
The first opportunity arose after I had collected a number of implementations of the same program for a different study. That study [Prechelt and Unger 2001] measured the effects of receiving a training in Watts Humphrey’s Personal Software Process (PSP, [Humphrey 1995]). The PSP claims big improvements in estimation accuracy, defect density, and productivity, yet our study found the effect to be a lot smaller than expected.
Half of the graduate student subjects in that study had received PSP training, and the others had received other programming-related training. In the study, they all solved exactly the same task (described in the next section), but could choose their programming language freely. I ended up with 40 implementations (24 in Java, 11 in C++, and 5 in C), and it occurred to me that it would be quite interesting to compare not just the PSP-trained programmers against the non-PSP-trained programmers, but to treat the programs as three sets stemming from different languages. It would be even more interesting to have further implementations in several scripting languages to compare.
I posted a public “call for implementations” in several Usenet newsgroups (this was in 1999), and within four weeks received another 40 implementations from volunteers: 13 in Perl, 13 in Python, 4 in Rexx, and 10 in TCL.
At this point, your skeptical brain ought to yell, “Wait! How can he know these people are of comparable competence?” A very good question, indeed; we will come back to it in the credibility discussion at the end.
The programmers were told to implement the following program.
The program first loads a dictionary into memory (a flat text file containing one word per line; the full test file contained 73,113 words and was 938 KB in size). Then, it reads “telephone numbers” from another file (in fact long, nonsensical strings of up to 50 arbitrary digits, dashes, and slashes), converts them one by one into word sequences, and prints the results. The conversion is defined by a fixed mapping of characters to digits (designed to balance digit frequencies) as follows:
e jnq rwx dsy ft am civ bku lop ghz 0 111 222 333 44 55 666 777 888 999
The program’s task is to find a sequence of words such that the sequence of characters in these words exactly corresponds to the sequence of digits in the phone number. All possible solutions must be found and printed. The solutions are created word-by-word, and if no word from the dictionary can be inserted at some point during that process, a single digit from the phone number can appear in the result at that position. Many phone numbers have no solution at all.
Here is an example of the program output for the phone number 3586-75.
Among the words in the dictionary were Dali, um,
Sao, da, and Pik.
3586-75: Dali um 3586-75: Sao 6 um 3586-75: da Pik 5
A list of partial solutions needs to be maintained by the program while processing each number. This requires the program to read the dictionary into an efficiency-supporting data structure, as it was explicitly prohibited to scan the whole dictionary for each digit to be encoded.
The programmers were asked to make sure their implementation was 100% reliable. They were given a small dictionary for testing purposes and one set of example telephone numbers for input plus the corresponding output—all correct encodings of these numbers with respect to the given dictionary.
Figure 14-1 shows a run-time comparison across the seven languages. (Refer to How to read the boxplot diagrams to interpret the figure’s boxplot format.)
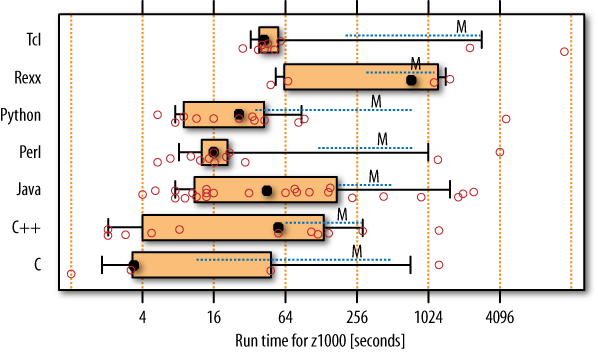
Remember that you are looking at data on a logarithmic scale. This means the within-language variabilities shown are actually huge! So huge that not a single one of the 21 pairwise differences of mean runtimes per language is statistically significant. This can be seen by the high degree of overlap among the dashed lines for essentially all languages in the figure. It means there is some non-negligible chance (clearly more than 5%, the commonly used threshold for statistical significance) that the observed differences are there only due to random fluctuations and are hence not “real.”
As a different way to put this, we could say the differences between programmers outweigh the differences between languages. There are a few significant differences for median runtimes (both Perl and Python are faster than both Rexx and Tcl), but medians are far less relevant because their use would imply that you only care whether one program is faster than another and not how much faster it is.
