
Chapter 4. API Gateways
Now that you have a good understanding of the life of an API, the protocols involved, and how to begin testing, we can turn our attention to platforms and tooling that are responsible for delivering APIs to end users in production. An API gateway is a critical part of any modern technology stack, sitting at the “edge” of systems and acting as a management tool that mediates between a client and a collection of backend services.
In this chapter you will learn about the “what,” “where,” and “why” of API gateways, and also explore the history of the API gateway and other edge technologies. In order to build upon the success of previous generations of engineers and developers, it is important that you understand the evolution of this technology and examine how this relates to important architectural concepts like coupling and cohesion.
You will also explore the taxonomy of API gateways, and learn how these fit into the bigger picture of system architecture and deployment models. You will revisit your earlier exploration of ingress (“north-south”) traffic and service-to-service (“east-west”) traffic, and explore the technologies that can be used to manage each traffic type. You will also explore the challenges and potential antipatterns when mixing traffic patterns and technologies.
Building on all of the topics above, you will conclude the chapter by learning how to select an appropriate API gateway based on your requirements, constraints, and use cases.
What Is an API Gateway?
In a nutshell, an API gateway is a management tool that sits at the edge of a system between a client and a collection of backend services and acts as a single point of entry for a defined group of APIs. The client can be an end-user application or device, such as a single page web application or a mobile app, or another internal system or third-party application or system.
As introduced in Chapter 1, an API gateway is implemented with two high-level fundamental components, a control plane and data plane. The control plane is where operators interact with the gateway and define routes, policies, and required telemetry, and the data plane is the location where all of the work specified in the control plane occurs; where the network packets are routed, the policies enforced, and telemetry emitted.
What Functionality Does an API Gateway Provide?
At a network level an API gateway typically acts as a reverse proxy to accept all of the API requests from a client, calls and aggregates the various application-level backend services (and potentially external services) required to fulfill them, and returns the appropriate result. An API gateway provides cross-cutting requirements such as user authentication, request rate limiting, timeouts/retries, and observability. Many API gateways provide additional features that enable developers to manage the lifecycle of an API, assist with the onboarding and management of developers using the APIs (such as providing a developer portal and related account administration and access control), and provide enterprise governance.
Where Is an API Gateway Deployed?
An API gateway is typically deployed at the edge of a system, but the definition of “system” in this case can be quite flexible. For startups and many small-medium businesses (SMBs) an API gateway will often be deployed at the edge of the data center or cloud. In these situations there may only be a single API gateway (deployed and running via multiple instances for high availability) that acts as the front door for the entire back end estate, and the API gateway will provide all of the edge functionality discussed in this chapter via this single component.
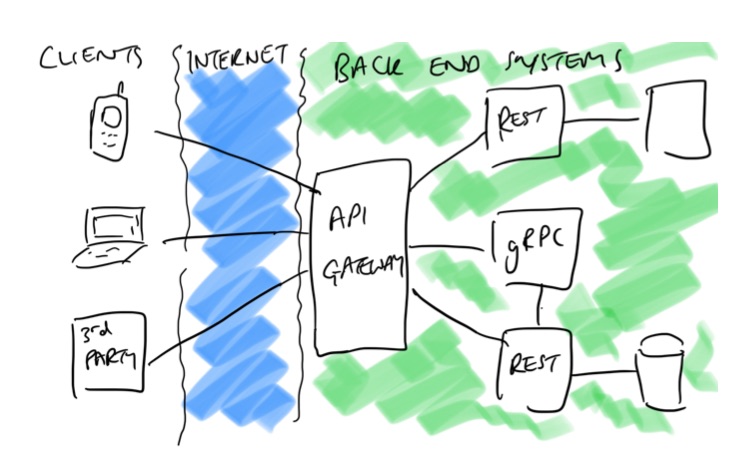
Figure 4-1. A typical startup/SMB API gateway deployment
For large organizations and enterprises an API gateway will typically be deployed in multiple locations, often as part of the initial edge stack at the perimeter of a data center, and additional gateways may be deployed as part of each product, line of business, or organizational department.
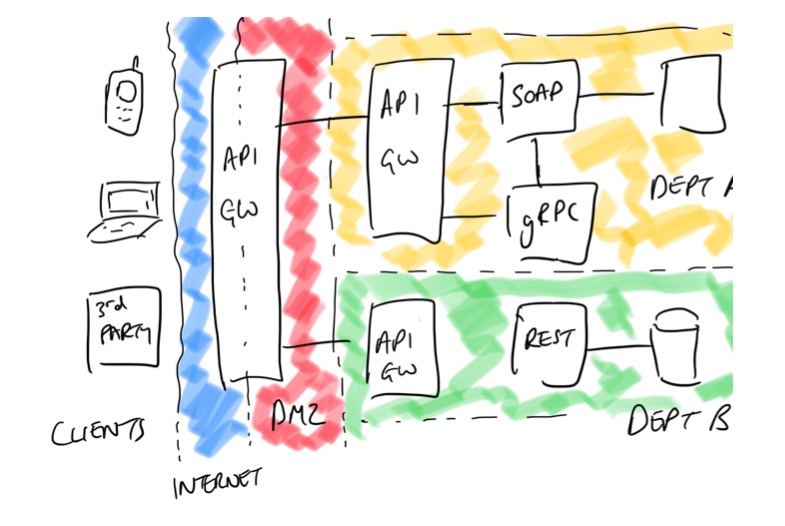
Figure 4-2. A typical large/enterprise API gateway deployment
As you will learn later in this chapter, the definition and exact functionality offered within an API gateway isn’t always consistent across implementations, and so the diagrams above should be thought of as more conceptual rather than logical.
How Does an API Gateway Integrate with a Typical Edge Stack?
There is typically many components deployed at the edge of an API-based system. This is where the clients and users first interact with the backend, and hence many cross-cutting concerns are best addressed here. Therefore, a modern “edge stack” provides a range of functionality that meets essential cross functional requirements for API-based applications. In some edge stacks each piece of functionality is provided by a separately deployed and operated component, and in others the functionality and/or components are combined. You will learn more about the individual requirements in the next section of the chapter, but for the moment the diagram below should highlight the key layers of a modern edge stack.
