
One of the modules available in Python to extract data from PDF documents is PyPDF2. The module can be downloaded directly with the pip install utility since it is located in the official Python repository .
In the https://pypi.org/project/PyPDF2/ URL, we can see the last version of this module:

This module offers us the ability to extract document information, and encrypt and decrypt documents. To extract metadata, we can use the PdfFileReader class and the getDocumentInfo() method, which returns a dictionary with the data of the document:

The following function would allow us to obtain the information of all the PDF documents that are in the "pdf" folder.
You can find the following code in the extractDataFromPDF.py file in the pypdf folder:
#!usr/bin/env python
# coding: utf-8
from PyPDF2 import PdfFileReader, PdfFileWriter
import os, time, os.path, stat
from PyPDF2.generic import NameObject, createStringObject
class bcolors:
OKGREEN = '�33[92m'
ENDC = '�33[0m'
BOLD = '�33[1m'
def get_metadata():
for dirpath, dirnames, files in os.walk("pdf"):
for data in files:
ext = data.lower().rsplit('.', 1)[-1]
if ext in ['pdf']:
print(bcolors.OKGREEN + "------------------------------------------------------------------------------------")
print(bcolors.OKGREEN + "[--- Metadata : " + bcolors.ENDC + bcolors.BOLD + "%s " %(dirpath+os.path.sep+data) + bcolors.ENDC)
print(bcolors.OKGREEN + "------------------------------------------------------------------------------------")
pdf = PdfFileReader(open(dirpath+os.path.sep+data, 'rb'))
info = pdf.getDocumentInfo()
for metaItem in info:
print (bcolors.OKGREEN + '[+] ' + metaItem.strip( '/' ) + ': ' + bcolors.ENDC + info[metaItem])
pages = pdf.getNumPages()
print (bcolors.OKGREEN + '[+] Pages:' + bcolors.ENDC, pages)
layout = pdf.getPageLayout()
print (bcolors.OKGREEN + '[+] Layout: ' + bcolors.ENDC + str(layout))
In this part of code, we use the getXmpMetadata() method to obtain other information related to the document, such as the contributors, publisher, and pdf version:
xmpinfo = pdf.getXmpMetadata()
if hasattr(xmpinfo,'dc_contributor'): print (bcolors.OKGREEN + '[+] Contributor:' + bcolors.ENDC, xmpinfo.dc_contributor)
if hasattr(xmpinfo,'dc_identifier'): print (bcolors.OKGREEN + '[+] Identifier:' + bcolors.ENDC, xmpinfo.dc_identifier)
if hasattr(xmpinfo,'dc_date'): print (bcolors.OKGREEN + '[+] Date:' + bcolors.ENDC, xmpinfo.dc_date)
if hasattr(xmpinfo,'dc_source'): print (bcolors.OKGREEN + '[+] Source:' + bcolors.ENDC, xmpinfo.dc_source)
if hasattr(xmpinfo,'dc_subject'): print (bcolors.OKGREEN + '[+] Subject:' + bcolors.ENDC, xmpinfo.dc_subject)
if hasattr(xmpinfo,'xmp_modifyDate'): print (bcolors.OKGREEN + '[+] ModifyDate:' + bcolors.ENDC, xmpinfo.xmp_modifyDate)
if hasattr(xmpinfo,'xmp_metadataDate'): print (bcolors.OKGREEN + '[+] MetadataDate:' + bcolors.ENDC, xmpinfo.xmp_metadataDate)
if hasattr(xmpinfo,'xmpmm_documentId'): print (bcolors.OKGREEN + '[+] DocumentId:' + bcolors.ENDC, xmpinfo.xmpmm_documentId)
if hasattr(xmpinfo,'xmpmm_instanceId'): print (bcolors.OKGREEN + '[+] InstanceId:' + bcolors.ENDC, xmpinfo.xmpmm_instanceId)
if hasattr(xmpinfo,'pdf_keywords'): print (bcolors.OKGREEN + '[+] PDF-Keywords:' + bcolors.ENDC, xmpinfo.pdf_keywords)
if hasattr(xmpinfo,'pdf_pdfversion'): print (bcolors.OKGREEN + '[+] PDF-Version:' + bcolors.ENDC, xmpinfo.pdf_pdfversion)
if hasattr(xmpinfo,'dc_publisher'):
for y in xmpinfo.dc_publisher:
if y:
print (bcolors.OKGREEN + "[+] Publisher: " + bcolors.ENDC + y)
fsize = os.stat((dirpath+os.path.sep+data))
print (bcolors.OKGREEN + '[+] Size:' + bcolors.ENDC, fsize[6], 'bytes ')
get_metadata()
The "walk" function within the os (operating system) module is useful for navigating all the files and directories that are included in a specific directory.
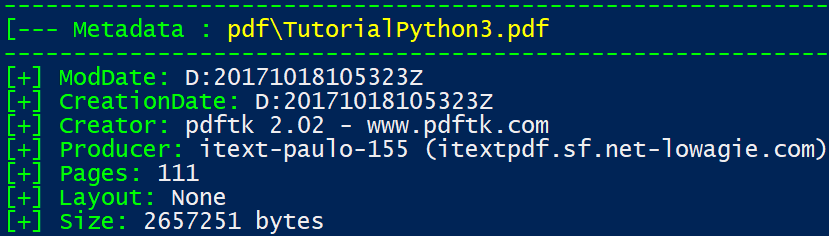
In this screenshot, we can see the output of the previous script that is reading a file inside the pdf folder:
Another feature it offers is the ability to decode a document that is encrypted with a password:
