
Chapter 2. Defining Rest APIs and Alternative API Approaches
Microservices based architectures and Service Oriented Architectures promote an increased number of independent services. Often services are running multi-process, on multiple machines in data centers around the globe. This has led to an explosion in mechanisms to communicate between processes and deal with the challenges of distributed communication between services. The software development community has responded by building a variety of creative API protocols and exchanges including REST, gRPC and GraphQL learning from vintage protocols. With a range of options available an API architect needs an overall understanding of the exchange styles available and how to pick the right technologies for their domain.
In this chapter we will explore how REST addresses the challenges of communicating across services, techniques for specifying REST APIs using OpenAPI and the practical applications of OpenAPI specifications. With modern tooling building REST APIs is easy, however building a REST API that is intuitive and follows recommended practices requires careful design and consideration. In order to be successful with microservices, a focus on continuous integration, deployment speed and safety is essential. REST APIs need to complement DevOps and rapid deployments rather than become a bottleneck or deployment constraint. In order to keep our system free to evolve and not disrupt consumers, it is also necessary to consider versioning in the release process of APIs.
Due to the simplicity of REST and wide support it is usually one of the best approaches to create an API. However there will be situations and constraints where we must consider alternative approaches for our API implementation. This may come down to performance or the requirement to create a query layer across multiple APIs.
The chapter concludes by looking at whether we can combine multiple API formats in a single service. We will also discuss whether the complexity of multi specifications takes us further away from the fundamentals of REST and other API approaches.
Introduction to REST
Roy Fielding’s dissertation Architectural Styles and the Design of Network-based Software Architectures provides an excellent definition of the architectural applications of REST. REpresentational State Transfer (REST) is one of the primary mechanisms for exchanging data between client and server and is extremely popular within the API ecosystem and beyond. If we adjust “distributed hypermedia system” in Roy Fielding’s definition below to “an API” it describes the benefit that we get from using REST APIs.
The Representational State Transfer (REST) style is an abstraction of the architectural elements within a distributed hypermedia system. REST ignores the details of component implementation and protocol syntax in order to focus on the roles of components, the constraints upon their interaction with other components, and their interpretation of significant data elements. It encompasses the fundamental constraints upon components, connectors, and data that define the basis of the Web architecture, and thus the essence of its behavior as a network-based application.Roy Thomas Fielding
To explore REST in more practical terms Figure 2-1 describes a typical REST exchange and the key components involved in the exchange over HTTP.
In this example the consumer requests information about the attendees resource, which is known by the resource identifier http://mastering-api.com/attendees.
Modelling an exchange in REST involves a request method (also known as the request verb), in this case a GET to retrieve data, and the resource identifer to describe the target of our operation.
REST defines the notion of a representation in the body and allows for representation metadata to be defined in the headers.
In this example we are informing the server we are expecting application/json by stating this in the Accept header.
The response includes the status code and message from the server, which enables the consumer to interrogate the result of the operation on the server-side resource. In the response body a JSON representation containing the conference attendees is returned. In “REST API Standards and Structure” we will explore approaches to modelling the JSON body for API compatibility.

Figure 2-1. Anatomy of a RESTful Request and Response over HTTP
Note
Although there is nothing in the REST specification that states HTTP is required, the data elements and their usage were designed with HTTP in mind.
The Richardson Maturity Model
The REST specification does not enforce a high degree of restriction in terms of how developers and architects build and design REST APIs. Speaking at QCon in 2008 Leonard Richardson presented his experiences of reviewing many REST APIs. Martin Fowler also covered Leonard Richardson’s maturity model on his blog. The model presents levels of adoption that teams apply to building APIs.
Level 0 - HTTP/RPC |
Establishes that the API is built using HTTP and has the notion of one URI and one HTTP method.
Taking our example above of |
Level 1 - Resources |
Establishes the use of resources, and starts to bring in the idea of modelling resources in the context of the URI.
In our example if we added |
Level 2 - Verbs (Methods) |
Starts to introduce the correct modelling of multiple resources URIs accessed by different request methods (also know as HTTP Verbs) based on the effect of the resources on the server.
An API at level 2 can make guarantees around |
Level 3 - Hypermedia Controls |
This is the epitome of REST design and involves navigable APIs by the use of HATEOAS (Hypertext As The Engine Of Application State).
In our example when we call |
Most APIs reach API maturity level 2, but with this wide range of options there is a lot for the developer to consider. The practical applications of HATEOAS are limited in modern RESTful APIs and this is where the theoretical ideal REST concept meets the battle testing of production code. In order to be consistent we need to establish baseline expectations of the APIs implemented using REST and provide that consistency across all the APIs offered.
REST API Standards and Structure
REST has some very basic rules, but for the most part the implementation and design of an API is left as an exercise for the developer. It is useful to have a more practical definition around the APIs to provide a uniformity and expectations across different APIs. This is where REST API Standards or Guidelines can help, however there are a variety of sources to choose from. For the purposes of discussing REST API design we will use the Microsoft REST API Guidelines, which represent a series of internal guidelines that have been OpenSourced to create a dialog in the community. The guidelines use RFC-2119 which defines terminology for standards such as MUST, SHOULD, SHOULD NOT, MUST NOT etc allowing the developer to determine whether requirements are optional or mandatory.
Tip
As REST API Standards are evolving, an open list of API Standards are available on the book’s Github. Please contribute via Pull Request any open standards you think would be useful for other readers to consider.
Lets evolve our attendees API using the Microsoft REST API Guidelines and introduce an endpoint to create a new attendee.
If you are familiar with REST the thought will immediately be to use POST, but the recommended response header might not be so obvious.
POST http://mastering-api.com/attendees
{
"displayName": "Jim",
"givenName": "James",
"surname": "Gough",
"email": "[email protected]"
}
---
201 CREATED
Location: http://mastering-api.com/attendees/1
The Location header reveals the location of the new resource created on the server, and in this API we are modelling a unique ID for the user. It is possible to use the email field as a unique ID, however the Microsoft REST API guidelines recommend in section 7.9 that PII should not be part of the URL.