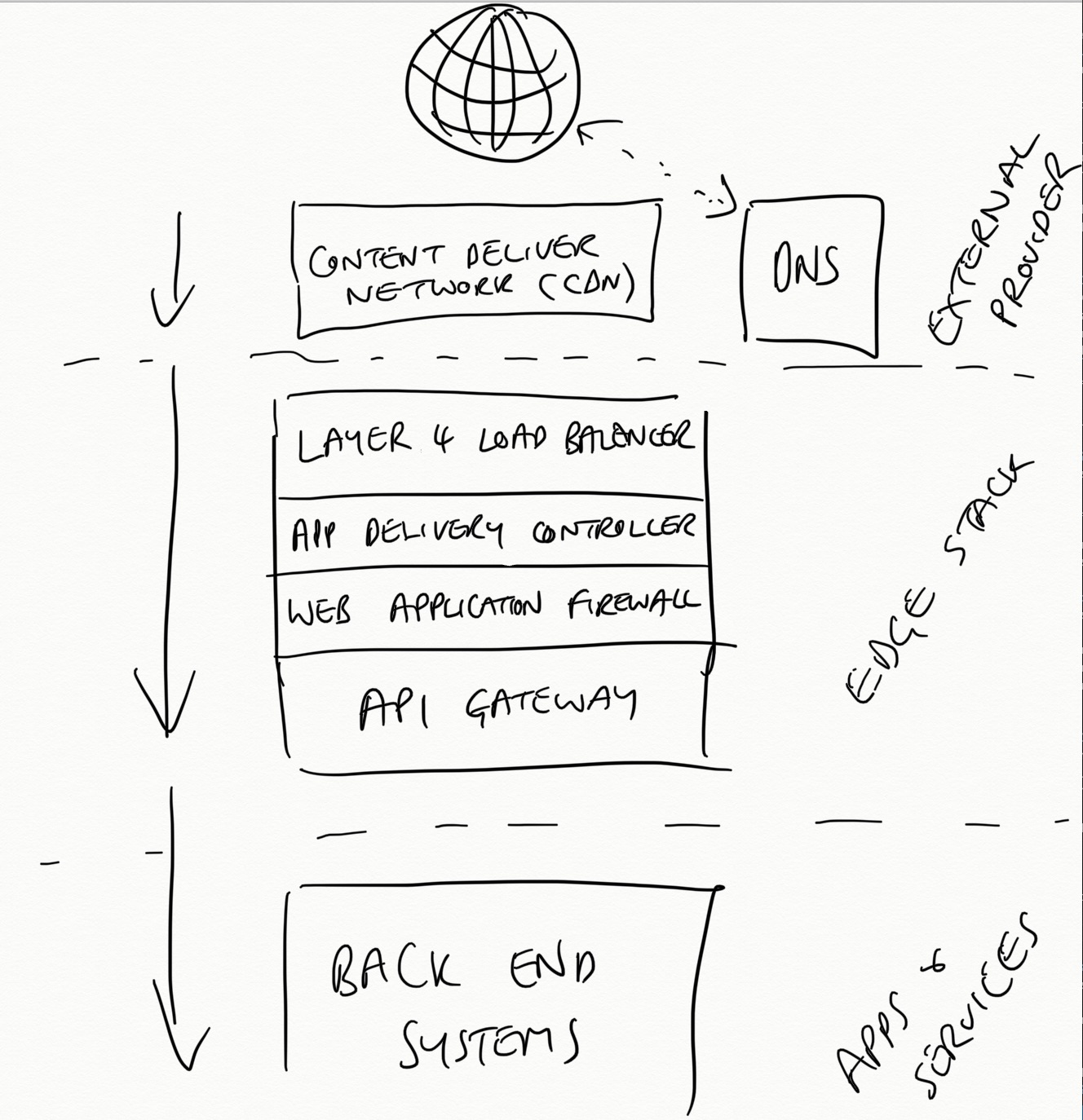
Figure 4-3. A modern edge stack
Now that you have a good idea about the “what” and “where” of an API gateway, let’s now look at why an organization would use an API gateway.
Why Use an API Gateway?
Establishing clearly the business goals, technical challenges, and organizational constraints before choosing a solution that involves a piece of technology is a big part of the modern software architect’s role. It can be tempting to deploy technology for technology’s sake, or add layer after layer of technology to a system—who hasn’t heard the cliche that every problem in software can be solved with another layer of indirection. It is therefore vital that you understand the goals, benefits, and drawbacks of modern API gateway technology, and can clearly articulate they “why” of this component to both technical and non technical stakeholders. This section of the chapter will provide you with an overview of the key problems that an API gateway can address, such as:
-
Reduce Coupling: Adapter / Facade Between Front Ends and Back Ends
-
Simplify Consumption: Aggregating / Translating Back End Services
-
Protect APIs from Overuse and Abuse: Threat Detection and Mitigation
-
Understand How APIs Are Being Consumed: Observability
-
Manage APIs as Products: API Lifecycle Management
-
Monetize APIs: Account Management, Billing, and Payment
Reduce Coupling: Adapter / Facade Between Front Ends and Back Ends
Two fundamental concepts that every software architect learns about early in their career are coupling and cohesion. You are taught that systems that are designed to exhibit loose coupling and high cohesion will be easier to understand, maintain and modify. Loose coupling allows different implementations to be swapped in easily, and internals to be modified without experiencing unintended cascading effects on surrounding modules or systems. High cohesion promotes understandabilty—i.e., all code in a module or system supports a central purpose—and reliability and reusability. In our experience, APIs are often the locations in a system in which the architectural theory meets the reality; an API is quite literally and figuratively an interface that other engineers integrate with.
Bounded Context, Contracts, and Coupling
You’ve already learned in earlier chapters that care should be taken with design of your API, as this is effectively a contract with your consumers. Like many tools, an API gateway can be used for good and evil: you can use functionality in the gateway to provide a more business-focused and cohesive API than the backend components may otherwise expose, but you can also add additional layers of indirection and complexity. Learning more about domain-driven design can provide you with useful knowledge about exposing systems, bounded contexts, and aggregates with the appropriate level of abstraction.
An API gateway can act as a single entry point and an adapter or facade (two classic Gang of Four design patterns), and hence promote loose coupling and cohesion. Clients integrate with the API exposed at the gateway, which, providing the agreed upon contract is maintained, allows components at the backend to change location, architecture, and implementation (language, framework, etc.) with minimal impact.

Figure 4-4. An API gateway providing a facade between front ends and back ends
Backends for Frontends (BFF): Single Point of Entry?
A popular architectural pattern for exposing APIs or back end functionality across multiple devices (or “experiences”, as this is often referred to) is the “backend for frontend (BFF)” pattern, popularized by Phil Calçado and the SoundCloud team. The BFF pattern can be implemented with in one of two styles: firstly, with one API gateway acting as a single point of entry that provides cross-cutting concerns, and which acts as an adapter to multiple BFF back ends; and secondly, with the use of multiple API gateways, each one providing cross-cutting concerns that are coupled to a specific BFF back end (e.g. “iOS API gateway and BFF,” “Web API gateway,” etc.). The first approach is commonly seen in enterprise organizations with strict governance requirements at the edge, where all traffic must be funneled through a single point of entry. The second is often used within smaller organizations when the cross-cutting concerns are different for each back end, e.g. differing authentication, protocols, and resiliency requirements.
Simplify Consumption: Aggregating / Translating Back End Services
Building on the discussion of coupling in the previous section, it is often the case that the API you want to expose to the front end systems is different than the current interface provided by a back end or composition of backend systems. For example, you may want to aggregate the APIs of several back end services that are owned by multiple owners into a single client-facing API in order to simplify the mental model for front end engineers, streamline data management, or hide the back end architecture. GraphQL is often used for exactly these reasons.
Orchestrating Concurrent API Calls
A popular simplification approach implemented in API gateways is orchestrating concurrent backend API calls. This is where the gateway orchestrates and coordinates the concurrent calling of multiple independent backend APIs. Typically you want to call multiple independent and non-coupled APIs in parallel rather than sequentially in order to save time when gathering results for the client. Providing this in the gateway removes the need to independently implement this functionality in each of the clients.
It is also common within an enterprise context that some protocol translation will be required. For example, you may have several “heritage” (money making) systems that provide SOAP-based APIs, but you only want to expose REST-like APIs to clients. Or your legacy systems may only support HTTP/1.1, but clients require HTTP/2 connections. Some organizations may implement all internal service APIs via gRPC and Protobuf, but want to expose external APIs using HTTP and JSON. The list goes on; the key point here is that some level of aggregation and translation is often required to meet externals requirement or provide further loose coupling between systems.
