
NoSQL is a blanket term for the databases that solve the scalability issues which are common among relational databases. This term, in its modern meaning, was first coined by Eric Evans. It should not be confused with the database named NoSQL (http://www.strozzi.it/cgi-bin/CSA/tw7/I/en_US/nosql/Home%20Page). NoSQL solutions provide scalability and high availability, but may not guarantee ACID: atomicity, consistency, isolation, and durability in transactions. Many of the NoSQL solutions, including Cassandra, sit on the other extreme of ACID, named BASE, which stands for basically available, soft-state, eventual consistency.
Note
Wondering about where the name, NoSQL, came from? Read Eric Evans' blog at http://blog.sym-link.com/2009/10/30/nosql_whats_in_a_name.html.
In 2000, Eric Brewer (http://en.wikipedia.org/wiki/Eric_Brewer_%28scientist%29), in his keynote speech at the ACM Symposium, said, "A distributed system requiring always-on, highly-available operations cannot guarantee the illusion of coherent, consistent single-system operation in the presence of network partitions, which cut communication between active servers". This was his conjecture based on his experience with distributed systems. This conjecture was later formally proved by Nancy Lynch and Seth Gilbert in 2002 (Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services, published in ACMSIGACT News, Volume 33 Issue 2 (2002), page 51 to 59 available at http://webpages.cs.luc.edu/~pld/353/gilbert_lynch_brewer_proof.pdf).
Let's try to understand this. Let's say we have a distributed system where data is replicated at two distinct locations and two conflicting requests arrive, one at each location, at the time of communication link failure between the two servers. If the system (the cluster) has obligations to be highly available (a mandatory response, even when some components of the system are failing), one of the two responses will be inconsistent with what a system with no replication (no partitioning, single copy) would have returned. To understand it better, let's take an example to learn the terminologies. These terms will be used frequently throughout this book.
Let's say you are planning to read George Orwell's book Nineteen Eighty-Four over the Christmas vacation. A day before the holidays start, you logged into your favorite online bookstore to find out there is only one copy left. You add it to your cart, but then you realize that you need to buy something else to be eligible for free shipping. You start to browse the website for any other item that you might buy. To make the situation interesting, let's say there is another customer who is trying to buy Nineteen Eighty-Four at the same time.
A consistent system is defined as one that responds with the same output for the same request at the same time, across all the replicas. Loosely, one can say a consistent system is one where each server returns the right response to each request.
In our book buying example, we have only one copy of Nineteen Eighty-Four. So, only one of the two customers is going to get the book delivered from this store. In a consistent system, only one can check out the book from the payment page. As soon as one customer makes the payment, the number of Nineteen Eighty-Four books in stock will get decremented by one, and one quantity of Nineteen Eighty-Four will be added to the order of that customer. When the second customer tries to check out, the system says that the book is not available any more.
Relational databases are good for this task because they comply with the ACID properties. If both the customers make requests at the same time, one customer will have to wait till the other customer is done with the processing, and the database is made consistent. This may add a few milliseconds of wait to the customer who came later.
An eventual consistent database system (where consistency of data across the distributed servers may not be guaranteed immediately) may have shown availability of the book at the time of check out to both the customers. This will lead to a back order, and one of the customers will be paid back. This may or may not be a good policy. A large number of back orders may affect the shop's reputation and there may also be financial repercussions.
Availability, in simple terms, is responsiveness; a system that's always available to serve. The funny thing about availability is that sometimes a system becomes unavailable exactly when you need it the most.
In our example, one day before Christmas, everyone is buying gifts. Millions of people are searching, adding items to their carts, buying, and applying for discount coupons. If one server goes down due to overload, the rest of the servers will get even more loaded now, because the request from the dead server will be redirected to the rest of the machines, possibly killing the service due to overload. As the dominoes start to fall, eventually the site will go down. The peril does not end here. When the website comes online again, it will face a storm of requests from all the people who are worried that the offer end time is even closer, or those who will act quickly before the site goes down again.
Availability is the key component for extremely loaded services. Bad availability leads to bad user experience, dissatisfied customers, and financial losses.
Network partitioning is defined as the inability to communicate between two or more subsystems in a distributed system. This can be due to someone walking carelessly in a data center and snapping the cable that connects the machine to the cluster, or may be network outage between two data centers, dropped packages, or wrong configuration. Partition-tolerance is a system that can operate during the network partition. In a distributed system, a network partition is a phenomenon where, due to network failure or any other reason, one part of the system cannot communicate with the other part(s) of the system. An example of network partition is a system that has some nodes in a subnet A and some in subnet B, and due to a faulty switch between these two subnets, the machines in subnet A will not be able to send and receive messages from the machines in subnet B. The network will be allowed to lose many messages arbitrarily sent from one node to another. This means that even if the cable between the two nodes is chopped, the system will still respond to the requests.
