
k-means clustering is but one concrete application of a more general algorithm known as expectation-maximization. In short, the algorithm works as follows:
- Start with some random cluster centers.
- Repeat until convergence:
- Expectation step: Assign all data points to their nearest cluster center.
- Maximization step: Update the cluster centers by taking the mean of all of the points in the cluster.
Here, the expectation step is so named because it involves updating our expectation of which cluster each point in the dataset belongs to. The maximization step is so named because it involves maximizing a fitness function that defines the location of the cluster centers. In the case of k-means, maximization is performed by taking the arithmetic mean of all of the data points in a cluster.
This should become clearer with the following screenshot:
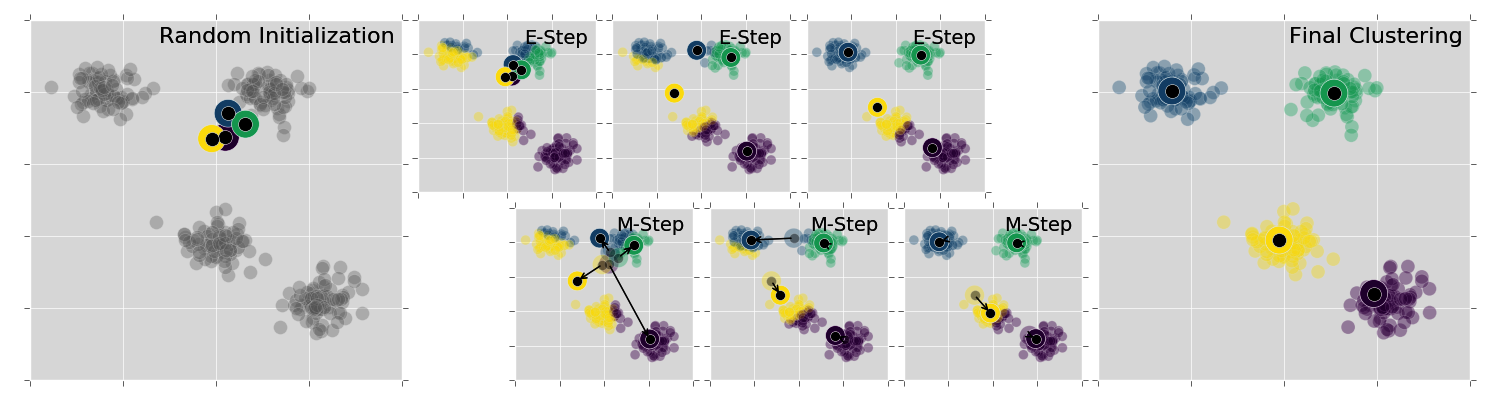
In the preceding screenshot, the algorithm works from left to right. Initially, all data points are grayed out (meaning, we don't know yet which cluster they belong to), and the cluster centers are chosen at random. In each expectation step, the data points are colored according to whichever cluster center they are closest to. In each maximization step, the cluster centers are updated by taking the arithmetic mean of all points belonging to the cluster; the resulting displacement of the cluster centers is indicated with arrows. These two steps are repeated until the algorithm converges, meaning: until the maximization step does not further improve the clustering outcome.