An API gateway can provide this aggregation and translation functionality. Implementations vary and can be as simple as exposing a single route and composing together (“mashing”) the responses from the associated multiple internal system, or providing a protocol upgrade from HTTP/1.1 to HTTP/2, all the way through to mapping individual elements from an internal API to a completely new external format and protocol.
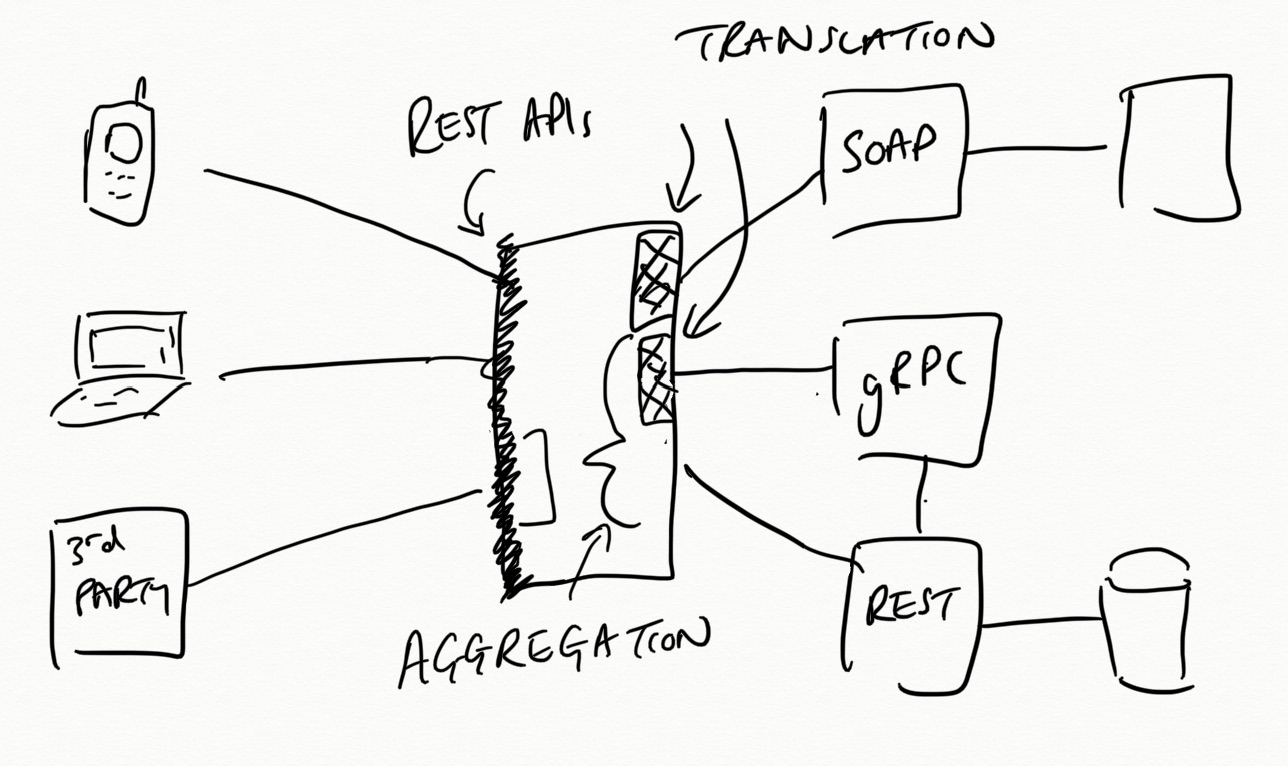
Figure 4-5. An API gateway providing aggregation and translation
Protect APIs from Overuse and Abuse: Threat Detection and Mitigation
The edge of a system is where your users first interact with your applications. It is also often the the point where bad actors and hackers first encounter your systems. Although the vast majority of enterprise organizations will have multiple security-focused layers to their edge stack, such as a content delivery network (CDN) and web application firewall (WAF), and even a perimeter network and dedicated demilitarised zone (DMZ), for many smaller organizations the API gateway can be the first line of defense. For this reason many API gateways include security-focused functionality, such as TLS termination, authentication/authorization, IP allow/deny lists, WAFs (either inbuilt or via external integration), and rate limiting and load shedding.

Figure 4-6. API gateway overuse and abuse
A big part of this functionality is the capability to detect API abuse, either accidental or deliberate, and for this you wil need to implement a comprehensive observability strategy.
Understand How APIs Are Being Consumed: Observability
Understanding how systems and applications are performing is vitally important for ensuring business goals are being met and that customer requirements are being satisfied. It is increasingly common to measure business objectives via key performance indicators (KPIs), such as customer conversion, revenue per hour, stream starts per second etc. Infrastructure and platforms are typically observed through the lens of service level indicators (SLIs), such as latency, errors, queue depth, etc. As the vast majority (if not all) of user requests flow through the edge of a system, this is a vital point for observability. It is a ideal location to capture top-line metrics, such as the number of errors, throughput, and latency, and it is also a key location for identifying and annotating requests (potentially with application-specific metadata) that flow throughout the system further upstream. Correlation identifiers (such as OpenZipkin b3 headers) are typically injected into a request via the API gateway and are then propagated by each upstream service. These identifiers can then be used to correlate log entries and request traces across services and systems.
Although the emitting and collecting of observability data is important at the system-level, you will also need to think carefully how to process, analyse, and interpret this data into actionable information that can then be used to drive decision making. Creating dashboards for visual display and manipulation, and also defining alerts are vital for a successful observability strategy. Cindy Sridharan’s O’Reilly book Distributed Systems Observability is a great primer for this topic.
Manage APIs as Products: API Lifecycle Management
Modern APIs are often designed, built, and run as products that are consumed by both internal and third-parties, and must be managed as such. Many large organizations see APIs as a critical and strategic component within their business, and as such will create a API program strategy, and set clear goals, constraints, and resources. With a strategy set, the day-to-day tactical approach is often focused on application lifecycle management. Full lifecycle API management spans the entire lifespan of an API that begins at the planning stage and ends when an API is retired. Engineers interact with an associated API gateway, either directly or indirectly, within many of these stages, and all user traffic flows through the gateway. For these reasons, choosing an appropriate API gateway is a critical decision.
There are multiple definitions for key API lifecycle stages. The Swagger and SmartBear communities define the five key steps as: planning and designing the API, developing the API, testing the API, deploying the API, and retiring the API.
The 3Scale and Red Hat teams define thirteen steps:

Figure 4-7. The 3Scale and Red Hat teams approach to full API lifecycle management
The Axway team strike a good balance with 3 key components—create, control, and consume—and 10 top stages of an API lifecycle:
- Building
-
Designing and building your API.
- Testing
-
Verifying functionality, performance, and security expectations.
- Publishing
-
Exposing your APIs to developers.
- Securing
-
Mitigating security risks and concerns.
- Managing
-
Maintaining and managing APIs to ensure they are functional, up to date, and meeting business requirements.
- Onboarding
-
Enabling developers to quickly learn how to consume the APIs exposed. For example, offering OpenAPI or ASyncAPI documentation, and providing a portal and sandbox.
- Analyzing
-
Enabling observability, and analyzing monitoring data to understand usage and detect issues.
- Promoting
-
Advertising APIs to developers, for example, listing in an API Marketplace.
- Monetizing
-
Enabling the charging for and collection of revenue for use of an API. We cover this aspect of API lifecycle management as a separate stages in the next section.
- Retirement
-
Supporting the deprecation and removal of APIs, which happens for a variety of reasons including, business priority shifts, technology changes, and security concerns.
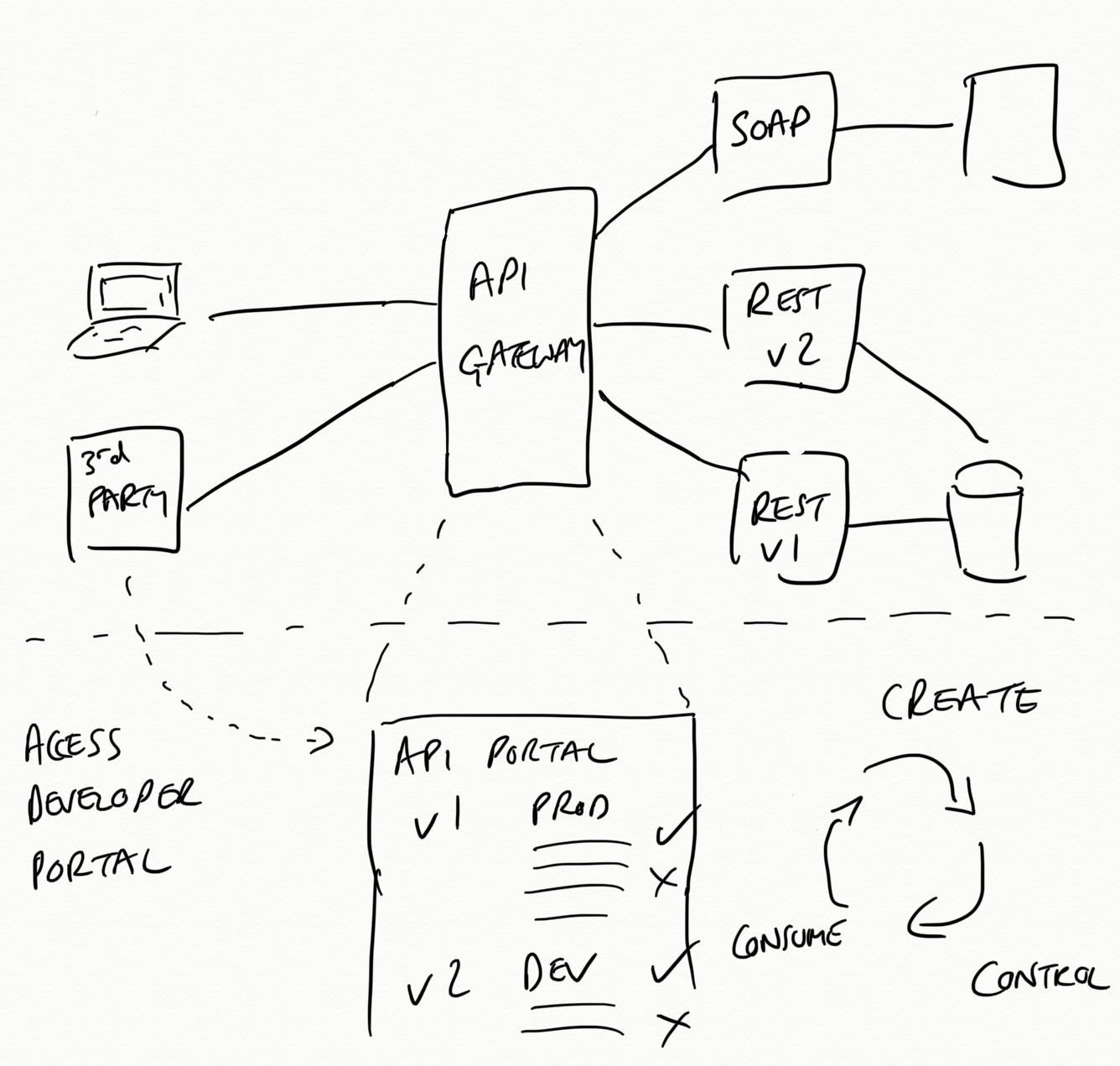
Figure 4-8. API gateway lifecycle management
Monetize APIs: Account Management, Billing, and Payment
The topic of billing monetized APIs is closely related to API lifecycle management. The APIs being exposed to customers typically have to be designed as a product, and offered via a developer portal that also includes account management and payment options. Many of the enterprise API gateways include monetization, such as Apigee Edge and 3Scale. These payment portals often integrate with payment solutions, such as PayPal or Stripe, and enable the configuration of developer plans, rate limits, and other API consumption options.
A Modern History of API Gateways
Now that you have a good understanding of the “what”, “where”, and “why” of API gateways, it is time to take a glance backwards through history before looking forward to current API gateway technology. As Mark Twain was alleged to have said, “history doesn’t repeat itself, but it often rhymes”, and anyone who has worked in technology for more than a few year will definitely appreciate the relevance this quote has to the general approach seen in the industry. Architecture style and patterns repeat in various “cycles” throughout the history of software development, as do operational approaches. There is typically progress made between these cycles, but it is also easy to miss the teachings that history has to offer.
This is why it is important that you understand the historical context of API gateways and traffic management at the edge of systems. By looking backwards we can build on firm foundations, understand fundamental requirements, and also try to avoid repeating the same mistakes.
Late 1990s: Hardware Load Balancers
The concept of World Wide Web (www) was proposed by Tim Berners-Lee in the late 1980s, but this didn’t enter the consciousness of the general public until the mid 1990s, where the initial hype culminated in the dotcom boom and bust of the late 90s. This “Web 1.0” period drove the evolution of web browsers (Netscape Navigator was launched late 1994), the web server (Apache Web Server was released in 1995), and hardware load balancers (F5 was founded in 1996). The Web 1.0 experience consisted of users visiting web sites via making HTTP requests using their browser, and the entire HTML document for each target page being returned in the response. Dynamic aspects of a website were implemented via Common Gateway Interface (CGI) in combination with scripts written in languages like Perl or C. This was arguably the first incantation of what we would call “Function as a Service (FaaS)” today.
As an increasing number of users accessed each website this strained the underlying web servers. The requirement to architect systems support increased load and implement fault tolerance was required. Hardware load balancers were deployed at the edge of the data center, with the goal of allowing infrastructure engineers, networking specialists, and sysadmins to spread user requests over a number of web server instances. These early load balancer implementations typically supported basic health checks, and if a web server failed or began responding with increased latency then user requests could be routed elsewhere accordingly.
Early 2000s: Software Load Balancers
As the Web overcame the early business stumbles from the dotcom bust, the demand for supporting a range of activities, such as users sharing content, ecommerce and online shopping, and businesses collaborating and integrating systems, continued to increase. In reaction, web-based software architectures began to take a number of forms. Smaller organizations were building on their early work with CGI and were also creating monolithic applications in the emerging web-friendly languages such asJava and .NET. Larger enterprises began to embrace modularization (taking their cues from David Parnas’ work in the 1970s), and Service Oriented Architecture (SOA) and the associated “Web Service” specifications (WS-) enjoyed a brief moment in the sun.
The requirements for high availability and scalability of web sites were increasing, and the expense and inflexibility of early hardware load balancers was beginning to become a constraining factor. Enter software load balancers, with HAProxy being launched in 2001 and NGINX in 2002. The target users were still operations teams, but the skills required meant that sysadmins comfortable with configuring software-based web servers were increasingly happy to take responsibility for what used to be a hardware concern.
Software Load Balancers: Still Going Strong
Although they have both evolved from initial launches, NGINX and HAProxy are still widely in use, and they are still very useful for small organizations and simple API gateway use cases (both also offer commercial variants more suitable for enterprise deployment). The rise of cloud (and virtualization) cemented the role of software load balancers, and we recommend learning about the basics of this technology.
This time frame also saw the rise of other edge technologies that still required specialized hardware implementation. Content Delivery Networks (CDNs), primarily driven by the Telco organizations, began to be increasingly adopted in order to offload requests from origin web servers. Web Application Firewalls (WAFs) also began to see increasing adoption, first implemented using specialized hardware, and later via software. The open source ModSecurity project, and the integration of this with the Apache Web Server, drove mass adoption of WAFs.
Mid 2000s: Application Delivery Controllers
The mid 2000s continued to see the increasing pervasiveness of the web in everyday life. The emergence of Internet capable phones only accelerated this, with BlackBerry initially leading the field, and everything kicking into a higher gear with the launch of the first iPhone in 2007. The PC-based web browser was still the de facto method of accessing the www, and the mid 2000s saw the emergence of “Web 2.0”, triggered primarily by the widespread adoption in browsers of the XMLHttpRequest API and the corresponding technique named “asynchronous JavaScript and XML (AJAX)”. At the time this technology was revolutionary. The asynchronous nature of the API meant that no longer did an entire HTML page have to be returned, parsed, and the display completed refreshed with each request. By decoupling the data interchange layer from the presentation layer, AJAX allowed web pages to change content dynamically without the need to reload the entire page.
All of these changes placed new demands on web servers and load balancers, for yet again handling more load, but also supporting more secure (SSL) traffic, increasingly large (media rich) data payloads, and different priority requests. This led to the emergence of a new technology named Application Delivery Controllers (ADCs). As these were initially implemented using specialized hardware this led to the existing networking players like F5 Networks, Citrix, Cisco dominating the market. ADCs provided support for compression, caching, connection multiplexing, traffic shaping, and SSL offload, combined with load balancing. The target users were once again infrastructure engineers, networking specialists, and sysadmins.
The Benefits, and Costs, of Specialization
By the mid 2000s nearly all of the components of modern edge stacks were widely adopted across the industry. The benefits of the separation of concerns were becoming clear (e.g. each edge technology had a clear and focused purpose), but this was increasingly the siloing between teams. If a developer wanted to expose a new application within a large organization this typically meant many separate meetings with the CDN vendors, the load balancing teams, the InfoSec and WAF teams, and the web/application server team. Movements like DevOps emerged, partly driven by a motivation to remove the friction imposed by these silos. If you still have a large number of layers in your edge stack and are migrating to the cloud or a new platform, now is the time to potentially think about the tradeoffs with multiple layers and specialist teams.
Early 2010s: First Generation API Gateways
The late 2000s and early 2010s saw the emergence of the API economy and associated technologies. Organizations like Twilio were disrupting telecommunications, with their founder, Jeff Lawson, pitching that “We have taken the entire messy and complex world of telephony and reduced it to five API calls.” The Google Maps API was enabling innovative user experiences, and Stripe was enabling organizations to easily charge for access to services. Founded in late 2007, Mashape was one of the early pioneers in attempting to create an API marketplace for developers. Although this exact vision didn’t pan out (arguably it was ahead of it’s time, looking now to the rise of “no code"/"low code” solutions), a byproduct of the Mashape business model was the creation of the Kong API Gateway, built upon OpenResty and the open source NGINX implementation. Other implementations included WSO2 with Cloud Services Gateway, Sonoa Systems with Apigee, and Red Ht with 3Scale Connect.
These were the first edge technologies that were targeted at developers in addition to platform teams and sysadmins. A big focus was on managing the software development lifecycle (SDLC) of an API and providing system integration functionality, such as endpoints and protocol connectors, and translation modules. Due to the range of functionality offered, the vast majority of first generation API gateways were implemented in software. Developer portals sprang up in many products, which allowed engineers to document and share their APIs in a structured way. These portals also provided access controls and user/developer account management, and publishing controls and analytics. The theory was that this would enable the easy monetization of APIs, and the management of “APIs as a product”.
During this evolution of developer interaction at the edge there was increasing focus on the application layer (layer 7) of the OSI Networking model. The previous generations of edge technologies often focused on IP addresses and ports, which primarily operate at the transport layer (layer 4) of the OSI model. Allowing developers to make routing decisions in an API gateway based on HTTP metadata such as path-based routing or header-based routing provided the opportunity for richer functionality.
There was also an emerging trend towards creating smaller service-based architectures, and some organizations were extracting single-purpose standalone applications from their existing monolithic code bases. Some of these monoliths acted as an API gateway, or provided API gateway-like functionality, such as routing and authentication. With the first generation of API gateways it was often the case that both functional and cross-functional concerns, such as routing, security, and resilience, were performed both at the edge and also within the applications and services.
Watch for Release Coupling When Migrating Away from a Monolith
Extracting standalone services from a monolithic application and having the monolith acting as a simple gateway can be a useful migration pattern towards adopting a microservices architecture. However, beware of the costs related to coupling between the application gateway and services that are introduced with this pattern. For example, although the newly extracted services can be deployed on demand, their release is often dependent on the release cadence of the monolith, as all traffic must be routed through this component. And if the monolith has an outage, then so do all of your services operating behind it.
2015 Onwards: Second Generation API Gateways
The mid 2010s saw the rise of the next generation of modular and service-oriented architectures, with the concept of “microservices” firmly entering the zeitgeist by 2015. This was largely thanks to “unicorn” organizations like Netflix, AWS, and Spotify sharing their experiences of working with these architectural patterns. In addition to back end systems being decomposed into more numerous and smaller services, developers were also adopting container technologies based on Linux LXC. Docker was released in March of 2013, and Kubernetes followed hot on it’s heels with a v1.0 release in July of 2015. This shift in architectural style and changing runtimes drove new requirements at the edge. Netflix released their bespoke JVM-based API gateway, Zuul, in mid 2013. Zuul supported service discovery for dynamic back end services and also allowed Groovy scripts to be injected at runtime in order to dynamically modify behaviour. This gateway also consolidated many cross cutting concerns into a single edge component, such as authentication, testing (canary releases), rate limiting and load shedding, and observability. Zuul was a revolutionary API gateway in the microservices space, and it has since involved into a second version, and Spring Cloud Gateway has been built on top of this.
Watch for Coupling of Business Logic in the Gateway
When using Zuul it was all too easy to accidentally highly couple the gateway with a service by including related business logic in both a Groovy script (or scripts) and the service. This meant that the deployment of a new version of a service often required modifications to the code running in the gateway. The pinnacle of this bad coupling can be seen when a microservice team decides to reuse an existing deployed Groovy script for their service, and then at an some arbitrary time in the future the script is modified by the original owning team in a incompatible way. This can quickly lead to confusion as to why things are broken, and also to whack-a-mole type fixes. This danger wasn’t unique to Zuul, and nearly all proxies and many gateways allowed the injection of plugins or dynamic behaviour, but this was often only accessible to operations teams or written in obscure (or unpopular) languages. The use of Groovy in Zuul made this very easy for application developers to implement.
With the increasing adoption of Kubernetes and the open source release of the Envoy Proxy in 2016 by the Lyft team, many API gateways were created around this technology, including Ambassador, Contour, and Gloo. This drove further innovation across the API gateway space, with Kong mirroring functionality offered by the next generation of gateways, and other gateways being launched, such as Traefik, Tyk, and others. Increasingly, many of the Kubernetes Ingress Controllers called themselves “API gateways”, regardless of the functionality they offered, and this led to some confusion for end users in this space.
