
A slightly more complex variant has been proposed by Drucker (in Improving Regressors using Boosting Techniques, Drucker H., ICML 1997) to manage regression problems. The weak learners are commonly decision trees and the main concepts are very similar to the other variants (in particular, the re-weighting process applied to the training dataset). The real difference is the strategy adopted in order to choose the final prediction yi given the input sample xi. Assuming that there are Nc estimators and each of them is represented as function dt(x), we can compute the absolute residual ri(t) for every input sample:

Once the set Ri containing all the absolute residuals has been populated, we can compute the quantity Sr = sup Ri and compute the values of a cost function that must be proportional to the error. The common choice that is normally implemented (and suggested by the author himself) is a linear loss:

This loss is very flat and it's directly proportional to the error. In most cases, it's a good choice because it avoids premature over-specialization and allows the estimators to readapt their structure in a gentler way. The most obvious alternative is the square loss, which starts giving more importance to those samples whose prediction error is larger. It is defined as follows:

The last cost function is strictly related to AdaBoost.M1 and it's exponential:

This is normally a less robust choice because, as we are also going to discuss in the next section, it penalizes small errors in favor of larger ones. Considering that these functions are also employed in the re-weighting process, an exponential loss can force the distribution to assign very high probabilities to samples whose misclassification error is high, driving the estimators to become over-specialized with effect from the first iterations. In many cases (such as in neural networks), the loss functions are normally chosen according to their specific properties but, above all, to the ease to minimize them. In this particular scenario, loss functions are a fundamental part of the boosting process and they must be chosen considering the impact on the data distribution. Testing and cross-validation provide the best tool to make a reasonable decision.
Once the loss function has been evaluated for all training samples, it's possible to build the global cost function as the weighted average of all losses. Contrary to many algorithms that simply sum or average the losses, in this case, it's necessary to consider the structure of the distribution. As the boosting process reweights the samples, also the corresponding loss values must be filtered to avoid a bias. At the iteration t, the cost function is computed as follows:

This function is proportional to the weighted errors, which can be either linearly filtered or emphasized using a quadratic or exponential function. However, in all cases, a sample whose weight is lower will yield a smaller contribution, letting the algorithm focus on the samples more difficult to be predicted. Consider that, in this case, we are working with classifications; therefore, the only measure we can exploit is the loss. Good samples yield low losses, hard samples yield proportionally higher losses. Even if it's possible to use C(t) directly, it's preferable to define a confidence measure:

This index is inversely proportional to the average confidence at the iteration t. In fact, when C(t) → 0, γ(t) → 0 and when C(t) → ∞, γ(t) → 1. The weight update is performed considering the overall confidence and the specific loss value:
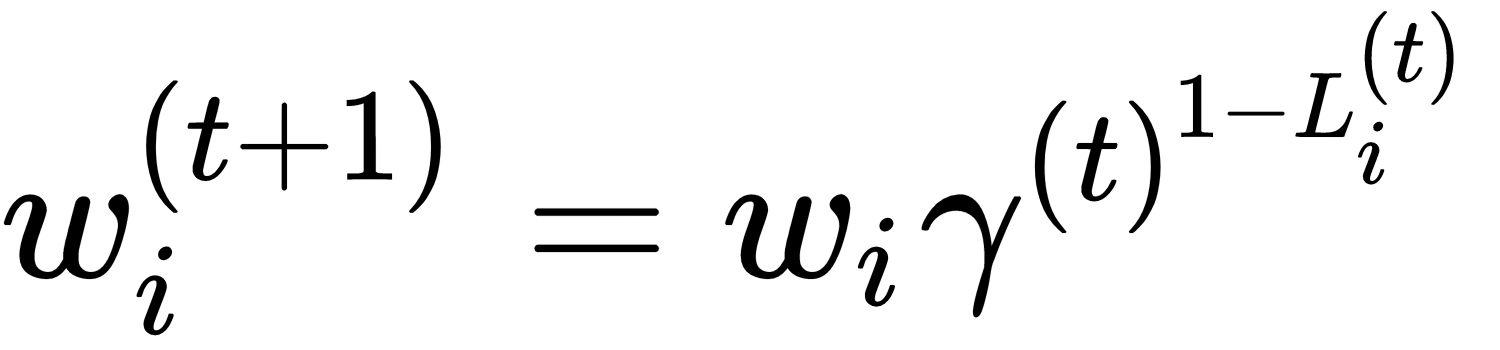
A weight will be decreased proportionally to the loss associated with the corresponding absolute residual. However, instead of using a fixed base, the global confidence index is chosen. This strategy allows a further degree of adaptability, because an estimator with a low confidence doesn't need to focus only on a small subset and, considering that γ(t) is bounded between 0 and 1 (worst condition), the exponential becomes ineffective when the cost function is very high (1x = 1), so that the weights remain unchanged. This procedure is not very dissimilar to the one adopted in other variants, but it tries to find a trade-off between global accuracy and local misclassification problems, providing an extra degree of robustness.
The most complex part of this algorithm is the approach employed to output a global prediction. Contrary to classification algorithms, we cannot easily compute an average, because it's necessary to consider the global confidence at each iteration. Drucker proposed a method based on the weighted median of all outputs. In particular, given a sample xi, we define the set of predictions:

As weights, we consider the log(1 / γ(t)), so we can define a weight set:

The final output is the median of Y weighted according to Γ (normalized so that the sum is 1.0). As γ(t) → 1 when the confidence is low, the corresponding weight will tend to 0. In the same way, when the confidence is high (close to 1.0), the weight will increase proportionally and the chance to pick the output associated with it will be higher. For example, if the outputs are Y = {1, 1.2, 1.3, 2.0, 2.2, 2.5, 2.6} and the weights are Γ = { 0.35, 0.15, 0.12, 0.11, 0.1, 0.09, 0.08 }, the weighted median corresponds to the second index, therefore the global estimator will output 1.2 (which is, also intuitively, the most reasonable choice).
The procedure to find the median is quite simple:
- The yi(t) must be sorted in ascending order, so that yi(1) < yi(2) < ... < yi(Nc)
- The set Γ is sorted accordingly to the index of yi(t) (each output yi(t) must carry its own weight)
- The set Γ is normalized, dividing it by its sum
- The index corresponding to the smallest element that splits Γ into two blocks (whose sums are less than or equal to 0.5) is selected
- The output corresponding to this index is chosen
The complete AdaBoost.R2 algorithm is as follows:
- Set the family and the number of estimators Nc
- Set the initial weights W(1) equal to 1/M
- Set the initial distribution D(1) equal to the dataset X
- Select a loss function L
- For i=1 to Nc:
- Train the ith estimator di(x) with the data distribution D(i)
- Compute the absolute residuals, the loss values, and the confidence measures
- Compute the global cost function
- Update the weights using the exponential formula
- Create the global estimator using the weighted median