
Many algorithms show better performances (above all, in terms of training speed) when the dataset is symmetric (with a zero-mean). Therefore, one of the most important preprocessing steps is so-called zero-centering, which consists in subtracting the feature-wise mean Ex[X] from all samples:

This operation, if necessary, is normally reversible, and doesn't alter relationships both among samples and among components of the same sample. In deep learning scenarios, a zero-centered dataset allows exploiting the symmetry of some activation function, driving to a faster convergence (we're going to discuss these details in the next chapters).
Another very important preprocessing step is called whitening, which is the operation of imposing an identity covariance matrix to a zero-centered dataset:

As the covariance matrix Ex[XTX] is real and symmetric, it's possible to eigendecompose it without the need to invert the eigenvector matrix:
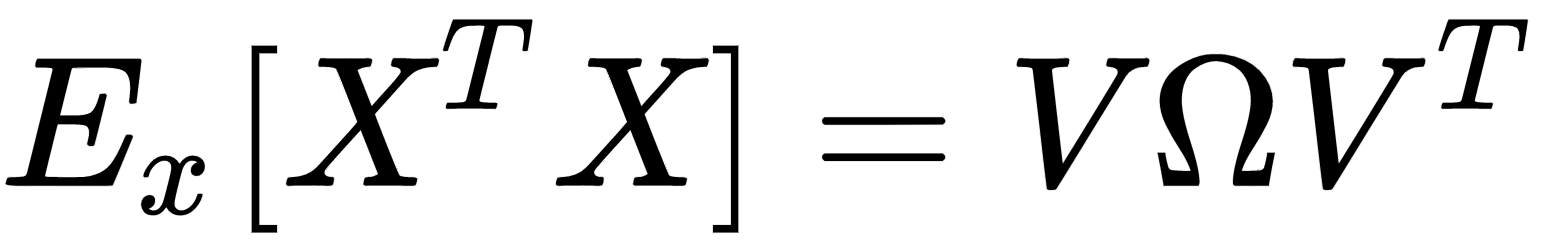
The matrix V contains the eigenvectors (as columns), and the diagonal matrix Ω contains the eigenvalues. To solve the problem, we need to find a matrix A, such that:

Using the eigendecomposition previously computed, we get:

Hence, the matrix A is:

One of the main advantages of whitening is the decorrelation of the dataset, which allows an easier separation of the components. Furthermore, if X is whitened, any orthogonal transformation induced by the matrix P is also whitened:

Moreover, many algorithms that need to estimate parameters that are strictly related to the input covariance matrix can benefit from this condition, because it reduces the actual number of independent variables (in general, these algorithms work with matrices that become symmetric after applying the whitening). Another important advantage in the field of deep learning is that the gradients are often higher around the origin, and decrease in those areas where the activation functions (for example, the hyperbolic tangent or the sigmoid) saturate (|x| → ∞). That's why the convergence is generally faster for whitened (and zero-centered) datasets.
In the following graph, it's possible to compare an original dataset, zero-centering, and whitening:

When a whitening is needed, it's important to consider some important details. The first one is that there's a scale difference between the real sample covariance and the estimation XTX, often adopted with the singular value decomposition (SVD). The second one concerns some common classes implemented by many frameworks, like Scikit-Learn's StandardScaler. In fact, while zero-centering is a feature-wise operation, a whitening filter needs to be computed considering the whole covariance matrix (StandardScaler implements only unit variance, feature-wise scaling).
Luckily, all Scikit-Learn algorithms that benefit from or need a whitening preprocessing step provide a built-in feature, so no further actions are normally required; however, for all readers who want to implement some algorithms directly, I've written two Python functions that can be used both for zero-centering and whitening. They assume a matrix X with a shape (NSamples × n). Moreover, the whiten() function accepts the parameter correct, which allows us to apply the scaling correction (the default value is True):
import numpy as np
def zero_center(X):
return X - np.mean(X, axis=0)
def whiten(X, correct=True):
Xc = zero_center(X)
_, L, V = np.linalg.svd(Xc)
W = np.dot(V.T, np.diag(1.0 / L))
return np.dot(Xc, W) * np.sqrt(X.shape[0]) if correct else 1.0