
Chapter 9. DECODE and CASE
Whether it is for user presentation, report formatting, or data feed extraction, data is seldom presented exactly as it is stored in the database. Instead, data is generally combined, translated, or formatted in some way. Although procedural languages such as PL/SQL and Java provide many tools for manipulating data, it is often desirable to perform these manipulations as the data is extracted from the database. Similarly, when updating data, it is far easier to modify the data in place rather than to extract it, modify it, and apply the modified data back to the database. This chapter will focus on two powerful features of Oracle SQL that facilitate various data manipulations: the CASE expression and the DECODE function. Along the way we’ll also demonstrate the use of several other functions (such as NVL and NVL2).
DECODE, NULLIF, NVL, and NVL2
Most of Oracle’s built-in functions are designed to solve a specific problem. If you need to find the last day of the month containing a particular date, for example, the LAST_DAY function is just the ticket. The DECODE, NULLIF, NVL, and NVL2 functions, however, do not solve a specific problem; rather, they are best described as inline if-then-else statements. These functions are used to make decisions based on data values within a SQL statement without resorting to a procedural language like PL/SQL. Table 9-1 shows the syntax and logic equivalent for each of the four functions.
|
Function syntax |
Logic equivalent |
|
DECODE(E1, E2, E3, E4) |
IF E1 = E2 THEN E3 ELSE E4 |
|
NULLIF(E1, E2) |
IF E1 = E2 THEN NULL ELSE E1 |
|
NVL(E1, E2) |
IF E1 IS NULL THEN E2 ELSE E1 |
|
NVL2(E1, E2, E3) |
IF E1 IS NULL THEN E3 ELSE E2 |
DECODE
The DECODE function can be thought of as an inline IF statement. DECODE takes three or more expressions as arguments. Each expression can be a column, a literal, a function, or even a subquery. Let’s look at a simple example using DECODE:
SELECT lname,DECODE(manager_emp_id, NULL, 'HEAD HONCHO', 'WORKER BEE') emp_typeFROM employee;LNAME EMP_TYPE -------------------- ----------- SMITH WORKER BEE ALLEN WORKER BEE WARD WORKER BEE JONES WORKER BEE MARTIN WORKER BEE BLAKE WORKER BEE CLARK WORKER BEE SCOTT WORKER BEE KING HEAD HONCHO TURNER WORKER BEE ADAMS WORKER BEE JAMES WORKER BEE FORD WORKER BEE MILLER WORKER BEE
In this example, the first expression is a column, the second is
NULL, and the third and fourth expressions are character literals.
The intent is to determine whether each employee has a manager by
checking whether an employee’s
manager_emp_id column is NULL. The DECODE function
in this example compares each row’s
manager_emp_id column (the first expression) to
NULL (the second expression). If the result of the comparison is
true, DECODE returns 'HEAD HONCHO' (the third
expression); otherwise, 'WORKER BEE' (the last
expression) is returned.
Since the DECODE function compares two expressions and returns one of two expressions to the caller, it is important that the expression types are identical or that they can at least be translated to be the same type. This example works because E1 can be compared to E2, and E3 and E4 have the same type. If this were not the case, Oracle would raise an exception, as illustrated by the following example:
SELECT lname,DECODE(manager_emp_id, SYSDATE, 'HEAD HONCHO', 'WORKER BEE') emp_typeFROM employee;ERROR at line 1: ORA-00932: inconsistent datatypes: expected DATE got NUMBER
Since the manager_emp_id column, which is numeric,
cannot be converted to a DATE type, the Oracle server cannot perform
the comparison and must throw an exception. The same exception would
be thrown if the two return expressions (E3 and E4) did not have
comparable types.
The previous example demonstrates the use of a DECODE function with the minimum number of parameters (four). The next example demonstrates how additional sets of parameters may be utilized for more complex logic:
SELECT p.part_nbr part_nbr, p.name part_name, s.name supplier,DECODE(p.status,'INSTOCK', 'In Stock','DISC', 'Discontinued','BACKORD', 'Backordered','ENROUTE', 'Arriving Shortly','UNAVAIL', 'No Shipment Scheduled','Unknown') part_statusFROM part p INNER JOIN supplier sON p.supplier_id = s.supplier_id;PART_NBR PART_NAME SUPPLIER PART_STATUS ---------------- ----------------------- ------------------- ---------- AI5-4557 Acme Part AI5-4557 Acme Industries In Stock TZ50828 Tilton Part TZ50828 Tilton Enterprises In Stock EI-T5-001 Eastern Part EI-T5-001 Eastern Importers In Stock
This example compares the value of a part’s
status column to each of five values, and, if a
match is found, returns the corresponding string. If a match is not
found, then the string 'Unknown' is returned.
Although the 12 parameters in this example are a great deal more than
the 4 parameters of the earlier example, we are still a long way from
the maximum allowable parameters, which is 255.
NULLIF
The NULLIF function compares two expressions and returns NULL if the expressions are equivalent, or the first expression otherwise. The equivalent logic using DECODE looks as follows:
DECODE(E1, E2, NULL, E1)
NULLIF is useful if you want to substitute NULL for a column’s value, as demonstrated by the next query, which shows salary information for only those employees making less than $2000:
SELECT fname, lname,NULLIF(salary, GREATEST(2000, salary)) salaryFROM employee;FNAME LNAME SALARY -------------------- -------------------- ---------- JOHN SMITH 800 KEVIN ALLEN 1600 CYNTHIA WARD 1250 TERRY JONES KENNETH MARTIN 1250 MARION BLAKE CAROL CLARK DONALD SCOTT FRANCIS KING MARY TURNER 1500 DIANE ADAMS 1100 FRED JAMES 950 JENNIFER FORD BARBARA MILLER 1300
In this example, the GREATEST function returns either the employee’s salary or 2000, whichever is greater. The NULLIF function compares this value to the employee’s salary and returns NULL if they are the same.
NVL and NVL2
The NVL and NVL2 functions allow you to test an expression to see whether it is NULL. If an expression is NULL, you can return an alternate, non-NULL value, to use in its place. Since any of the expressions in a DECODE statement can be NULL, the NVL and NVL2 functions are actually specialized versions of DECODE. The following example uses NVL2 to produce the same results as the DECODE example shown in a previous section:
SELECT lname,NVL2(manager_emp_id, 'WORKER BEE', 'HEAD HONCHO') emp_typeFROM employee;LNAME EMP_TYPE -------------------- ----------- SMITH WORKER BEE ALLEN WORKER BEE WARD WORKER BEE JONES WORKER BEE MARTIN WORKER BEE BLAKE WORKER BEE CLARK WORKER BEE SCOTT WORKER BEE KING HEAD HONCHO TURNER WORKER BEE ADAMS WORKER BEE JAMES WORKER BEE FORD WORKER BEE MILLER WORKER BEE
NVL2 looks at the first expression, manager_emp_id
in this case. If that expression evaluates to NULL, NVL2 returns the
third expression. If the first expression is not NULL, NVL2 returns
the second expression. Use NVL2 when you wish to specify alternate
values to be returned for the case when an expression is NULL, and
also for the case when an expression is not NULL.
The NVL function is most commonly used to substitute a default value
when a column is NULL. Otherwise, the column value itself is
returned. The next example shows the ID of each
employee’s manager, but substitutes the word
'NONE' when no manager has been assigned (i.e.,
when manager_emp_id is NULL):
SELECT emp.lname employee,NVL(mgr.lname, 'NONE') managerFROM employee emp LEFT OUTER JOIN employee mgrON emp.manager_emp_id = mgr.emp_id;EMPLOYEE MANAGER -------------------- -------------- FORD JONES SCOTT JONES JAMES BLAKE TURNER BLAKE MARTIN BLAKE WARD BLAKE ALLEN BLAKE MILLER CLARK ADAMS SCOTT CLARK KING BLAKE KING JONES KING SMITH FORD KING NONE
Even though DECODE may be substituted for any NVL or NVL2 function, most people prefer to use NVL or NVL2 when checking to see if an expresssion is NULL, presumably because the intent is clearer. Hopefully, the next section will convince you to use CASE expressions whenever you are in need of if-then-else functionality. Then you won’t need to worry about which built-in function to use.
The Case for CASE
The CASE expression made its SQL debut in the SQL-92 specification in 1992. Eight years later, Oracle included the CASE expression in the Oracle8i release. Like the DECODE function, the CASE expression enables conditional logic within a SQL statement, which might explain why Oracle took so much time implementing this particular feature. If you have been using Oracle for a number of years, you might wonder why you should care about the CASE expression, since DECODE does the job nicely. Here are several reasons why you should make the switch:
CASE expressions can be used everywhere that DECODE functions are permitted.
CASE expressions are more readable than DECODE expressions.
CASE expressions execute faster than DECODE expressions.[1]
CASE expressions handle complex logic more gracefully than DECODE expressions.
CASE is ANSI-compliant, whereas DECODE is proprietary.
The only downside to using CASE over DECODE is that CASE expressions are not supported in Oracle8i’s PL/SQL language. If you are using Oracle9i Database or Oracle Database 10g, however, any SQL statements executed from PL/SQL may include CASE expressions.
The SQL-92 specification defines two distinct flavors of the CASE expression: searched and simple. Searched CASE expressions are the only type supported in the Oracle8i release. If you are using a later release, you may also use simple CASE expressions.
Searched CASE Expressions
A searched CASE expression evaluates a number of conditions and returns a result determined by which condition is true. The syntax for the searched CASE expression is as follows:
CASE WHENC1THENR1WHENC2THENR2. . . WHENCNTHENRNELSE RD END
In the syntax definition, C1, C2 . . . Cn
represent conditions, and R1, R2 .
. . RN represent results. You can use up to 127 WHEN
clauses in each CASE expression, so the logic can be quite robust.
