
Chapter 2. Event Streams and Event Brokers
Event Streams and Event Brokers are at the heart of every real-time system. An Event Stream is an endless series of events. Let’s think back to chapter one and the banking example; a borrower’s financial transactions can be considered an event stream. Each time a borrower uses their credit card, applies for a new credit line, or deposits a check, those actions or events are appended to their Event Stream. Since the Event Stream is infinite, the bank can use it to return to any point in the borrower’s past. If the lender wanted to figure out what the borrower’s bank account looked like on a specific day in history, they could reconstruct that from an Event Stream. The Event Stream is a powerful concept, and when equipped with this data, it can empower organizations and developers to make life-changing experiences.
Event Brokers are the technology platforms that store Event Streams and interact with clients that read data from Event Streams or write data to Event Streams. Apache Pulsar is an Event Broker at its heart. However, calling Pulsar, only an Event Broker would minimize its scope and impact. To fully understand what makes Pulsar unique, it is beneficial to dive into some of the strengths and weaknesses of Event Brokers and their approaches to implementing Event Streams. This chapter will walk through some historical context and motivate the discussion around the need for Apache Pulsar.
Publish/Subscribe
Developers across disciplines in Software Engineering commonly use the Publish/Subscribe pattern. At its core, the publish/subscribe pattern decouples software systems and smooths the user experience of asynchronous programming. Popular messaging technologies like Apache Pulsar, Apache Kafka, RabbitMQ, NATS, and ActiveMQ all utilize the publish/subscribe pattern in their protocols. It’s worth jumping into this pattern’s history to understand its significance and build on why Pulsar is unique.
In 1987, Thomas Joseph and Kenneth Birman published a paper titled Exploiting Virtual Synchrony in Distributed Systems in the Proceedings of the ACM. Their paper described an early implementation of a large scale messaging platform built on the publish/subscribe pattern. In their paper, the authors make a convincing case around the publish/subscribe pattern’s value. Specifically, they claim that systems implemented this way feel synchronous, even though they are inherently asynchronous. To illustrate this point more clearly, let’s dive into the publish/subscribe pattern with some examples.
The idea of a subscription is commonplace in the 21st century. I have subscriptions to news services, entertainment, food delivery, loyalty programs, and many others. Figure 2-1 provides a simple illustration of a pub/sub pattern. I subscribe to goods for services from a retailer or entertainer, and they deliver me goods or services based on an agreement. The news services I subscribe to is the best way to illustrate a publish/subscribe pattern. I subscribe to a news service, and when a news source publishes a new article, I expect to receive it on my phone. In this example, you can consider my news service provider to be an Event Broker, the news publication to be a producer and, me to be a consumer. There are a few features in this relationship that are worth pointing out.

Figure 2-1. An illustration of the Publish/Subscribe Pattern
First, there is no coupling between the news publication (publisher) and the subscriber (consumer). The news publication does not need to know that I’m a subscriber; they focus on writing articles and sending them to the news service. Similarly, I don’t have to know anything about the mechanisms of the news publication. The news service provides a reliable mechanism for publication and consumption. From a consumer perspective, getting news on my phone promptly feels magical. I can control how many messages I receive per day or what times I prefer to deliver. For the news publication, they can focus on producing quality news. Delivering the news to the right customers at the right time are all managed by the news service.