Warning
The reason for removing sensitive data from the URL is paths or query parameters might be inadvertently cached in the network, for example in server logs or elsewhere.
Another aspect of APIs that can be difficult is naming, as we will discuss in “API Versioning” something as simple as changing a name can break compatibility. There is a short list of standard names that should be used in the Microsoft Rest API Guidelines, however teams should expand this to have a common domain data dictionary to supplement the standards. Lets now take a look at patterns for retrieving data.
Collections and Pagination
It seems reasonable to model the GET /attendees request as a response containing a raw array.
The source snippet below shows an example of what that might look like as a response body.
GET http://mastering-api.com/attendees
---
200 OK
[
{
"displayName": "Jim",
"givenName": "James",
"surname": "Gough",
"email": "[email protected]",
"id": 1,
},
{
"displayName": "Matt",
"givenName": "Matthew",
"surname": "Auburn",
"email": "[email protected]",
"id": 2,
}
]
Let’s consider at an alternative model to the GET /attendees that nests the array of attendees inside an object.
It may seem strange that an array response is returned in an object, however the reason for this is that allows for us to model bigger collections and pagination.
This is reaping the benefits of hindsight, adding pagination later and converting from an array to a object in order to add a @nextLink (as recommended by the standards) would break compatibility.
GET http://mastering-api.com/attendees
---
200 OK
{
"value": [
{
"displayName": "Jim",
"givenName": "James",
"surname": "Gough",
"email": "[email protected]",
"id": 1,
}
],
"@nextLink": "{opaqueUrl}"
}
Filtering Collections
Our conference is looking a little lonely with only two attendees, however when collections grow in size we may need to add filtering in addition to pagination.
The filtering standard provides an expression language within REST to standardize how filter queries should behave, based upon the OData Standard.
For example we could find all attendees with the displayName Jim using
GET http://mastering-api.com/attendees?$filter=displayName eq 'Jim'
It is not necessary to complete all filtering and searching features from the start. Designing an API in line with the standards will allow the developer to support an evolving API architecture without breaking compatibility for consumers.
Updating Data
When designing an API the developer would need to make an active decision on whether to use PUT or PATCH to update an attendees details.
A PUT is used to replace the resource entirely with the content of the request, where as a PATCH would only update the attributes specified by the request.
Depending on the number of fields and expected parallel updates the API should be designed accordingly.
For example two PUT operations would likely involve a lost update whereas two PATCH requests may be successful independently.
Error Handling
An important consideration when extending APIs to consumers is defining what should happen in various error scenarios. Error standards are useful to define upfront and share with API producers to provide consistency. It is important Errors describe to the API Consumer exactly what has gone wrong with the request, this will avoid increased support of the API.
Warning
Ensure that the error messages sent back to the consumer does not contain stack traces and other sensitive information. This information can help an hacker aiming to compromise the system.
We have just scratched the surface on building REST APIs, but clearly there are important decisions to be made at the beginning of the project to build an API. If we combine the desire to present intuitive APIs that are consistent and allow for an evolving compatible API, it is worth adopting an API Standard early.
Checklist: Choosing an API Standard
Decision |
Which API standard should we adopt? |
Discussion Points |
Does the organization already have other standards within the company? Can we extend those standards to external consumers? Are we using any third party APIs that we will need to expose to a consumer (e.g. Identity Services) that already have a standard? What does the impact of not having a standard look like for our consumers? |
Recommendations |
Pick an API standard that best matches the culture of the Organization and formats of APIs you may already have in the inventory. Be prepared to evolve and add to a standard any domain/industry specific amendments. Start with something early to avoid having to break compatibility later for consistency. Be critical of existing APIs, are they in a format that consumers would understand or is more effort required to offer the content? |
Specifying REST APIs
As we have seen the design of an API is fundamental to the success of an API platform. The next challenge to overcome is sharing the API with developers consuming our APIs.
API marketplaces provide a public or private listing of APIs available to a consumer. The developer can browse documentation and quickly trial an API in the browser to explore the API behavior and functionality. Public and private API marketplaces have placed REST APIs prominently into the consumer space. Architecturally REST APIs are increasingly important in support of both microservices based architectures and Service Oriented Architectures. The success of REST APIs has been driven by both the technical landscape and the low barrier to entry for both the client and server.
Prior to 2015 there was no standard for specifying REST APIs, which may be quite surprising given that API specifications are not a new concept. XML had XML Schema Definitions (or XSD), which were a core mechanism in ensuring compatibility of services. However, it is important to remember that REST was designed for the web, rather than specifically for APIs. As the number of APIs grew it quickly became necessary to have a mechanism to share the shape and structure of APIs with consumers. This is why the OpenAPI Initiative was formed by API industry leaders to construct the OpenAPI Specification (OAS). The OAS was formerly known as Swagger and documentation and implementation use OAS and Swagger interchangeably.
OpenAPI Specification Structure
Let’s explore an example OpenAPI Specification for the attendees API.
"openapi":"3.0.3","info":{"title":"Attendees Mastering API","description":"Example accompanying the Mastering API Book","version":"1.0"},"servers":[{"url":"http://mastering-api.com","description":"Demo Server"}],
The specification begins by defining the OAS version, information about the API and the servers the API is hosted on.
The info attribute is often used for top level documentation and for specifying the version of the API.
The version of the API is an important attribute, which we will discuss in more detail in “API Versioning”.
The servers array is one of the new additions in OpenAPI Specification 3, prior to this only a single host could be represented.
The openapi object key is named swagger in older versions of the specification.
Note
As well as defining the shape of an API the OpenAPI Specification often conveys full documentation about the API.
"paths":{"/attendees":{"get":{"tags":["attendees-controller"],"summary":"Retrieve a list of all attendees stored within the system","operationId":"getAttendees","responses":{"200":{"description":"OK","content":{"*/*":{"schema":{"$ref":"#/components/schemas/AttendeeResponse"}}}}}}}},
The paths tag conveys the possible operations on the RESTful API and the expected request and response object formats.