Conditions are evaluated in order. When a condition is found that
evaluates to TRUE, the corresponding result is returned, and
execution of the CASE logic ends. Therefore, carefully order WHEN
clauses to ensure that your desired results are achieved. The
following example illustrates the use of the CASE statement by
determining the proper string to show on an order status report:
SELECT co.order_nbr, co.cust_nbr,CASE WHEN co.expected_ship_dt IS NULL THEN 'NOT YET SCHEDULED'WHEN co.expected_ship_dt <= SYSDATE THEN 'SHIPPING DELAYED'WHEN co.expected_ship_dt <= SYSDATE + 2 THEN 'SHIPPING SOON'ELSE 'BACKORDERED'END ship_statusFROM cust_order coWHERE co.ship_dt IS NULL AND co.cancelled_dt IS NULL;ORDER_NBR CUST_NBR SHIP_STATUS ---------- ---------- ----------------- 1001 1 SHIPPING DELAYED 1003 4 SHIPPING DELAYED 1004 4 SHIPPING DELAYED 1005 8 SHIPPING DELAYED 1007 5 SHIPPING DELAYED 1008 5 SHIPPING DELAYED 1009 1 SHIPPING DELAYED 1012 1 SHIPPING DELAYED 1017 4 SHIPPING DELAYED 1019 4 SHIPPING DELAYED 1021 8 SHIPPING DELAYED 1025 5 SHIPPING DELAYED 1027 5 SHIPPING DELAYED 1029 1 SHIPPING DELAYED
Similar to DECODE, all results in a CASE expression must have comparable types; otherwise, ORA-00932 will be thrown. Each condition in each WHEN clause is independent of the others, however, so your conditions can include various data types, as demonstrated in the next example:
SELECT co.order_nbr, co.cust_nbr,CASEWHEN co.sale_price > 10000 THEN 'BIG ORDER'WHEN co.cust_nbr IN(SELECT cust_nbr FROM customer WHERE tot_orders > 100)THEN 'ORDER FROM FREQUENT CUSTOMER'WHEN co.order_dt < TRUNC(SYSDATE) -- 7 THEN 'OLD ORDER'ELSE 'UNINTERESTING ORDER'END order_typeFROM cust_order coWHERE co.ship_dt IS NULL AND co.cancelled_dt IS NULL;ORDER_NBR CUST_NBR ORDER_TYPE ---------- ---------- ------------ 1001 1 OLD ORDER 1003 4 OLD ORDER 1004 4 OLD ORDER 1005 8 OLD ORDER 1007 5 OLD ORDER 1008 5 OLD ORDER 1009 1 OLD ORDER 1012 1 OLD ORDER 1017 4 OLD ORDER 1019 4 OLD ORDER 1021 8 OLD ORDER 1025 5 OLD ORDER 1027 5 OLD ORDER 1029 1 OLD ORDER
Simple CASE Expressions
Simple CASE expressions are structured differently than searched CASE expressions in that the WHEN clauses contain expressions instead of conditions, and a single expression to be compared to the expressions in each WHEN clause is placed in the CASE clause. Here’s the syntax:
CASEE0WHENE1THENR1WHENE2THENR2. . . WHENENTHENRNELSE RD END
Each of the expressions E1...EN are compared to expression E0. If a
match is found, the corresponding result is returned; otherwise, the
default result (RD) is returned. All of
the expressions must be of the same type, since they all must be
compared to E0, making simple CASE
expressions less flexible than searched CASE expressions. The next
example illustrates the use of a simple CASE expression to translate
the status code stored in the part table:
SELECT p.part_nbr part_nbr, p.name part_name, s.name supplier,CASE p.statusWHEN 'INSTOCK' THEN 'In Stock'WHEN 'DISC' THEN 'Discontinued'WHEN 'BACKORD' THEN 'Backordered'WHEN 'ENROUTE' THEN 'Arriving Shortly'WHEN 'UNAVAIL' THEN 'No Shipment Scheduled'ELSE 'Unknown'END part_statusFROM part p INNER JOIN supplier sON p.supplier_id = s.supplier_id;PART_NBR PART_NAME SUPPLIER PART_STATUS ---------------- ----------------------- ------------------- ------------ AI5-4557 Acme Part AI5-4557 Acme Industries In Stock TZ50828 Tilton Part TZ50828 Tilton Enterprises In Stock EI-T5-001 Eastern Part EI-T5-001 Eastern Importers In Stock
A searched CASE can do everything that a simple CASE can do, which is probably the reason Oracle only implemented searched CASE expressions the first time around. For certain uses, such as translating values for a column, a simple expression may prove more efficient if the expression being evaluated is computed via a function call.
DECODE and CASE Examples
The following sections present a variety of examples illustrating the uses of conditional logic in SQL statements. Although we recommend that you use the CASE expression rather than the DECODE function, where feasible we provide both DECODE and CASE versions of each example to help illustrate the differences between the two approaches.
Result Set Transformations
You may have run into a situation where you are performing aggregations over a finite set of values, such as days of the week or months of the year, but you want the result set to contain one row with N columns rather than N rows with two columns. Consider the following query, which aggregates sales data for each day of the week:
SELECT TO_CHAR(order_dt, 'DAY') day_of_week,SUM(sale_price) tot_salesFROM cust_orderWHERE sale_price IS NOT NULLGROUP BY TO_CHAR(order_dt, 'DAY')ORDER BY 2 DESC;DAY_OF_WEEK TOT_SALES ------------ ---------- SUNDAY 396 WEDNESDAY 180 MONDAY 112 FRIDAY 50 SATURDAY 50
In order to transform this result set into a single row with seven columns (one for each day in the week), you will need to fabricate a column for each day of the week and, within each column, sum only those records whose order date falls in the desired day. You can do that with DECODE:
SELECTSUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'SUNDAY ', sale_price, 0)) SUN,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'MONDAY ', sale_price, 0)) MON,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'TUESDAY ', sale_price, 0)) TUE,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'WEDNESDAY', sale_price, 0)) WED,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'THURSDAY ', sale_price, 0)) THU,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'FRIDAY ', sale_price, 0)) FRI,SUM(DECODE(TO_CHAR (order_dt, 'DAY'), 'SATURDAY ', sale_price, 0)) SATFROM cust_orderWHERE sale_price IS NOT NULL;SUN MON TUE WED THU FRI SAT --------- --------- --------- --------- --------- --------- --------- 396 112 0 180 0 50 50
Each of the seven columns in the previous query are identical, except
for the day being checked by the DECODE function. For the
SUN column, for example, a value of 0 is returned
unless an order was booked on a Sunday, in which case the
sale_price column is returned. When the values
from all orders are summed, only Sunday orders are added to the
total, which has the effect of summing all Sunday orders while
ignoring orders for all other days of the week. The same logic is
used for Monday, Tuesday, etc., to sum orders for each of the other
days.
The CASE version of this query is as follows:
SELECTSUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'SUNDAY 'THEN sale_price ELSE 0 END) SUN,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'MONDAY 'THEN sale_price ELSE 0 END) MON,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'TUESDAY 'THEN sale_price ELSE 0 END) TUE,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'WEDNESDAY'THEN sale_price ELSE 0 END) WED,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'THURSDAY 'THEN sale_price ELSE 0 END) THU,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'FRIDAY 'THEN sale_price ELSE 0 END) FRI,SUM(CASE WHEN TO_CHAR(order_dt, 'DAY') = 'SATURDAY 'THEN sale_price ELSE 0 END) SATFROM cust_orderWHERE sale_price IS NOT NULL;SUN MON TUE WED THU FRI SAT --------- --------- --------- --------- --------- --------- --------- 396 112 0 180 0 50 50
Obviously, such transformations are only practical when the number of values is relatively small. Aggregating sales for each weekday or month works fine, but expanding the query to aggregate sales for each week, with a column for each week, would quickly become tedious.
Selective Function Execution
Imagine you’re
generating an inventory report.
Most of the information resides in your local database, but a trip
across a gateway to an external, non-Oracle database is required to
gather information for parts supplied by Acme Industries. The round
trip from your database through the gateway to the external server
and back takes 1.5 seconds on average. There are 10,000 parts in your
database, but only 100 require information via the gateway. You
create a user-defined function called
get_resupply_date to retrieve the resupply date
for parts supplied by ACME, and include it in your query:
SELECT s.name supplier_name, p.name part_name, p.part_nbr part_number p.inventory_qty in_stock, p.resupply_date resupply_date, my_pkg.get_resupply_date(p.part_nbr) acme_resupply_date FROM part p INNER JOIN supplier s ON p.supplier_id = s.supplier_id;
You then include logic in your reporting tool to use the
acme_resupply_date instead of the
resupply_date column if the
supplier’s name is Acme Industries. You kick off the
report, sit back, and wait for the results. And wait. And wait...
Unfortunately, the server is forced to make 10,000 trips across the gateway when only 100 are required. In these types of situations, it is far more efficient to call the function only when necessary, instead of always calling the function and discarding the results when not needed:
SELECT s.name supplier_name, p.name part_name, p.part_nbr part_number,
p.inventory_qty in_stock,
DECODE(s.name, 'Acme Industries',
my_pkg.get_resupply_date(p.part_nbr),
p.resupply_date) resupply_date
FROM part p INNER JOIN supplier s
ON p.supplier_id = s.supplier_id;The DECODE function checks if the supplier name is 'Acme
Industries‘. If so, it calls the function to retrieve the
resupply date via the gateway; otherwise, it returns the resupply
date from the local part table. The CASE
version of this query looks as
follows:
SELECT s.name supplier_name, p.name part_name, p.part_nbr part_number,
p.inventory_qty in_stock,
CASE WHEN s.name = 'Acme Industries'
THEN my_pkg.get_resupply_date(p.part_nbr)
ELSE p.resupply_date
END resupply_date
FROM part p INNER JOIN supplier s
ON p.supplier_id = s.supplier_id;Now the user-defined function is only executed if the supplier is Acme, reducing the query’s execution time drastically. For more information on calling user-defined functions from SQL, see Chapter 11.
