
The Linux Kernel
The core of the Linux system is the kernel. The kernel controls all of the hardware and software on the computer system, providing access to hardware when necessary, and executing software when required.
If you’ve been following the Linux world at all, no doubt you’ve heard the name Linus Torvalds. Linus is the person responsible for creating the first Linux kernel software while he was a student at the University of Helsinki. He intended it to be a copy of the Unix system, at the time a popular operating system used at many universities.
After developing the Linux kernel, Linus released it to the Internet community and solicited suggestions for improving it. This simple process started a revolution in the world of computer operating systems. Soon Linus was receiving suggestions from students as well as professional programmers from around the world.
Allowing anyone to change programming code in the kernel would result in complete chaos. To simplify things, Linus acted as a central point for all improvement suggestions. It was ultimately Linus’s decision whether or not to incorporate suggested code in the kernel. This same concept is still in place with the Linux kernel code, except that instead of just Linus controlling the kernel code, a team of developers has taken on the task.
The kernel is primarily responsible for four main functions:
System memory management
Software program management
Hardware management
Filesystem management
The following sections explore each of these functions in more detail.
System Memory Management
One of the primary functions of the operating system kernel is memory management. Memory management is the ability to control how programs and utilities run within the memory restrictions of the system. Not only does the kernel manage the physical memory available on the server, it can also create and manage virtual memory, or memory that doesn’t actually exist but is created on the hard drive and treated as real memory.
It does this by using space on the hard disk called the swap space. The kernel swaps the contents of virtual memory locations back and forth from the swap space to the actual physical memory. This allows applications to think there is more memory available than what physically exists (as shown in FIGURE 1-2).
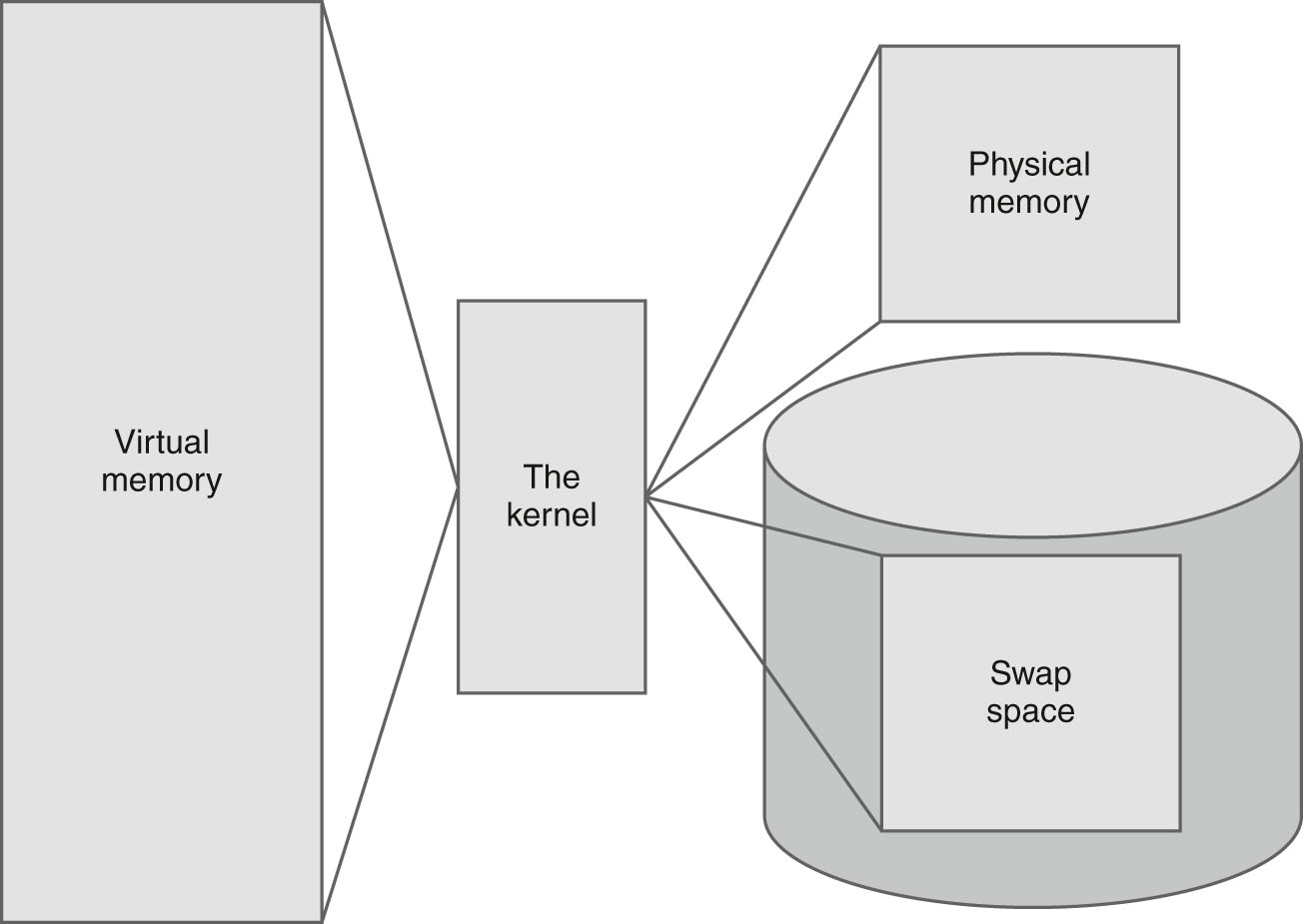
FIGURE 1-2 The Linux system memory map.
The memory locations are grouped into blocks called pages. The kernel locates each page of memory either in the physical memory or the swap space. The kernel then maintains a table of the memory pages that indicates which pages are in physical memory and which pages are swapped out to disk.
