
Let's now consider a parameterized model with a single vectorial parameter (this isn't a limitation, but only a didactic choice):

The goal of a learning process is to estimate the parameter θ so as, for example, to maximize the accuracy of a classification. We define the bias of an estimator (in relation to a parameter θ):

In other words, the bias is the difference between the expected value of the estimation and the real parameter value. Remember that the estimation is a function of X, and cannot be considered a constant in the sum.
An estimator is said to be unbiased if:

Moreover, the estimator is defined as consistent if the sequence of estimations converges (at least with probability 1) to the real value when k → ∞:

Given a dataset X whose samples are drawn from pdata, the accuracy of an estimator is inversely proportional to its bias. Low-bias (or unbiased) estimators are able to map the dataset X with high-precision levels, while high-bias estimators are very likely to have a capacity that isn't high enough for the problem to solve, and therefore their ability to detect the whole dynamic is poor.
Let's now compute the derivative of the bias with respect to the vector θ (it will be useful later):
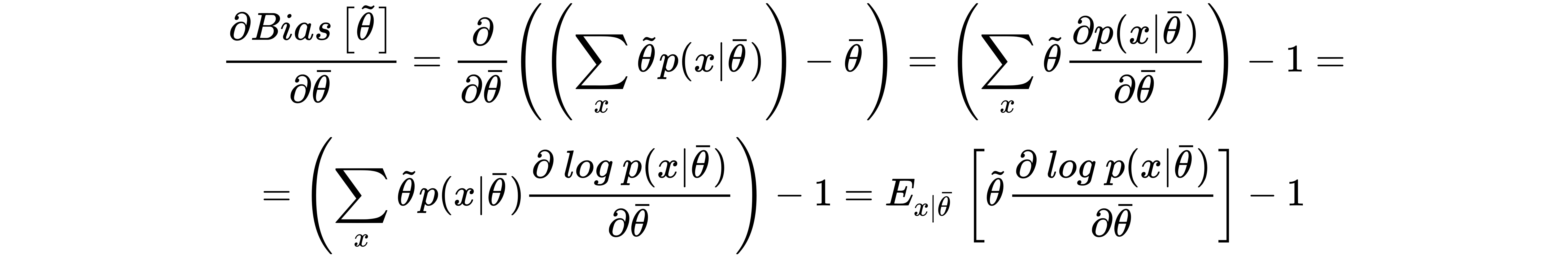
Consider that the last equation, thanks to the linearity of E[•], holds also if we add a term that doesn't depend on x to the estimation of θ. In fact, in line with the laws of probability, it's easy to verify that:
