
Chapter 3. Pulsar
In chapter 2, we spent a considerable effort building the motivation for a system like Apache Pulsar. Namely, a system that handled both the Event Stream and Pub/Sub pattern seamlessly. We provided sufficient evidence for the utility of a system like Pulsar and provided a historical backdrop for asynchronous messaging. We did not, however, cover how it is that Pulsar came into existence. To begin this chapter on the design principles and use cases for Pulsar, it’s worth understanding how exactly the system came to be.
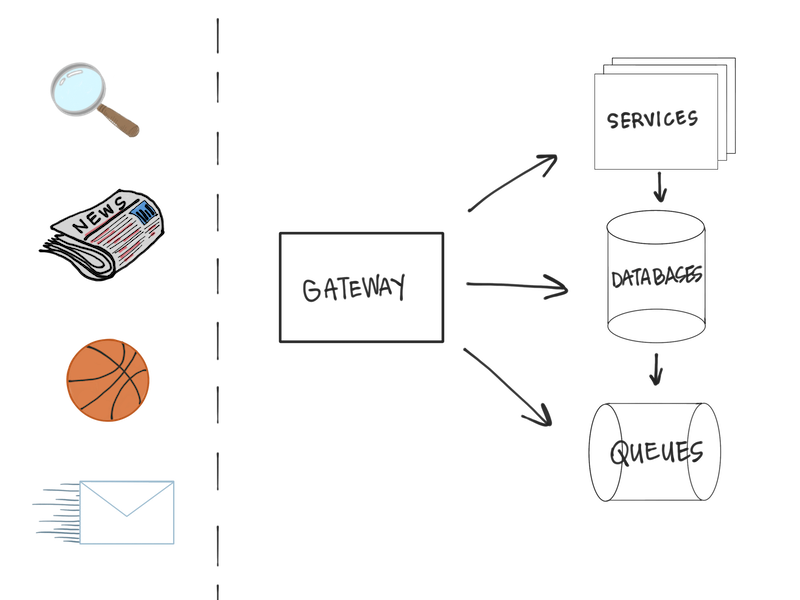
Figure 3-1. Figure caption placeholder
In 2013, Yahoo! reported having 800 million active users across its services. Yahoo! provided email, photo storage, news, social media, chat, fantasy sports, among other services. From an infrastructure perspective, Yahoo! felt that they needed to address some of their underlying architecture decisions to meet their users’ demands and continue to build their world-class services. Among other points of improvement, the messaging architecture used at Yahoo! was seen as the most important place to improve their systems. In their service-oriented architecture, the messaging system helped all components scale and provided the low-latency primitives to simplify scalability across all services (depicted in figure 3-1). The most critical aspects for a new messaging platform to meet were:
-
Flexibility. Yahoo! worked with the queues, publish/subscribe and streaming, and wanted their messaging platform to handle these use cases seamlessly.
-
Reliability. 99.999% reliability is what Yahoo! was accustomed to, and the new system they built should have the same reliability, if not better.
-
Performance. Yahoo! needed low end-to-end latencies for services like chat and email as well as their ad platform.
At the time, Yahoo! evaluated existing messaging technologies and determined that none of the open-source or off the shelf solutions would work for their scale and needs. Yahoo! decided to create their system to meet their needs and designed and built the first version of Pulsar.
In 2015, Yahoo! Deployed their first Pulsar cluster. Pulsar’s use quickly exploded to replace all the existing messaging infrastructure at Yahoo! In 2017, Yahoo Open Sourced Pulsar by donating the project to the Apache Software Foundation.
Pulsar Design Principles
Pulsar was designed from the ground up to be the default messaging platform at Yahoo! As a large technology company with hundreds of millions of users and tens of popular services, meeting all of the needs as a messaging platform is complicated. Scalability and usability challenges are the tips of the iceberg. At the dawn of Pulsar’s design and implementation, many companies utilized the public cloud, but it was far from the mainstream adoption that it has today. Creating a system that meets company needs today but doesn’t lock the company into a single development pattern for years to come is a challenge few engineering teams can meet.
To meet these challenges, Pulsar designers focus on two essential design principles.