The kernel keeps track of which memory pages are in use and automatically copies memory pages that have not been accessed for a period of time to the swap space area (called swapping out)—even if there’s other memory available. When a program wants to access a memory page that has been swapped out, the kernel must make room for it in physical memory by swapping out a different memory page and swapping in the required page from the swap space. Obviously, this process takes time and can slow down a running process. The process of swapping out memory pages for running applications continues for as long as the Linux system is running.
You can see the current status of the virtual memory on your Linux system by viewing the special /proc/meminfo file. Here’s an example of a sample /proc/meminfo entry:
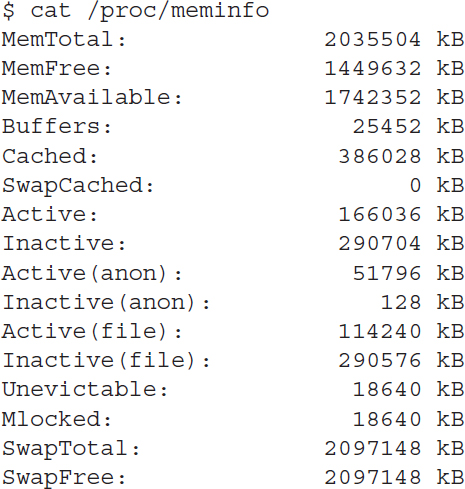
The MemTotal and MemFree lines show that this Linux server has 20 GB of physical memory and that there is about 14 GB not currently being used (free). The output also shows that there is about 2 GB of swap space memory available on this system. The kernel continually updates the meminfo file to show exactly what’s going on in memory at that moment in time, so you can always get a picture of what’s happening on the system.
Software Program Management
With the Linux operating system, a running program is called a process. A process can run in the foreground, displaying output on a display, or it can run in the background, behind the scenes. The kernel controls how the Linux system manages all the processes running on the system.
The kernel creates the first process, called the init process, to start all other processes on the system. When the kernel starts, it loads the init process into virtual memory. As the kernel starts each additional process, it gives it a unique area in virtual memory to store the data and code that the process uses.
There are a few different types of init process implementations available in Linux, but these days, two are most popular:
SysVinit—The SysVinit initialization method was the original method used by Linux and was based on the Unix System V initialization method. Though it is not used by many Linux distributions these days, you still may find it around in older Linux distributions
Systemd—The systemd initialization method was created in 2010 and has become the most popular initialization and process management system used by Linux distributions.
