
A simpler but no less effective way to create an ensemble is based on the idea of exploiting a limited number of strong learners whose peculiarities allow them to yield better performances in particular regions of the sample space. Let's start considering a set of Nc discrete-valued classifiers f1(x), f2(x), ..., fNc(x). The algorithms are different, but they are all trained with the same dataset and output the same label set. The simplest strategy is based on a hard-voting approach:

In this case, the function n(•) counts the number of estimators that output the label yi. This method is rather powerful in many cases, but has some limitations. If we rely only on a majority vote, we are implicitly assuming that a correct classification is obtained by a large number of estimators. Even if, Nc/2 + 1 votes are necessary to output a result, in many cases their number is much higher. Moreover, when k is not very large, also Nc/2 + 1 votes imply a symmetry that involves a large part of the population. This condition often drives to the training of useless models that could be simply replaced by a single well-fitted strong learner. In fact, let's suppose that the ensemble is made up of three classifiers and one of them is more specialized in regions where the other two can easily be driven to misclassifications. A hard-voting strategy applied to this ensemble could continuously penalize the more complex estimator in favor of the other classifiers. A more accurate solution can be obtained by considering real-valued outcomes. If each estimator outputs a probability vector, the confidence of a decision is implicitly encoded in the values. For example, a binary classifier whose output is (0.52, 0.48) is much more uncertain than another classifier outputting (0.95, 0.05). Applying a threshold is equivalent to flattening the probability vectors and discarding the uncertainty. Let's consider an ensemble with three classifiers and a sample that is hard to classify because it's very close to the separation hyperplane. A hard-voting strategy decides for the first class because the thresholded output is (1, 1, 2). Then we check the output probabilities, obtaining (0.51, 0.49), (0.52, 0.48), (0.1, 0.9). After averaging the probabilities, the ensemble output becomes about (0.38, 062) and by applying argmax(•), we get the second class as the final decision. In general, it's also a good practice to consider a weighted average, so that the final class is obtained as follows (assuming the output of the classifier is a probability vector):
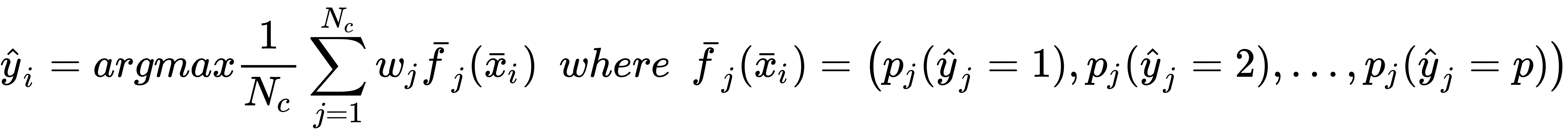
The weights can be simply equal to 1.0 if no weighting is required or they can reflect the level of trust we have for each classifier. An important rule is to avoid the dominance of a classifier in the majority of cases because it would be an implicit fallback to a single estimator scenario. A good voting example should always allow a minority to overturn a result when their confidence is quite higher than the majority. In this strategies, the weights can be considered as hyperparameters and tuned up using a grid search with cross-validation. However, contrary to other ensemble methods, they are not fine-grained, therefore the optimal value is often a compromise among some different possibilities.
A slightly more complex technique is called stacking and consists of using an extra classifier as a post-filtering step. The classical approach consists of training the classifiers separately, then the whole dataset is transformed into a prediction set (based on class labels or probabilities) and the combining classifier is trained to associate the predictions to the final classes. Using even very simple models like Logistic Regressions or Perceptrons, it's possible to mix up the predictions so as to implement a dynamic reweighting that is a function of the input values. A more complex approach is feasible only when a single training strategy can be used to train the whole ensemble (including the combiner). For example, it could be employed with neural networks that, however, have already an implicit flexibility and can often perform quite better than complex ensembles.