
We've seen how the C# language evolved in early versions, 2.0 and 3.0, with important features, such as generics, lambda expressions, the LINQ syntax, and so on.
Starting with version 4.0, some common and useful practices were eased into the language (and framework libraries), especially everything related to synchronicity, execution threads, parallelism, and dynamic programming. Finally, although versions 6.0 and 7.0 don't include game-changing improvements, we can find many new aspects intended to simplify the way we write code.
In this chapter, we will cover the following topics:
- New features in C# 4: covariance and contravariance, tuples, lazy initialization, Dynamic programming, the
Taskobject and asynchronous calls. - The async/await structure (belongs to C# 5).
- What's new in C# 6.0: string interpolation, Exception filters, the
NameOfoperator, null-conditional operator, auto-property initializers, static using, expression bodied methods and index initializers. - News in C# 7.0: Binary Literals, Digit Separators, Local Functions, Type switch, Ref Returns, Tuples, Out var, Pattern Matching, Arbitrary async returns and Records.
With the release of Visual Studio 2010, new versions of the framework showed up, although that was the last time they were aligned (to date). C# 5.0 is linked to Visual Studio 2012 and .NET framework 4.5, and C# 6, appeared in Visual Studio 2015 and was related to a new (not too big) review of .NET framework: 4.6. The same happens to C#7, although this is aligned with Visual Studio 2017.
Just to clarify things, I'm including a table that shows the whole evolution of the language and the frameworks aligned to them along with the main features and the corresponding version of Visual Studio:
|
C# version |
.NET version |
Visual Studio |
Main features |
|---|---|---|---|
|
C# 1.0 |
.NET 1.0 |
V. S. 2002 |
Initial |
|
C# 1.2 |
.NET 1.1 |
V. S. 2003 |
Minor features and fixes. |
|
C# 2.0 |
.NET 2.0 |
V. S. 2005 |
Generics, anonymous methods, nullable types, iterator blocks. |
|
C# 3.0 |
.NET 3.5 |
V. S. 2008 |
Anonymous types, var declarations (implicit typing), lambdas, extension methods, LINQ, expression trees. |
|
C# 4.0 |
.NET 4.0 |
V. S. 2010 |
Delegate and interface generic variance, dynamic declarations, argument improvements, tuples, lazy instantiation of objects. |
|
C# 5.0 |
.NET 4.5 |
V. S. 2012 |
Async/await for asynchronous programming and some other minor changes. |
|
C# 6.0 |
.NET 4.6 |
V. S. 2015 |
Roslyn services and a number of syntax simplification features. |
|
C# 7.0 |
.NET 4.6 |
V. S. 2017 |
Syntatic "sugar", extended support for tuples, Pattern Matching, and some minor features. |
Table 1: Alignment of C#, .NET, and Visual Studio versions
So, let's start with delegate and interface generic variance, usually called covariance and contravariance.
As more developers adopted the previous techniques shown in Chapter 2, Core Concepts of C# and .NET, new necessities came up and new mechanisms appeared to provide flexibility were required. It's here where some already well-known principles will apply (there were theoretical and practical approaches of compilers and authors, such as Bertrand Meyer).
Note
Luca Cardelli explains as far back as in 1984 the concept of variant in OOP (refer to A semantics of multiple inheritance by Luca Cardelli (http://lucacardelli.name/Papers/Inheritance%20(Semantics%20of%20Data%20Types).pdf).
Meyer referred to the need for generic types in the article Static Typing back in 1995 (also available at http://se.ethz.ch/~meyer/publications/acm/typing.pdf), indicating that for safety, flexibility, and efficiency, the proper combination (he's talking about static and dynamic features in a language) is, I believe, static typing and dynamic binding.
In other seminal work, nowadays widely used, ACM A.M. Turing Award winner Barbara Liskov published his famous Substitution Principle, which states that:
"In a computer program, if S is a subtype of T, then objects of type T may be replaced with objects of type S (i.e., objects of type S may substitute objects of type T) without altering any of the desirable properties of that program (correctness, task performed, etc.)."
Note
Some ideas about covariance and contra-variance are explained in an excellent explanation published by Prof. Miguel Katrib and Mario del Valle in the already extinct dotNetMania magazine. However, you can find it (in Spanish) at https://issuu.com/pacomarin3/docs/dnm_062.
In short, this means that if we have a type, Polygon, and two subtypes, Triangle and Rectangle, which inherit from the former, the following actions are valid:
Polygon p = new Triangle(); Polygon.GreaterThan(new Triangle(), new Rectangle());
The concept of variance is related to situations where you can use classes, interfaces, methods, and delegates defined over a type T instead of the corresponding elements defined over a subtype or super-type of T. In other words, if C<T> is a generic entity of type T, can I substitute it for another of type C<T1> or C<ST>, T1 being a subtype of T and ST a super-type of T?
Note that in the proposal, basically, the question arises where can I apply Liskov's substitution principle and expect correct behavior?
This capability of some languages is called (depending on the direction of the inheritance) covariance for the subtypes, and its counterpart, contravariance. These two features are absolutely linked to parametric polymorphism, that is, generics.
In versions 2.0 and 3.0 of the language, these features were not present. If we write the following code in any of these versions, we will not even get to compile it, since the editor itself will notify us about the problem:
List<Triangle> triangles = new List<Triangle>
{
new Triangle(),
new Triangle()
};
List<Polygon> polygons = triangles;Even before compiling, we will be advised that it's not possible to convert a triangle into a polygon, as shown in the following screenshot:
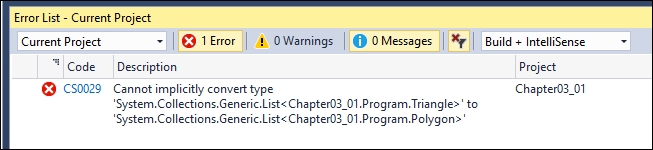
In the previous example, the solution is easy when we use C# 4.0 or higher: we can convert the triangles assignment to List<Polygon> by calling the generic type converter for List just by adding a simple call:
List<Polygon> polygons = triangles.ToList<Polygon>();
In this case, LINQ extensions come to our rescue, since several converters were added to collections in order to provide them with these type of convenient manipulations, which simplify the use object's hierarchies in a coherent manner.
Consider this code, where we change the defined polygons identifier as type IEnumerable<Polygon>:
IEnumerable<Polygon> polygons2 =
new List<Triangle> {
new Triangle(), new Triangle()};This doesn't lead to a compilation error because the same ideas are applied to interfaces. To allow this, the generic parameter of interfaces such as IEnumerable<T> is used only as an out value. In such cases, it's interesting to take a look at the definition using the Peek Definition option (available on the editor's context menu for any type):

In turn, the IEnumerable interface only defines the GetEnumerator method in order to return an iteration mechanism to go through a collection of T types. It's only used to return T by means of the Current property and nothing else. So, there's no danger of the possible manipulation of elements in an incorrect manner.
In other words, according to our example, there's no way you can use an object of type T and place a rectangle where a triangle is expected because the interface specifies that T is used only in an exit context; it's used as a return type.
You can see the definition of this in Object Browser, asking for IEnumerator<T>:

It's not the same situation, though, when you use another interface, such as IList, which allows the user to change a type once it is assigned in the collection. For instance, the following code generates a compilation error:
IList<Polygon> polygons3 =
new List<Triangle> {
new Triangle(), new Triangle()};As you can see, the code is just the same as earlier, only changing the type of generic interface used for the polygons3 assignment. Why? Because the definition of IList includes an indexer that you could use to change the internal value, as Object Explorer shows.
Like any other indexer, the implementation provides a way to change a value in the collection by a direct assignment. This means that we can write this code to provoke a breach in the hierarchy of classes:
polygons3[1] = new Rectangle();
Notice the definition of interface IList<T>: this[int] is read/write, as the next capture shows:

This is due to the ability to set an item in the collection to another value once it is created, as we can see in the preceding screenshot.
It's worth noting that this out specification is only applicable when using the interface. Types derived from IEnumerable<T> (or any other interface that defines an out generic parameter) are not obliged to fulfill this requirement.
Furthermore, this covariance is only applicable to reference types when using references' conversion statements. That's the reason why we cannot assign IEnumerable<int> to IEnumerable<object>; such conversion implies boxing (the heap and the stack are implicated), so it's not a pure reference conversion.
Covariance can be extended to generic types and used with predefined delegates (remember, those delegates supplied by the Framework Factory that can be of types Action, Predicate, and Func).
To place a simple code that shows this feature, observe the following declaration:
IEnumerable<Func<Polygon>> dp = new List<Func<Rectangle>>();
Here, we're assigning a list of delegates of type Rectangle to an enumerable of delegates of type Polygon. This is possible because three characteristics play their role:
Rectangleis assignable toPolygonfor Substitution PrincipleFunc<Rectangle>is assignable toFunc<Polygon>due to covariance in the genericout Tparameter ofFunc<T>- Finally,
IEnumerable<Func<Rectangle>>is assignable toIEnumerable<Func<Polygon>>due to a covariance extension over the generic typeout TofIEnumerable
Note that the mentioned Substitution Principle should not be mistaken with the convertible character of some types (especially, primitive or basic types).
To illustrate this feature, just think of the following definitions:
IEnumerable<int> ints = new int[] { 1, 2, 3 };
IEnumerable<double> doubles = ints;The second sentence generates a compilation error because although there is an implicit conversion from int to double, such conversion is considered for covariance, since this is only applicable to inheritance relations between types, and that is not the case with int and double types because none of them inherits from the other.
Another situation in which covariance is important shows up when using some of the operators defined by the LINQ syntax. This happens, for instance, with the Union operator.
In previous versions, consider that you try to code something like this:
polygons = polygons.Union(triangles);
If you code something like the preceding code, you will get a compilation error, which doesn't happen from version 4.0 onward. This is because in the renewed definition, parameters of operator Union use the mentioned covariance, since they are of type IEnumerable<T>.
However, it's not possible to compile something like this:
var y = triangles.Union(rectangles);
This is because the compiler indicates that there's no definition of Union and the best method overload, Queryable.Union<Program.Rectangle> (IQueryable<Program.Rectangle>, IEnumerable<Program.Rectangle>), requires a receiver of type IQueryable<Program.Rectangle>, as shown in the upcoming screenshot.
This can be avoided this time by means of helping the compiler understand our purpose via generics:
var y = triangles.Union<Polygon>(rectangles);
Observe the way in which the Error List window describes the error, justifying it in terms of proper source code elements and their definitions and capabilities (see the following screenshot):

The case of contravariance is different and usually a bit more difficult to understand. To comprehend things through a known example, let's remember the IComparer<T> interface that we used in the previous chapter.
We used an implementation of IComparer<T> to compare collections of types Customer and Provider indistinctly:
public class GenericComparer : IComparer<IPersonBalance>
{
public int Compare(IPersonBalance x, IPersonBalance y)
{
if (x.Balance < y.Balance) { return -1; }
else if (x.Balance > y.Balance) return 1;
else { return 0; }
}
}In this way, we can compare both types as long as the Customer and Provider classes implement the IPersonBalance interface.
In previous (to C# 4.0) versions of the language, consider that you tried to use a similar code to compare polygons and triangles, as follows:
// Contravariance IComparer<Polygon> polygonComparer = new ComparePolygons(); triangles = triangles.Sort(polygonComparer);
You will then get an error indicating the usual: there's no conversion between Triangle and Polygon, while there's really no risk in receiving these types since no change will happen; they will only be used to compare the entities.
In this case, the inheritance arrow goes upside down—from the specific to the generic—and since both are of type Polygon, the comparison should be possible.
Starting from version 4.0 of C#, this was changed. The new definition of the IComparer interface defines another in modifier for the T operator, using the Peek Definition feature when you right-click on the declaration:

As you can see, the definition indicates that parameter T is contravariant: you can use the type you specified or any type that is less derived, that is, any antecessor of the type in the inheritance chain.
In this case, the in modifier specifies this possibility and indicates to the compiler that type T can only be used in entry contexts, such as what happens here because the purpose of T is to specify the type of entry arguments x and y.
From very early times, programming languages try to express the idea of tuples, first embodied in the COBOL language. Later, Pascal followed it up with the concept of record: a special type of data structure that, unlike arrays, collects data types of different natures in order to define a particular structure, such as a customer or a product.
Let's also remember that the C language itself provided structures (structs) enhanced into objects in the C++ evolution. Usually, every field of this structure represents a characteristic of the whole, so it makes more sense to access its value through a meaningful description instead of using its position (like in arrays).
This idea was also related to the database relational model, so it was particularly suitable to represent these entities. With objects, functionalities are added to recreate fragments of real object properties that are required to be represented in an application: the object model.
Then, in the interest of reusability and adaptability, OOP started promoting objects to hide parts of its state (or the whole state) as a means to preserve its internal coherence. Methods of a class should only have the purpose of maintaining the internal logic of its own state, said a theoretician at the beginning of an OOP class in a well-known university whose name I don't want to remember. We can admit that, exceptions aside, this assertion is true.
If there are parts of the state that can be abstracted (in math terms, you could say that they constitute a pattern), they are candidates for a higher class (abstract or not), so reusability starts with these common factors.
Along this evolution, the concept of tuple got lost in a way, ceding all the land to the concept of object, and programming languages (with some notable exceptions, mainly in the area of functional languages) ceased to have their own notation in order to work with tuples.
However, practice has shown that not all work with data requires the wearing of uniform objects. Perhaps one of the most obvious situations shows up when querying data from a database—the way we've seen in LINQ queries. Once the filtered data meets certain requirements, we only need some components (which is known as a projection in the jargon of databases, as we've tested in previous examples).
This projections are nothing but anonymous objects, which don't deserve to be predefined, since they're usually handled in a single procedure.
The implementation of tuples in .NET 4 is based on the definition (mscorlib.dll assembly and the System namespace) of eight generic classes Tuple<> with different number of type parameters to represent tuples of different cardinalities (it's also called arity).
As a complement to this family of generic classes, eight overloads of the Create method in the Tuple class are provided, converting it into a factory of many possible variations of these types. In order to deliver resources for the creation of longer tuples, the eighth tuple in the list can also be a tuple itself, allowing it to grow as required.
The following code shows the implementation of one of these methods. Thus, to create tuples, we can take advantage of a more concise notation and write this:
Tuple.Create(1, 2, 3, 4, 5);
We'll discover how the Intellisense system of Visual Studio warns us about the structure generated by this declaration and how it is interpreted by the editor:

So, we can express it in this simple way instead of using the following, more explicit code:
new Tuple<int,int,int,int,int>(1, 2, 3, 4, 5);
Since tuples can hold elements of any kind, it is alright to declare a tuple of a variety of types:
Tuple.Create("Hello", DateTime.Today, 99, 3.3);This is similar to what we would do when defining the elements of an object's state, and we can be sure that the compiler will infer its different types, as shown in the following screenshot:

This usage becomes obvious when comparing it with a typical record in the database's table, with the ability of vertically selecting the members (fields, if you want) that we need. We're going to see an example of comparing tuples with anonymous types.
With the tuples .NET classes (and, therefore, their bodies treated by reference), comparing two tuples with the == operator is referential; that is, it relies on memory addresses where the compared objects reside; therefore, it returns false for two different objects-tuples even if they store identical values.
However, the Equals method has been redefined in order to establish equality based on the comparison of the values of each pair of corresponding elements (the so-called structural equality), which is desired in most tuple's applications and which is also the default semantics for the comparison of tuples' equality in the F# language.
Note that the implementation of structural equality for tuples has its peculiarities, starting with the fact that tuples with a tupled eighth member have to be accessed in a recursive manner.
For the case of projections, tuples adapt perfectly and allow us to get rid of anonymous types. Imagine that we want to list three fields of a given Customers table (say, their Code, Name, and Balance fields from dozens of possible fields), and we need to filter them by their City field.
If we assume that we have a collection of customers named Customers, it's easier to write a method in this manner:
static IEnumerable<Tuple<int, string, double>> CustBalance(string city)
{
var result =
from c in Customers
where c.City == city
orderby c.Code, c.Balance
select Tuple.Create(c.Code, c.Name, c.Balance);
return result;
}So, the method returns IEnumerable<Tuple<int, string, double>>, which we can refer where required, having extra support from the Intellisense engine and making it very easy to iterate and present in the output.
To test this feature, I've generated a random name list from the site (http://random-name-generator.info/) named ListOfNames.txt in order to have a list of random customer names, and I have populated the rest of fields with random values so that we have a list of customers based on the following class:
public class Customer
{
public int Code { get; set; }
public string Name { get; set; }
public string City { get; set; }
public double Balance { get; set; }
public List<Customer> getCustomers()
{
string[] names = File.ReadAllLines("ListOfNames.txt");
string[] cities = { "New York", "Los Angeles", "Chicago", "New Orleans" };
int totalCustomers = names.Length;
List<Customer> list = new List<Customer>();
Random r = new Random(DateTime.Now.Millisecond);
for (int i = 1; i < totalCustomers; i++)
{
list.Add(new Customer()
{
Code = i,
Balance = r.Next(0, 10000),
Name = names[r.Next(1, 50)],
City = cities[r.Next(1, 4)]
});
}
return list;
}
}Note
There are quite a lot of random name generators you can find on the Internet, besides the ones mentioned previously. You can just configure them (they allow a certain degree of tuning) and save the results in a text file within Visual Studio. Only, remember that the copy and paste operation will most likely include a Tab code ( ) separator.
In the TuplesDemo class, which holds the entry point, the following code is defined:
static List<Customer> Customers;
static IEnumerable<Tuple<int, string, double>> Balances;
static void Main()
{
Customers = new Customer().getCustomers();
Balances = CustBalance("Chicago");
Printout();
Console.ReadLine();
}
static void Printout()
{
string formatString = " Code: {0,-6} Name: {1,-20} Balance: {2,10:C2}";
Console.WriteLine(" Balance: Customers from Chicago");
Console.WriteLine((" ").PadRight(32, '-'));
foreach (var f in Balances)
Console.WriteLine(formatString, f.Item1, f.Item2, f.Item3);
}With this structure, everything works fine, and there's no need to use anonymous objects, as we can see in the Console output:

The only imperfection comes from the way we make references to Balance members, since they lose the type names, so we have to reference them by the identifiers Item1, Item2, and so on (this has been improved in version C# 7 where tuples' members can have identifiers).
But even so, this is an advantage with respect to the previous approach, and we have more control over the generated members coming out of the LINQ query.
To finish this review on the most important features appearing in C# 4.0, I'd like to cover a new way of the instantiation of objects, named lazy initialization. The official documentation defines lazy objects and lazy initialization of an object, indicating that its creation is deferred until it is first used. (Note, here, that both terms are synonymous: initialization and instantiation).
This reminds us that Lazy initialization is primarily used to improve performance, avoid wasteful computation, and reduce program memory requirements. Typically, this happens when you have an object that takes some time to create (like a connection) or, for any reason, might produce a bottleneck.
Instead of creating the object in the usual way, .NET 4.0 introduces Lazy<T>, which defers the creation effectively, allowing evident performance improvements, as we'll see in the following demo.
Let's use the previous code, but this time, we double the method for the creation of customers by adding a lazy version of it. To be able to prove it more accurately, we introduce a delay in the constructor of the Customer class, so it finally looks like this:
public class Customer
{
public int Code { get; set; }
public string Name { get; set; }
public string City { get; set; }
public double Balance { get; set; }
public Customer()
{
// We force a delay for testing purposes
Thread.Sleep(100);
}
public List<Customer> getCustomers()
{
string[] names = File.ReadAllLines("ListOfNames.txt");
string[] cities = { "New York", "Los Angeles", "Chicago", "New Orleans" };
int totalCustomers = names.Length;
List<Customer> list = new List<Customer>();
Random r = new Random(DateTime.Now.Millisecond);
for (int i = 1; i < totalCustomers; i++)
{
list.Add(new Customer()
{
Code = i,
Balance = r.Next(0, 10000),
Name = names[r.Next(1, 50)],
City = cities[r.Next(1, 4)]
});
}
return list;
}
public List<Lazy<Customer>> getCustomersLazy()
{
string[] names = File.ReadAllLines("ListOfNames.txt");
string[] cities = { "New York", "Los Angeles", "Chicago", "New Orleans" };
int totalCustomers = names.Length;
List<Lazy<Customer>> list = new List<Lazy<Customer>>();
Random r = new Random(DateTime.Now.Millisecond);
for (int i = 1; i < totalCustomers; i++)
{
list.Add(new Lazy<Customer>(() => new Customer()
{
Code = i,
Balance = r.Next(0, 10000),
Name = names[r.Next(1, 50)],
City = cities[r.Next(1, 4)]
}));
}
return list;
}
}Note two main differences: first, the constructor forces a delay of a tenth of a second for every call. Second, the new way to create the Customer list (getCustomersLazy) is declared as List<Lazy<Customer>>. Besides, every call to the constructor comes from a lambda expression associated with the Lazy<Customer> constructor.
In the Main method, this time, we don't need to present the results; we only need to present the time elapsed for the creation of Customers using both approaches. So, we modified it in the following way:
static List<Customer> Customers;
static List<Lazy<Customer>> CustomersLazy;
static void Main()
{
Stopwatch watchLazy = Stopwatch.StartNew();
CustomersLazy = new Customer().getCustomersLazy();
watchLazy.Stop();
Console.WriteLine(" Generation of Customers (Lazy Version)");
Console.WriteLine((" ").PadRight(42, '-'));
Console.WriteLine(" Total time (milliseconds): " +
watchLazy.Elapsed.TotalMilliseconds);
Console.WriteLine();
Console.WriteLine(" Generation of Customers (non-lazy)");
Console.WriteLine((" ").PadRight(42, '-'));
Stopwatch watch = Stopwatch.StartNew();
Customers = new Customer().getCustomers();
watch.Stop();
Console.WriteLine("Total time (milliseconds): " +
watch.Elapsed.TotalMilliseconds);
Console.ReadLine();
}With these changes, the same class is called, and the same sentences are also used in creation, only changed to be lazy in the first creation process. By the way, you can change the order of creation (calling the non-lazy routine in the first place) and check whether there's no meaningful change in performance: the lazy structure executes almost instantly (hardly some more than 100 milliseconds, which is the time forced by Thread.Sleep(100) in the initial creation of Customer).
The difference, as you can see in the following screenshot, can be significant:

So, a new and useful solution for certain scenarios that appeared in version 4.0 of the framework becomes especially interesting when delaying the creation of objects can produce big differences in time for the initial presentation of the data.
One of the most requested features by programmers was the ability to create and manipulate objects without the restrictions imposed by static typing, since there are many daily situations in which this possibility offers a lot of useful options.
However, let's not mistake the dynamic features offered by C# 4.0 with the concept of Dynamic Programming in general computer science, in which the definition refers to the case where a problem is divided into smaller problems, and the optimal solution for each of these cases is sought, with the program being able to access each of these smaller solutions at a later time for optimal performance.
In the context of .NET Framework, though, C# 4.0 introduced a set of features linked to a new namespace (System.Dynamic) and a new reserved word, dynamic, which allows the declaration of elements that get rid of the type-checking feature we've seen so far.
Using the dynamic keyword, we can declare variables that are not checked in compilation time but can be resolved at runtime. For instance, we can write the following declaration without any problems (at the time of writing):
dynamic o = GetUnknownObject(); o.UnknownMethod();
In this code, o has been declared in an static way as dynamic, which is a type supported by the compiler. This code compiles even without knowing what UnknownMethod means or whether it exists at execution time. If the method doesn't exist, an exception will be thrown. Concretely, due the dynamic binding nature of the process, a Microsoft.CSharp.RuntimeBinder.RuntimeBinderException comes up, as we see when we misspell a call to the ToUpper() method in a string (we'll explain the code snippet a bit later):

When this kind of declaration appeared, there was some confusion related to the differences with declaring the previous sentence, as follows:
object p = ReturnObjectType(); ((T)p).UnknownMethod();
The difference here is that we have to know previously that a type T exists and it has a method called UnknownMethod. In this case, the casting operation ensures that an IL code is generated to guarantee that the p reference is conformant with the T type.
In the first case, the compiler cannot emit the code to call UnknownMethod because it doesn't even know whether such a method exists. Instead, it emits a dynamic call, which will be handled by another, new execution engine called Dynamic Language Runtime, or DLR.
The role of DLR, among others, is also to infer the corresponding type, and from that point, treat dynamic objects accordingly:
dynamic dyn = "This is a dynamic declared string"; Console.WriteLine(dyn.GetType()); Console.WriteLine(dyn); Console.WriteLine(dyn.Length); Console.WriteLine(dyn.ToUpper());
So, this that means we can not only use the value of dyn, but also its properties and methods like what the previous code shows, behaving in the way that's expected, and showing that dyn is a type string object and presenting the results in Console, just as if we have declared dyn as string from the beginning:

Perhaps you remember the reflection characteristics we mentioned in Chapter 1, Inside the CLR, and are wondering why we need this if many of the features available in this manner can be also managed with reflection programming.
To make a comparison, let's quickly remember how this possibility would look like (let's say we want to read the Length property):
dynamic dyn = "This is a dynamic declared string";
Type t = dyn.GetType();
PropertyInfo prop = t.GetProperty("Length");
int stringLength = prop.GetValue(dyn, new object[] { });
Console.WriteLine(dyn);
Console.WriteLine(stringLength);For this scenario, we get the same output that we expect, and technically, the performance penalty is dismissible:

It seems that both results are the same, although the way in which we get them is quite different. However, besides the boilerplate involved in reflection techniques, DLR is more efficient, and we also have the possibility of personalizing dynamic invocations.
It's true that it might seem contradictory for experienced static typing programmers: we lose the Intellisense linked to it, and the dynamic keyword forces the editor behind to understand that methods and properties accompanying such types will present themselves as dynamic as well. Refer to the tooltip shown in the next screenshot:

Part of the flexibility of this feature comes from the fact that any reference type can be converted into dynamic, and this can be done (via Boxing) with any value type.
However, once we have established our dynamic object to be of a type (such as String, in this case), the dynamism ends there. I mean, you cannot use other kinds of resources apart from those available in the definition of the String class.
One of the additions linked to this dynamic feature of the language is something called ExpandoObject, which—as you might have figured out by the name—allows you to expand an object with any number of properties of any type, keeping the compiler quiet and behaving in a similar way as it would happen when coding in real dynamic languages, such as JavaScript.
Let's look at how we can use one of these ExpandoObject object to create an object that grows in a totally dynamic way:
// Expando objects allow dynamic creation of properties
dynamic oex = new ExpandoObject();
oex.integerProp = 7;
oex.stringProp = "And this is the string property";
oex.datetimeProp = new ExpandoObject();
oex.datetimeProp.dayOfWeek = DateTime.Today.DayOfWeek;
oex.datetimeProp.time = DateTime.Now.TimeOfDay;
Console.WriteLine("Int: {0}", oex.integerProp);
Console.WriteLine("String: {0}", oex.stringProp);
Console.WriteLine("Day of Week: {0}", oex.datetimeProp.dayOfWeek);
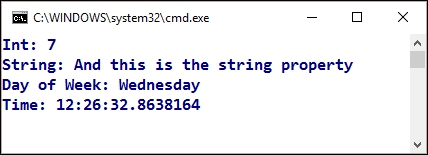
Console.WriteLine("Time: {0}", oex.datetimeProp.time);As the preceding code shows, it is not just that we can expand the object with new properties of the type we want; we can even nest objects inside each other. There's no problem at runtime, as this screenshot shows in the Console output:
Actually, these dynamic features can be used in conjunction with other generic characteristics we've already seen, since the declaration of generic dynamic objects is also allowed in this context.
To prove this, we can create a method that builds ExpandoObjects containing some information about Packt Publishing books:
public static dynamic CreateBookObject(dynamic title, dynamic pages)
{
dynamic book = new ExpandoObject();
book.Title = title;
book.Pages = pages;
return book;
}Note that everything is declared as dynamic: the method itself and the arguments passed to it as well. Later on, we can use generic collections with these objects, as shown in the following code:
var listOfBooks = new List<dynamic>();
var book1 = CreateBookObject("Mastering C# and .NET Programming", 500);
var book2 = CreateBookObject("Practical Machine Learning", 468);
listOfBooks.Add(book1);
listOfBooks.Add(book2);
var bookWith500Pages = listOfBooks.Find(b => b.Pages == 500);
Console.WriteLine("Packt Pub. Books with 500 pages: {0}",
bookWith500Pages.Title);
Console.ReadLine();Everything works as expected. Internally, ExpandoObject behaves like Dictionary<string, object>, where the name of the field added dynamically is the key (of type String), and the value is an object of any kind. So, in the previous code, the Find method of the List collection works correctly, finds the object we're looking for, and retrieves the title to show it the console:

There are some other dynamic features, but we will deal with some of them in the chapter dedicated to Interop, where we'll examine the possibilities of an interaction between a C# application and other applications in the OS, including Office applications and—generally speaking—any other application that implements and exposes a Type library.
The declaration of optional parameters had been requested by programmers a long time ago, especially considering that it's a feature that was present in Visual Basic .NET since the beginning.
The way the Redmond team implemented this is simple: you can define a constant value associated with a parameter as long as you locate the parameter at the end of the parameters' list. Thus, we can define one of those methods in this way:
static void RepeatStringOptional(int x, string text = "Message")
{
for (int i = 0; i < x; i++)
{
Console.WriteLine("String no {0}: {1}", i, text);
}
}Thus, optional parameters are characterized by being given an initial value. In this way, if the RepeatStringOptional method is called with only one argument, the text parameter is initialized with the passed value, so it will never be null. The IDE itself reminds us of such a situation when writing a call to the method.

Remember that by convention, any element enclosed in square brackets is considered optional in computer science definitions.
As a variant of the previous feature, we can also provide an argument with name using the function_name (name: arg) syntax pattern. The same structural pattern of optional arguments is followed; that is, if we pass a named argument to a function, it has to be placed after any other positional argument, although within the named parameters section their relative order does not matter.
Although it is not part of the language itself, a Base Class Library (BCL) feature is worth mentioning in this chapter, as it is one of the most important innovations in this version of the framework. Up until this point, building and executing threads was something that was covered mainly in two forms: using the objects provided by the System.Thread namespace (available since version 1.0 of the framework) and from version 3.0, using the BackgroundWorker object, which was a wrapper on top of a functionality available in System.Thread to facilitate the creation of these objects.
The latter was primarily used in long duration processes, when a feedback was required during execution (progress bars, among others). It was a first attempt to ease thread programming, but since the new Task object came up, most of these scenarios (and many others, implying parallel or thread running processes) are mainly coded in this way.
Its usage is simple (especially when compared to previous options). You can declare a Task non-generic object and associate it with any method with the help of an Action delegate, as the IDE suggests when creating a new task by calling its constructor:

So, if we have a slow method and we have no special requirements about the type returned (so it can be non-generic), it's possible to call it in a separate thread by writing the following:
public static string theString = "";
static void Main(string[] args)
{
Task t = new Task(() =>
{
SlowMethod(ref theString);
});
t.Start();
Console.WriteLine("Waiting for SlowMethod to finish...");
t.Wait();
Console.WriteLine("Finished at: {0}",theString);
}
static void SlowMethod(ref string value)
{
System.Threading.Thread.Sleep(3000);
value = DateTime.Now.ToLongTimeString();
}Note a few details in this code: first, the argument is passed by reference. This means that the value of theString is changed by SlowMethod, but no return type is provided because the method should fit the signature of an Action (no return type); thus, to access the modified value, we pass it by reference and include in our SlowMethod code how to modify it.
The other main point is that we need to wait until SlowMethod finishes before trying to access theString (observe that the method is forced to take 3 seconds to complete by calling Thread.Sleep(3000). Otherwise, execution would continue and the value accessed would be just the original empty string. In between, it's possible to perform other actions, such as printing a message in the console.
A generic variation of this object is also provided when we need Task to operate with a given type. As long as we define a variable of type Task<T>, the IDE changes the tooltip to remind us that in this case, a delegate of type Func<T> should be provided instead of Action, as is the case. You can compare this screenshot with the previous one:

However, in the following code, we adopt the more common approach of creating the generic Task object by calling the StartNew<T> method available in the Factory object of Task<T>, so we can simplify the former example in this manner:
static void Main(string[] args)
{
Task<string> t = Task.Factory.StartNew<string>(
() => SlowMethod());
Console.WriteLine("Waiting for SlowMethod to finish...");
t.Wait();
Console.WriteLine("Finished at: {0}", t.Result);
Console.ReadLine();
}
static string SlowMethod()
{
System.Threading.Thread.Sleep(3000);
return DateTime.Now.ToLongTimeString();
}As you can see, this time we don't need an intermediate variable to store the return value, and the Task<T> definition allows you to create a Task object of almost any type.
There's much more about tasks and related features, such as parallel execution, asynchronous calls, and so on, so we'll go deeper into all this in Chapter 12, Performance, which we dedicate to performance and optimization, so take this as a very brief introduction to the subject.