To squeeze more information out of the data, we have to aggregate the languages into just three groups: Java forms one, C and C++ form the second, and all four scripting languages form the third. In this aggregation, statistical analysis reveals that with 80% confidence, a script program will run at least 1.29 times as long as a C/C++ program, and a Java program will run at least 1.22 times as long as a C/C++ program. No big deal. “I don’t believe this!” I hear you say. “C and C++ are a hell of a lot faster than scripts. Where have these differences gone?”
There are two answers to this question. The first is revealed when we split up each runtime into two pieces. The execution of the phonecode program has two phases: first, load the dictionary and create the corresponding data structure, and second, perform the actual search for each input phone number. For the search phase, the within-language differences are quite large for the script languages, very large for Java, and enormous for C/C++. This within-language variability is so large that it renders the between-language differences statistically insignificant. For the dictionary load phase, the C/C++ programs are indeed the fastest. The Java programs need at least 1.3 times as long to complete this phase, and the script programs need at least 5.5 times as long, on average (again with 80% confidence).
The second answer has to do with the within-language variability, which is mind-boggling, particularly for C and C++. This blurs language differences a lot. Remember the good/bad ratio mentioned earlier: the median run time of the slower half of the C++ programs is 27 times as large as for the faster half. Are these slower-half programmers complete cretins? No, they are not. The upcoming discussion of program structure will reveal where these differences come from.
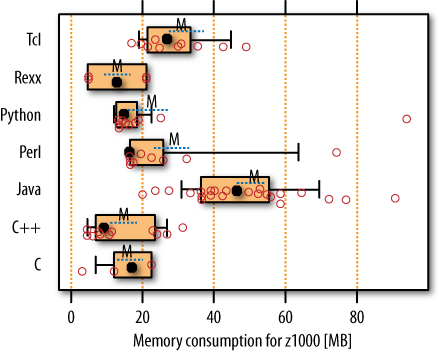
For the same program runs we considered in the previous sections, see the corresponding plots for the memory consumption in Figure 14-2.
From these results we can derive the following observations:
Nothing beats the low memory consumption of the smaller C/C++ programs.
The C++ and Java groups are clearly partitioned into two subgroups (look at the small circles!) that have small versus large memory consumption.
Scripting languages tend to be worse than C/C++.
Java is, on average, clearly worse than everything else.
But you can shoot yourself in the memory footprint with any language.
Java shows the largest variability and hence the largest planning risk.
We’ll find the reason for the partitioning of programs in our upcoming analysis.
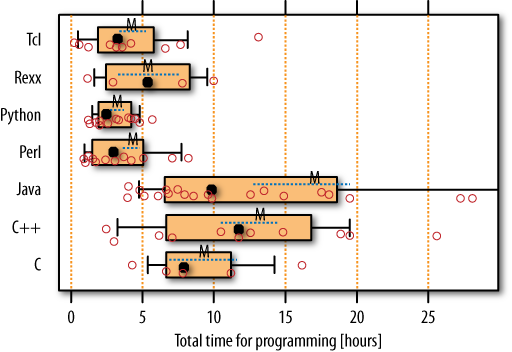
In a time of multigigabyte memories and multigigahertz, multicore processors, often both runtime and memory consumption are not critical. Saving programmer effort, however, will never go out of fashion. Figure 14-3 shows how long the programmers took to write each implementation, probably the most spectacular result of this study.
We see that the average work times are roughly in the range of 3 to 5 hours for the scripting languages, but 9 to 16 hours for the nonscript languages. Nonscripts take about three times as long! I can almost see all you nonscripting programmers shift uneasily in your seat now. Should we be willing to believe these data? Or have many of the scripting programmers cheated about their work time? Figure 14-4 offers evidence that their reports can be trusted, because the scripts are also hardly more than one-third as long as the nonscripts. However, please see Should I Believe This? for a caveat when interpreting these data.
In a mass reliability testing of all programs, we found that most implementations worked perfectly. Those few that failed were spread about evenly over all languages—at least when one considers the somewhat different working conditions of the script versus the nonscript programmers, described in [Prechelt 2000a]. Furthermore, the failures also tended to occur for the same inputs across all languages: devious “phone numbers” that contained no digit at all, only dashes and slashes. In short, the experiment did not reveal consistent reliability differences between the languages.
When we looked at the source code of the programs to see how they are designed, we found the second really spectacular result of this experiment.
Programs used one of three basic data structures to represent the dictionary content so as to speed up the search:
A simple partitioning of the dictionary into 10 subsets based on the digit corresponding to the first character. This is a simple but also very inefficient solution.
An associative array (hash table) indexed by phone numbers and mapping to a set of all corresponding words from the dictionary. This is hardly more difficult to program, but is very efficient.