In this example on a 200 status response the consumer can expect to receive an object AttendeeResponse.
The components object will describe the response has a key value containing the Attendee array.
The $ref tag indicates that this will be represented elsewhere in the specification.
"components":{"schemas":{"Attendee":{"title":"Attendee","required":["email","givenName","surname","displayName"],"type":"object","properties":{"displayName":{"type":"string"},"email":{"maxLength":254,"minLength":0,"type":"string"},"givenName":{"maxLength":35,"minLength":0,"type":"string"},"id":{"type":"integer","format":"int32"},"surname":{"maxLength":35,"minLength":0,"type":"string"}}},"AttendeeResponse":{"title":"AttendeeResponse","type":"object","properties":{"value":{"type":"array","items":{"$ref":"#/components/schemas/Attendee"}}}}}}}
Note
In addition to documentation the author can also supply example responses to demonstrate how the API should be used.
Components holds the various object schemas 1 for the specification and in this case defines our Attendee and AttendeeResponse object.
OpenAPI specifications can also include a wide range of additional metadata and useful features for developers and API consumers.
In the Attendees example the required fields of an Attendee are all fields except for id, at the time of generating an Attendee the consumer does not know the id.
The specification also sets out maximum lengths for some of the strings, it also possible to set a regular expression to pattern match email.
Full details of the OpenAPI Specification are hosted on the book’s GitHub.
Example requests and responses, like the one we’ve shown here, demonstrate a typical data exchange supported by the API. The OAS also documents the OAuth2 flows that are supported by an API, which we will explore further in Chapter 9. Over the course of the chapter it should become clear how important the OpenAPI Specification is to offering any type of REST API platform.
Visualizing OpenAPI Specifications
It’s quite difficult to read a specification in JSON or in YAML (which is also supported by OAS), especially as APIs grow beyond a handful of operations. The example specification above includes no user documentation. When documentation is added specifications can rapidly become thousands of lines long, which makes the specification difficult to read without a tool. One of the big success stories of OpenAPI Specifications has been the number of tools available in many different languages. There are tools that enable the developer to generate OpenAPI Specifications directly from their code or use the Swagger Editor.
Practical Application of OpenAPI Specifications
Once an OpenAPI Specification is shared the power of the specification starts to become apparent. OpenAPI.Tools documents a full range of open and closed source tools available. In this section we will explore some of the practical applications of tools based on their interaction with the OpenAPI Specification.
Code Generation
Perhaps one of the most useful features of an OpenAPI specification is allowing the generation of client side code to consume the API. As discussed in “Specifying REST APIs” we can include the full details of the server, security and of course the API structure itself. With all this information we can generate a series of model and service objects that represent and invoke the API. The OpenAPI Generator project supports a wide range of languages and tool chains. For example, in Java you can choose to use Spring or JAX-RS and in Typescript you can choose a combination of Typescript with your favorite framework. It is also possible to generate the API implementation stubs from the OpenAPI Specification.
This raises an important question about what should come first the specification or the server side code? In the next chapter we are going to discuss “API Contracts” which presents a behavior driven approach to testing and building APIs. The challenge with OpenAPI Specifications is that alone they only convey the shape of the API. OpenAPI specifications do not fully model the semantics (or expected behavior of the API) under different conditions. If you are going to present an API to external users it is important that the range of behaviors is modelled and tested to help avoid having to drastically change the API later.
A common challenge with API modelling, as discussed in “The Richardson Maturity Model”, is determining whether you need a RESTful API or whether you need RPC. We will explore this idea further in “Alternative API Formats”. It is important that this is an active decision, as delivering RPC over REST can result in a modelling mistake and a challenge for consumers. APIs should be designed from the perspective of the consumer and abstract away from the underlying representation behind the scenes. It is important to be able to freely refactor components behind the scenes without breaking API compatibility, otherwise the API abstraction loses value.
OpenAPI Validation
OpenAPI Specifications are useful for validating the content of an exchange to ensure the request and response match the expectations of the specification. At first it might not seem apparent where this would be useful, if code is generated surely the exchange will always be right? One practical application of OpenAPI validation is in securing APIs and API infrastructure. In many organizations a zonal architecture is common, with a notion of a DMZ (Demilitarized Zone) used to shield a network from inbound traffic. A useful feature is to interrogate messages in the DMZ and terminate the traffic if the specification does not match.
Atlassian, for example, Open Sourced a tool called the swagger-request-validator, which is capable of validating JSON REST content.
The project also has adapters that integrate with various mocking and testing frameworks to help ensure that API Specifications are conformed to as part of testing.
The tool has an OpenApiInteractionValidator which is used to create a ValidationReport on an exchange.
//Using the location of the specification create an interaction validator//The base path override is useful if the validator will be used behind a gateway/proxyfinalOpenApiInteractionValidatorvalidator=OpenApiInteractionValidator.createForSpecificationUrl(specUrl).withBasePathOverride(basePathOverride).build;//Requests and Response objects can be converted or created using a builderfinalValidationReportreport=validator.validate(request,response);if(report.hasErrors()){// Capture or process error information}
Examples and Mocking
The OpenAPI Specification can provide example responses for the paths in the specification. Examples, as we’ve discussed, are useful for documentation to help developers understand the API usage. Some products have started to use examples to allow the user to query the API and return example responses from a mock service. This can be really useful in features such as a Developer Portal, which allows developers to explore documentation and invoke APIs.
Examples can potentially introduce an interesting problem, which is that this part of the specification is essentially a string (in order to model XML/JSON etc).
openapi-examples-validator 2 validates that an example matches the OpenAPI Specification for the corresponding request/response component of the API.
Detecting Changes
OpenAPI Specifications can also be useful in detecting changes in an API. This can be incredibly useful as part of a DevOps pipeline. Detecting changes for backwards compatibility is incredibly important, but first it is useful to understand versioning of APIs in more detail.