Conditional Update
If your database
design includes
denormalizations, you may run nightly
routines to populate the denormalized columns. For example, the
part table contains the denormalized column
status, the value for which is derived from the
inventory_qty and resupply_date
columns. To update the status column, you could
run four separate UPDATE statements each night, one for each of the
four possible values for the status column. For example:
UPDATE part SET status = 'INSTOCK' WHERE inventory_qty > 0; UPDATE part SET status = 'ENROUTE' WHERE inventory_qty = 0 AND resupply_date < SYSDATE + 5; UPDATE part SET status = 'BACKORD' WHERE inventory_qty = 0 AND resupply_date > SYSDATE + 5; UPDATE part SET status = 'UNAVAIL' WHERE inventory_qty = 0 and resupply_date IS NULL;
Given that columns such as inventory_qty and
resupply_date are unlikely to be indexed, each of
the four UPDATE statements would require a full table-scan of the
part table. By adding conditional expressions to
the statement, however, the four UPDATE statements can be combined,
resulting in a single scan of the part table:
UPDATE part SET status =
DECODE(inventory_qty, 0,
DECODE(resupply_date, NULL, 'UNAVAIL',
DECODE(LEAST(resupply_date, SYSDATE + 5), resupply_date,
'ENROUTE', 'BACKORD')),
'INSTOCK'),The CASE version of this UPDATE is as follows:
UPDATE part SET status =
CASE WHEN inventory_qty > 0 THEN 'INSTOCK'
WHEN resupply_date IS NULL THEN 'UNAVAIL'
WHEN resupply_date < SYSDATE + 5 THEN 'ENROUTE'
WHEN resupply_date > SYSDATE + 5 THEN 'BACKORD'
ELSE 'UNKNOWN' END;The readability advantage of the CASE expression is especially apparent here, since the DECODE version requires three nested levels to implement the same conditional logic handled by a single CASE expression.
Optional Update
In some situations, you may need to modify data only if certain conditions exist. For example, you have a table that records information such as the total number of orders and the largest order booked during the current month. Here’s the table definition:[2]
describe mtd_orders;
Name Null? Type
----------------------------------------- -------- ------------
TOT_ORDERS NOT NULL NUMBER(7)
TOT_SALE_PRICE NOT NULL NUMBER(11,2)
MAX_SALE_PRICE NOT NULL NUMBER(9,2)
EUROPE_TOT_ORDERS NOT NULL NUMBER(7)
EUROPE_TOT_SALE_PRICE NOT NULL NUMBER(11,2)
EUROPE_MAX_SALE_PRICE NOT NULL NUMBER(9,2)
NORTHAMERICA_TOT_ORDERS NOT NULL NUMBER(7)
NORTHAMERICA_TOT_SALE_PRICE NOT NULL NUMBER(11,2)
NORTHAMERICA_MAX_SALE_PRICE NOT NULL NUMBER(9,2)Each night, the table is updated with that day’s
order information. While most of the columns will be modified each
night, the column for the largest order, which is called
max_sale_price, will only change if one of the
day’s orders exceeds the current value of the
column. The following PL/SQL block shows how this might be
accomplished using a procedural language:
DECLARE
tot_ord NUMBER;
tot_price NUMBER;
max_price NUMBER;
prev_max_price NUMBER;
BEGIN
SELECT COUNT(*), SUM(sale_price), MAX(sale_price)
INTO tot_ord, tot_price, max_price
FROM cust_order
WHERE cancelled_dt IS NULL
AND order_dt >= TRUNC(SYSDATE);
UPDATE mtd_orders
SET tot_orders = tot_orders + tot_ord,
tot_sale_price = tot_sale_price + tot_price
RETURNING max_sale_price INTO prev_max_price;
IF max_price > prev_max_price THEN
UPDATE mtd_orders
SET max_sale_price = max_price;
END IF;
END;After calculating the total number of orders, the aggregate order
price, and the maximum order price for the current day, the
tot_orders and tot_sale_price
columns of the mtd_orders table are modified with
today’s sales data. After the update is complete,
the maximum sale price is returned from mtd_orders
so that it can be compared with today’s maximum sale
price. If today’s max_sale_price
exceeds that stored in the mtd_orders table, a
second UPDATE statement is executed to update the field.
Using DECODE or CASE, however, you can update the
tot_orders and tot_sale_price
columns and optionally update the
max_sale_price column in the same UPDATE
statement. Additionally, since you now have a single UPDATE
statement, you can aggregate the data from the
cust_order table within a subquery and eliminate
the need for PL/SQL:
UPDATE mtd_orders mtdo
SET (mtdo.tot_orders, mtdo.tot_sale_price, mtdo.max_sale_price) =
(SELECT mtdo.tot_orders + day_tot.tot_orders,
mtdo.tot_sale_price + NVL(day_tot.tot_sale_price, 0),
DECODE(GREATEST(mtdo.max_sale_price,
NVL(day_tot.max_sale_price, 0)), mtdo.max_sale_price,
mtdo.max_sale_price, day_tot.max_sale_price)
FROM
(SELECT COUNT(*) tot_orders, SUM(sale_price) tot_sale_price,
MAX(sale_price) max_sale_price
FROM cust_order
WHERE cancelled_dt IS NULL
AND order_dt >= TRUNC(SYSDATE)) day_tot);In this statement, the max_sale_price column is
set equal to itself unless the value returned from the subquery is
greater than the current column value, in which case the column is
set to the value returned from the subquery. The next statement uses
CASE to perform the same optional update:
UPDATE mtd_orders mtdo
SET (mtdo.tot_orders, mtdo.tot_sale_price, mtdo.max_sale_price) =
(SELECT mtdo.tot_orders + day_tot.tot_orders,
mtdo.tot_sale_price + day_tot.tot_sale_price,
CASE WHEN day_tot.max_sale_price > mtdo.max_sale_price
THEN day_tot.max_sale_price
ELSE mtdo.max_sale_price END
FROM
(SELECT COUNT(*) tot_orders, SUM(sale_price) tot_sale_price,
MAX(sale_price) max_sale_price
FROM cust_order
WHERE cancelled_dt IS NULL
AND order_dt >= TRUNC(SYSDATE)) day_tot);One thing to keep in mind when using this approach is that setting a
value equal to itself is still seen as a modification by the database
and may trigger an audit record, a new value for the
last_modified_date column, etc.
