
Chapter 19. The role of XML
XML is the underlying technology that makes modern content management systems (CMSs) possible. It allows us to break content into reusable elements, and helps us find them so we can arrange them into new information products. It allows different types of computer systems to talk to each other—to send information back and forth—allowing us to share information between departments and companies.
The best part about XML is that you don’t really need to know too much about it to use it. It’s like driving a car. You don’t have to understand how an internal combustion engine works to start and drive the car; likewise you don’t have to understand the internals of XML in order to use it well.
On the other hand, knowledge is a good thing, so we encourage you to read through this chapter. In it you’ll learn a bit about the history of XML, where it came from, and what it can do. We’ll compare XML with HTML and then introduce a little bit about Darwin Information Typing Architecture (DITA) and other XML tagging schemes.
Perhaps most importantly we’ll start off with a question we hear a lot from writers and other content creators.
Should you fear XML?
It does sound complicated and geeky. At one point it was; most writers had to be able to edit text like they were creating code. But that was a long time ago.
Remember, there was a time when mainstream word processing packages like WordStar™ and WordPerfect™ required writers to memorize complicated keystroke commands and “dot codes” for formatting content. WYSIWYG editors took over as soon as the computer platforms became powerful enough to run them, and the dreaded “dot codes” were hidden under a nice, clean, easy-to-use interface. Those who pined for the days of ugly screens could opt for the “codes on” mode, but most authors quickly dispensed with them.
The same has happened with XML editors. Early editors were famous for displaying the text in “tags on” mode. In this mode, you see all of the underlying structure and coding needed to create the final document. Like the earlier “codes on” mode in word processors, the screens were cluttered and the programs fairly hard to use.
XML authoring tools have moved on, and like their word processing ancestors, sport easy-to-use interfaces. The interface can look just like a modern word processing program (like Microsoft Word, or they actually can be Microsoft Word) or can be totally customized to meet the specific needs of the writers.
For example, in Figure 19.1 we see a sample document in an XML authoring tool that is Microsoft Word with XML structure “under the covers.” It looks like Word because it is Word, but it has a lot more functionality than traditional Word without the overt complexities of XML.

Figure 19.1. Sample structured document in Quark XML Author™.
The origins
In the beginning (all the way back to the 1970s), there were disparate software applications that really did not play well together at all. Charles Goldfarb, a researcher at IBM, observed that many systems at IBM could not share information with one another, that they each used their own “language” (incompatible file formats) to format the text. SGML (Standard Generalized Markup Language) was born out of a project to build a system for creating, managing, and publishing legal documents. A markup language is a set of annotations (tags) on text that describe how the text is to be structured, laid out, or formatted. HTML, which is used to define the appearance of content on web pages, is probably the most widely known markup language. Any application that formats text has an underlying markup language. For example, RTF (Rich Text Format) was for many years the underlying markup language for Microsoft Word.
SGML was based on the following three principles:
• Computers need to share files in a common format (they need to “speak” the same language).
• The markup of a document has to be extensible.
• There needs to be a way to identify the structure of documents so that different documents of the same type will share the same structure or rules.
As the World Wide Web came into being and developed, the community recognized that although HTML was useful for formatting information displayed on the Web, it had its limitations (insufficient tag set, could only describe format and not the content itself). It also realized that SGML was essentially overkill. So a working group under the World Wide Web Consortium (W3C) began work on XML.
The goals of the W3C in developing XML include the following:
• Web-based delivery
• Open standard
• Based on SGML
• Formal and concise
• Easy to author and create
• Easy to develop applications for
• Extensible
The first point is extremely important. To be suitable for the Web, the working group needed to create a streamlined version of SGML—SGML Lite—that would provide a lightweight markup standard, with all of the needed features and without the bulkiness that would overwhelm the Web.
XML was that streamlined version of SGML.
XML has been a great success. Use has spread beyond content markup to all sorts of other business and software applications.
Why XML in content creation?
From a content and publishing perspective, XML has become an extremely important technology for both big and small publishers. For complex content management with information reuse, XML is the technology of choice.
XML provides the ability to do a whole lot more than what can be done with traditional tools. The characteristics of XML that best support publishing are:
• Structured content
• Separation of content and format
• XSL (eXtensible Stylesheet Language) stylesheets
XML and structured content
Authors typically have a high-level understanding of the concept of structured content. For example, they understand that books have front matter, body chapters, and back matter. They also recognize repeatable structures at a lower level. Chapters have titles, overviews, sections containing the “meat” of the chapter, and a summary.