The SysVinit method
The SysVinit initialization method used a concept called run levels to determine what processes to start. The run level defines the state of the running Linux system, and what processes should run in each state. TABLE 1-1 shows the different run levels associated with the SysVinit initialization method.
TABLE 1-1 SysVinit initialization methods.
| RUN LEVEL | DESCRIPTION |
|---|---|
| 0 | Shut down the system |
| 1 | Single-user mode used for system maintenance |
| 2 | Multi-user mode without networking services enabled |
| 3 | Multi-user mode with networking services enabled |
| 4 | Custom |
| 5 | Multi-user mode with GUI enabled |
| 6 | Reboot the system |
The /etc/inittab file defines the default run level for the system. The processes that start for specific run levels are defined in subdirectories of the /etc/rc.d directory. You can view the current run level at any time using the runlevel command:

This output shows the system is currently at run level 5, which is the default used for graphical desktops.
The systemd method
The systemd initialization method has become popular because it has made several improvements over the original init method. One of those improvements is that it has the ability to start processes based on different events:
When the system boots
When a particular hardware device is connected
When a service is started
When a network connection is established
When a timer has expired
The systemd method determines what processes to run by linking events to unit files. Each unit file defines the programs to start when the specified event occurs. The systemctl program allows you to start, stop, and list the unit files currently running on the system.
The systemd method also groups unit files together into targets. A target defines a specific running state of the Linux system, similar to the SysVinit run level concept. At system startup, the default.target target defines all of the unit files to start. You can view the current default target using the systemctl command:

The graphical.target target defines the processes to start when a multi-user graphical environment is running, similar to the old SysVinit run level 5.
Viewing processes
The ps command allows you to view the processes currently running on the Linux system. Here’s an example of what you’ll see using the ps command:
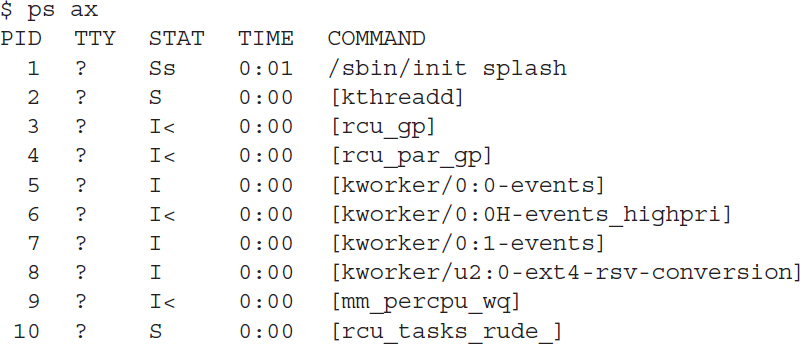

There are lots of processes running on a Linux system at any time; I’ve abbreviated the output to show just a few of the listed processes. The first column in the output shows the process ID (or PID). Notice that the first process is the friendly init process, and the Linux system assigns it PID 1. All other processes that start after the init process are assigned PIDs in numerical order. No two processes can have the same PID.
The third column shows the current status of the process (I for idle, S for sleeping, and R for running). The last column shows the process name. The process names that appear in brackets mean that the ps command couldn’t determine the command line parameters used to start the process.
Hardware Management
Still another of the kernel’s responsibilities is hardware management. Any device that the Linux system must communicate with needs driver code. The driver code allows the kernel to pass data back and forth to the device, acting as a middleman between applications and the hardware. Two methods are used for interfacing device driver code with the Linux kernel:
Compiling the device driver code with the kernel code
Compile the device driver code into a separate module, which then interfaces with the kernel during runtime
In the very early days of Linux, the only way to insert device driver code was to recompile the kernel. Each time you added a new device to the system, you had to recompile the kernel code. This process became even more inefficient as Linux kernels supported more hardware and as removable storage devices (such as USB sticks) became more popular. Fortunately, Linux developers devised a better method to insert driver code into the running kernel.