-
Modularity
-
Performance

Figure 3-2. Figure caption placeholder
Modularity and performance is a rare combination in systems. Like a pure-breed racehorse made of legos (figure 3-2), Pulsar allows for extensions while never compromising on performance. From these two design principles, some of Pulsar’s elegance and foresight come to the surface, namely Pulsar’s multi-tenancy and geo-replication part. We’ll dive into each and show how it relates to Pulsar’s design principles.
Multi-Tenancy
When I was growing up, I lived in an apartment complex with 27 residents in a five-story building. We all shared the utilities, including the heating, water, cable, and gas. Trying to keep all of the units at a suitable temperature, good water pressure, a reliable cable signal, and adequate gas was impossible. In the wintertime, the apartment complex’s top floor was boiling at 75 degrees Fahrenheit, and the first floor was barely tolerable at 65 degrees. In the morning, it was a race between tenants to get to the shower first before all the hot water was used and the water pressure was reduced. On a Monday night, if you’re watching football, you’d have difficulty getting a reliable signal watching anything else.

Figure 3-3. Figure caption placeholder
Our apartment complex was multi-tenant (depicted in figure 3-3) in that each apartment unit contained its own family, but we shared resources as a building. In software, multi-tenant systems are designed to run workloads for different customers on the same hardware. Pulsar’s flexible subscription model and decoupled architecture enable a high-quality multi-tenant experience.
Pulsar handles multi-tenancy through namespacing and allows tenants’ scheduling on a specific part of the Pulsar Cluster. These two mechanisms put the Pulsar cluster operator in full control of resource allocation and isolation for specific tenants. Returning to the example of my apartment complex, Pulsar allows a cluster operator to put tenants who like to keep their home at the same temperature together and tenants who take showers around the same time separate to preserve hot water and water pressure. We’ll explore multi-tenancy in Pulsar in a later chapter.
Geo-Replication
Pulsar was initially developed at Yahoo!, a globally distributed company with over 800 million users at its peak. Pulsar’s usage spread throughout Yahoo and across the globe, and with that expansion came the responsibility of replicating data. Replication is the process of copying data from one node in Pulsar to another. Replication is necessary for redundancy and low latency.
Pulsar, by default, can be deployed across multiple data centers. What this means is as an application scales across geographies, it can use one Pulsar cluster. Topics are replicated across data centers, and topic redundancy can be configured to the applications’ needs that utilize the topic. For a Pulsar topic deployed across hundreds of data centers and throughout the globe, Pulsar manages the complexity of routing data to the right place.

Figure 3-4. Figure caption placeholder
Later in the book, we’ll dive into how Pulsar’s replication protocol works and showcase how replication enables smooth global operations for companies like Splunk. For this chapter, we’ll focus on how Pulsar components are modular, allowing for a cluster across the globe to appear as one connected cluster (Depicted in figure 3-4) : this design and implementation detail separate Pulsar from other systems.
Performance
As a messaging system, Pulsar’s primary responsibility is to reliably and quickly consume publishers’ messages and deliver subscribers’ messages. Fulfilling these responsibilities on top of being a reliable message storage mechanism is complicated. From the onset, Yahoo! was concerned about building a system with low latency. In the 2016 post “Open-Sourcing Pulsar, Pub-sub Messaging at Scale,” Yahoo cites 5ms average publish latencies being a strict requirement for them when building Pulsar.
While this book covers all of Pulsar’s features, building blocks, and ecosystem, the reality is the core functionality that Pulsar offers is unquestionably fast message delivery. All other features in Pulsar build off of this fundamental truth.
Modularity
At its core, Pulsar’s implementation is a distributed log. The distributed log is an excellent primitive for a system like Pulsar because it provides the building blocks for many systems, including databases and file systems. In 2013, Jay Kreps, then a Principal Staff Engineer at LinkedIn, published a blog post titled “The Log: What every software engineer should know about real-time data’s unifying abstraction.” In this post, Kreps argued that the log provided some key tenants allowing it to be a building block for real-time systems. Namely, logs are appended only (meaning you can add to the log but not remove an item from the log), and that they are index based on the order an item was inserted into the log.
