
The second opportunity for a language comparison arose after a software manager named Gaylord Aulke called me in 2005 and said, “I own a service company that builds web applications. I have read your Phonecode report and use it to explain to my customers why they need not be afraid of scripting languages. But I would like to have something more specific. Couldn’t you do something like that for PHP?”
It was a fascinating thought, but it took me only two seconds to decide that no, I could not. I explained the reasons to him: to be credible, comparing web development platforms would need to involve a much bigger task (at least several days long, to make interesting aspects of web applications visible), platform groups of teams (at least three people each, to make interesting aspects of web development processes visible) rather than language groups of individuals, and high-quality professionals rather than arbitrary folks or students (because of the greater depth of knowledge required for a realistic use of web platforms). Also, the evaluation would be much more complicated. I simply could not imagine how anybody would pay for a study of this size.
His reaction was “Hmm, I see. I will talk to someone. Maybe we can do something about it.” Months later, the person he had talked to put me in contact with Richard Seibt and Eduard Heilmayr, who eventually were able to attract teams to participate in the experiment, which I had been able to scale down a great deal and which was now called Plat_Forms. The mission of the experiment was to look for any and all characteristics of the solutions or development processes that were consistent within a platform, yet different between platforms. These characteristics could then be considered emergent properties of the platforms—that is, effects on development that probably weren’t designed into the platforms or motivations for adopting them, but that nevertheless had a consistent impact.
The data collection, announced as a contest, went smoothly, except that we could not find enough teams for .NET, Python, and Ruby, and so had teams for only Java, Perl, and PHP. The evaluation was indeed quite difficult, but eventually we found some intriguing results.
In the morning of January 25, 2007, nine competent professional teams (three using Java, three Perl, and three PHP) were handed a 20-page document (spelling out 127 fine-grained functional, 19 nonfunctional, and 5 organizational requirements) and two data files on a CD. The next afternoon, they handed in a DVD containing the source code, version archive, and turnkey-runnable VMware virtual machine of their solution. In the meantime, they worked in whatever style suited them (even including field tests via a public prototype server and blog comments), using all the available software and tools they wanted.
The functional requirements came in use-case format, were prioritized as MUST, SHOULD, or MAY, and described a community portal called “People by Temperament” (PbT). They asked for:
A user registration, including uncommon attributes such as GPS coordinates.
The “Trivial Temperament Test” (TTT), a questionnaire of 40 binary questions (provided as a structured text file on the CD) leading to a four-dimensional classification of personality type.
Search for users, based on 17 different search criteria (all combinable), some of them complicated, such as selecting a subset of the 16 personality types or coarsely classifying distance based on the GPS coordinates.
A user list, used for representing search results, users “in contact” with myself, etc., including a graphical summary of the list as a 2D Cartesian coordinate plot visualizing the users as symbols based on two selectable criteria.
User status page, displaying details about a user (with some attributes visible only under certain conditions) and implementing a protocol by which users can reveal their email address to each other (“get in contact”) by sending and answering “requests for contact details” (RCDs).
An additional SOAP-based web-service interface conforming to a WSDL file provided on the CD.
The nonfunctional requirements talked about scalability, persistence, programming style, and some user interface characteristics, among other things.
The participants could ask clarification questions, but each group did so less than twice per hour overall. The task turned out to be suitable and interesting for the comparison, but also somewhat too large for the given time frame.
Being the scientist that I am, I was completely blank with respect to what the experiment would find and had no prejudices whatsoever regarding the characteristics of the three platforms. Do you believe that? Laughable! I was indeed neutral (in the sense of nonpartisan), but of course I had some expectations, and it was both entertaining and instructive to see that many of them crumbled. To get the most fun as well as knowledge out of this chapter, I encourage you to formulate your own expectations as well. Now. I mean it.
Here is an approximate summary of my assumptions:
- Productivity
Higher for PHP and Perl
- Length of source code
Lowest for Perl, low for PHP, high for Java
- Execution speed
Fastest for Java
- Security
Best for Java, worst for PHP
- Architecture style
“Clean” for Java, “pragmatic” for Perl and PHP (whatever that would mean; I wasn’t sure myself)
- Development style
Less incremental for Java and with more up-front design
Some of these expectations were more or less fulfilled, but others held a big surprise.