API Versioning
We have explored the advantages of sharing an OpenAPI specification with a consumer, including the speed of integration. Consider the case where multiple consumers start to operate against the API. What happens when there is a change to the API or one of the consumers requests the addition of new features to the API?
Let’s take a step back and think about if this was a code library built into our application at compile time. Any changes to the library would be packaged as a new version and until the code is recompiled and tested against the new version, there would be no impact to production applications. As APIs are running services, we have a couple of upgrade options that are immediately available to us when changes are requested:
-
Release a new version and deploy in a new location. Older applications continue to operate against the older version of the APIs. This is fine from a consumer perspective, as the consumer only upgrades to the new location and API if they need the new features. However, the owner of the API needs to maintain and manage multiple versions of the API, including any patching and bug fixing that might be necessary.
-
Release a new version of the API that is backwards compatible with the previous version of the API. This allows additive changes without impacting existing users of the API. There are no changes required by the consumer, but we may need to consider downtime or availability of both old and new versions during the upgrade. If there is a small bug fix that changes something as small as an incorrect fieldname, this would break compatibility.
-
Break compatibility with the previous API and all consumers must upgrade code to use the API. This seems like an awful idea at first, as that would result in things breaking unexpectedly in production.3 However a situation may present itself where we cannot avoid breaking compatibility with older versions. One example where APIs have had to break compatibility for a legal reasons was the introduction of GDPR (General Data Protection Regulation) in Europe.
The challenge is that each of these different upgrade options offer advantages, but also drawbacks either to the consumer or the API owner. The reality is that we want to be able to support a combination of all three options. In order to do this we need to introduce rules around versioning and how versions are exposed to the consumer.
Semantic Versioning
Semantic Versioning offers an approach that we can apply to REST APIs to give us a combination of the above. Semantic versioning defines a numerical representation attributed to an API release. That number is based on the change in behavior in comparison to the previous version, using the following rules.
-
A Major version introduces non-compatible changes with previous versions of the API. In an API platform upgrading to a new major version is an active decision by the consumer. There is likely going to be a migration guide and tracking as consumers upgrade to the new API.
-
A Minor version introduces a backwards compatible change with the previous version of the API. In an API service platform it is acceptable for consumer to receive minor versions without making an active change on the client side.
-
A Patch version does not change or introduce new functionality, but is used for bug fixes on an existing Major.Minor version of functionality.
Formatting for semantic versioning can be represented as Major.Minor.Patch.
For example 1.5.1 would represent major version 1, minor version 5 with patch upgrade of 1.
Whilst reading the above the reader may have noticed that with APIs running as services there is another important aspect to the story.
Versioning alone is not enough, an element of deployment and what is exposed to the consumer at what time is part of the challenge.
This is where the API Lifecycle is important to consider, n terms of versioning.
API Lifecycle
The API space is moving quickly, but one of the clearest representations of version lifecycle comes from the now archived PayPal API Standards. The lifecycle is defined as follows:
Planned |
Exposing an API from a technology perspective is quite straightforward, however once it is exposed and consumed we have multiple parties that need to be managed. The planning stage is about advertising that you are building an API to the rest of the API program. This allows a discussion to be had about the API and the scope of what it should cover. |
Beta |
Involves releasing a version of our API for users to start to integrate with, however this is generally for the purpose of feedback and improving the API. At this stage the producer reserves the right to break compatibility, it is not a versioned API. This helps to get rapid feedback from consumers about the design of the API before settling on a structure. A round of feedback and changes enables the producer to avoid having many major versions at the start of the APIs lifetime. |
Live |
The API is now versioned and live in production. Any changes from this point onward would be versioned changes. There should only ever be one live API, which marks the most recent major/minor version combination. Whenever a new version is released the current live API moves to deprecated. |
Deprecated |
When an API is deprecated it is still available for use, but significant new development should not be carried out against it. When a minor version of a new API is released an API will only be deprecated for a short time, until validation of the new API in production is complete. After the new version is successfully validated a minor version moves to retired, as the new version is backwards compatible and can handle the same features as the previous API. When a major version of the API is released the older version becomes deprecated. It is likely that will be for weeks or months, as an opportunity must be given to consumers to migrate to the new version. There is likely going to be communication with the consumers, a migration guide and tracking of metrics and usage of the deprecated API. |
Retired |
The API is retired from production and is no longer accessible. |
The lifecycle helps the consumer fully understand what to expect from the API. The main question is what does the consumer see with respect to the versioning and lifecycle? With Semantic Versioning combined with the API Lifecycle the consumer only needs to be aware of the major version of the API. Minor and patch versions will be received without updates required on the consumers side and won’t break compatibility.
One often controversial question is how should the major version be exposed to the user. One way is to expose the major version in the URL i.e. http://mastering-api.com/v1/attendees. From a purely RESTful perspective however the version is not part of the resource. Having the major version as part of the URL makes it clear to the consumer what they are consuming. A more RESTful way is to have the major version as part of the header, e.g. VERSION: 1. Having the version in a header may be slightly hidden from the consumer. A decision would need to be made to be consistent across APIs.
You may be wondering how APIs with multiple versions can be presented side-by-side during deployments and route to specific API services. We will explore this further in Chapter 4 and in Chapter 5.
OpenAPI Specification and Versioning
Now that we have explored versioning we can look at examples of breaking changes and non breaking changes using the attendees API specification. There are several tools to choose from to compare specifications, in this example we will use openapi-diff from OpenAPITools.
We will start with a breaking change.
We will change givenName to be a field called firstName.
