
Let's have a look at an example in order to learn how to use this tool:
- If you don't have a Bluemix account, register for one here: ibm.biz/CloudFreemium.
- Once you have an account in place, go to https://datascience.ibm.com, and click on Sign In.
- Click on Sign-In with your IBM ID, and follow the instructions.
Once you are ready to go, let's start with a small hello world project by creating a Jupyter notebook on Scala with Apache Spark 2.x.
As illustrated in the following screenshot, click on the Create notebook button:

This opens the Create notebook dialog as illustrated here:
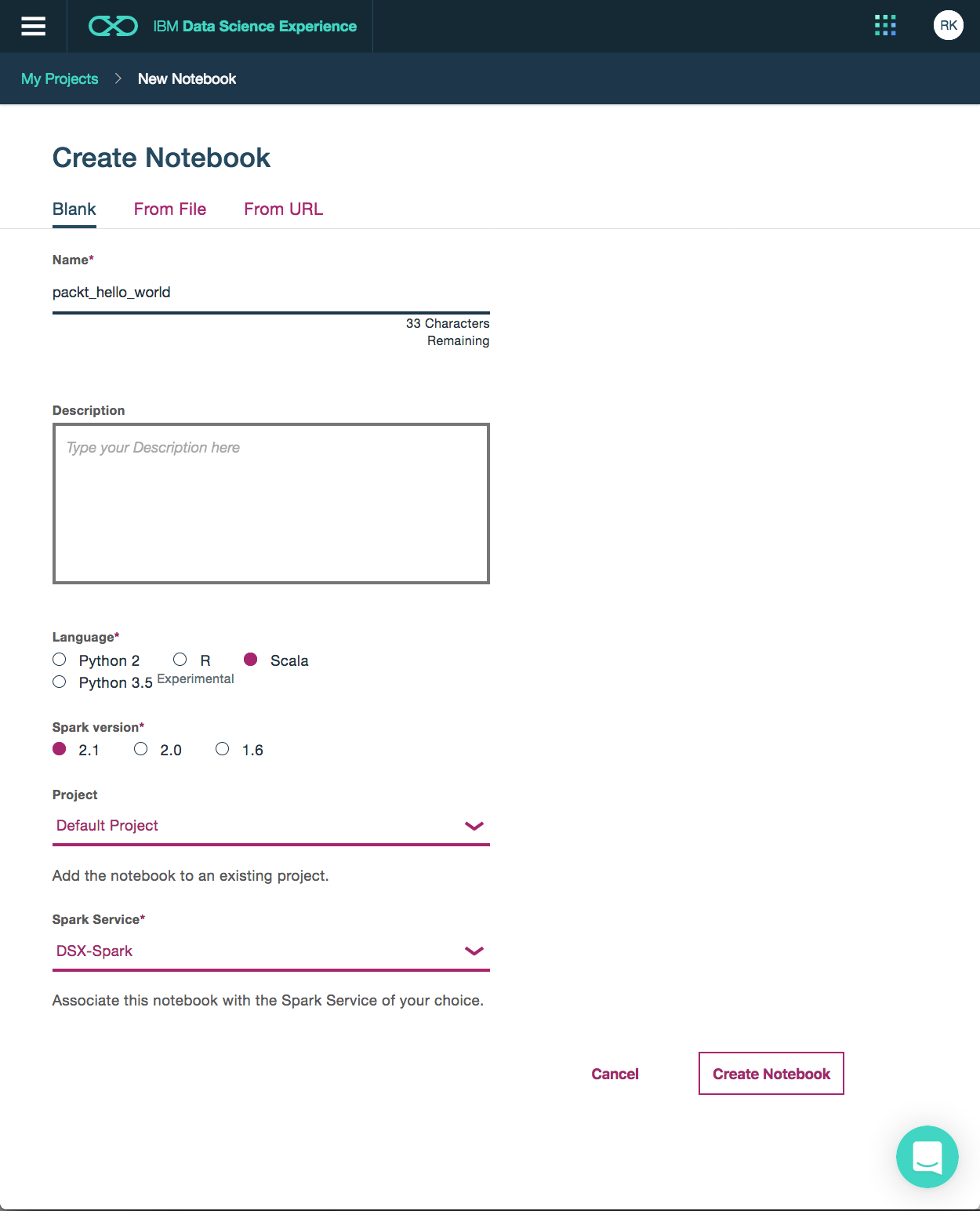
So let's have a look at what information we need to provide:
- First of all, each notebook needs a name. We choose packt_hello_world as the name.
- Then we select Scala as the programming language.
- We want to run our code on an Apache Spark 2.x instance.
- We choose Default Project. Putting notebooks into projects facilitates collaboration, resource assignments, and version management of third-party libraries.
- Finally, we choose an Apache Spark instance running on the IBM Bluemix cloud, where our code has to be executed. This service is completely containerized; therefore, it can handle each of the supported Apache Spark versions and programming languages, which, at the time of writing this book, are Scala, Python 2.7, Python 3.5, and R on Apache Spark versions 1.6, 2.0, and 2.1.
So let's start with a motivating example and see how easy it is to interact with the SparkSQL object. This is the first time we will run Scala code within Apache Spark without using either the spark-shell command or the spark-submit command.
We'll also use Python, R and Scala interchangeably in different notebooks since each programming language has its own strengths-–Jupyter notebooks make it easy to use such a hybrid approach because no further programming language-dependent skills, other than syntax such as IDEs or build tools, are required.
Let's consider the real-life scenario of a small industrial enterprise doing analytics in the cloud. As you've might have experienced, good data scientists are a rare species, and most of them don't come with a Scala background. Mostly, they work with MATLAB, R, and Python. The same holds for this enterprise. They have plenty of Java developers but only one data scientist. Therefore, it is a good idea to create different roles.
Finally, this data product development process based on Jupyter and Apache Spark as a service catalyzes communication and exchange between skill groups involved in data science projects. The software engineer becomes a better mathematician, and the mathematician becomes a better software engineer because everyone can have a look at (and modify) the assets created by the other since all are in one central place and not buried behind server logins and shell scripts. In addition, they are very readable since they contain not only code but also documentation and output from that code.
Let's start with the first example, where we perform the following steps:
- The Java software engineer is responsible for implementing the ETL process. He pulls data from machines (in this example, we'll pull a dataset from the web), transforms it, and then loads data into a cloud object store. This is entirely done using a Scala notebook. Although the software engineer is not an expert in Scala, he has acquired enough knowledge for this task. The fact that he can use ANSI SQL for querying data really helps since most software engineers have basic SQL skills. Those notebooks can also be triggered and run automatically on a periodic basis in order to update data.
- Once the data is prepared and available in the object store, the data scientist can create an interactive analytics notebook based on Python and the Pixiedust interactive data visualization library in order to get an idea of what the data looks like.
Python is a very easy-to-learn programming language, so it can be seen as the intersection between software engineers and statisticians since you can pick it up really fast if you are coming from a Java and R/MATLAB background. - Use an R notebook and the famous ggplot2 library for creating awesome, publishable plots.