However, when you examine similar information products, you find that structures are not consistent from product to product. Even among documents of the same type, structures will vary from author to author, from department to department, from division to division. Even information written by a single author will vary over time. This is a problem for a number of reasons.
For customers, the impact of changes in structure can range from distracting to confusing. As creatures of habit, they get used to seeing things in the same places. When things move, it takes them time to get used to the changes. Changes in structure may be seen as inconsistencies, and may lead customers to distrust the material.
Inconsistency also has a major impact on reuse. Effective reuse is built on predictability. The initial analysis of the content and customers’ needs for that content will define the structure of your information products.
What is XML?
XML is a set of rules for defining markup languages. We’re all familiar with markup languages, with HTML being the most common example available. We’ve all looked at HTML code and in many cases we create content directly in HTML.
The XML standard is based on the SGML standard, which was designed with many of the same goals as XML. XML has been streamlined—reduced in complexity and capability—from SGML to make it practical for the Internet. However, XML retains enough of the characteristics to make it very effective for all sorts of publishing and specifically content management for publishing.
The advantage that XML has over HTML is that it allows you to define a tag set that meets the specific needs of your content. It’s a set of rules for creating markup languages (like HTML). Unlike HTML, where the tags are defined, XML allows you to create the tags to suit the needs of your content and your authors.
But what is XML?
XML can best be described by walking through a sample of XML markup.
XML files are made up primarily of elements and attributes. Elements have start tags, end tags, and content. Attributes have names and values.
<Procedure Audience=”All”>
<Title>Logging On to AccSoft </Title>
<Text>You must log on to the system before you can complete any tasks.
</Text>
<Intro>To log on to AccSoft:</Intro>
<ProcedureSteps>
<Step>Double-click the AccSoft application</Step>
<Step>Type your USERID into the <Fieldname>Name</Fieldname> field</ Step>
<Step>Type your password into the <Fieldname>Password</Fieldname> field.</Step>
<Step>Click the OK button to log on to AccSoft.</Step>
</ProcedureSteps>
</Procedure>
In the sample, <Title> is a start tag. Tags are enclosed by angle brackets.</Title> is an end tag: end tags always begin with a slash (/) after the opening angle bracket. The Title element is the start tag (<Title>), the end tag(</ Title>), and everything in between. Audience is an attribute name; All is the value. The combination of name and value make up the attribute.
In the example, some elements, like Title, Text, and Intro, just contain data. Others, like ProcedureSteps, contain other elements. Some Step elements contain both data and elements (Fieldname).
What do XML tags do?
XML tags:
• Describe your document’s content (meaningful tag and attribute names).
• Describe the structure of your document (document/node tree).
• Indicate hierarchy of data through embedded elements.
• Do not include formatting or “style” characteristics.
Comparing XML and HTML
There are a number of differences between HTML and XML. HTML is a set of tags that you can use to present content in a browser. Its primary application is presentation. It was not designed to capture structure. On the other hand, XML allows you to create your own markup languages with a focus on capturing the structure of content. The XML standard does not provide any specific capability for presentation.
From w3schools (http://www.w3schools.com/xml/xml_whatis.asp):
• XML was designed to describe data and to focus on what data is.
• HTML was designed to display data and to focus on how data looks.
A procedure in HTML
Consider what the sample procedure above might look like if it were marked up with HTML.
<h2>Logging On to AccSoft </h2>
<p>You must log on to the system before you can complete any tasks.</p>
<h3>To log on to AccSoft:</h3>
<ol>
<li>Double-click the AccSoft application</li>
<li>Type your USERID into the <i>Name field</i></li>
<li>Type your password into the <i>Password</i> field.</li>
<li>Click the OK button to log on to AccSoft.</li>
</ol>
The h2 tag indicates that you have a second-level heading, but you must interpret the content to determine that the content is a procedure.
Advantages of XML?
The advantages of XML are that it:
• Promotes consistency through structured documents. Documents follow the same structures, with similar documents having the same content pieces.
• Separates structure from format, allowing authors to focus on writing.
• Enables single-sourcing (component reuse). Structured information is easy to break into individual components for reuse or repurposing.
• Enables multiple outputs (formats and content). Publishing information is isolated from the content and is easily changed/replaced/added to.
• Enables dynamic documents. Documents can be built from components, enabling you to select components dynamically.
• Increases output flexibility. Structured information is easy to manipulate to reconfigure or republish.
An example
Consider a procedure. The content model for a procedure could be expressed as:
• A procedure contains a title
• Followed by a description of the procedure
• Followed by a heading to introduce actual steps
• Followed by one or more steps
• Followed by links to related procedures
The content model is a specific relationship of elements of content.
DTDs and schemas
In XML, structure can be defined in a schema or DTD (Document Type Definition) that specifically defines all the elements (tags) that can be used in a document as well as the relationship of those elements to other elements. You can specify the hierarchy of elements (“a chapter contains ...”), the order of elements, even the number of elements.
DTDs and schemas:
• Are formal documents, written in a particular syntax that specifies an XML vocabulary (set of tags)
• Describe which elements and entities may appear in associated documents, including:
• Elements
• Child elements
• Number of children
• Sequences of elements
• Mixed content
• Empty elements
• Text declarations
• Document content models in a formal manner
Advantages of schemas over DTDs
DTDs and schemas are similar in that they both define the required structure of a document. However, schemas are, in effect, an updated version of DTDs. As XML use on the Web increased, developers realized that DTDs were limited in what they could do, and that a more able mechanism for defining structure was needed. Schemas provide that increase in capability.
Schemas include all the capabilities of DTDs, plus:
• They are written as well-formed XML documents (DTDs are created using a different language).
• Data can be validated based on built-in and user-defined data types.
• Programmers can more easily create complex and reusable content models.
• Schemas support local and global variables in the XML document.
The two key differences (for authoring and publication) between schemas and DTDs are that schemas are written using a specific XML markup language, while DTDs require you to learn a separate, unique language. Most importantly, schemas offer what developers like to call “rich data typing capabilities for elements and attributes.” That translates to enabling much greater control over the structure of content and the content itself. For example, in a DTD, you can create a “year” element as part of a date. You can also specify that the “year” element contains only content and not other elements. But that is all you can specify within the element. A DTD can only specify the correct arrangements of elements to other elements. In a schema, not only can you define a “year” element, you can also specify that it must be four characters long and that all characters must be numeric (1, 2, 3,...). It allows control over the data itself.
A schema can be invaluable for authoring and publication. Many authors take as much time figuring out the structure they need to write to as they do actually crafting the information. Do I need an overview? Should my procedure have an introduction? With a schema, you can mandate the structure that is required. This consistency is also very valuable for customers. Consistency leads to predictability. Customers learn where information is to be found and can navigate to it automatically, finding what they need quickly and efficiently.
For structural consistency, having a defined structure in a schema is important. However, you need to be able to confirm that your content matches the content model defined in the schema. This functionality is provided by specialized tools called parsers that can read a schema and enforce the structural rules defined in it. The parser “reads” the document and reports an error when the structure and content do not match the schema.
Most XML authoring tools have built-in parsers to parse the content as you enter it, and to ensure that the elements and content match the requirements of the schema. Some authoring tools will allow you to enter elements only in their defined places and will not allow you to enter elements that break the rules of the schema. By providing authors with an editor and a schema, you can ensure that all your information products are structurally consistent.
Separation of content and format
Word processing and desktop publishing tools revolutionized the way content was created. Authors quickly gained the opportunity to take control of formatting their documents. The long lead times and production cycles of formal layout for printing were eliminated as authors began producing their own camera-ready, hot-off-the-laser-printer copy.
However, these new formatting capabilities come with issues. For some, having responsibility is a burden, for others, a distraction. Many authors become more concerned with how content looks, than with what the content says.
XML by itself is not acceptable for display to the average customer. It must be formatted for presentation.
There are a number of technologies available for formatting. XML presentation is created using XSL stylesheet. Unlike traditional stylesheets, which provide only formatting commands, XSL is a powerful mechanism for both transforming and formatting XML documents.
Using a stylesheet gives you the ability to describe all your formatting needs, including fonts, colors, sizes, margins, bullets, list numbers, and so on, in a WYSIWYG editor.
XSL
Of course, your job is probably not to deliver XML files, but rather printed books, eBooks, PDFs, or HTML pages. For content management and publishing, a large measure of the advantages of XML comes from XSL. You use XSL to transform (or convert or publish) to the output formats you want to deliver.