We can run the diff tool from a docker container using the following command:
$docker run --rm -t
-v $(pwd):/specs:ro
openapitools/openapi-diff:latest /specs/original.json /specs/first-name.json
==========================================================================
== API CHANGE LOG ==
==========================================================================
Attendees Mastering API
--------------------------------------------------------------------------
What's Changed --
--------------------------------------------------------------------------
- GET /attendees
Return Type:
- Changed 200 OK
Media types:
- Changed */*
Schema: Broken compatibility
Missing property: [n].givenName (string)
--------------------------------------------------------------------------
Result --
--------------------------------------------------------------------------
API changes broke backward compatibility
Tip
The -v $(pwd):/specs:ro adds the present working directory to the container under the /specs mount as read only.
We can try to add a new attribute to the /attendees return type to add an additional field age.
Adding new fields does not break existing behavior and therefore does not break compatibility.
$ docker run --rm -t
-v $(pwd):/specs:ro
openapitools/openapi-diff:latest --info /specs/original.json /specs/age.json
==========================================================================
== API CHANGE LOG ==
==========================================================================
Attendees Mastering API
--------------------------------------------------------------------------
What's Changed --
--------------------------------------------------------------------------
- GET /attendees
Return Type:
- Changed 200 OK
Media types:
- Changed */*
Schema: Backward compatible
--------------------------------------------------------------------------
Result --
--------------------------------------------------------------------------
API changes are backward compatible
It is worth trying this out to see what would be compatible changes and what would not. Introducing this type of tooling as part of the API pipeline is going to help avoid unexpected non compatible changes for consumers. OpenAPI specifications are an important part of an API program, and when combined with tooling, versioning and lifecycle they are invaluable.
Alternative API Formats
REST APIs work incredibly well for extending services to external consumers. From the consumer perspective the API is clearly defined, won’t break unexpectedly and all major languages are supported. But, is using a REST API for every exchange in a microservices based architecture the right approach? For the remainder of the chapter we will discuss the various API formats available to us and factors that will help determine the best solution to our problem.
Remote Procedure Call (RPC)
Remote Procedure Calls (RPC) are definitely not a new concept. RPC involves executing code or a function of another process. It is an API, but unlike a REST API it generally exposes the underlying system or function internals. With RPC the model tends to convey the exact functionality at a method level that is required from a secondary service.
RPC is different from REST as REST focuses on building a model of the domain and extending an abstraction to the consumer. REST hides the system details from the user, RPC exposes it. RPC involves exposing a method from one process and allows it to be called directly from another.
gRPC is a modern open source high performance Remote Procedure Call (RPC). gRPC is under stewardship of the Linux Foundation and is the defacto standard for RPC across most platforms. Figure 2-2 describes an RPC call in gRPC, which involves the Schedule Service invoking the remote method on the Attendees Service. THe gRPC Attendees Service creates a server, allowing methods to be invoked remotely. On the client side, the Schedule Service, a stub is used to abstract the complexity of making the remote call into the library.

Figure 2-2. Example Attendees with RPC using gRPC
Another key difference between REST and RPC is state, REST is by definition stateless - with RPC state depends on the implementation. The authors have seen huge systems built around SOAP, which was the XML-RPC successor of the noughties! Many systems have been built around content based routing of messages to specific services with the right cached state to handle the request. In state based RPC systems the developer must have a detailed understanding of each exchange and expected behavior. In order to scale, systems start to leak business logic into routing, which if not carefully managed can lead to increased complexity.
Implementing RPC with gRPC
The Attendees service could model either a North→South or East→West API. In addition to modelling a REST API we are going to evolve the Attendees service to support gRPC.
Tip
East→West such as Attendees tend to be higher traffic, and can be implemented as microservices used across the architecture. gRPC may be a more suitable tool than REST for East→West services, owing to the smaller data transmission and speed within the ecosystem. Any performance decisions should always be measured in order to be informed.
Let’s explore using a Spring Boot Starter to rapidly create a gRPC server. The Java code below demonstrates a simple structure for implementing the behavior on the generated gRPC server classes.
@GrpcServicepublicclassAttendeesServiceImplextendsAttendeesServiceGrpc.AttendeesServiceImplBase{@OverridepublicvoidgetAttendees(AttendeesRequestrequest,StreamObserver<AttendeeResponse>responseObserver){AttendeeResponse.BuilderresponseBuilder=AttendeeResponse.newBuilder();//populate responseresponseObserver.onNext(responseBuilder.build());responseObserver.onCompleted();}}
The following .proto file defines an empty request and returns a repeated Attendee response.
In protocols used for binary representations it is important to note that position and order of fields is important, as they govern the layout of the message.
Adding a new service or new method is backward compatible as is adding a field to a message, but care is required.
Removing a field or renaming a field will break compatibility, as will changing the datatype of a field.
Changing the field number is also an issue as field numbers are used to identify fields on the wire.
The restrictions of encoding with gRPC mean the definition must be very specific.
REST and OpenAPI are quite forgiving as the specification is only a guide 4.
Extra fields and ordering do not matter in OpenAPI, versioning and compatibility is therefore even more important when it comes to gRPC.
The following .proto file models the same attendee object that we explored in our OpenAPI Specification example.
syntax = "proto3";
option java_multiple_files = true;
package com.masteringapi.attendees.grpc.server;
message AttendeesRequest {
}
message Attendee {
int32 id = 1;
string givenName = 2;
string surname = 3;
string email = 4;
}
message AttendeeResponse {
repeated Attendee attendees = 1;
}
service AttendeesService {
rpc getAttendees(AttendeesRequest) returns (AttendeeResponse);
}
The Java service modelling this example can be found on the Book GitHub page.
gRPC cannot be queried directly from a browser without additional libraries, however you can install gRPC UI to use the browser for testing.
grpcurl also provides a command line tool:
$grpcurl -plaintext localhost:9090com.masteringapi.attendees.grpc.server.AttendeesService/getAttendees{"attendees":[{"id": 1,"givenName":"Jim","surname":"Gough","email":"[email protected]"}]}
gRPC gives us another option for querying our service and defines a specification for the consumer to generate code. gRPC has a more strict specification than OpenAPI and requires methods/internals to be understood by the consumer.