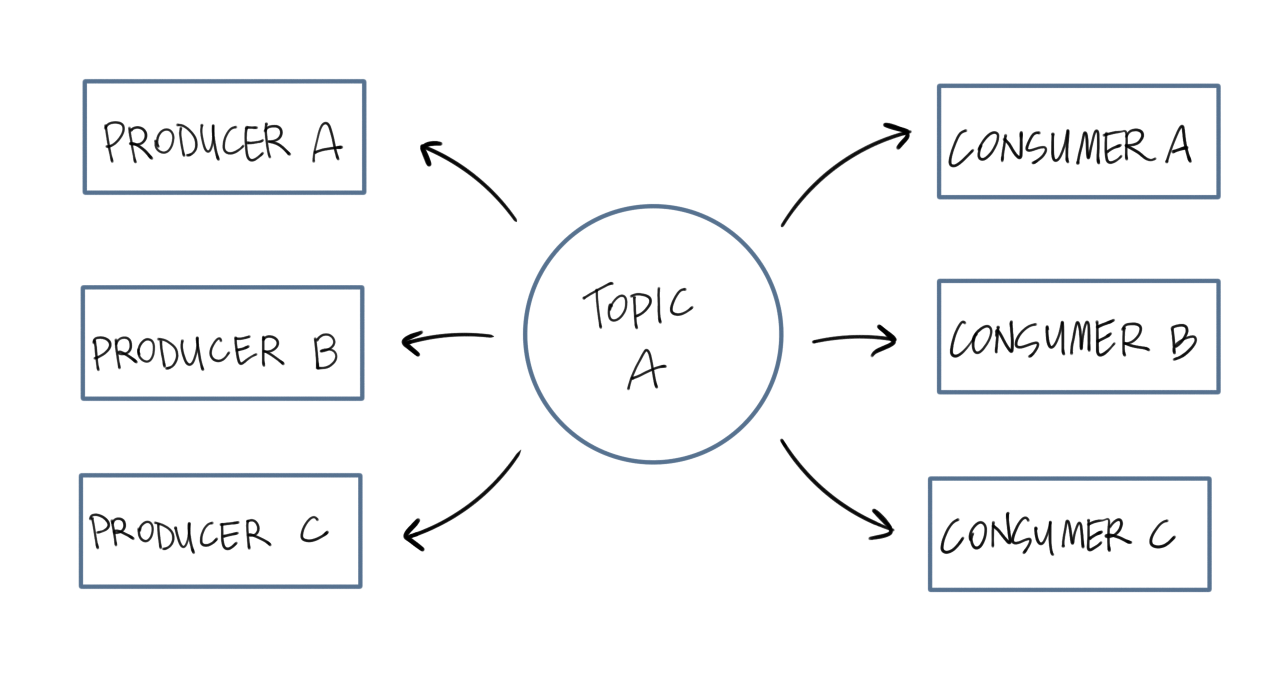
Figure 2-2. A more complex publish/subscribe topology
The aha moment in the Virtual Synchrony paper was that the publish/subscribe pattern makes asynchronous workflows feel synchronous. Figure 2-2 provides a visual look into this model. Examining the interactions with my news service from all angles, it does feel synchronous. I don’t feel like I have an ask and wait for a relationship with my news publication; it just shows up when I need it. The publisher publishes their stories to the news service, and their stories are in users’ hands.
The Event Stream implements a publish/subscribe pattern, but it has one critical distinction, the event broker must retain the same order for every subscriber. This distinction may not seem like much at first blush, but it enables a whole new way of using the publish/subscribe pattern. Consider our example of the news service. When a new customer signs up for the service, they will receive news articles in the future but likely will not receive all past messages onto their device on sign up. Most messaging systems guarantee to deliver a published message to a current subscriber and purposefully released messages that are already delivered. For an Event Stream, the event broker retains the entire history of data. When a new consumer subscribes to the event stream, they choose where they want to start consuming from (including the beginning of time).
Queue
A queue is a different approach to a publish/subscribe pattern. In the publish/subscribe pattern discussed in the previous section, every subscriber to a topic received a published message. In the Queue model, only one subscriber will receive a message published to a topic. The queue model tackles a specific kind of publish/subscribe problem where each message in the queue is waiting on work to be completed, and the subscribers perform that work. Consider the process of being invited to a party (Figure 2-3). An invitation to anyone who has access to the fliers is analogous to a queue (left) and an invitation to a specific subscriber is analogous to an event stream (right).

Figure 2-3. Caption to come
The queue model is more straightforward than the event stream model and works for a larger class of applications. The class of applications where a client receives a work unit publishes it to the messaging system, and a downstream consumer completes the work. Email, unsubscribing, deleting records, orchestration of events, and indexing is examples of this class of applications.
Some messaging systems are purpose-built for the queue model. This class of messaging systems is called a Work Queue. Beanstalk is a widely used messaging system that is a work queue. Beanstalk’s design is purposefully simple and doesn’t require the user to configure it. Beanstalk has simple semantics, and most users need only to publish and consume messages from Beanstalk. While Beanstalk’s simplicity is attractive, the simplicity also makes it poorly suited for the Event Stream model. Beanstalk is also poorly suited for the publish/subscribe models where all consumers receive messages on a topic.
