
This model (which represents the state-of-the-art recurrent cell in many fields) was proposed in 1997 by Hochreiter and Schmidhuber (in Long Short-Term Memory, Hochreiter S., Schmidhuber J., Neural Computation, Vol. 9, 11/1997) with the emblematic name long-short-term memory (LSTM). As the name suggests, the idea is to create a more complex artificial recurrent neuron that can be plugged into larger networks and trained without the risk of vanishing and, of course, exploding gradients. One of the key elements of classic recurrent networks is that they are focused on learning, but not on selectively forgetting. This ability is indeed necessary for optimizing the memory in order to remember what is really important and removing all those pieces of information that are not necessary to predict new values.
To achieve this goal, LSTM exploits two important features (it's helpful to expose them before discussing the model). The first one is an explicit state, which is a separate set of variables that store the elements necessary to build long and short-term dependencies, including the current state. These variables are the building blocks of a mechanism called constant error carousel (CEC), named in this way because it's responsible for the cyclical and internal management of the error provided by the backpropagation algorithm. This approach allows the correction of the weights without suffering the multiplicative effect anymore. The internal LSTM dynamics allow better understanding of how the error is safely fed back; however, the exact explanation of the training procedure (which is always based on the gradient descent) is beyond the scope of this book and can be found in the aforementioned paper.
The second feature is the presence of gates. We can simply define a gate as an element that can modulate the amount of information flowing through it. For example, if y = ax and a is a variable bounded between 0 and 1, it can be considered as a gate, because when it's equal to 0, it blocks the input x; when it's equal to 1, it allows the input to flow in without restrictions; and when it has an intermediate value, it reduces the amount of information proportionally. In LSTMs, gates are managed by sigmoid functions, while the activations are based on hyperbolic tangents (whose symmetry guarantees better performances). At this point, we can show the structural diagram of an LSTM cell and discuss its internal dynamics:

The first (and most important) element is the memory state, which is responsible for the dependencies and for the actual output. In the diagram, it is represented by the upper line and its dynamics are represented by the following general equation:

So, the state depends on the previous value, on the current input, and on the previous output. Let's start with the first term, introducing the forget gate. As the name says, it's responsible for the persistence of the existing memory elements or for their deletion. In the diagram, it's represented by the first vertical block and its value is obtained by considering the concatenation of previous output and current input:

The operation is a classical neuron activation with a vectorial output. An alternative version can use two weight matrices and keep the input elements separated:

However, I prefer the previous version, because it can better express the homogeneity of input and output, and also their consequentiality. Using the forget gate, it's possible to determine the value of g1(C(t)) using the Hadamard (or element-wise) product:

The effect of this computation is filtering the content of C(t) that must be preserved and the validity degree (which is proportional to the value of f(t+1)). If the forget gate outputs a value close to 1, the corresponding element is still considered valid, while lower values determine a sort of obsolescence that can even lead the cell to completely remove an element when the forget gate value is 0 or close to it. The next step is to consider the amount of the input sample that must be considered to update the state. This task is achieved by the input gate (second vertical block). The equation is perfectly analogous to the previous one:

However, in this case, we also need to compute the term that must be added to the current state. As already mentioned, LSTM cells employ hyperbolic tangents for the activations; therefore, the new contribution to the state is obtained as follows:
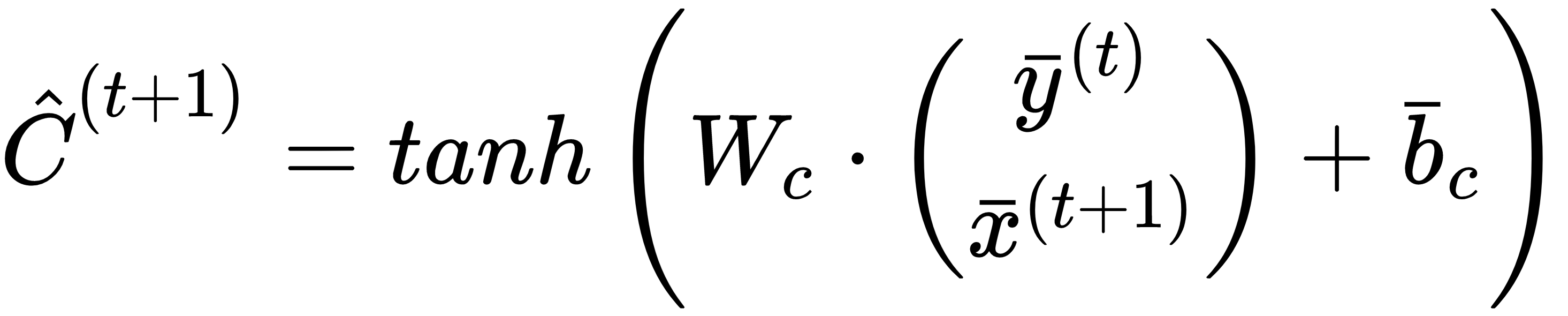
Using the input gate and the state contribution, it's possible to determine the function g2(x(t+1), y(t)):