Since all teams had the same amount of time (two days) and worked towards the same set of fine-grained requirements, and no team finished early, we measured productivity by counting how many of the requirements were implemented and working. The result is shown in Figure 14-6.
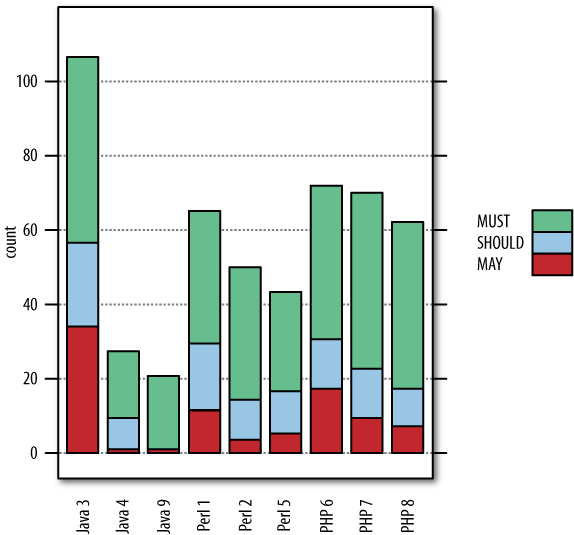
Please note that team 9 should be ignored for this evaluation. They used an immature framework in pre-alpha stage whose limitations kept them from achieving much. They had been very reluctant to participate, but we had urged them because we had no other third Java team. Team 4 also should be interpreted with care: they lost a lot of time on problems with their VMware setup that had nothing to do with Java. That said, the data holds the following interesting insights:
The most productive team was actually from the least expected platform: Java. We can only speculate why this is so. Some participants (not from Team 3) pointed out that Team 3 was the only one who used a commercial framework. It is possible that this difference indeed allowed for higher productivity or that Team 3 was most versed in the use of its respective framework, perhaps because of a well-refined “company style.”
The highest average productivity was found for PHP.
PHP also had the most even productivity. If this is a systematic effect, it would mean that PHP projects (at least with teams as competent as these) are least risky.
That last finding is something for which I had formulated no expectations at all, but it clearly calls for further research, as risk is a very important project characteristic [Hearty et al. 2008]. In hindsight, I would expect such smooth productivity more in a “high-ceremony” (statically typed) language than in a dynamic language.
Although the projects varied widely in the number of requirements they implemented, this was nothing compared to the size differences we found when we opened the hood and looked at the solutions’ source code. Figure 14-7 provides an overview of the size (in lines of code) of each team’s deliverable, when one takes into account only programming language and templating files (not data files, binary files, build files, or documentation).
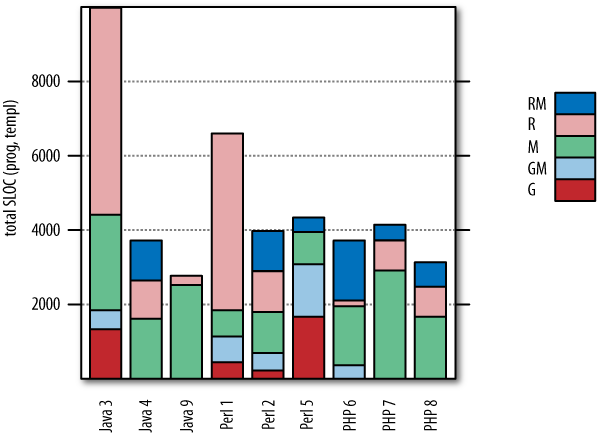
Figure 14-7. Total artifact size in source lines of code (SLOC) for each team, separated by origin of the respective file: reused-then-modified (RM), reused (R), manually written (M), generated-automatically-then-modified (GM), and generated automatically (G). Note that the Java 3 bar extends all the way up to 80,000 (with almost no RM), dwarfing all others by a factor of 10 to 20.