Selective Aggregation
To expand on
the mtd_orders
example in the previous section,
imagine that you also want to store total sales for particular
regions such as Europe and North America. For the additional six
columns, individual orders will affect one set of columns or the
other, but not both. An order will either be for a European or North
American customer, but not for both at the same time. To populate
these columns, you could generate two more update statements, each
targeted to a particular region, as in:
/* Europe buckets */
UPDATE mtd_orders mtdo
SET (mtdo.europe_tot_orders, mtdo.europe_tot_sale_price,
mtdo.europe_max_sale_price) =
(SELECT mtdo.europe_tot_orders + eur_day_tot.tot_orders,
mtdo.europe_tot_sale_price + nvl(eur_day_tot.tot_sale_price, 0),
CASE WHEN eur_day_tot.max_sale_price > mtdo.europe_max_sale_price
THEN eur_day_tot.max_sale_price
ELSE mtdo.europe_max_sale_price END
FROM
(SELECT COUNT(*) tot_orders, SUM(co.sale_price) tot_sale_price,
MAX(co.sale_price) max_sale_price
FROM cust_order co INNER JOIN customer c
ON co.cust_nbr = c.cust_nbr
WHERE co.cancelled_dt IS NULL
AND co.order_dt >= TRUNC(SYSDATE)
AND c.region_id IN
(SELECT region_id FROM region
START WITH name = 'Europe'
CONNECT BY PRIOR region_id = super_region_id)) eur_day_tot);
/* North America buckets */
UPDATE mtd_orders mtdo
SET (mtdo.northamerica_tot_orders, mtdo.northamerica_tot_sale_price,
mtdo.northamerica_max_sale_price) =
(SELECT mtdo.northamerica_tot_orders + na_day_tot.tot_orders,
mtdo.northamerica_tot_sale_price + nvl(na_day_tot.tot_sale_price, 0),
CASE WHEN na_day_tot.max_sale_price > mtdo.northamerica_max_sale_price
THEN na_day_tot.max_sale_price
ELSE mtdo.northamerica_max_sale_price END
FROM
(SELECT COUNT(*) tot_orders, SUM(co.sale_price) tot_sale_price,
MAX(co.sale_price) max_sale_price
FROM cust_order co INNER JOIN customer c
ON co.cust_nbr = c.cust_nbr
WHERE co.cancelled_dt IS NULL
AND co.order_dt >= TRUNC(SYSDATE) - 60
AND c.region_id IN
(SELECT region_id FROM region
START WITH name = 'North America'
CONNECT BY PRIOR region_id = super_region_id)) na_day_tot);However, why not save yourself a trip through the
cust_order table and aggregate the North American
and European totals at the same time? The trick here is to put
conditional logic within the aggregation functions so that only the
appropriate rows influence each calculation. This approach is similar
to the example from Section 9.3.1. in that it selectively
aggregates data based on data stored in the table:
UPDATE mtd_orders mtdo
SET (mtdo.northamerica_tot_orders, mtdo.northamerica_tot_sale_price,
mtdo.northamerica_max_sale_price, mtdo.europe_tot_orders,
mtdo.europe_tot_sale_price, mtdo.europe_max_sale_price) =
(SELECT mtdo.northamerica_tot_orders + nvl(day_tot.na_tot_orders, 0),
mtdo.northamerica_tot_sale_price + nvl(day_tot.na_tot_sale_price, 0),
CASE WHEN day_tot.na_max_sale_price > mtdo.northamerica_max_sale_price
THEN day_tot.na_max_sale_price
ELSE mtdo.northamerica_max_sale_price END,
mtdo.europe_tot_orders + nvl(day_tot.eur_tot_orders, 0),
mtdo.europe_tot_sale_price + nvl(day_tot.eur_tot_sale_price, 0),
CASE WHEN day_tot.eur_max_sale_price > mtdo.europe_max_sale_price
THEN day_tot.eur_max_sale_price
ELSE mtdo.europe_max_sale_price END
FROM
(SELECT SUM(CASE WHEN na_regions.region_id IS NOT NULL THEN 1
ELSE 0 END) na_tot_orders,
SUM(CASE WHEN na_regions.region_id IS NOT NULL THEN co.sale_price
ELSE 0 END) na_tot_sale_price,
MAX(CASE WHEN na_regions.region_id IS NOT NULL THEN co.sale_price
ELSE 0 END) na_max_sale_price,
SUM(CASE WHEN eur_regions.region_id IS NOT NULL THEN 1
ELSE 0 END) eur_tot_orders,
SUM(CASE WHEN eur_regions.region_id IS NOT NULL THEN co.sale_price
ELSE 0 END) eur_tot_sale_price,
MAX(CASE WHEN eur_regions.region_id IS NOT NULL THEN co.sale_price
ELSE 0 END) eur_max_sale_price
FROM cust_order co INNER JOIN customer c
ON co.cust_nbr = c.cust_nbr
LEFT OUTER JOIN (SELECT region_id FROM region
START WITH name = 'North America'
CONNECT BY PRIOR region_id = super_region_id) na_regions
ON c.region_id = na_regions.region_id
LEFT OUTER JOIN (SELECT region_id FROM region
START WITH name = 'Europe'
CONNECT BY PRIOR region_id = super_region_id) eur_regions
ON c.region_id = eur_regions.region_id
WHERE co.cancelled_dt IS NULL
AND co.order_dt >= TRUNC(SYSDATE)) day_tot);This is a fairly robust statement, so let’s break it
down. Within the day_tot
inline view, you are joining the
cust_order table to the
customer table, and then outer-joining from
customer.region_id to each of two inline views
(na_regions and eur_regions)
that perform hierarchical queries on the region
table. Thus, orders from European customers will have a non-null
value for eur_regions.region_id, since the outer
join would find a matching row in the eur_regions
inline view. Six aggregations are performed on this result set; three
check for a join against the na_regions inline
view (North American orders), and three check for a join against the
eur_regions inline view (European orders). The six
aggregations are then used to modify the six columns in
mtd_orders.
This statement could (and should) be combined with the statement from
the previous example (which updated the first three columns) to
create an UPDATE statement that touches every column in the
mtd_orders table via one pass through the
cust_order table. For data warehouse applications,
where large data sets must be manipulated each night within tight
time constraints, such an approach can often make the difference
between success
and
failure.
Checking for Existence
When evaluating
optional
one-to-many relationships, there are certain cases where you want to
know whether the relationship is zero or greater than zero without
regard for the actual data. For example, you want to write a report
showing each customer along with a flag showing whether the customer
has had any orders in the past five years. Using conditional logic,
you can include a correlated subquery on the
cust_order table, check to see if the number of
orders exceeds zero, and then assign either a 'Y'
or a 'N' to the column:
SELECT c.cust_nbr cust_nbr, c.name name,DECODE(0, (SELECT COUNT(*) FROM cust_order coWHERE co.cust_nbr = c.cust_nbr AND co.cancelled_dt IS NULLAND co.order_dt > TRUNC(SYSDATE) - (5 * 365)),'N', 'Y') has_recent_ordersFROM customer c;CUST_NBR NAME H ---------- ------------------------------ - 1 Cooper Industries Y 2 Emblazon Corp. N 3 Ditech Corp. N 4 Flowtech Inc. Y 5 Gentech Industries Y 6 Spartan Industries N 7 Wallace Labs N 8 Zantech Inc. Y 9 Cardinal Technologies N 10 Flowrite Corp. N 11 Glaven Technologies N 12 Johnson Labs N 13 Kimball Corp. N 14 Madden Industries N 15 Turntech Inc. N 16 Paulson Labs N 17 Evans Supply Corp. N 18 Spalding Medical Inc. N 19 Kendall-Taylor Corp. N 20 Malden Labs N 21 Crimson Medical Inc. N 22 Nichols Industries N 23 Owens-Baxter Corp. N 24 Jackson Medical Inc. N 25 Worcester Technologies N 26 Alpha Technologies Y 27 Phillips Labs N 28 Jaztech Corp. N 29 Madden-Taylor Inc. N 30 Wallace Industries N
Here is the CASE version of the query:
SELECT c.cust_nbr cust_nbr, c.name name,
CASE WHEN EXISTS (SELECT 1 FROM cust_order co
WHERE co.cust_nbr = c.cust_nbr AND co.cancelled_dt IS NULL
AND co.order_dt > TRUNC(SYSDATE) - (5 * 365))
THEN 'Y' ELSE 'N' END has_recent_orders
FROM customer c;Division by Zero Errors
As a general rule, you should write your code so that unexpected data values are handled gracefully. One of the more common arithmetic errors is ORA-01476: divisor is equal to zero. Whether the value is retrieved from a column, passed in via a bind variable, or returned by a function call, always wrap divisors with DECODE or CASE, as illustrated by the following example:
SELECT p.part_nbr, SYSDATE + (p.inventory_qty /
DECODE(my_pkg.get_daily_part_usage(p.part_nbr), NULL, 1,
0, 1, my_pkg.get_daily_part_usage(p.part_nbr))) anticipated_shortage_dt
FROM part p
WHERE p.inventory_qty > 0;The DECODE function ensures that the divisor is something other than zero. Here is the CASE version of the statement:
SELECT p.part_nbr, SYSDATE + (p.inventory_qty /
CASE WHEN my_pkg.get_daily_part_usage(p.part_nbr) > 0
THEN my_pkg.get_daily_part_usage(p.part_nbr)
ELSE 1 END) anticipated_shortage_dt
FROM part p
WHERE p.inventory_qty > 0;Of course, if you are bothered by the fact that the
get_daily_part_usage function is called a second
time for each part that yields a positive response, simply wrap the
function call in an inline view, as in:
SELECT parts.part_nbr, SYSDATE + (parts.inventory_qty /
CASE WHEN parts.daily_part_usage > 0
THEN parts.daily_part_usage
ELSE 1 END) anticipated_shortage_dt
FROM
(SELECT p.part_nbr part_nbr, p.inventory_qty inventory_qty,
my_pkg.get_daily_part_usage(p.part_nbr) daily_part_usage
FROM part p
WHERE p.inventory_qty > 0) parts;State Transitions
In certain cases, the order in which the values may be changed is constrained as well as the allowable values for a column. Consider the diagram shown in Figure 9-1, which shows the allowable state transitions for an order.
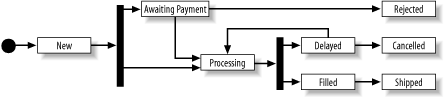
As you can see, an order currently in the Processing state should only be allowed to move to either Delayed or Filled. Rather than allowing each application to implement logic to change the state of an order, write a user-defined function that returns the appropriate state depending on the current state of the order and the transition type. In this example, two transition types are defined: positive (POS) and negative (NEG). For example, an order in the Delayed state can make a positive transition to Processing or a negative transition to Cancelled. If an order is in one of the final states (Rejected, Cancelled, Shipped), the same state is returned. Here is the DECODE version of the PL/SQL function:
FUNCTION get_next_order_state(ord_nbr in NUMBER,
trans_type in VARCHAR2 DEFAULT 'POS')
RETURN VARCHAR2 is
next_state VARCHAR2(20) := 'UNKNOWN';
BEGIN
SELECT DECODE(status,
'REJECTED', status,
'CANCELLED', status,
'SHIPPED', status,
'NEW', DECODE(trans_type, 'NEG', 'AWAIT_PAYMENT', 'PROCESSING'),
'AWAIT_PAYMENT', DECODE(trans_type, 'NEG', 'REJECTED', 'PROCESSING'),
'PROCESSING', DECODE(trans_type, 'NEG', 'DELAYED', 'FILLED'),
'DELAYED', DECODE(trans_type, 'NEG', 'CANCELLED', 'PROCESSING'),
'FILLED', DECODE(trans_type, 'POS', 'SHIPPED', 'UNKNOWN'),
'UNKNOWN')
INTO next_state
FROM cust_order
WHERE order_nbr = ord_nbr;
RETURN next_state;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RETURN next_state;
END get_next_order_state;As of Oracle8i, the PL/SQL language does not include the CASE expression in its grammar, so you would need to be running Oracle9i or later to use the CASE version of the function:
FUNCTION get_next_order_state(ord_nbr in NUMBER,
trans_type in VARCHAR2 DEFAULT 'POS')
RETURN VARCHAR2 is
next_state VARCHAR2(20) := 'UNKNOWN';
BEGIN
SELECT CASE
WHEN status = 'REJECTED' THEN status
WHEN status = 'CANCELLED' THEN status
WHEN status = 'SHIPPED' THEN status
WHEN status = 'NEW' AND trans_type = 'NEG' THEN 'AWAIT_PAYMENT'
WHEN status = 'NEW' AND trans_type = 'POS' THEN 'PROCESSING'
WHEN status = 'AWAIT_PAYMENT' AND trans_type = 'NEG' THEN 'REJECTED'
WHEN status = 'AWAIT_PAYMENT' AND trans_type = 'POS' THEN 'PROCESSING'
WHEN status = 'PROCESSING' AND trans_type = 'NEG' THEN 'DELAYED'
WHEN status = 'PROCESSING' AND trans_type = 'POS' THEN 'FILLED'
WHEN status = 'DELAYED' AND trans_type = 'NEG' THEN 'CANCELLED'
WHEN status = 'DELAYED' AND trans_type = 'POS' THEN 'PROCESSING'
WHEN status = 'FILLED' AND trans_type = 'POS' THEN 'SHIPPED'
ELSE 'UNKNOWN'
END
INTO next_state
FROM cust_order
WHERE order_nbr = ord_nbr;
RETURN next_state;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RETURN next_state;
END get_next_order_state;This example handles only the simple case in which there are just two paths out of each state, but it does demonstrate one strategy for managing state transitions in your database. To demonstrate how the previous function could be used, here is the UPDATE statement used to change the status of an order once it has made a successful state transition:
UPDATE cust_order SET status = my_pkg.get_next_order_state(order_nbr, 'POS') WHERE order_nbr = 1107;
[1] Since CASE is built into Oracle’s SQL grammar, there is no need to call a function in order to evaluate the if-then-else logic. Although the difference in execution time is miniscule for a single call, the aggregate time savings from not calling a function should become noticeable when working with large result sets.
[2] For this example, we will ignore the European and North American totals.