Hence, the complete state equation becomes as follows:

Now, the inner logic of an LSTM cell is more evident. The state is based on the following:
- A dynamic balance between previous experience and its re-evaluation according to new experience (modulated by the forget gate)
- The semantic effect of the current input (modulated by the input gate) and the potential additive activation
Realistic scenarios are many. It's possible that a new input forces the LSTM to reset the state and store the new incoming value. On the other hand, the input gate can also remain closed, giving a very low priority to the new input (together with the previous output). In this case, the LSTM, considering the long-term dependencies, can decide to discard a sample that is considered noisy and not necessarily able to contribute to an accurate prediction. In other situations, both the forget and input gates can be partially open, letting only some values influence the state. All these possibilities are managed by the learning process through the correction of the weight matrices and the biases. The difference with BPTT is that the long-term dependencies are no longer impeded by the vanishing gradients problem.
The last step is determining the output. The third vertical block is called the output gate and controls the information that must transit from the state to the output unit. Its equation is as follows:

The actual output is hence determined as follows:

An important consideration concerns the gates. They are all fed with the same vector, containing the previous output and the current input. As they are homogenous values, the concatenation yields a coherent entity that encodes a sort of inverse cause-effect relationship (this is an improper definition, as we work with previous effect and current cause). The gates work like logistic regressions without thresholding; therefore, they can be considered as pseudo-probability vectors (not distributions, as each element is independent). The forget gate expresses the probability that last sequence (effect, cause) is more important than the current state; however, only the input gate has the responsibility to grant it the right to influence the new state. Moreover, the output gate expresses the probability that the current sequence is able to let the current state flow out. The dynamic is indeed very complex and has some drawbacks. For example, when the output gate remains closed, the output is close to zero and this influences both forget and input gates. As they control the new state and the CEC, they could limit the amount of incoming information and consequent corrections, leading to poor performance.
A simple solution that can mitigate this problem is provided by a variant called peephole LSTM. The idea is to feed the previous state to every gate so that they can take decisions more independently. The generic gate equation becomes as follows:

The new set of weights Ug (for all three gates) must be learned in the same way as the standard Wg and bg. The main difference with a classic LSTM is that the sequential dynamic: forget gate | input gate | new state | output gate | actual output is now partially shortcutted. The presence of the state in every gate activation allows them to exploit multiple recurrent connections, yielding a better accuracy in many complex situations. Another important consideration is about the learning process: in this case, the peepholes are closed and the only feedback channel is the output gate. Unfortunately, not every LSTM implementation support peepholes; however, several studies confirmed that in most cases all the models yield similar performances.
Xingjian et al. (in Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, Xingjian S., Zhourong C., Hao W., Dit-Yan Y., Wai-kin W., Wang-Chun W., arXiv:1506.04214 [cs.CV]) proposed a variant called convolutional LSTM, which clearly mixes Convolutions and LSTM cells. The main internal difference concerns the gate computations, which now become (without peepholes, which however, can always be added):

Wg is now a kernel that is convoluted with the input-output vector (which is usually the concatenation of two images). Of course, it's possible to train any number of kernels to increase the decoding power of the cell and the output will have a shape equal to (batch size × width × height × kernels). This kind of cell is particularly useful for joining spatial processing with a robust temporal approach. Given a sequence of images (for example, satellite images, game screenshots, and so on), a convolutional LSTM network can learn long-term relationships that are manifested through geometric feature evolutions (for example, cloud movements or specific sprite strategies that it's possible to anticipate considering a long history of events). This approach (even with a few modifications) is widely employed in Deep Reinforcement Learning in order to solve complex problems where the only input is provided by a sequence of images. Of course, the computational complexity is very high, in particular when many subsequent layers are used; however, the results outperformed any existing method and this approach became one of the first choices to manage this kind of problem.
Another important variant, which is common to many Recurrent Neural Networks, is provided by a bidirectional interface. This isn't an actual layer, but a strategy that is employed in order to join the forward analysis of a sequence with the backward one. Two cellblocks are fed with a sequence and its inverse and the output, for example, is concatenated and used for further processing steps. In fields such as NLP, this method allows us to dramatically improve the accuracy of classifications and real-time translations. The reason is strictly related to the rules underlying the structure of a sequence. In natural language, a sentence w1 w2 ... wn has forward relationships (for example, a singular noun can be followed by is), but the knowledge of backward relationships (for example, the sentence this place is pretty awful) permits avoiding common mistakes that, in the past, had to be corrected using post-processing steps (the initial translation of pretty could be similar to the translation of nice, but a subsequent analysis can reveal that the adjective mismatches and a special rule can be applied). Deep learning, on the other side, is not based on special rules, but on the ability to learn an internal representation that should be autonomous in making final decisions (without further external aids) and bidirectional LSTM networks help in reaching this goal in many important contexts.