GraphQL
RPC offers access to a series of individual functions provided by a producer, but does not usually extend a model or abstraction to the consumer. REST extends a resource model for a single API provided by the producer. It is possible to offer multiple APIs on the same base URL by combining REST APIs together using API Gateways. We will explore this notion further in Chapter 4. If we offer multiple APIs in this way the consumer will need to query the APIs sequentially to build up state on the client side. This approach is also wasteful if the client is only interested in a subset of fields on the API response. Consider a user interface that models a dashboard of data on our conference system using visual tiles. Each individual tile would need to invoke each API to populate the UI to display the tile content the user is interested in. Figure 2-3 shows the number of invocations required.
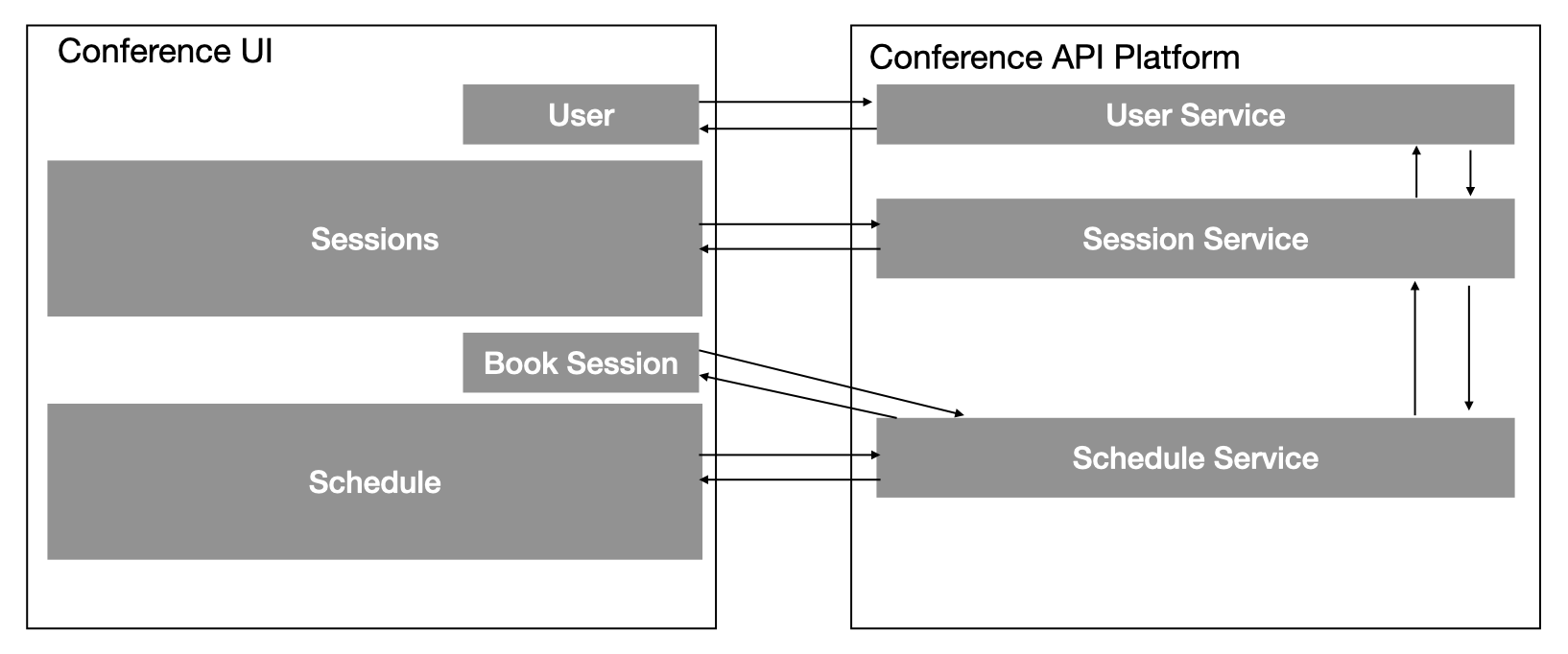
Figure 2-3. Example User Interface model
GraphQL introduces a technology layer over existing services, data stores and APIs that provides a query language to query across multiple sources. The query language allows the client to ask for exactly the fields required, including fields that span across multiple APIs.
GraphQL introduces the GraphQL schema language, which is used to specify the types in individual APIs and how APIs combine. One major advantage of introducing a GraphQL schema is the ability to provide a single version across all APIs, removing the need for potentially complex version management on the consumer side.
After defining the schema the next consideration is the implementation of behavior and defining how data is retrieved and if necessary converted to match the schema.
A Resolver is a function that a GraphQL server implementor creates to source the data for data elements in the GraphQL schema.
Mark Stuart has written an excellent blog on GraphQL resolver best practices for PayPal Engineering.
Tip
One mistake that API developers and architects often make is assuming that GraphQL is only a technology used with User Interfaces. In systems where vast amounts of data is stored across different subsystems GraphQL can provide an ideal solution to abstracting away internal system complexity.
Lets implement a very trivial GraphQL schema for the /attendees call to look at what GraphQL looks like to the consumer.
varschema=buildSchema(`type Attendee {givenName: Stringsurname: StringdisplayName: Stringemail: Stringid: Int}type Query {attendees: [Attendee]}`);// Logic to resolve and fetch contentvarapp=express();app.use('/graphql',graphqlHTTP({schema:schema,rootValue:root,graphiql:true,}));app.listen(4000);
GraphQL has a single POST /graphql endpoint (not too dissimilar from RPC), however unlike RPC it is not single a method with set behavior that is invoked but a declarative request for specific elements of the schema.
curl -X POST -H"Content-Type: application/json"-d'{"query": "{ attendees { email } }"}'http://localhost:4000/graphql{"data":{"attendees":[{"email":"[email protected]"}]}}
Figure 2-4 shows how GraphiQL (a UI tool for GraphQL) provides the consumer with a graphical mechanism for building up queries, along with the ability to explore the schema data types.