API Gateways, Edge Proxies, and Ingress Controllers
As Christian Posta noted in his blog post API Gateways Are Going Through an Identity Crisis, there is some confusion around what an API gateway is in relation to edge technologies emerging from the cloud space. Generally speaking, in this context an API gateway enables some form of management of APIs, ranging from simple adaptor-style functionality operating at the application layer (OSI layer 7) that provides fundamental cross-cutting concerns, all the way to full lifecycle API management. Edge proxies are more general purpose traffic proxies or reverse proxies that operate at the network and transport layers (OSI layers 3 and 4 respectively) and provide basic cross-cutting concerns, and tend not to offer API-specific functionality. Ingress controllers are a Kubernetes-specific technology that controls what traffic enters a cluster, and how this traffic is handled.
The target users for the second generation of API gateways was largely the same as the cohort for the first generation, but with a clearer separation of concerns and a stronger focus on developer self-service. The move from first to second generation of API gateways saw increased consolidation of both functional and cross-functional requirements being implemented in the gateway. Although it became widely accepted that microservices should be built around the idea espoused by James Lewis and Martin Fowler of “smart endpoints and dumb pipes”, the uptake of polyglot language stacks mean that “microservice gateways” emerged (more detail in the next section) that offered cross-cutting functionality in a language-agnostic way.
Coda (2017 Onwards): Service Mesh and/or API Gateway?
In early 2017 there was increasing buzz about the use of “service meshes”, a new communication framework for microservice-based systems. William Morgan, CEO of Buoyant and ex-Twitter engineer, is largely credited with coining the term. The early service meshes exclusively targeted the east-west, service-to-service communication requirements. As Phil Calçado writes in Pattern: Service Mesh, service meshes evolved from early in-process microservice communication and resilience libraries, such as Netflix’s Ribbon, Eureka, and Hystrix. Buoyant’s Linkerd was the first service mesh to be hosted by the CNCF, but Google’s Istio captured the attention of many engineers (largely thanks to Google’s impressive marketing machine).
Although there is a lot of functional overlap between service meshes and API gateways, and much of underlying proxy (data plane) technology is identical, the use cases and control plane implementations are at the moment quite different. Several service meshes offer ingress and gateway-like functionality, for example, Istio Gateway and Consul Ingress Gateways. However, this functionality is typically not as feature-rich or as mature as that currently offered by existing API gateways. This is why the majority of modern API gateways integrate effectively with at least one service mesh.
Start at the Edge and Work Inwards
Every production system that exposes an API will require an API gateway, but not necessarily a service mesh. Many existing systems, and also simple greenfield applications, are implemented as a shallow stack of services, and therefore the added operational complexity of deploying and running a service mesh does not provide a high enough level of benefit. For this reason it is typically the case that we recommend engineers “start at the edge and work inwards”, i.e. select and deploy an API gateway, and only when the number of services (and their interactions) grows consider selecting a service mesh.
Current API Gateway Taxonomy
As can be the case with terminology in the software development industry, there often isn’t an exact agreement on what defines or classifies an API gateway. There is broad agreement in regards to the functionality this technology should provide, but different segments of the industry have different requirements, and hence different views, for an API gateway. This has led to several sub-types of API gateway emerging and being discussed. In this section of the chapter you will explore the emerging taxonomy of API gateways, and learn about their respective use cases, strengths, and weaknesses.
Traditional Enterprise Gateways
The traditional enterprise API gateway is typically aimed at the use case of exposing and managing business-focused APIs. This gateway is also often integrated with a full API lifecycle management solution, as this is an essential requirement when releasing, operating, and monetizing APIs at scale. The majority of gateways in this space may offer an open source edition, but there is typically a strong usage bias towards the open core/commercial version of the gateway.
These gateways typically require the deployment and operation of dependent services, such as data stores. These external dependencies have to be run with high availability to maintain the correct operation of the gateway, and this must be factored into running costs and DR/BC plans.
Micro/Microservices Gateways
The primary use case of microservices API gateway, or micro API gateway, is to route ingress traffic to backend APIs and services. There is typically not much provided for the management of an API’s lifecycle. These types of gateway are often available fully-featured as open source or are offered as a lightweight version of a traditional enterprise gateway.
The tend to be deployed and operated as standalone components, and often make use of the underlying platform (e.g., Kubernetes) for the management of any state. As microservices gateways are typically built using modern proxy technology like Envoy, the integration capabilities with service meshes (especially those built using the same proxy technology) is typically good.
Service Mesh Gateways
The ingress or API gateway included with a service mesh is typically designed to provide only the core functionality of routing external traffic into the mesh. For this reason they often lack some of the typical enterprise features, such as comprehensive integration with authentication and identity provider solutions, and also integration with other security features, such as a WAF.
The service gateway typically manages state using the capabilities of the mesh itself or underlying deployment fabric (e.g. Kubernetes). This type of gateway is also implicitly coupled with the associated service mesh (and operational requirements), and so if you are not yet planning to deploy a service mesh, then this is most likely not a good first choice of API gateway.
Comparing API Gateway Types
The table below highlights the difference between the two most widely deployed API gateway types across six important criteria.
| Use case | Traditional Enterprise API gateway | Microservices API gateway | Service Mesh Gateway |
|---|---|---|---|
Primary Purpose |
Expose, compose, and manage internal business APIs |
Expose and observe internal business services |
Expose internal services within the mesh |
Publishing Functionality |
API management team or service team registers/updates gateway via admin |
API Service team registers/updates gateway via declarative code as part of the deployment process |
Service team registers/updates mesh and gateway via declarative code as part of the deployment process |
Monitoring |
Admin and operations focused e.g. meter API calls per consumer, report errors (e.g. internal 5XX). |
Developer focused e.g. latency, traffic, errors, saturation |
Platform focused e.g. utilization, saturation, errors |
Handling and Debugging Issues |
L7 error-handling (e.g. custom error page). Run gateway/API with additional logging. Troubleshoot issue in staging environment |
L7 error-handling (e.g. custom error page, failover, or payload). Configure more detailed monitoring. Enable traffic shadowing and/or canarying to verify issue |
L7 error-handling (e.g. custom error page or payload). Configure more detailed monitoring. Debug via specialized tooling e.g. Squash or Telepresence |
Testing |
Operate multiple environments for QA, Staging, and Production. Automated integration testing, and gated API deployment. Use client-driven API versioning for compatibility and stability (e.g. semver) |
Facilitate canary routing for dynamic testing (taking care with data mutation side effects in live environments). Use developer-driven service versioning for upgrade management |
Facilitate canary routing for dynamic testing |
Local Development |
Deploy gateway locally (via installation script, Vagrant or Docker), and attempt to mitigate infrastructure differences with production. Use language-specific gateway mocking and stubbing frameworks |
Deploy gateway locally via service orchestration platform (e.g. container, or Kubernetes) |
Deploy service mesh locally via service orchestration platform (e.g. Kubernetes) |
Deploying API Gateways: Understanding and Managing Failure
Regardless of the deployment pattern and number of gateways involved within a system, an API gateway is typically on the critical path of many, if not all, user requests entering into your system. An outage of a gateway deployed at the edge typically results in the unavailability of the entire system. And an outage of a gateway deployed further upstream typically results in the unavailability of some core subsystem. For this reason the topics of understanding and managing failure of an API gateway are vitally important to learn.
