
When we discussed the cluster assumption, we also defined the low-density regions as boundaries and the corresponding problem as low-density separation. A common supervised classifier which is based on this concept is a Support Vector Machine (SVM), the objective of which is to maximize the distance between the dense regions where the samples must be. For a complete description of linear and kernel-based SVMs, please refer to Bonaccorso G., Machine Learning Algorithms, Packt Publishing; however, it's useful to remind yourself of the basic model for a linear SVM with slack variables ξi:

This model is based on the assumptions that yi can be either -1 or 1. The slack variables ξi or soft-margins are variables, one for each sample, introduced to reduce the strength imposed by the original condition (min ||w||), which is based on a hard margin that misclassifies all the samples that are on the wrong side. They are defined by the Hinge loss, as follows:
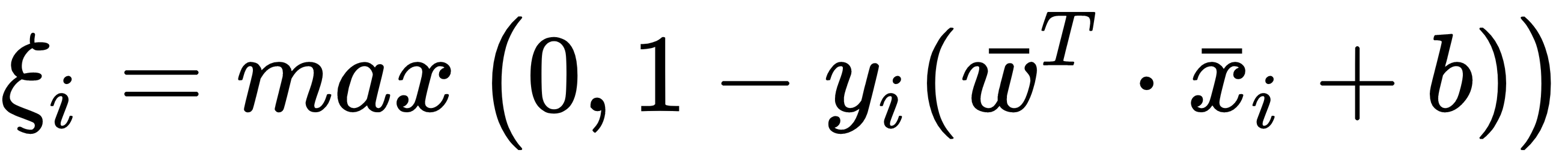
With those variables, we allow some points to overcome the limit without being misclassified if they remain within a distance controlled by the corresponding slack variable (which is also minimized during the training phase, so as to avoid uncontrollable growth). In the following diagram, there's a schematic representation of this process:

The last elements of each high-density regions are the support vectors. Between them, there's a low-density region (it can also be zero-density in some cases) where our separating hyperplane lies. In Chapter 1, Machine Learning Model Fundamentals, we defined the concept of empirical risk as a proxy for expected risk; therefore, we can turn the SVM problem into the minimization of empirical risk under the Hinge cost function (with or without Ridge Regularization on w):

Theoretically, every function which is always bounded by two hyperplanes containing the support vectors is a good classifier, but we need to minimize the empirical risk (and, so, the expected risk); therefore we look for the maximum margin between high-density regions. This model is able to separate two dense regions with irregular boundaries and, by adopting a kernel function, also in non-linear scenarios. The natural question, at this point, is about the best strategy to integrate labeled and unlabeled samples when we need to solve this kind of problem in a semi-supervised scenario.
The first element to consider is the ratio: if we have a low percentage of unlabeled points, the problem is mainly supervised and the generalization ability learned using the training set should be enough to correctly classify all the unlabeled points. On the other hand, if the number of unlabeled samples is much larger, we return to an almost pure clustering scenario (like the one discussed in the paragraph about the Generative Gaussian mixtures). In order to exploit the strength of semi-supervised methods in low-density separation problems, therefore, we should consider situations where the ratio labeled/unlabeled is about 1.0. However, even if we have the predominance of a class (for example, if we have a huge unlabeled dataset and only a few labeled samples), it's always possible to use the algorithms we're going to discuss, even if, sometimes, their performance could be equal to or lower than a pure supervised/clustering solution. Transductive SMVs, for example, showed better accuracies when the labeled/unlabeled ratio is very small, while other methods can behave in a completely different way. However, when working with semi-supervised learning (and its assumptions), it is always important to bear in mind that each problem is supervised and unsupervised at the same time and the best solution must be evaluated in every different context.
A solution for this problem is offered by the Semi-Supervised SVM (also known as S3VM) algorithm. If we have N labeled samples and M unlabeled samples, the objective function becomes as follows:

The first term imposes the standard SVM condition about the maximum separation distance, while the second block is divided into two parts:
- We need to add N slack variables ηi to guarantee a soft-margin for the labeled samples.
- At the same time, we have to consider the unlabeled points, which could be classified as +1 or -1. Therefore, we have two corresponding slack-variable sets ξi and zi. However, we want to find the smallest variable for each possible pair, so as to be sure that the unlabeled sample is placed on the sub-space where the maximum accuracy is achieved.
The constraints necessary to solve the problems become as follows:

The first constraint is limited to the labeled points and it's the same as a supervised SVM. The following two, instead, take into account the possibility that an unlabeled sample could be classified as +1 or -1. Let's suppose, for example, that the label yj for the sample xj should be +1 and the first member of the second inequality is a positive number K (so the corresponding term of the third equation is -K). It's easy to verify that the first slack variable is ξi ≥ 1 - K, while the second one is zj ≥ 1 + K.
Therefore, in the objective, ξi is chosen to be minimized. This method is inductive and yields good (if not excellent) performances; however, it has a very high computational cost and should be solved using optimized (native) libraries. Unfortunately, it is a non-convex problem and there are no standard methods to solve it so it always reaches the optimal configuration.