XSL:
• Is XML markup language itself (there is an XSL vocabulary)
• Can format content for online display or for paper-based delivery
• Can add constant text or graphics (like the icon in a note)
• Can filter content
• Can sort or reorder content
• Is really divided into three parts:
1. XSLT—a transformation language
2. XSL-FO (XSL Formatting Objects—a language used to format XML)
3. XPath
But rather than simply formatting the information in a document, XSL gives you the ability to transform it into something else. That is, you can manipulate the information to reorder, repeat, filter out information, or even add information based on details in the file. This is where XSL transformation, also known as XSLT, fits in. XSLT allows you to transform an XML document into another markup language. The most common use of XSLT is to transform information to HTML for display on the Web. But XSLT can also be used to convert information from XML into markup for mobile.
The flexibility of XSL and its pieces is extremely valuable for information publication and presentation. Unlike traditional tools, which associate one stylesheet with one document, you can create any number of stylesheets for a single XML document or information product. If you want to post the document on the Web or mobile, create an XSL stylesheet to HTML. For print, create an XSL stylesheet to XSL-FO or better yet, to an XML-aware composition tool.
Despite the unstoppable growth of the Internet and display technologies, paper will continue to be a required output for information. XSL-FO has been designed for that purpose. If you want paper, create an XSL-FO stylesheet. XSL-FO provides stylesheet capabilities for converting XML to paper-based formats like PDF. It provides for all of the required formatting, including page layouts, headers, footers, recto/verso (odd/even) pages, portrait and landscape pages, and so on. Many organizations are skipping XSL-FO completely and going from XML to a composition package such as Adobe InDesign and QuarkXPress.
When the information is ready to publish, you can process the file against all stylesheets simultaneously and get all required outputs at the same time.
What about DITA?
You’ve probably heard a lot about DITA, and might be aware that it’s related to XML in some way. So what is it, and why might you be interested in it?
With all that, why do we need DITA?
First of all, starting an XML implementation from scratch can be expensive. The process of creating content models, DTDs or schemas, and stylesheets can be quite time-consuming. DITA is an existing markup standard, and being able to start out with an existing, well thought out standard can take you a giant step along the development timeline, saving you both time and money.
DITA was developed primarily by IBM in response to the changing needs of their business. Those needs are the same needs that we all face:
• Figuring out how to get products to market faster
• Finding ways to reduce unnecessary expenses
• Delivering content in an increasing number of output formats
• Finding ways to react faster to changing demands (more flexibility)
• Increasing the effectiveness of content
Changes in corporate goals, changes in technology, and changes in customer expectations and needs all have to be met. DITA is the mechanism IBM chose to meet those needs.
Recognizing that DITA would benefit writing departments everywhere, IBM has passed the standard to the Organization for the Advancement of Structured Information Standards (OASIS), a not-for-profit, international consortium, that drives the development, convergence, and adoption of eBusiness standards.
Design goals
Before discussing the details of DITA, it’s useful to understand some of the goals that led to the development of the standard.
Move away from a single format to multiple formats and outputs
One of the largest impacts of technology on information development is the addition of so many new formats for delivering information. No one just delivers to one format any more. There is an increasing need for information to be delivered in multiple formats. While some improvements have been made, many of the technologies in use today are not efficient tools for creating multiple outputs from a single source of content. The standards that have been available to date, like DocBook, have been book-based.
Move away from SGML to XML
IBM had been using SGML for some time but recognized that XML, with its stated focus on Internet applicability, was a better option. Web-based and mobile formats and delivery have become crucial tools for delivering effective information to customers.
Move towards the trend to minimalism
The goal of information development and delivery should be “the right information, at the right time, in the right format, to the right person.” For IBM, that meant reducing information “glut,” lessening the volume of irrelevant information presented to customers, and focusing on providing only the information that customers need. This approach reduces the time it takes to both create and maintain information, facilitates quicker information delivery, and reduces the effort required to keep information up-to-date.
Provide more flexibility in structures and move away from “monolithic” DTDs
The trend in the past was to create a DTD focused on the needs of individual departments and specific information products they produce. This approach, however, can have a negative impact on wide-scale reuse, as content created by one department may be difficult to reuse in other departments. DITA is intended to provide a mechanism that establishes a clear base of common structures, making it easier to create specific structures needed by different departments.
Support maximum reuse
Reuse is today’s best practice for information developers. DITA was developed specifically to promote content reuse and reduce redundant information.
Benefits of DITA
Considering the benefits that come with SGML and XML, you might wonder why you should consider DITA instead of just developing your own XML markup scheme. That might be the right way to go; there are still many, many applications that cry out for XML solutions other than DITA. And there are many other XML solutions that compete with DITA, like DocBook and S1000D. So what are the arguments in favor of DITA?
First, starting from scratch is expensive. DITA is an open standard that includes a set of predefined structures for capturing topic-based content and gives you a set of tags and structures to use as-is or as a starting point for creating your own specialized structures.
DITA is output independent. That is, as a basic principle of its use, topics are written in DITA to be output into other formats as necessary. When authoring in Microsoft Word or standard FrameMaker, for example, you are authoring in an interface that has been designed and optimized for creating paper output.
DITA was designed to support reuse. From the beginning, DITA’s developers recognized reuse as a best principle of content creation. By focusing on the information, rather than the output, you can write information once and use it in other formats and contexts as needed. This does take planning to get the structures right, effort to teach people to write in a new way, and discipline to actually write that way. But you can save money, save time, and improve quality if you do it right.
Topics, the building blocks of DITA
The DITA standard defines the topic as the basic building block of content. Users author content using specific topic structures. There are four different topic structures—that is, four different kinds of topics—delivered with DITA (see Table 19.1).
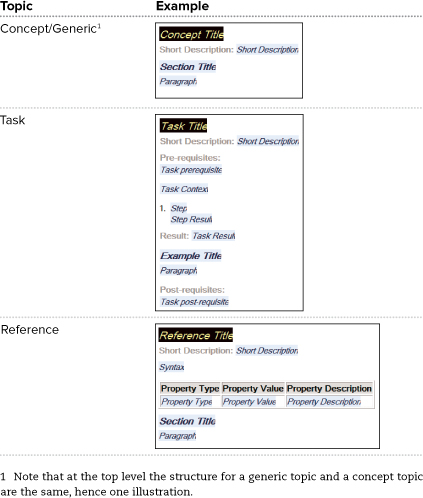
The base definition for all topics comes from the generic topic. It is defined with a relatively simple structure, including elements for title, short description, prolog (for metadata), the topic body, and related links. The topic body is defined with mostly generic HTML tags for structure, with the notable exception of a section substructure, which allows you to break up a long topic into sections.
One of the strengths of DITA—and where the Darwin angle fits in—is that the other three topic types (concept, task, and reference) all borrow their base structures from the generic topic structure. In other words, they inherit the same basic structure as a generic topic. However, because the DITA creators recognized that generic structure will not always provide the necessary authoring or output control, the three specialized types have additional structure that is specific to the kind of information they represent. For example, the task topic has a defined substructure for capturing procedures, with steps, actions, and results, among other specialized elements. The reference topic includes structure for documenting a screen or an interface.
It is that topic structure that gives DITA much of its effectiveness. Users capture content in individual topics that can be included into different outputs to create different information products.
Topics and DITA Maps
Creating topics is effective, but not what we typically deliver. DITA is based on a topic architecture that sees output products built from topics aggregated by a DITA map. This means that DITA maps provide an index of the topics that are associated with an individual book or help system, for example.
Broken down, a map is really just a series of topic references; the references point to the topics to be included in the output when you process the map (see Figure 19.2). You can set the order and the hierarchy of the topic references. The map does not contain content, it just points to it. This simplifies reuse, as you can point to the same topic from as many maps as you want. You can change a topic’s hierarchy level in different books. In one map, a topic can be at a “chapter” level, while in another book, it can function as a “section” or “subsection.” You can also point to the same topic in the same document as many times as you want or need. The map basically operates as a table of contents for a virtual document.
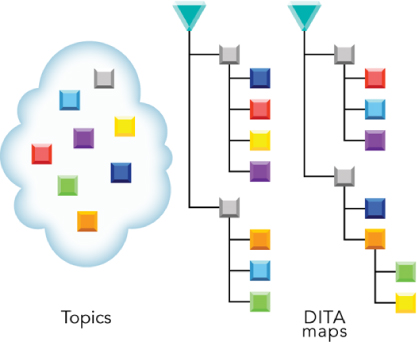
Figure 19.2. How topics can be assembled into DITA maps.
It’s not perfect for all purposes
IBM’s business has long been focused on delivering software and services. Accordingly, much of their documentation needs is centered on managing software and the documentation for that software.
When you look at the DITA standard, you’ll see many internal references that make this apparent. Examples used in the specification often reflect DITA’s roots. That doesn’t mean that you can only use it to structure software documentation; far from it. It just reflects its origins.
Recent updates to the standard have widened the scope considerably. DITA 1.2 includes new elements to support the specific needs of training departments. This is a welcome development. DITA is now being used in the publishing industry as well.