Chapter 4 will dive deeper into Pulsar’s implementation of a distributed log, but for now, we’ll focus on how building this core enables other messaging models to work with Pulsar. An Event Stream has a 1-to-1 relationship with a log. Each event is appended to the stream and ordered by an index (off-set). When a consumer publishes an event stream, keeping the order the messages were published in is vital. Pulsar’s based implementation works well for this use case. For a queue, the order the messages are published in doesn’t matter. Additionally, the queue consumers don’t care where they are relative to the queue’s beginning or end. In this instance, you can still use the log but relax some of the constraints to model a queue.
Alternative pub/sub implementations can be small moderations on top of a distributed log implementation. For example, the Message Queuing Telemetry Transport (MQTT) is implemented in Pulsar via the MQTT-On-Pulsar project. Other implementations and protocols can run on top of Pulsar with modifications to the core log, such as the Kafka protocol or the AMQP 1.0 protocol.
Pulsar Ecosystem
The creation and open-sourcing of Pulsar provided the building blocks for sound and flexible messaging. Since the open-sourcing, developers have built powerful tooling to couple with Pulsar’s underlying technology. In addition to the three projects highlighted in this section, the Pulsar community is active and shares resources on deployment strategies, infrastructure as code approaches, and upcoming community developments.
Pulsar Functions
At its core, Pulsar is about performant messaging and storage. We’ve talked at length in this chapter about Pulsar’s flexible design for data storage and scalability. Pulsar Functions answers the question of how to process data stored within Pulsar. Pulsar Functions are a lightweight computing framework that can consume from a Pulsar Topic, perform some computation and then publish the results to a Pulsar topic.
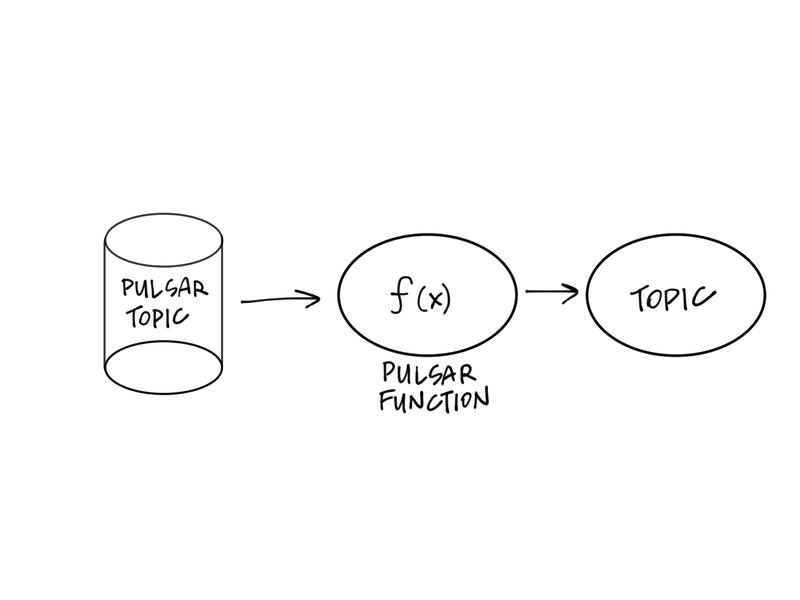
Figure 3-5. Figure caption placeholder
Pulsar Functions draws inspiration from functions as a service implementation like Google Cloud Functions and Amazon Web Services Lambda Functions. Specifically, Pulsar functions have a flexible deployment model where the Pulsar Functions’ resources can be coupled with the Pulsar Broker Nodes or run as a separate process. Pulsar functions have Pulsar topics as input and output to Pulsar topics as well (as depicted in figure 3-5)
Pulsar functions align well with the design principle of modularity. Though written Pulsar’s core is written in Java, you can write Pulsar Functions in Java, Python, or Go. The choice to separate Pulsar and Pulsar Functions’ runtime reduces programmers’ barrier to learn Pulsar and interact with it. Additionally, Pulsar functions provide a high-quality stream processing implementation that has a shallow learning curve. If you can write Java, Python, or Go, you can write semantically correct stream processing without learning a new framework.
Pulsar IO
Pulsar IO is a connector framework for Pulsar that allows Pulsar topics to become input or output for other processes. To understand Pulsar IO, it’s a bit more instructive to think of an end-to-end example. Suppose you wanted to create a pipeline that read in data from your MySQL database row by row and then stored it in an Elasticsearch index. Pulsar IO can facilitate this entire application with just configuration (Depicted in figure 3-6).
