
Scikit-Learn implements a slightly different algorithm proposed by Zhu and Ghahramani (in the aforementioned paper) where the affinity matrix W can be computed using both methods (KNN and RBF), but it is normalized to become a probability transition matrix:
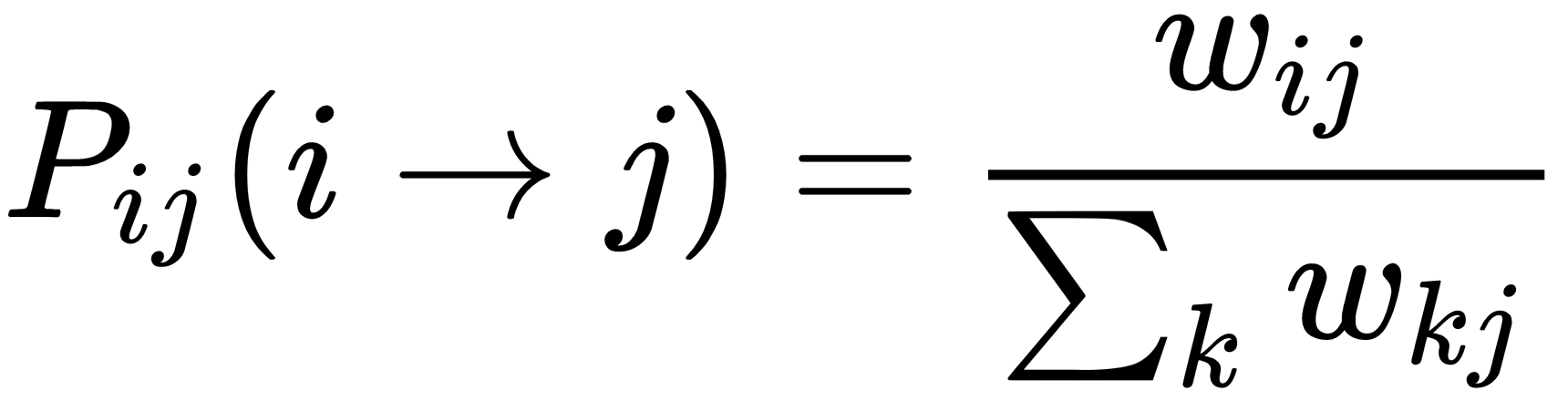
The algorithm operates like a Markov random walk, with the following sequence (assuming that there are Q different labels):
- Define a matrix YMi = [P(label=y0), P(label=y1), ..., and P(label=yQ)], where P(label=yi) is the probability of the label yi, and each row is normalized so that all the elements sum up to 1
- Define Y(0) = YM
- Iterate until convergence of the following steps:

The first update performs a label propagation step. As we're working with probabilities, it's necessary (second step) to renormalize the rows so that their element sums up to 1. The last update resets the original labels for all labeled samples. In this case, it means imposing a P(label=yi) = 1 to the corresponding label, and setting all the others to zero. The proof of convergence is very similar to the one for label propagation algorithms, and can be found in Learning from Labeled and Unlabeled Data with Label Propagation, Zhu X., Ghahramani Z., CMU-CALD-02-107. The most important result is that the solution can be obtained in closed form (without any iteration) through this formula:

The first term is the sum of a generalized geometric series, where Puu is the unlabeled-unlabeled part of the transition matrix P. Pul, instead, is the unlabeled-labeled part of the same matrix.
For our Python example, we need to build the dataset differently, because Scikit-Learn considers a sample unlabeled if y=-1:
from sklearn.datasets import make_classification
nb_samples = 1000
nb_unlabeled = 750
X, Y = make_classification(n_samples=nb_samples, n_features=2, n_informative=2, n_redundant=0, random_state=100)
Y[nb_samples - nb_unlabeled:nb_samples] = -1
We can now train a LabelPropagation instance with an RBF kernel and gamma=10.0:
from sklearn.semi_supervised import LabelPropagation
lp = LabelPropagation(kernel='rbf', gamma=10.0)
lp.fit(X, Y)
Y_final = lp.predict(X)
The result is shown in the following double plot:

As expected, the propagation converged to a solution that respects both the smoothness and the clustering assumption.