The following figure shows the database classification based on the CAP theorem:
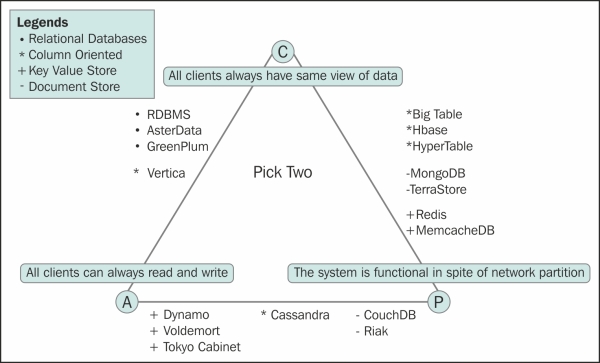
An example of a partition-tolerant system is a system with real-time data replication with no centralized master(s). So, for example, in a system where data is replicated across two data centers, the availability will not be affected, even if a data center goes down.
Once you decide to scale up, the first thing that comes to mind is vertical scaling, which means using beefier servers with a bigger RAM, more powerful processor(s), and bigger disks. For further scaling, you need to go horizontal. This means adding more servers. Once your system becomes distributed, the CAP theorem starts to play, which means, in a distributed system, you can choose only two out of consistency, availability, and partition-tolerance. So, let's see how choosing two out of the three options affects the system behavior as follows:
- CA system: In this system, you drop partition-tolerance for consistency and availability. This happens when you put everything related to a transaction on one machine or a system that fails like an atomic unit, like a rack. This system will have serious problems in scaling.
- CP system: The opposite of a CA system is a CP system. In a CP system, availability is sacrificed for consistency and partition-tolerance. What does this mean? If the system is available to serve the requests, data will be consistent. In an event of a node failure, some data will not be available. A sharded database is an example of such a system.
- AP system: An available and partition-tolerant system is like an always-on system that is at risk of producing conflicting results in an event of network partition. This is good for user experience, your application stays available, and inconsistency in rare events may be alright for some use cases. In the book example, it may not be such a bad idea to back order a few unfortunate customers due to inconsistency of the system than having a lot of users return without making any purchases because of the system's poor availability.
- Eventual consistent (also known as BASE system): The AP system makes more sense when viewed from an uptime perspective—it's simple and provides a good user experience. But, an inconsistent system is not good for anything, certainly not good for business. It may be acceptable that one customer for the book Nineteen Eighty-Four gets a back order. But if it happens more often, the users would be reluctant to use the service. It will be great if the system could fix itself (read: repair) as soon as the first inconsistency is observed; or, maybe there are processes dedicated to fixing the inconsistency of a system when a partition failure is fixed or a dead node comes back to life. Such systems are called eventual consistent systems.
The following figure shows the life of an eventual consistent system:
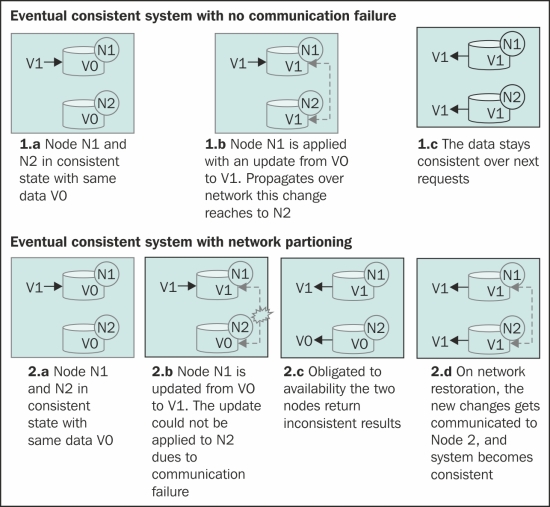
Quoting Wikipedia, "[In a distributed system] given a sufficiently long time over which no changes [in system state] are sent, all updates can be expected to propagate eventually through the system and the replicas will be consistent". (The page on eventual consistency is available at http://en.wikipedia.org/wiki/Eventual_consistency.)
Eventual consistent systems are also called BASE, a made-up term to represent that these systems are on one end of the spectrum, which has traditional databases with ACID properties on the opposite end.
Cassandra is one such system that provides high availability and partition-tolerance at the cost of consistency, which is tunable. The preceding figure shows a partition-tolerant eventual consistent system.