Programmers developed the concept of kernel modules to allow you to insert device driver code into a running kernel without having to recompile the kernel. Also, a kernel module could be removed from the kernel when the system had finished using the device. This greatly simplified using hardware with Linux.
The Linux system represents hardware devices as special files, called device files. There are three different classifications of device files:
Character
Block
Network
A character device file is for a device that can only handle data one character at a time. Most types of modems and terminals are created as character files. A block device file is for a device such as a disk drive that can handle data in large blocks at a time.
The network device file types (also called socket files) are used for devices that use packets to send and receive data. This includes temporary files used to send network data between programs running on the same physical host and a special loopback device that allows the Linux system to communicate with itself using common network programming protocols.
Linux creates special files, called nodes, for each device on the system. All communication with the device is performed through the device node. Each node has a unique number pair that identifies it to the Linux kernel. The number pair includes a major and a minor device number. Similar devices are grouped into the same major device number. The minor device number is used to identify a specific device within the major device group. Here is an example of a few device files on a Linux server:
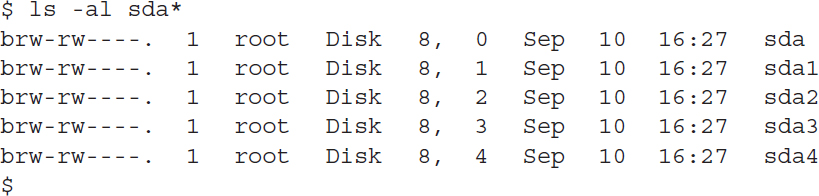
Different Linux distributions handle devices using different device names. In this distribution, the sda device is the first solid state drive (SSD) on the system.
The fifth column is the major device node number. Notice that all of the sda devices have the same major device node, 8. The sixth column is the minor device node number. Each device within a major number has its own unique minor device node number.
The first column indicates the permissions for the device file. The first character of the permissions indicates the type of file. Notice that the SSD files are all marked as block (b) devices.
Filesystem Management
A filesystem defines how the operating system stores data on storage devices. Unlike some other operating systems, the Linux kernel can support different types of filesystems to read and write data to and from hard drives, CD or DVD devices, and USB flash drives. Besides having over a dozen filesystems of its own, Linux can read and write to and from filesystems used by other operating systems, such as Microsoft Windows. The kernel must be compiled with support for all types of filesystems that the system will use, or device driver modules must be built and installed to support the filesystem. TABLE 1-2 lists the standard filesystems that a Linux system can use to read and write data.
TABLE 1-2 Linux filesystems.
| FILESYSTEM | DESCRIPTION |
|---|---|
| ext | Linux extended filesystem—the original Linux filesystem |
| ext2 | Second extended filesystem, provided advanced features over ext |
| ext3 | Third extended filesystem, supports journaling |
| ext4 | Fourth extended filesystem, supports advanced journaling |
| btrfs | A newer, high performance filesystem that supports journaling and large files |
| exfat | The extended Windows filesystem, used for SD cards and USB sticks |
| hpfs | OS/2 high‐performance filesystem |
| jfs | IBM’s journaling filesystem |
| iso9660 | ISO 9660 filesystem (CD-ROMs) |
| minix | MINIX filesystem |
| msdos | Microsoft FAT16 |
| nfs | Network File System |
| ntfs | Support for Microsoft NT file system |
| proc | Access to system information |
| smb | Samba SMB filesystem for network access |
| sysv | Older Unix filesystem |
| ufs | BSD filesystem |
| umsdos | Unix—like filesystem that resides on top of MS-DOS |
| vfat | Windows 95 file system (FAT32) |
| XFS | High‐performance 64‐bit journaling filesystem |
Any hard drive that a Linux system accesses must be formatted using one of the filesystem types listed in Table 1-1.
The Linux kernel interfaces with each filesystem using the Virtual File System (VFS). This provides a standard interface for the kernel to communicate with any type of filesystem. VFS caches information in memory as each filesystem is mounted and used.