A 10-ary tree where any path corresponds to a digit sequence and dictionary words are attached to all leaf nodes and some inner nodes. This requires the most program code, but is blazingly fast in the search phase.
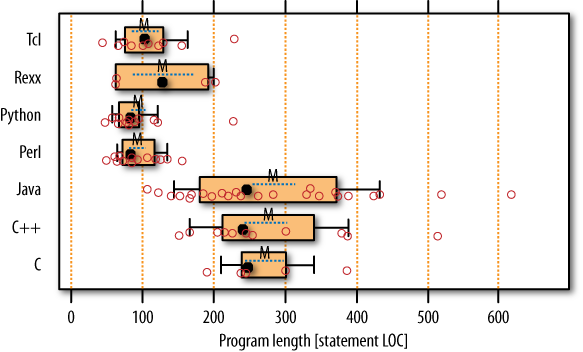
And here is the fascinating observation: First, all C, C++, and Java programs used either solution 1 or solution 3. The difference between these two solutions explains the huge within-language runtime variability in these three groups seen in Figure 14-1. Second, all script programs used solution 2.
Solution 2 can be considered the best solution, in that it provides high efficiency at rather low coding effort. But, of course, although suitable hash map implementations were available to at least the C++ and Java programmers, apparently none of them thought of using them. For the script programmers, in contrast, using associative arrays for many things appears to be second nature, so they all came up with the corresponding straightforward and compact search routine.
The language used really shaped the programmers’ thinking here—even though many of them also knew a language of the other type. The observation also explains some part of the between-languages difference in program length: the loop using the associative array needs fewer statements.
I do not believe that this effect is about “better” or “worse” languages. I think that particular languages incline programmers toward particular solution styles. Which of these styles is better depends on the particular problem at hand.
Remember, we still have a nagging question open:
How do we know that the programmers in different languages being compared are of similar competence?
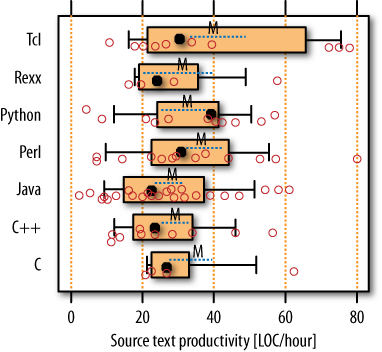
We can find an answer through the same technique we already used in the section on productivity: compare the productivity across languages measured in lines of code per reported work hour. It has long been known that the effort per line of code depends on the program requirements and various constraints, but hardly on the programming language ([Boehm 1981], p. 477), so higher language expressiveness is a most promising source of productivity improvements. Thus, if the range found for lines of code per hour is similar for each language, we can be reasonably confident that the programmer group for each language is comparable to the others (and also that at most, a few of the script programmers reported too-low work times).
The results, as shown in Figure 14-5, show that there are at most four abnormally high productivity values (three for TCL and one for Perl); all others are in the range established by the carefully supervised Java, C, and C++ programmers from the PSP study, and all averages are reasonably similar. This means it is fair to assume that the groups are indeed comparable and the times reported for scripting are at least approximately correct.
OK, so if we are willing to accept the results at face value, what limitations should we keep in mind when interpreting them? There are basically three:
The measurements are old (1999). The efficiency results might be different today because of differently sized improvements in the language implementations; in particular, Java (version 1.2 at that time) and Python (version 1.5 at that time) have likely improved a lot in the meantime. Also, Java was so new at the time of the data collection that the Java programmers were naive about their language. For instance, some of them simply used
StringswhereStringBufferswere called for, which explains part of the worse results reported for them in the memory usage and runtime categories.The task solved in this study is small and hence rather specific. Its nature is also quite idiosyncratic. Different tasks might bring forth different results, but we cannot know for sure.
The working conditions for the scripting groups were rather different from conditions for the Java/C/C++ groups. The latter worked under laboratory conditions, and the former under field conditions. In particular, some of the scripting participants reported they had not started implementation right after they had read the task description, which puts them at an advantage because the background thinking they performed in the meantime does not show up in the time measurements. Fortunately, the difference in work times is huge enough that a meaningful amount remains even if one applies a hefty rebate to the nonscript work times.
A number of other considerations may also hedge the results of this study. If you want to learn about them, have a look at the original source for this study [Prechelt 2000a]. A much shorter report, but still more detailed than the description here, can be found in [Prechelt 2000b].