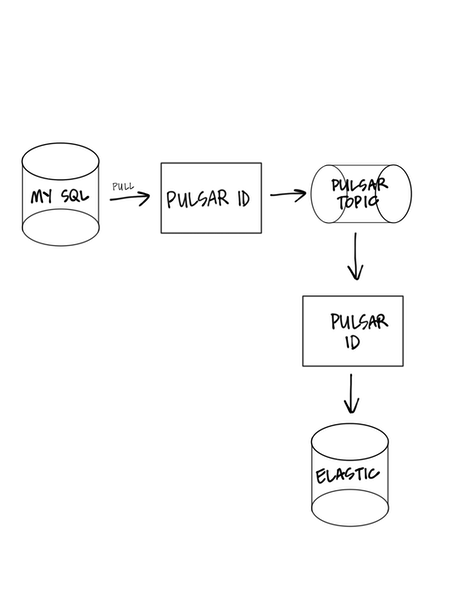
Figure 3-6. Figure caption placeholder
Like Pulsar Functions, Pulsar IO provides an isolated and scalable compute process to facilitate the event-driven movement of data through Pulsar topics to destinations. Pulsar IO has some philosophical and implementation similarities to Kafka Connect. Like Kafka Connect, Pulsar IO is designed to enable ease of use for everyday use cases with Pulsar. We’ll dive into considerably more detail and examples of using Pulsar IO and building our application later in this book. Still, for now, understanding where this project sits in the Pulsar ecosystem will suffice.
Pulsar SQL
Pulsar’s decoupled compute and storage architecture allows Pulsar to store data for more extended periods and store more of it. With all of the data stored in Pulsar, querying data on Pulsar is a natural next step. Pulsar SQL provides a scalable compute runtime that enables SQL queries to be executed against Pulsar topics. Pulsar SQL using Apache Presto, a SQL-on-Anything engine to provide the compute resources to query Pulsar topics.
Pulsar SQL has some philosophical similarities to Kafka’s KSQL. Both are designed to allow the querying of topics with an SQL syntax. Pulsar SQL is a read-only system designed to query topics and not necessarily create permanent data views. KSQL, on the other hand, is interactive and allows users to create new topics based on the result of SQL queries. We’ll dive deeper into Pulsar SQL implementation and use cases in a future chapter.
Pulsar Success Stories
So far in this chapter, we’ve talked at length about the creation story of Apache Pulsar, its design, and it is open-sourcing as a system created for the unique challenges! In 2014, can Pulsar address the problems of companies today? Does a platform like Pulsar created in the private cloud of Yahoo! work for companies hosted on the public cloud? These are essential questions for teams that are evaluating Pulsar for their messaging needs. In this section, we’ll cover three companies that adapted Pulsar have been successful with it. These stories highlight a business problem that engineering teams turned to Pulsar to solve and details how Pulsar helped them solve it.
Yahoo! Japan
In 2017 Yahoo! Japan managed about 70 Billion Pageviews per month. At the time, they faced challenges with managing the load on their servers and orchestrating hundreds of services in their service-oriented architecture. Along with the challenges of running their services at scale, Yahoo! Japan wished to distribute their entire architecture across countries (geo-replication). Yahoo! Japan looked to a messaging system to help with each of these problems with this design. They explored Apache Pulsar and Apache Kafka for their workflow and reported the results of their investigation in a blog post published in 2019.
The authors of the post detail some of Pulsar and Kafka’s key differences and why they ultimately chose Pulsar for their workloads. The three most important aspects of the system they chose were:
-
Geo-Replication.
-
Reliability.
-
Flexibility.
While Pulsar and Kafka scored similarly on reliability, geo-replication and flexibility are where Pulsar separated itself from Kafka. At the time of their investigation, little had been published on cross-data center deployments of Kafka. Meanwhile, the Pulsar story around geo-replication was well known in the community (as stated in this chapter’s opening). Ultimately Yahoo! Japan settled on using Pulsar and have used it for many years to power their services. Pulsar provides the engine for their service-oriented architecture and removes many of the burdens that come with geo-replication.