API Gateway as a Single Point of Failure
The first essential step in identifying single points of failure in a system is to ensure that you have an accurate understanding of the current system. This is typically accomplished by investigation and the continual update of associated documentation and diagrams. Assembling a diagram that traces a user-initiated request for each core journey or use case, all the way from ingress to data store or external system and back to egress, that shows all the core components involved can be extremely eye opening. This is especially the case in large organizations, where ownership can be unclear and core technologies can accidentally become abandoned.
In a typical web-based system, the first obvious single point of failure is typically DNS. Although this is often externally managed, there is no escaping the fact that if this fails, then your site will be unavailable. The next single points of failure will typically then be the global and regional layer 4 load balancers, and depending on the deployment location and configuration, the security edge components, such as the firewall or WAF.
Challenge Assumptions with Security Single Points of Failure
Depending on the product, deployment, and configuration, some security components may “fail open”, i.e. if the component fails then traffic will simply be passed through to upstream components or the backend. For some scenarios where availability is the most important goal this is desired, but for others (e.g. financial or government systems), this is most likely not. Be sure to challenge assumptions in your current security configuration.
After these core edge components, the next layer is typically the API gateway. The more functionality you are relying on within the gateway, the bigger the risk involved and bigger the impact of an outage. As an API gateway if often involved in a software release the configuration is also continually being updated. It is critical to be able to detect and resolve issues, and mitigate any risks.
Detecting Problems
The first stage in detecting issues is ensuring that you are collecting and have access to appropriate signals from your monitoring system, i.e. data from metrics, logs, and traces. If you are new to this concept, then we recommend learning more about Brendan Gregg’s utilization, saturization, and errors (USE) method, Tom Wilkie’s rate, errors, and duration (RED) method, and Google’s four golden signals of monitoring. In particular, the Google Site Reliability Engineering (SRE) book, is highly recommended. A key takeaway from the book is that for any critical system you should ensure a team owns it and is accountable for any issues. The Google team talk about the need to define service level objectives (SLOs) SLOs, which can be codified into service level agreements (SLAs) for both internal and external customers.
Synthetic Monitoring: One of the Most Valuable Detection Techniques
One of the more effective ways of detecting user-facing issues, particularly in a rapidly evolving system, is to use synthetic monitoring (also called semantic monitoring and synthetic transactions). This technique consists of continually running a subset of an application’s business-focused automated tests against the production system in the same manner a user would make them. The user-facing results are then pushed into a monitoring service, which triggers alerts in case of failures.
Resolving Incidents and Issues
First and foremost, each API gateway operating within your system needs an owner that is accountable if anything goes wrong with the component. As an API gateway is on the critical path of requests, some portion of this owning team should be on-call as appropriate (this may be 24/7/365). The on-call team will then face the tricky task of fixing the issue as rapidly as possible, but also learning enough (or locating and quarantining systems and configuration) to learn what went wrong. After each incident you should strive to conduct blameless a post mortem, and document and share all of your learning. Not only can this information be used to trigger remediate action to prevent this issue reoccurring, but this knowledge can be very useful for engineers learning the system and for external teams dealing with similar technologies or challenges. If you are new to this space then the Learning from Incidents website is a fantastic jumping off point.
Mitigating Risks
Any component that is on the critical path for handling user requests should be made as highly available as is practical in relation to cost and operational complexity. Software architects and technical leaders deal with tradeoffs; this type is one of the most challenging. In the world of API gateways, high availability typically starts with running multiple instances. With on-premise/co-lo instances this translates into operating multiple (redundant) hardware appliances, ideally spread across separate locations. In the cloud, this translates into designing and running the API gateway instance in multiple availability zones/data centers and regions. If a (global) load balancer is deployed in front of the API gateway instances, then this must be configured appropriately with health checks and failover processes that must be test regularly. This is especially important if the API gateways instances run in active/passive or leader/node modes of operation.
Load Balancing Challenges
You must ensure that your load balancer to API gateway failover process meets all of your requirements in relation to continuity of service. Common problems experienced during failover events include:
-
User client state management issues, such as backend state not being migrated correctly, which causes the failure of sticky sessions
-
Poor performance, as client are not redirected based on geographical considerations e.g. European users being redirected to the US west coast when an east coast data center is available
-
Unintentional cascading failure, such as a faulty leader election component that results in deadlock, which causes all backend systems to become unavailable
Care should be taken with any high availability strategy to ensure that dependent components are also included. For example, many enterprise API gateways rely on a data store to store configuration and state in order function correctly. This must also be run in a HA configuration, and it must be available to all active and passive components. It is becoming increasingly common to split the deployment and operation of the control plane and data plan, but you will need to understand what happens if the control plane has an outage over a considerable period of time.
Often the biggest period of change with an API gateway is during configuration update, for example, a release of a new API or service. Progressive delivery techniques should be used, such as rolling upgrades, localized rollouts, blue/green deployments, and canary releasing. These allow fast feedback and incremental testing in a production environment, and also limit the blast radius of any outage.
Finally, you can put in place reactive fallback measures to handle failure. Examples of this include building functionality to serve a degraded version of the website from static servers, caches, or via a CDN.
API Gateway Antipatterns: Mixing Traffic Patterns
Although it can be tempting to want to find a single solution to manage all traffic flowing into and within a system (“one gateway to rule them all”), history has not been kind to this approach. There are many examples of technology that became overly coupled with the underlying application and added increasing friction to the software delivery process being a key culprit. There are several antipatterns you should always try and avoid.
API Gateway Loopback: “Service Mesh Lite”
As with all antipatterns, the implementation of this pattern often begins with good intentions. When an organization has only a few services this typically doesn’t warrant the installation of a service mesh. However, a subset of service mesh functionality is often required, particularly service discovery. An easy implementation is to route all traffic through the edge or API gateway, which maintains the official directory of all service locations. At this stage the pattern looks somewhat like a “hub and spoke” networking diagram. The challenges present themselves in two forms: Firstly, when all of the service-to-service traffic is leaving the network before reentering via the gateway this can present performance, security, and cost concerns (cloud vendors often charge for egress). Secondly, this pattern doesn’t scale beyond a handful of services, as the gateway becomes overloaded and a bottleneck, and it becomes a true single point of failure.
API Gateway as an ESB: Egregious Spaghetti Boxes?
The vast majority of API gateways support the extension of their out-of-the-box functionality via the creation of plugins or modules. NGINX supported Lua modules, which OpenResty and Kong capitalised on. Envoy Proxy originally supported extensions in C, and now WebAssembly filters. And we’ve already discussed how the original implementation of Netflix’s Zuul API gateway “2015 Onwards: Second Generation API Gateways”, supported extension via Groovy scripts. Many of the use cases realised by these plugins are extremely useful, such as authn/z, filtering, and logging. However, it can be tempting to put business logic into these plugins, which is a way to highly-couple your gateway with your service or application. This leads to a potentially fragile system, where a change in a single plugin ripples throughout the organization, or additional friction during release where the target service and plugin have to be deployed in lockstep.
Turtles (API Gateways) All the Way Down
If one API gateway is good, more must be better, right? It is common to find multiple API gateways deployed within the context of large organization, often in a hierarchical fashion, or in an attempt to segment networks or departments. The intentions are typically good: either for providing encapsulation for internal lines of business, or for a separation of concerns with each gateway (e.g. “this is the transport security gateway, this is the auth gateway, this is the logging gateway…”). The antipatterns rears its head when the cost of change is too high, e.g. you have to coordinate with a large number of gateway teams to release a simple service upgrade, there are understandability issues (“who owns the tracing functionality?”), or performance is impacted as every network hop naturally incurs a cost.
