
AdaBoost.SAMME.R is a variant that works with classifiers that can output prediction probabilities. This is normally possible employing techniques such as Platt scaling, but it's important to check whether a specific classifier implementation is able to output the probabilities without any further action. For example, SVM implementations provided by Scikit-Learn don't compute the probabilities unless the parameter probability=True (because they require an extra step that could be useless in some cases).
In this case, we assume that the output of each classifier is a probability vector:

Each component is the conditional probability that the jth class is output given the input xi. When working with a single estimator, the winning class is obtained through the argmax(•) function; however, in this case, we want to re-weight each learner so as to obtain a sequentially grown ensemble. The basic idea is the same as AdaBoost.M1, but, as now we manage probability vectors, we also need an estimator weighting function that depends on the single sample xi (this function indeed wraps every single estimator that is now expressed as a probability vectorial function pi(t)(y=i|x)):
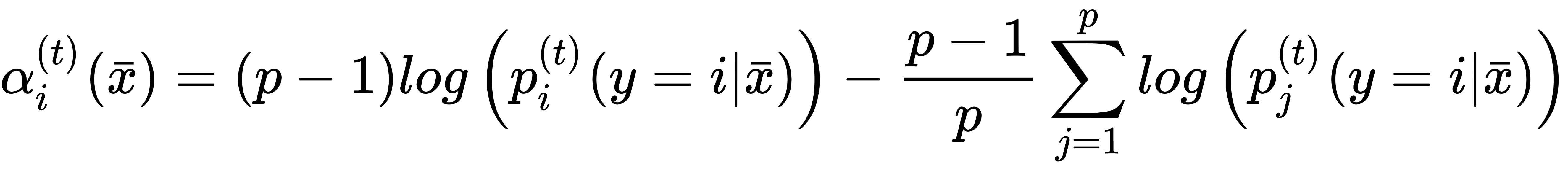
Considering the properties of logarithms, the previous expression is equivalent to a discrete α(t); however, in this case, we don't rely on a weighted error sum (the theoretical explanation is rather complex and is beyond the scope of this book. The reader can find it in the aforementioned paper, even if the method presented in the next chapter discloses a fundamental part of the logic). To better understand the behavior of this function, let's consider a simple scenario with p = 2. The first case is a sample that the learner isn't able to classify (p=(0.5, 0.5)):
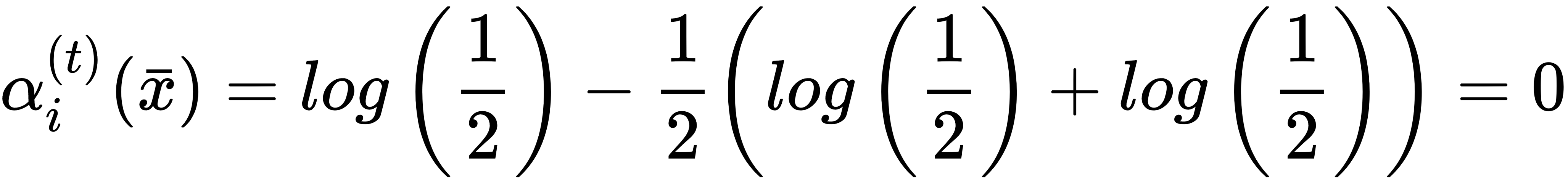
In this case, the uncertainty is maximal and the classifier cannot be trusted for this sample, so the weight becomes null for all output probabilities. Now, let's apply the boosting, obtaining the probability vector p=(0.7, 0.3):

The first class will become positive and its magnitude will increase when p → 1, while the other one is the opposite value. Therefore, the functions are symmetric and allow working with a sum:

This approach is very similar to a weighted majority vote because the winning class yi is computed taking into account not only the number of estimators whose output is yi but also their relative weight and the negative weight of the remaining classifiers. A class can be selected only if the strongest classifiers predicted it and the impact of the other learners is not sufficient to overturn this result.
In order to update the weights, we need to consider the impact of all probabilities. In particular, we want to reduce the uncertainty (which can degenerate to a purely random guess) and force a superior attention focused on all those samples that have been misclassified. To achieve this goal, we need to define the yi and p(t)(xi) vectors, which contain, respectively, the one-hot encoding of the true class (for example, (0, 0, 1, ..., 0)) and the output probabilities yielded by the estimator (as a column vector). Hence, the update rule becomes as follows:

If, for example, the true vector is (1, 0) and the output probabilities are (0.1, 0.9), with η=1, the weight of the sample will be multiplied by about 3.16. If instead, the output probabilities are (0.9, 0.1), meaning the sample has been successfully classified, the multiplication factor will become closer to 1. In this way, the new data distribution D(t+1), analogously to AdaBoost.M1, will be more peaked on the samples that need more attention. All implementations include the learning rate as a hyperparameter because, as already explained, the default value equal to 1.0 cannot be the best choice for specific problems. In general, a lower learning rate allows reducing the instability when there are many outliers and improves the generalization ability thanks to a slower convergence towards the optimum. When η < 1, every new distribution is slightly more focused on the misclassified samples, allowing the estimators to search for a better parameter set without big jumps (that can lead the estimator to skip an optimal point). However, contrary to Neural Networks that normally work with small batches, AdaBoost can often perform quite well also with η=1 because the correction is applied only after a full training step. As usual, I recommend performing a grid search to select the right values for each specific problem.
The complete AdaBoost.SAMME.R algorithm is as follows:
- Set the family and the number of estimators Nc
- Set the initial weights W(1) equal to 1/M
- Set the learning rate η (for example, η = 1)
- Set the initial distribution D(1) equal to the dataset X
- For i=1 to Nc:
- Train the ith estimator di(x) with the data distribution D(i)
- Compute the output probabilities for each class and each training sample
- Compute the estimator weights αj(i)
- Update the weights using the exponential formula (with or without the learning rate)
- Normalize the weights
- Create the global estimator applying the argmax(•) function to the sum αj(i) (for i=1 to Nc)