Again, we can make a number of interesting observations:
Some teams modify reused or generated files and others do not, but no platform-dependent pattern is visible.
Generating files appears to be most common for Perl.
The fraction of reused code differs wildly, again without a clear platform-dependent pattern.
Team 3’s commercial framework is particularly heavyweight.
Although these are interesting academically, they are hardly of much practical interest. The curiosity of a pragmatic person would be much better satisfied by the representation shown in Figure 14-8, which considers manually written files only and relates their size to the number of requirements implemented.
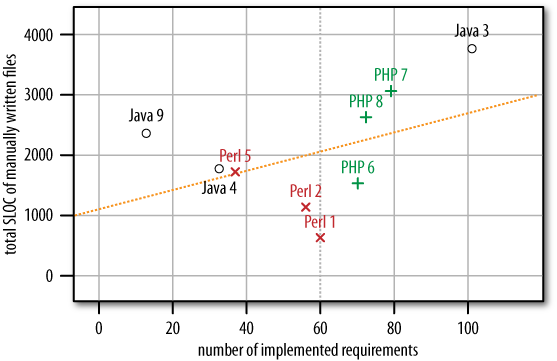
Figure 14-8. Total length of manually written files (as shown in Figure 14-7) depending on the number of requirements implemented (as shown in Figure 14-6)
This data shows that at least one of my initial expectations is right on target: the Java solutions are larger than average (above the trend line), and the Perl solutions are smaller than average (below the trend line).
There are normally two reasons why we are interested in artifact size. First, it can be used as a proxy for effort: larger artifacts tend to take longer to produce. The productivity data listed earlier has already shown us that this rule has to be taken with a grain of salt. Second, artifact size can be used as a proxy for modifiability: larger artifacts tend to require more effort for a given change. How about this in our case?
Modifiability is governed by two other -ities: understandability (how long do I need to find out where the change needs to be done and how?) and modularity (are the change spots widely spread or confined to a narrow region of the product?). Since the 1970s, researchers have been looking for ways to quantify these properties, but so far all metrics suggested [Fenton and Pfleeger 2000] have proven unsatisfactory. We have therefore investigated modifiability through two simple modification requests we made:
Add another text field in the registration dialog for representing the user’s middle initial, and handle this data throughout the user data model. What changes are required to the GUI form, program logic, user data structure, or database?
Add another question to the TTT questionnaire and its evaluation.
In each scenario, we listed for each solution what changes were needed in which files.
With respect to scenario 1, Perl is the clear winner with the smallest number of change spots throughout. Java and PHP needed to make more changes, and some of the changes were also much less obvious.
With respect to scenario 2, the solutions of teams Perl 1, Perl 5, PHP 7, and PHP 8 implemented an interpreter for the original structured text file containing the TTT questionnaire, so the change amounted to just adding the new question to that text file and you were done. Neat! Team Java 9 had also started in that direction, but had not implemented the actual evaluation. The other teams all used approaches that were much less straightforward, involving separate property files (Java 3 and Java 4), a hard-coded array in the source code (PHP 6), or database tables (Perl 2). All of these are much more difficult to change and require modifications in more than one place.
The message from these experiments in modification is mixed, but we interpret them to mean that the users of dynamic languages tend more strongly toward ad-hoc (as opposed to standardized) solution approaches. With the right design idea (as teams 1, 5, 7, 8 had), this can be better for modifiability.
Internationalization, by the way, was explicitly not a requirement, but could be done easily, even with the interpreter approach. Before implementing the property file approach, teams Java 3 and Java 4 (as well as Perl 1) had queried the “customer” whether they should allow for dynamic modification of the questionnaire at run time and had received a “no” answer.
Regarding the expectation of a “clean” architectural style for Java and a “pragmatic” one for Perl and PHP, my personal conclusion is that our study does not indicate, at least for the system we asked teams to implement, any particular cleanness (or other advantage) for Java. But a pragmatic style is visible for Perl and fares quite well!