Selecting an API Gateway
Now that you learned about the functionality provided by an API gateway, the history of the technology, and how an API gateway fits into to the overall system architecture, next is the $64,000 question: how do you select an API gateway to included in your stack?
Identifying Requirements
One of the first steps with any new software delivery or infrastructure project is identifying the related requirements. This may appear obvious, but it is all too easy to get distracted by shiny technology, magical marketing, or good sales documentation!
You can look back to “Why Use an API Gateway?”, to explore in more detail the high-level requirements you should be considering during the selection process:
-
Reducing coupling between front ends and back ends
-
Simplifying client consumption of APIs by aggregating and/or translating back end services
-
Protecting APIs from overuse and abuse, via threat detection and mitigation
-
Understanding how APIs are being consumed and how the underlying systems are performing
-
Managing APIs as products i.e. API Lifecycle Management requirements
-
Monetizing APIs, including the needs for account management, billing, and payment
It is important to ask question both focused on current pain points and also your future roadmap. For example, do you need to simply expose REST-based backend APIs with a thin layer of load balancing and security, or do you need comprehensive API aggregation and translation functionality combined with enterprise-grade security?
Exploring Constraints: Team, Technologies, and Roadmap
In addition to identifying requirements it is also essential that you identify your organization’s constraints. Broadly speaking, we have found there are three key areas that are well worth exploring when choosing your API gateway: team structure and dynamics, existing technology investments, and future roadmap.
The much discussed Conway’s law, stating that organizations design systems mirror their own communication structure, has almost become a cliche. But there is truth to this. As explored by Matthew Skelton and Manuel Pais in Team Topologies your organizational structure will constrain your solution space. For example, if your organization has a separate InfoSec team, there is a good chance that you will end up with a separate security gateway.
Another well discussed concept is the notion of the sunk cost fallacy, but in the real world we see this ignored time and time again. Existing technology deployed often constrains future decisions. You will need to investigate the history associated with many of the big ticket technology decision making within an organization, such as API gateway choice, in order to avoid messy politics. For example, if a platform team has already invested millions of dollars into creating a bespoke API gateway, there is a good chance they will be reluctant to adopt another gateway, even if this is a better fit for the current problem space.
Finally, you will need to identify and explore your organization’s roadmap. Often this will constrain the solution space. For example, some organizations are banning the use of certain cloud vendors or technology vendors, for reasons related to competition or ethical concerns. Other times, you will find that the roadmap indicates the leadership is “all-in” on a specific technology, say, Java, and so this may restrict the deployment of a gateway that doesn’t run on a JVM.
Build Versus Buy
A common discussion when selecting an API gateway is the “build versus buy” dilemma. This is not unique to this component of a software system, but the functionality offered via an API gateway does lead to some engineers gravitating to this that they could build this “better” than existing vendors, or that their organization is somehow “special”, and would benefit from a custom implementation. In general, we believe that the API gateway component is sufficiently well-established that it typically best to adopt an open source implementation or commercial solution rather than build your own. Presenting the case for build versus buy with software delivery technology could take an entire book, and so in this section we only want to highlight some common challenges:
-
Underestimating the Total Cost of Ownership (TCO): Many engineers discount the cost of engineering a solution, the continued maintenance costs, and the ongoing operational costs.
-
Not thinking about opportunity cost: Unless you are a cloud or platform vendor, it is highly unlikely that a custom API gateway will provide you with a competitive advantage. You can delivery more value to your customers by building some functionality closer to your overall value proposition
-
Not being aware of current technical solutions of products. Both the open source and commercial platform component space moves fast, and it can be challenging to keep up to date. This, however, is a core part of the role of being a technical leader.
Radars, Quadrants, and Trend Reports
Although you should always perform your own experiments and proof of concept work, we recommend keeping up to date with technology trends via reputable IT press. This type of content can be especially useful when you are struggling with a problem or have identified a solution and are in need of a specific piece of technology that many vendors offer.
We recommend the following sources of information for learning more about the state of the art of technology within the API gateway space:
Several organizations and individuals also publish periodic API gateway comparison spreadsheets, and these can be useful for simple “paper evaluations” in order to shortlist products to experiment with. It should go without saying that you will need to check for bias across these comparisons (vendors frequently sponsor such work), and also ensure the publication date is relatively recent. Enterprise API gateways solutions do not change much from month to month, but this is not true in the cloud native and Kubernetes space.
API Gateway: A Type 1 Decision
Jeff Bezos, the CEO of Amazon, is famous for many things, and one of them is his discussion of Type 1 decisions and Type 2 decisions. Type 1 decisions are not easily reversible, and you have to be very careful making them. Type 2 decisions are easy to change: “like walking through a door — if you don’t like the decision, you can always go back.” Usually this concept is presented in relation to confusing the two, and using Type 1 processes on Type 2 decisions: “The end result of this is slowness, unthoughtful risk aversion, failure to experiment sufficiently, and consequently diminished invention. We’ll have to figure out how to fight that tendency.” However, in the majority of cases—especially within a large enterprise context—choosing an API gateway is very much a Type 1 decision. Ensure your organization acts accordingly!
Checklist: Selecting an API Gateway
Decision |
How should we approach selecting an API gateway for our organization? |
Discussion Points |
Have we identified and prioritized all of our requirements associated with selecting an API gateway? Have we identified current technology solutions that have been deployed in this space within the organization? Do we know all of our team and organizational constraints? Have we explored our future roadmap in relation to this decision? Have we honestly calculated the “build versus buy” costs? Have we explored the current technology landscape and are we aware of all of the available solutions? Have we consulted and informed all involved stakeholders in our analysis and decision making? |
Recommendations |
Focus particularly on your requirement to reduce API/system coupling, simplify consumption, protect APIs from overuse and abuse, understand how APIs are being consumed, manage APIs as products, and monetize APIs Key questions to ask include: is there are existing API gateway in use? Has a collection of technologies been assembled to provide similar functionality (e.g. hardware load balancer combined with a monolithic app that performs authentication and application-level routing)? How many components currently make up your edge stack (e.g. WAF, LB, edge cache, etc.) Focus on technology skill levels within your team, availability of people to work on a API gateway project, and available resources and budget etc It is important to identify all planning changes, new features, and current goals that could impact traffic management and the other functionality that an API gateway provides Calculate the total cost of ownership (TCO) of all of the current API gateway-like implementations and potential future solutions. Consult with well known analysts, trend reports, and product reviews in order to understand all of the current solutions available. Selecting and deploying an API gateway will impact many teams and individuals. Be sure to consult with the developers, QA, the architecture review board, the platform team, InfoSec etc. |
Summary
In this chapter you have learned what an API gateway is, and also explored the historical context that led the to evolution of the features currently provided by this essential component in any web-based software stack. You have explored the current taxonomy of API gateways and their deployment models, which has equipped you to think about how to manage potential single points of failure in an architecture where all user traffic is routed through an edge gateway. Building on the concepts of managing traffic at the (ingress) edge of systems, you have also learned about service-to-service communication and how to avoid antipatterns such as deploying an API gateway as a less-functional enterprise service bus (ESB).
The combination of all of this knowledge has equipped you with the key thinking points, constraints, and requirements necessary in order to make an effective choice when selecting an API gateway for your current use cases. As with most decisions a software architect or technical leader has to make, there is no distinct correct answer, but there often can be quite a few bad solutions to avoid.
Now that you have explored the functionality that API gateways provide during the runtime operation of systems, the next important concept to learn about is how to test APIs and API gateways in production.