Splunk
Splunk is a corporation that makes the collection, aggregation, and searching of logs and other telemetry data easy (Depicted in Figure 3-7). Hundreds of Enterprise tech companies use Splunk to collect logs from their applications, instrument their applications and troubleshoot their infrastructure and applications. In 2019, Splunk Acquired Streamlio, the first managed offering of Apache Pulsar. In the press announcement of the acquisition, Splunk noted that Apache Pulsar was a unique technology and that it would be transformative to the company. It’s not hard for a company like Splunk to imagine how technology like Pulsar is used in their products. In a 2020 talk titled “How Splunk Mission Control Leverages Various Pulsar subscription types,” Pranav Dharma, then Senior Software Engineer at Splunk, covers how Pulsar’s flexible subscription model is used at Splunk to power their center of operations.
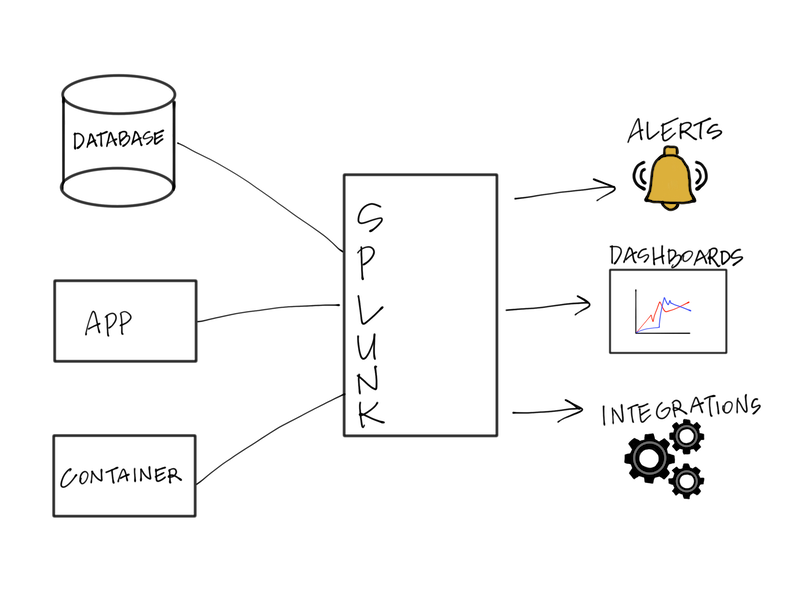
Figure 3-7. Figure caption placeholder
In another 2020 talk titled “Why, Splunk Chose Pulsar,” Karthik Ramasamy, distinguished engineer at Splunk and founder of Streamlio, details the wins that Splunk gets from Pulsar geo-replication, low latency message transmission, and scalable storage via Apache Bookkeeper. Apache Pulsar was a significant investment for Splunk but, by all accounts, a worthwhile one for the company. Splunk leverages the core performance of Pulsar to make quick decisions. They leverage Pulsar’s flexible subscription model to provide a single platform to handle all messaging needs.
Iterable
Iterable is a Customer Engagement platform designed to make customer lifecycle marketing, recommendation systems, and cross-channel engagement easy. To scale their operations across thousands of customers, Iterable needed a messaging platform that could be the foundation of their software interactions. Initially, Iterable used RabbitMQ but ran into the system’s limitations and turned to other systems to solve their messaging problems. Laid out in an article titled “How Apache Pulsar is Helping Iterable Scale its Customer Engagement Platform,” author Greg Methvin lays out the problems Iterable looked to solve with a new messaging platform. The three key features Greg and his team looked for in a new platform were:
-
Scalability. Iterable needed a system that would scale up to the demand of their users.
-
Reliability. Iterable needed a system that could reliably store their messaging data.
-
Flexibility. Iterable needed a system that would handle all of their messaging needs.
Iterable evaluated several messaging platforms, including Apache Kafka, Amazon’s SQS, and Kinesis. In their evaluation, Pulsar was the only system among the three that provided the semantics and scalability they wanted. Iterable used its messaging platform for both Queuing and Streaming. While Kinesis and Kafka provided some facilities for accomplishing this, they fell short of Pulsar’s elegance and general-purpose mechanism. Additionally, Pulsar’s decoupled architecture provided the flexibility Iterable needed to scale topics independently and provide the proper semantics on a topic basis.
By settling on Pulsar and the event backbone of their architecture, Iterable has been able to scale and meet new and growing customers’ demands.