Apache Kafka is a popular event streaming platform. Kafka, built on the distributed log concept (similar to Pulsar), Kafka clusters power applications like Airbnb, Slack, and Netflix. Kafka is an unquestionably unique platform; however, there are limitations to using Kafka as a queue. From the producer side, Kafka is perfectly suitable to work as a Queue. It is on the consumer side where difficulties may arise. Kafka provides the ability for configuration on a topic-by-topic basis; it does not, however, allow the alteration of semantics for the topic. Every topic in Kafka is an Event Stream and requires strict ordering and that consumers manage their place in the event stream. Consumers should get the next message in a queueing model and not be concerned about their place in the topic. It’s possible to mimic this behavior through consumer side logic, but it’s not a native feature to Kafka.
A system that could enable both a queue and event stream model on a topic would be an operational win and a win for simplicity.
Failure Modes
Messaging systems can fail. They can fail to deliver messages to subscribers; they can fail to accept publishers’ messages and lose messages in transit. Contingent on the system’s design and use, each of these failures can have varying degrees of severity. If we think back on the email examples in previous sections, failure to deliver email can have a varying degree of severity. If you fail to get your favorite email newsletter in your inbox on a given day, that is not the end of the world. You may spend your time on other more fulfilling pursuits in the absence of the newsletter. For an example of a more robust system, consider a payment portal. An e-commerce platform may use messages to create Virtual Synchrony for their payment platform. If a failure occurs in the payment pipeline, it can prevent a user from getting their products in the best case and bankrupt a business in the worst case. It’s essential to build a messaging platform that is robust to failures.
Managing the three failures of message acceptance, message delivery, and message storage requires thoughtful design and wise implementations—we’ll discuss the details about how Pulsar tackles these issues in the next chapter.
Push vs. Poll
When a producer publishes new messages to a queue or event stream, how that message propagates to the consumers can vary. The two mechanisms for pushing that message to consumers are pushing and polling.
In the push model, the event broker pushes messages to a consumer with some predefined configuration. For example, the broker may have a fixed number of messages per period that it sends to a consumer, or it may have a max number of messages queued before it pushes to the consumer. Today’s majority of messaging systems use a push mechanism because brokers are eager to move messages off their hands.
In an event system, queued messages have some value, but processing the messages is the system’s end goal. By eagerly pushing messages to available consumers, the event broker can rid itself of the responsibility for the message. However, as discussed in the failure modes section, an event broker may try to push a consumer message, and the consumer may be unavailable. This failure mode necessitates the event broker to retry or, in the queue case, move the message onto another consumer.
An alternative to the push model is the poll model. The poll model requires the consumer to ask the event broker for new messages. The consumer may ask for new messages after a configured time interval or may ask based on a downstream event. The advantage of this model is the consumer is always ready to receive messages when it asks. The disadvantage is that the consumer may not receive messages on time or receive them at all.
The Need for Pulsar
In this chapter, we’ve talked about early systems developed to tackle messaging. We’ve talked about systems like RabbitMQ, ActiveMQ, and Apache Kafka. These systems require a non-trivial amount of resources to develop and a large community to remain viable in a developer market. Why do we need another one? Apache Pulsar addresses three problems that are not addressed by other event broker technology.
-
Unification of Streaming and Queue
-
Modularity
-
Performance
Unification
The Event Stream requires an ordered sequence for messages. That ordered sequence enables the rich applications described in chapter one and used in many of the applications you use every day. However, an Event Stream has specific semantics requiring consumers to manage how they process the stream’s events. What if an application doesn’t require the use of an ordered sequence? What if each client needed to get the next available event and was not concerned about its place in the stream?