Alternatives to DITA
DITA is not the first XML initiative to become popular or widely used. Companies implementing XML solutions have always had alternatives, including building custom DTDs from scratch. Industry-standard DTDs, like DocBook, and NLM, have also existed for people to use. Each has strengths and weaknesses, as does any initiative or approach.
DocBook
If you approached XML editor or CMS vendors five years ago, they would at some point during the conversation ask you if you had considered DocBook. For publishing, it was really the first industry-standard DTD for the publications focus.
It was originally developed as an SGML markup language for converting, sharing, and ultimately authoring technical manuals for UNIX computer systems. Eventually, its development was taken over by a technical committee of OASIS.
The standard has undergone multiple revisions since its initial version, with wide contributions from many customers. As a result, it’s a very robust model, which accommodates pretty much any model of documentation guide imaginable. However, with over 300 individual elements, it’s very complex and can be difficult to use. To help alleviate the problem, the DocBook developers have designed the model and DTD to facilitate the use of a customization layer. This layer is built on top of DocBook to simplify the models actually used by authors.
DocBook is a stable, tested, mature software documentation model. It’s been used and refined over a long period of time and over varied applications. As a result, it has built-in models to cover most, if not all, typical software documentation applications. DocBook is not just for technical documentation, though; many organizations such as publishers and companies that write a lot of articles and reports use DocBook.
However, DocBook has lost some of its appeal in the last few years for several reasons. DocBook:
• Was designed for the creation of books, not materials on the Web
• Does not support reuse well
• Is overly complex
DocBook is still in use and is not likely to go away for a long time to come. DocBook is appropriate for content that is largely print-based. DocBook is frequently used for narrative documents and in areas like government.
DocBook is seeing a resurgence in the increased use of XQuery. XQuery is a recommendation of the W3C and is supported by all the major database engines (IBM, Oracle, Microsoft, and so on). XQuery is to XML what SQL is to database tables. That is, it’s a language for extracting data from XML repositories, just as SQL is a query language for extracting data from relational databases. In fact, XQuery is semantically similar to SQL, but is designed specifically for finding and extracting elements and attributes from XML documents. Many companies are converting their existing content to DocBook because XQuery can:
• Query/search any XML-based content, regardless of schema.
• Automatically extract and reassemble content in any desired configuration.
• Repurpose content without pre-chunking.
XML formats for publishing
A variety of different XML formats can be used for XML publishing including:
• Text Encoding Initiative (TEI)
• National Library of Medicine (NLM)
• DocBook
• DITA for Publishers
TEI
TEI (Text Encoding Initiative) is an extremely rich and complex tag set, consisting of nearly 500 elements. In practice, most practitioners use far fewer tags. A typical document is likely to use fewer than 50.
TEI is managed by the Text Encoding Initiative Consortium that develops and maintains a standard for the representation of texts in digital form. The complexity of the TEI tag set is caused by TEI’s goal of providing “a framework for encoding (in theory) any genre of text from any period in any language.”
http://www.tei-c.org/index.xml
NLM
National Library of Medicine (NLM) is a DTD developed by the US National Library of Medicine to structure information for publication in scientific and medical journals and other publications.
NLM is fast becoming the de facto XML standard for scientific journals and publications, especially those in the medical field.
The US National Library of Medicine is the world’s largest medical library. In order to structure and organize information, including information published in medical journals, the library chose XML as the tagging methodology. In order to capture the data required, they developed their own DTDs. These DTDs are known as the NLM DTDs.
http://www.nlm.nih.gov/news/electronic_archiving.html
DITA for publishers
The DITA for Publishers project is an open-source community project to enable the quick and productive use of DITA by publishers. DITA for publishers provides:
• DITA specializations for common publishing document components (article, chapter, subsection, sidebar, part)
• Plug-ins for HTML, PDF, EPUB, and Kindle
• Ability to convert styled Word documents to DITA
• Ability to produce InCopy and InDesign documents from DITA content
http://dita4publishers.sourceforge.net
Summary
There is no need to fear working with XML; today’s XML authoring tools are Microsoft Word-like or are even Microsoft Word itself, which makes it simple to create XML-based content.
XML is not the only technology solution for reuse, but it’s the most powerful by far. XML provides the best functionality of SGML and the ease-of-use of HTML, the best of both worlds.
XML provides powerful support for a unified content strategy through:
• Structured content
• Separation of content and format
• Built-in metadata
• Database orientation
• XSL stylesheets
• Personalization