Figure 2-4. Executing a Query from the GraphiQL UI
GraphQL is a fascinating technology and offers a complement to REST and RPC and in some cases will be a better choice. Learning GraphQL by Eve Porcello and Alex Banks offers an in-depth exploration for the curious architect. GraphQL works very well when the data and services that a team or company present are from a specific business domain. In the case where disparate APIs are presented externally GraphQL could introduce a complicated overhead to maintain if it tried to do too much. Whilst you can use GraphQL to normalize access to a domain, maintenance may be reduced if the services behind the scenes have already been normalized.
Exchanges and Choosing an API Format
Earlier, we discussed the concept of traffic patterns, and the difference between requests originating from outside the ecosystem and requests within the ecosystem. Traffic patterns are an important factor in determining the appropriate format of API for the problem at hand. When we have full control over the services and exchanges within our microservices based architecture, we can start to make compromises that we would not be able to make with external consumers.
It is important to recognize that the performance characteristics of an East→West service are likely to be more applicable than a North→South service. In a North→South exchange traffic originating from outside the API producer’s environment will generally involve the exchange using the internet. The internet introduces a high degree of latency, and an API architect should always consider the compounding effects of each service. In a microservices based architecture it is likely that one North→South request will involve multiple East→West exchanges. High traffic East→West exchange need to be efficient to avoid cascading slow-downs propagating back to the consumer.
High Traffic Services
In our example Attendees is a central service.
In a microservices based architecture components will keep track of an attendeeId.
APIs offered to consumers will potentially retrieve data stored in the Attendees service, and at scale it will be a high traffic component.
If the exchange frequency is high between services, the cost of network transfer due to payload size and limitations of one protocol vs another will be more profound as usage increases.
The cost can present itself in either monetary costs of each transfer or the total time taken for the message to reach the destination.
Large Exchange Payloads
Large payload sizes may also become a challenge in API exchanges and are susceptible to increasing transfer performance across the wire. JSON over REST is human readable, and will often be more verbose than a fixed or binary representation.
Tip
A common misconception is that “human readability” is quoted as a primary reason to use JSON in data transfers. The number of times a developer will need to read a message vs the performance consideration is not a strong case with modern tracing tools. It is also rare that large JSON files will be read from beginning to end. Better logging and error handling can mitigate the human readable argument.
Another factor in large payload exchanges is the time taken by components to parse the message content into language level domain objects. Performance time of parsing data formats varies vastly depending on the language a service is implemented in. Many traditional server side languages can struggle with JSON compared to a binary representation for example. It is worth exploring the impact of parsing and include that consideration when choosing an exchange format.
HTTP/2 Performance Benefits
Using HTTP/2 based services can help to improve performance of exchanges by supporting binary compression and framing. The binary framing layer is transparent to the developer, but behind the scenes will split and compress the message into smaller chunks. The advantage of binary framing is it allows for a full request and response multiplexing over a single connection. Consider processing a list in another service and the requirement is to retrieve 20 different attendees, if we retrieved these as individual HTTP/1 requests it would require the overhead of creating 20 new TCP connections. Multiplexing allows us to perform 20 individual requests over a single HTTP/2 connection.
gRPC uses HTTP/2 by default and reduces the size of exchange by using a binary protocol. If bandwidth is a concern or cost gRPC will provide an advantage, in particular as content payloads increase significantly in size. gRPC may be beneficial compared to REST if payload bandwidth is a cumulative concern or the service exchanges large volumes of data. If large volumes of data exchanges are frequent it is also worth considering some of the asynchronous capabilities of gRPC, which we will cover in Chapter 10.
Vintage Formats
Not all services in an architecture will be based on a modern design. In Chapter 6 we will look at how to isolate and evolve vintage components, however as part of an evolving architecture older components will be an active consideration. Many older services will use formats such as SOAP/XML over HTTP/TCP. It is important that an API architect understands the overall performance impact of introducing vintage components.
Performance Testing Exchanges
Recognizing the performance characteristics of exchanges is a useful skill for an API Architect to develop. Often it is not the network alone that needs to be considered - the test should include the network, parsing, responding to the query and returning a response. Smaller benchmarks do not capture the full picture, so it is important to look at the performance in the context of your system. Let’s explore the approach of a simple end-to-end performance test in the gRPC ecosystem.
Performance is at the heart of every build of the gRPC libraries, and a Performance Dashboard monitors each build and the impact of changes on performance. Buying into the gRPC ecosystem will provide a full stack of complementing libraries that work together in the target language for building services.
If performance is a primary concern for a service it is important to build a benchmark that can be used to test changes to code and libraries over time.
We can use a gRPC benchmarking tool ghz to get an idea of the performance of the attendees service.
brew install ghz
ghz --insecure --format=html --total=10000
--proto ./attendees.proto
--call com.masteringapi.attendees.grpc.server.AttendeesService.getAttendees
-d {} localhost:9090 > results.html
Figure 2-5 shows a graphical representation of the the performance of 10,000 requests. The average response time was 2.49 milliseconds, the slowest response time was 14.22 milliseconds and the fastest was 0.16ms.

Figure 2-5. GHZ gRPC Benchmark Tool - https://github.com/bojand/ghz
Tip
We want to avoid premature optimization and benchmarks without analysis can lead to a confirmation bias. gRPC will provide performance benefits, but it is important to consider the consumer and their expectations of the API.
gRPC also supports asynchronous and streaming APIs, we will spend Chapter 10 discussing asynchronous approaches to APIs. If services are constantly exchanging information an open asynchronous pipe would offer advantages over an individual request/response model. In Chapter 5 we will explore alternative approaches to testing and monitoring the behavior of applications and exchanges in production.