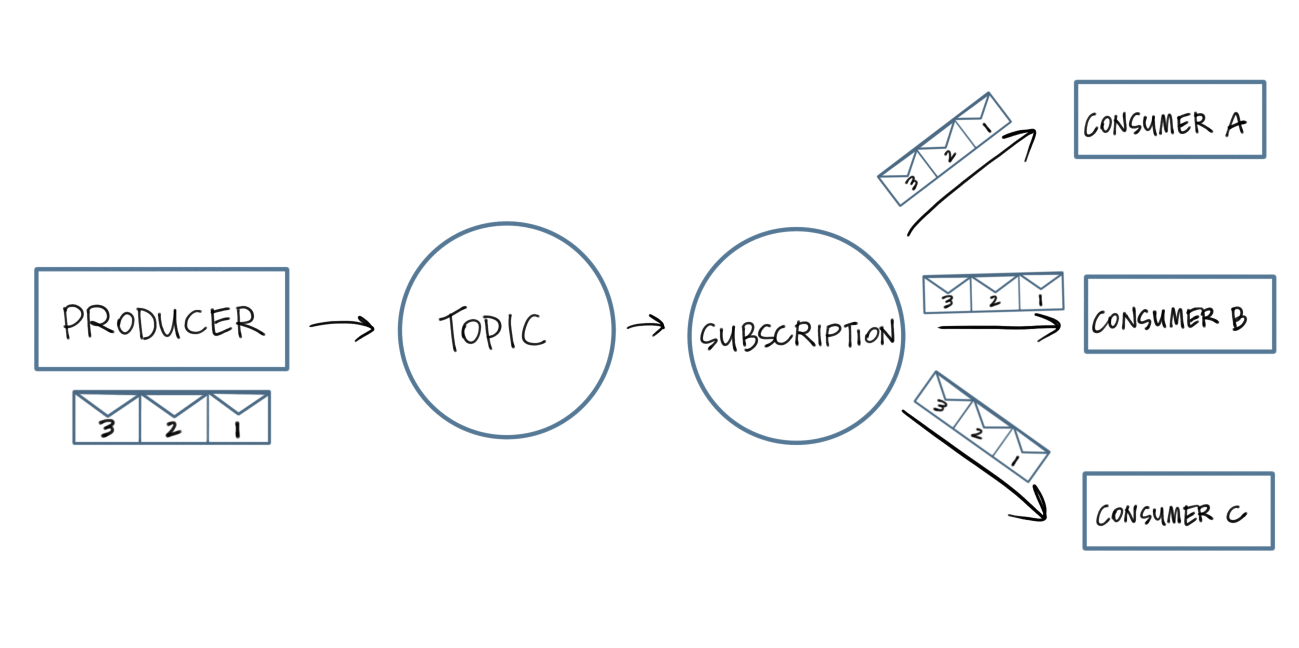
Figure 2-4. Caption to come
The flexibility of Pulsar allows topics to be either a queue or an event stream as depicted in figure 2-4. This flexibility means a Pulsar Cluster can provide the platform for all of the interactions discussed in this chapter.
Modularity
In 2.1 and 2.2, we talked about the differences between the Queue and Event Stream models of the publish/subscribe model. While these models differ enough to warrant different architectures, application developers are likely to need both models for building robust software. It’s not uncommon for software development teams to use one system intentionally designed for event streams and another for queueing. While this “best tool for the job” approach can be wise, it does have some downsides. One downside is the operational burden of managing two systems. Each system is unique in its maintenance schedule and procedure, best practices, and operations paradigm. An additional downside is that programmers have to familiarize themselves with multiple paradigms and APIs to write applications.
At its core, Pulsar is an Event Stream implementation. However, designed in such a way that building alternative paradigms on top of Pulsar is not onerous. This design decision enables Pulsar to be an Event Stream platform and a Queue platform simultaneously. Pulsar’s modular design enables Pulsar to bridge from the Pulsar protocol to other protocols like AMQP 0.9.1, Kafka Protocol, and MQTT. Pulsar provides the building blocks to build interoperability with popular messaging protocols.
For a mature company, migrating from an existing messaging system like RabbitMQ, MQTT, or Kafka to Pulsar may be infeasible. Each of these platforms has a unique protocol, requires custom client libraries, and has a unique paradigm and vernacular. The process of migrating may take years for a sufficiently large organization. With Pulsar, an organization can use Pulsar and RabbitMQ simultaneously and slowly migrate their RabbitMQ topics to Pulsar or keep both running side by side.
