
Chapter 5
The k-Nearest Neighbors Classifiers
5.1 Introduction
In pattern recognition, the k-nearest neighbors algorithm (or k-NN for short) is a nonparametric method used for classification and regression [1]. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression:
■ In k-NN classification, the output is a class membership. An object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k-NN (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
■ In k-NN regression, the output is the property value for the object. This value is the average of the values of its k-NN.
k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification. The k-NN algorithm is among the simplest of all machine learning algorithms.
For both classification and regression, it can be useful to assign weight to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighing scheme consists of giving each neighbor a weight of 1/d, where d is the distance to the neighbor.
The neighbors are taken from a set of objects for which the class (for k-NN classification) or the object property value (for k-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.
A shortcoming of the k-NN algorithm is that it is sensitive to the local structure of the data. The algorithm has nothing to do with and is not to be confused with k-means, another popular machine learning technique.
5.2 Example
Suppose that we have a two-dimensional data, consisting of circles, squares, and diamonds as in Figure 5.1.
Each of the diamonds is desired to be classified as either a circle or a square. Then, the k-NN can be a good choice to do the classification task.
The k-NN method is an instant-based learning method that can be used for both classification and regression.
Suppose that we are given a set of data points {(x1, C1),(x2, C2), …, (xN, CN)}, where each of the points xj, j = 1, …, N has m attributes aj1, aj2, …, ajm and C1, …, CN are taken from some discrete or continuous space K.
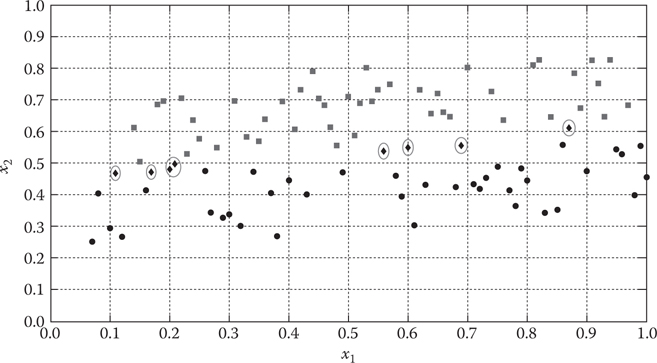
Figure 5.1 Two classes of squares and circle data, with unclassified diamonds.
It is clear that
with f(xj) = Cj, where X = {x1, …, xN} is a subset of some space Y.
Given an unclassified point xs = (as1, as2, …, asm) ∊ Y, we would like to find Cs ∊ K such that f(xs) = Cs. At this point, we have two scenarios [2]:
The space K is discrete and finite: in this case we have a classification problem, Cs ∊ K where K = {C1, …, CN}, where and the k-NN method sets f(xs) to be the major vote of the k-NN of xs.
The space K is continuous: In this case, we have a regression problem and the k-NN method sets , where {xs1, xs2, …, xsk} is the set of k-NN of xs. That is, f(xs) is the average of the values of the k-NN of point xs.
The k-NN method belongs to the class of instance-based supervised learning methods. This class of methods does not create an approximating model from a training set as happens in the model-based supervised learning methods.
To determine the k-NN of a point xs, a distant measure must be used to determine the k closest points to point xs: {xs1, xs2, …, xsk}. Assuming that d(xs, xj), j = 1, …, N, measures the distance between xs and xj, and {xsi: i = 1, …, k} is the set of k-NN of xs according to the distant metric d. Then, the approximation assumes that all the k-neighboring points have the same contribution to the classification of the point xs.
5.3 k-Nearest Neighbors in MATLAB®
MATLAB enables the construction of a k-NN method through the method “ClassifyKNN.fit,” which receives a matrix of attributes and a vector of corresponding classes. The output of the ClassifyKNN.fit is a k-NN model.
The default number of neighbors is 1, but it is possible to change this number through setting the attribute “NumNeighbors” to the desired value.
The following MATLAB script applies the k-NN classifier to the ecoli dataset:
clear; clc;EcoliData = load(‘ecoliData.txt’); % Loading theecoli datasetEColiAttrib = EcoliData(:, 1:end-1); % ecoliattributesEColiClass = EcoliData(:, end); % ecoli classes%knnmodel = ClassificationKNN.fit(EColiAttrib(1:280,:), EColiClass(1:280),...% ‘NumNeighbors’, 5, ‘DistanceWeight’, ‘Inverse’);% fitting the% ecoli data with the k-nearest neighbors method% The above line changes the number of neighborsto 4knnmodel = ClassificationKNN.fit(EColiAttrib(1:280,:), EColiClass(1:280),...‘NumNeighbors’, 5)Pred = knnmodel.predict(EColiAttrib(281:end,:));knnAccuracy = 1-find(length(EColiClass(281:end)-Pred))/length(EColiClass(281:end));knnAccuracy = knnAccuracy * 100
The results are as follows:
knnmodel =ClassificationKNNPredictorNames: {‘x1’ ‘x2’ ‘x3’ ‘x4’ ‘x5’‘x6’ ‘x7’}ResponseName: ‘Y’ClassNames: [1 2 3 4 5 6 7 8]ScoreTransform: ‘none’NObservations: 280Distance: ‘euclidean’NumNeighbors: 5Properties, MethodsknnAccuracy =
98.2143
Another approach assumes that a closer point to xs shall have more contribution to the classification of xs. Therefore, came the idea of the weighted weights, which is assumed to be proportional to the closeness of the point from xs. Now, if {xs1, xs2, …,xsk} denotes the k-NN of xs, let
It is obvious that Finally, f(xs) is approximated as
MATLAB enables the use of weighted distance through changing the attribute “DistanceWeights” from “equal” to either “Inverse” or “SquaredInverse.” This is done by using
knnmodel = ClassificationKNN.fit(EColiAttrib(1:280,:), EColiClass(1:280),...‘NumNeighbors’, 5, ‘DistanceWeight’, ‘Inverse’);
Applying the KNN classifier with a weighted distance provides the following results:
knnAccuracy =98.2143
which is the same as the model with equal distance.
References
1. Hastie, T., Tibshirani, R., and Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Ed., New York: Springer-Verlag, February 2009.
2. Vapnik, V. N. The Nature of Statistical Learning Theory. 2nd Ed., New York: Springer-Verlag, 1999.