research and academic libraries can no longer be directed but should be guided. They can work in the new environment as trusted human sources.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.