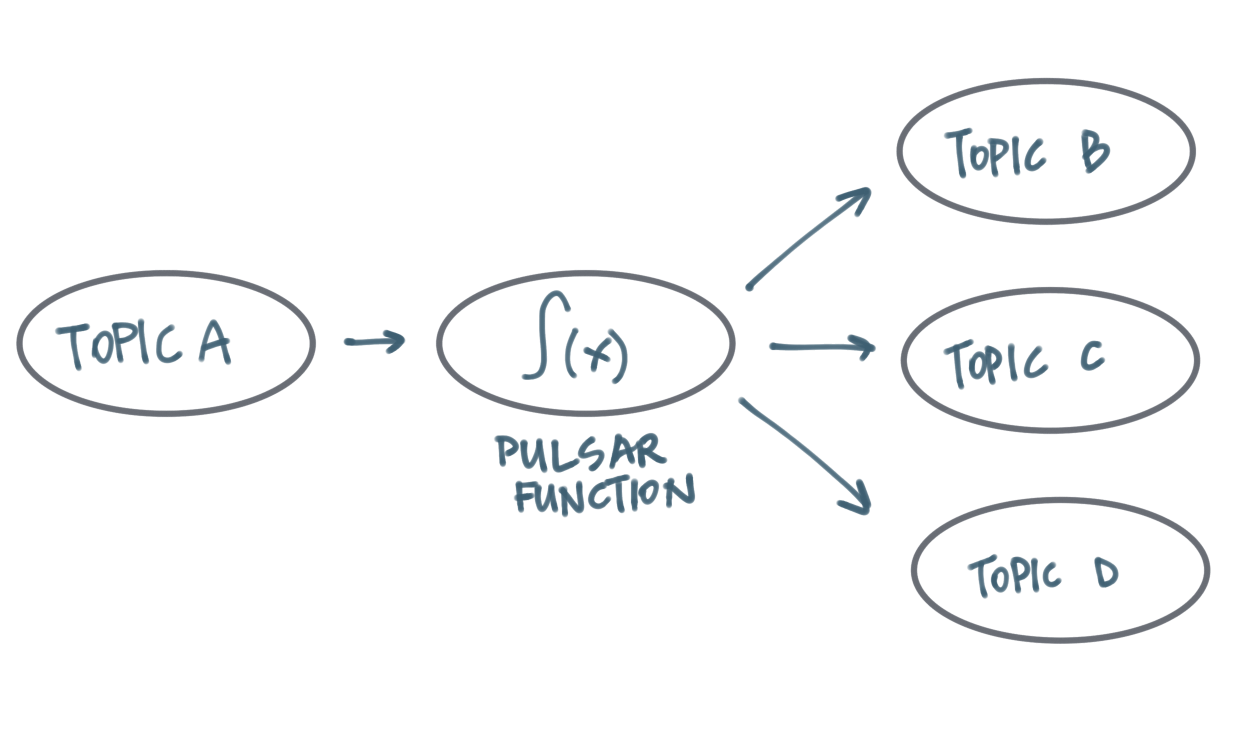
Figure 2-5. Pulsar Functions are a built-in runtime for stream processing in Pulsar
The power of Pulsar’s modular design is also evident in its ecosystem. Pulsar supports functions as a service (depicted in figure 2-5), SQL querying, and Change Data Capture with minimal configuration. Each of these features provides additional building blocks and tools for creating rich event-driven applications.
Performance
Throughout this chapter, we have discussed three critical components of a quality event broker. The broker needs to (1) reliably store data, (2) reliably deliver messages to consumers, and (3) quickly consume messages from publishers. Performing these three tasks well requires thoughtful design and optimized resource utilization. All event brokers have to work through the same limitations of disk speeds, CPU, memory, and network. In further chapters, we’ll get into more detail around the design considerations in Apache Pulsar, but for now, we’ll talk about how some design considerations enable exceptional performance and scalability.
In the section on modularity, we discussed Pulsar’s modular approach to storage by using Apache Bookkeeper. We focused on how this choice enabled features to archive and retrieve Pulsar data. Pulsar administrators can grow the size of the Bookkeeper cluster separately from the Pulsar Event Broker nodes. The storage needs may change during a day, month, or year within a messaging platform. Pulsar enables the flexibility to scale up storage more comfortably with this design decision. When it comes to reliability concerns about storing data, the storage systems’ scalability is a significant factor.
Reliability in the consumption of messages is contingent on the Event Broker being able to consume the volume of messages sent its way. If an Event Broker can’t keep up with the volume of messages, many failure scenarios may follow. Clients connect to Pulsar via the Pulsar Protocol and connect to a Pulsar Node. Since Pulsar nodes can scale separately from the Bookkeeper cluster, scaling up consumption is also more flexible.
Finally, what about raw performance? How many messages can a Pulsar cluster consume per second? How many many can it securely store in the Bookkeeper cluster per second? Many published benchmarks on Apache Pulsar and it’s performance, but you should take every benchmark with a grain of salt. As mentioned earlier in this chapter, every messaging system has constraints. The engineers who design these systems take advantage of their unique knowledge and circumstances. Therefore, designing benchmarks that fairly assess the performance of each platform is often an exercise in futility. That said, Apache Pulsar has a reputation for being a performant platform, and hundreds of companies have chosen Pulsar to manage their event streaming platforms.
In this chapter, we acquired the foundational knowledge needed to understand Pulsar’s value proposition and uniqueness. From here, we’ll pull apart all Pulsar components to gain a deep understanding of the base building blocks. With that knowledge, we’ll be ready to deep dive into the APIs and start building applications.