Checklist: Modelling Exchanges
Decision |
What format should we use to model the API for our service? |
Discussion Points |
Is the exchange a North→South or East→West exchange? Are we in control of the consumer code? Is there a strong business domain across multiple services or do we want to allow consumers to construct their own queries? What versioning considerations do we need to have? What is the deployment/change frequency of the underlying data model. Is this a high traffic service where bandwidth or performance concerns have been raised? |
Recommendations |
If the API is consumed by external users REST is the lowest barrier to entry and provides a strong domain model. If the APIs offered connect well together and users are likely to use the API to query across APIs frequently consider using GraphQL. If the API is interacting between two services under close control of the producer or the service is proven to be high traffic consider gRPC. |
Multiple Specifications
In this chapter we have explored a variety of API formats for an API Architect to consider and perhaps the final question is “Can we provide all formats?”. The answer is yes we can support an API that has a RESTful presentation, a gRPC service and connections into a GraphQL schema. However, it is not going to be easy and may not be the right thing to do. In this final section we will explore some of the options available for a multi-format API and the challenges it can present.
The Golden Specification
The .proto file for attendees and the OpenAPI specification do not look too dissimilar, they contain the same fields and both have data types.
Is it possible to generate a .proto file from an OpenAPI specification using the openapi2proto tool?
Running openapi2proto --spec spec-v2.json will output the .proto file with fields ordered alphabetically by default.
This is fine until we add a new field to the OpenAPI specification that is backwards compatible and suddenly the ID of all fields changes, breaking backwards compatibility.
The sample .proto file below shoes that adding a_new_filed would be alphabetically added to the beginning, changing the binary format and breaking existing services.
message Attendee {
string a_new_field = 1;
string email = 2;
string givenName = 3;
int32 id = 4;
string surname = 5;
}
OpenAPI specifications support the idea of extensions, and by using the openapi2proto specific OpenAPI extensions it is possible to generate the compatibility between the two mechanisms of specification.
Note
There are other tools available to solve the specification conversion problem, however it is worth noting that some tools only support OpenAPI Specification version 2. The time taken to move between version 2 and 3 in some of the tools built around OpenAPI has led to many products needing to support both versions of the OAS.
An alternative option is grpc-gateway, which generates a reverse-proxy providing a REST facade in front of the gRPC service.
The reverse proxy is generated at build time against the .proto file and will produce a best effort mapping to REST, similar to openapi2proto.
You can also supply extensions within the .proto file to map the RPC methods to a nice representation in the OpenAPI specification.
import "google/api/annotations.proto";
//...
service AttendeesService {
rpc getAttendees(AttendeesRequest) returns (AttendeeResponse) {
option(google.api.http) = {
get: "/attendees"
};
}
Using grpc-gateway gives us another option for presenting both a REST and gRPC service. However, grpc-gateway involves several commands and setup that would only be familiar to developers who work with the go language or build environment.
Challenges of Combined Specifications
It’s important to take a step back here and consider what we are trying to do. When converting from OpenAPI we are effectively trying to convert our RESTful representation into a gRPC series of calls. We are tying to covert an extended hypermedia domain model into a lower level function to function call. This is a potential conflation of the difference between RPC and APIs and is likely going to result in wrestling with compatibility.
With converting gRPC to OpenAPI we have a similar issue, the objective is trying to take gRPC and make it look like a REST API. This is likely going to create a difficult series of issues when evolving the service.
Once specifications are combined or generated from one another, versioning becomes a challenge. It is important to be mindful of how both the gRPC and OpenAPI specifications maintain their individual compatibility requirements. An active decision should be made as to whether coupling the REST domain to an RPC domain makes sense and adds overall value. Rather than generate RPC for East→West from North→South, what makes more sense is to carefully design the microservices based architecture (RPC) communication independently from the REST representation, allowing both APIs to evolve freely.
GraphQL offers a mechanism that is version-less from the consumers perspective, they interact with only the data that they wish to retrieve. This is at the cost to the producer in maintaining a GraphQL Schema and logic that is used to fetch and resolve data from the underlying services. It is possible to offer REST APIs to external users and then use the separate GraphQL server to aggregate together APIs that have combined domains. It is also possible to use GraphQL to present RPC based services in a normalized schema to clients.
Summary
In this chapter we have scratched the surface of a variety of topics that an API Architect, API developer or individuals involved in an API program perspective must appreciate.
-
The barrier to building a REST API is really low 5 in most technologies.
-
REST is a fairly loose standard and for building APIs, conforming to an agreed API Standards ensures our APIs are consistent and have the expected behavior for our consumers.
-
OpenAPI specifications are a useful way of sharing API structure and automating many coding related activities. Teams should actively select OpenAPI features within their platform and choose what tooling or generation features will be applied to projects.
-
Versioning is an important topic that adds complexity for the API producer but is necessary to ease API usage for the API consumer. Not planning for versioning in APIs exposed to consumers is dangerous. Versioning should be an active decision in the product feature set and a mechanism to convey versioning to consumers should be part of the discussion. Versioning alone is usually not enough and ensuring we have an API Lifecycle to help govern versioning will lead to a successful API offering.
-
REST is great, but is it not always the best option especially when traffic patterns and performance concerns are factored in. It is important to consider how we approach and model exchanges of information in our microservices based architecture. gRPC and GraphQL provide options that need to be considered when we design our exchange modelling.
-
Modelling multiple specifications starts to become quite tricky, especially when generating from one type of specification to another. Versioning complicates matters further but is an important factor to avoid breaking changes. Teams should think carefully before combining RPC representations with RESTful API representations, as there are fundamental differences in terms of usage and control over the consumer code.
The challenge for an API architect is to drive the requirements from a consumer business perspective, create a great developer experience around APIs, and avoid unexpected compatibility issues.
1 The schema object is an extended subset of the JSON Schema Specification Wright Draft 00.
2 https://github.com/codekie/openapi-examples-validator
3 The authors have been in this situation many times, usually first thing on a Monday!
4 Validation of OpenAPI specifications at runtime helps enforce a greater strictness of OpenAPI Specifications.
5 Anecdotally, whilst researching this chapter some developers claim it is 10 minutes.