The last area with fairly spectacular results (at least in my opinion) concerns the related questions of input validation, error checking, and security. It is very difficult to perform a fair security evaluation for nine systems that are so different both externally (the amount and representation of implemented functionality) and internally (the structure and technology used). We eventually settled for a fixed set of scenarios, as in the modifiability test, that did not attempt actual penetration, but just collected symptoms of potential vulnerabilities. We used a purely black-box approach restricted to unfriendly inputs at the user interface level: inputs involving HTML tags, SQL quotes, Chinese characters, very many characters, and so on. Figure 14-9 summarizes the results. The items on the X axis are:
- </...>
HTML tags
- Long
Very long inputs
- Int’l
Nonwestern 8-bit ISO characters and non-8-bit Unicode characters
Invalid email addresses
- SQL
Quotes in text and number fields
- Cookie
Operation with cookies turned off
The reaction of the system in each case was classified as correct (OK), acceptable ((OK)), broken (!), or security risk (!!!).
To summarize our findings:
- HTML-based cross-site scripting (CSS)
Two PHP solutions and one Perl solution appear susceptible. The Java 4 solution lacked the output functionality for this test, but the other two Java solutions came out clean.
- SQL injection
All three Perl solutions and one Java solution can be provoked to produce SQL exceptions by malign user input, which may or may not represent an actual vulnerability. All three PHP solutions came out clean here.
- Long inputs
Perl 2 fails in an uncontrolled way, but all other solutions behave acceptably.
- International characters
Perl 2 and Java 3 reject even short Chinese inputs as too long, whereas all PHP solutions work correctly.
- Email address checking
Two Java and two Perl solutions performed no email address validity checking; all PHP solutions did.
- Operation with cookies turned off
These made Java 9 fail silently and Perl 5 fail incomprehensibly. For the other (including all PHP) solutions, the operation was either possible or was rejected with a clean error message.
Summing this up, we have two findings that may be surprising for many people. First, the only solution that is correct or acceptable in each respect tested is a PHP solution, PHP 6. Second, with the exception of the CSS test, every other test had at least one broken Java solution and one broken Perl solution—but zero broken PHP solutions. It appears that, at least in the hands of capable teams, PHP is more robust than is often thought.
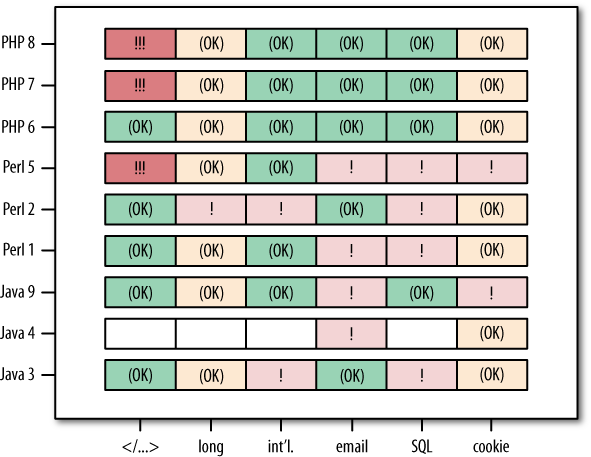
Figure 14-9. Results of black-box robustness and security testing. We evaluated the handling of six scenarios of potentially difficult dialog inputs. We report vulnerable-looking behavior only; we have not attempted to actually break in. The Java 4 solution lacks some functionality required for the tests.
We attempted to evaluate a number of other aspects in our Plat_Forms study, but some turned out to be too difficult to investigate and others returned no interesting differences between the platforms.
For instance, we had expected that teams on different platforms would exhibit different development styles in their processes. We attempted to capture these differences using a simple classification of who-is-doing-what in 15-minute intervals based on human observation (a single person going around to all nine teams). We also analyzed the time/person/file patterns of check-in activity in each team’s version repository. But neither data source indicated identifiable platform differences.
Of course, we also intended to investigate performance and scalability. Unfortunately, the intersection of the functionalities implemented in the nine solutions was too small for a meaningful comparison.
Again, many relevant details have been glossed over in this chapter. The original, very detailed source for this study is [Prechelt 2007]. A shorter but still fairly precise article is [Prechelt 2010].