
17
Artificial Intelligence and Autonomous Car
Merve Arıtürk1,2, Sırma Yavuz1, and Tofigh Allahviranloo2
1Faculty of Electrical and Electronics, Department of Computer Engineering, Yıldız Technical University, Istanbul, Turkey
2Faculty of Engineering and Natural Sciences, Bahcesehir University, Istanbul, Turkey
17.1 Introduction
With the advancement of technology, the use of computers and smart devices is increasing day by day. Increased usage and desire trigger the next step by making life easier. At this point, artificial intelligence, which aims to solve problems and eliminate requests, comes into play. In this section, first of all, artificial intelligence is explained and general usage areas are explained with examples. The objectives and levels of natural language processing (NLP), which is one of the subfields of artificial intelligence, are mentioned. The classification of robots is given in detail by making the most important definitions about the very popular robotic field that attracts everyone's attention. Image preprocessing, image enhancement, image separation, feature extraction, and image classification techniques are explained by explaining the logic of image processing, which is one of the most important subfields of artificial intelligence. Problem solving, which is the basic task of artificial intelligence, is explained in detail. Optimization related to problem solving is defined and applications related to this field are given with examples. Finally, today's technology and autonomous systems that we will be more closely integrated in the future are explained in detail.
17.2 What Is Artificial Intelligence?
Artificial intelligence is a field that provides the most accurate solutions for any problem by combining with the computer commands or software of the human mind. It aims not only to solve problems in computer science but also to solve problems in other sciences. Figure 17.1 shows the areas where artificial intelligence is used.
Figure 17.1 General usage of artificial intelligence.
In essence, artificial intelligence means solving problems. There are many subfields of artificial intelligence that allow machines to think and work like humans: NLP, robotics, image processing, machine learning, problem solving, optimization, autonomous systems, etc. Let us examine the subfields of artificial intelligence in more detail.
17.3 Natural Language Processing
NLP is the science and engineering branch that deals with the design and realization of computer systems whose main function is to analyze, understand, interpret, and produce a natural language. NLP is a subcategory of artificial intelligence and linguistics, which examines the processing of texts, words, syllables, and sounds in the computer language, aiming at the processing and use of natural languages.
NLP combines theories, methods, and technologies developed in a wide range of fields such as artificial intelligence (knowledge representation, planning, reasoning, etc.), formal language theory (language analysis), theoretical linguistics, and cognitive psychology. This subject, which is seen as a small subfield of artificial intelligence in the 1950s and 1960s, is now recognized as a fundamental discipline of computer science after achieving the achievements of researchers and practices.
NLP is one of the candidate technologies to bring fundamental changes in people's interaction with computers in the years to come. Because of the fact that NLP is based on cheap computing power, the emergence of powerful computers for the NLP applications, which are very expensive compared to the expected result, has made major changes.
The main objectives in research in the field of NLP have generally been the following:
- – Better understand the function and structure of natural languages
- – Use natural language as an interface between computers and people and thus facilitate communication between people and the computer
- – Language translation with computer
NLP systems are examined at five main levels. These levels are as follows:
- Phonology: Phonology examines the sounds of letters and how they are used in the language. All languages have an alphabet. The sound of each letter is different from the others, and these units are called phonemes. The main problem in phonology is that the phonemes are discrete, although the sound waves are continuous. To understand speech, a continuous‐flowing speech should be divided into discrete sounds. Then, sounds and phonemes should be classified. This complex problem is handled within the scope of pattern recognition.
- Morphology: Morphology is the science that deals with word formation. At this stage, the main aim is to correctly identify and classify the root and the suffixes of the word. In a word, the order and structure of the inserts, the construction, and shooting of the process such as the determination of attachments are made at this level.
- Syntax: Syntaxology examines how words should be sorted in order to create a sentence. It defines the structural tasks of words in sentences, phrases, and subphrases that make up them. Combining words and creating sentences or parsing of a sentence is performed at this stage.
- Semantics: Semantics is the level in which language communicates with the real world. It examines the meanings of words and how they come together to form the meaning of the sentence.
- Pragmatics: Pragmatics examines situations in which sentences are used in a different sense from the normal meaning of sentences. For example, the phrase “can you open the window” is not a question. It is considered by some as a subset of semantics.
17.4 Robotics
Reprogrammable mechanical components are called robots. The concept of robotics defines the working area of mechanical engineering, computer engineering, electrical engineering, and control engineering. With the development of microchip technology over time, the concept of robotics has become widespread [1].
Applications of robot technology are listed below.
- Mechanical production: Parts selection, sorting, and placement;
- In the assembly of parts;
- Tooling and workpiece attachment, disassembly, and replacement;
- Deburring and polishing;
- Loading and unloading of hot parts (such as forged casting) to the counter (heat treatment);
- Measurement and control of finished parts; and
- Used for loading, transfer, and packaging of parts, machine tools, plastic parts manufacturing, presses, die casting, precision casting, forging, filling, and unloading of furnaces in storage processes.
If we classify the robot technology, we can collect it under two main classes.
17.4.1 Classification by Axes
The capacity of a robot movement is determined by the movements in the axes that are possible to be controlled. It is very similar to movements in numerical control. Industrial robots are made in different types and sizes. They can make various arm movements and have different motion systems.
17.4.1.1 Axis Concept in Robot Manipulators
If a manipulator is turning from a single joint around its axis or doing one of its forward/backward linear movements, this robot (1 degree of freedom) is called a uniaxial robot. If the manipulator has two connection points and each of these nodes has linear or rotational movements, this robot (2 degrees of freedom) is called a biaxial robot. If the manipulator has three connection points and each of these nodes has linear or rotational motions, this robot (3 degrees of freedom) is called a three‐axis robot. Industrial robots have at least three axes. These movements can be summarized as the rotation around its axis and its ability to move up and down and back and forth.
17.4.2 Classification of Robots by Coordinate Systems
- Cartesian coordinate system: All robot movements; they are at right angles to each other. This is a robot design form with the most limited freedom of movement. The process for assembling some parts is done by Cartesian configuration robots. This robot shape has parts moving in three axes perpendicular to each other. Moving parts X, Y, and Z move parallel to the Cartesian coordinate system axes. The robot can move the lever to points within the three‐dimensional rectangular prism volume.
- Cylindrical coordinate system: It can rotate around a basic bed and has a main body with other limbs. The movement is provided vertically and the main body is provided radially when the axis is accepted. Therefore, within the working volume, a zone is formed up to the volume of the main body, which the robot cannot reach. In addition, because of mechanical properties, the trunk cannot fully rotate 360°.
- Spherical coordinate system: Mathematically, the spherical coordinate system has three axes, two circular axes and one linear axis. There are basically two movements. These are horizontal and vertical rotation. A third movement is the linear movement of the elongation arm. The linear motion behaves just like the movement of any coordinate from the Cartesian coordinates.
- Rotating coordinate system: If a robot does the work in a circular motion, this type of robot is called a robot with a rotating coordinate system. The connections of the robot arm are mounted on the body so that it rotates around it and carries two separate sections with similar abutments. Rotating parts can be mounted horizontally and vertically.
- Multiaxis (articulated) robots: Arm‐jointed robots, according to their abilities, were made to undertake the tasks that the human arm could fulfill. They move freely in six axes. Three are for arm movement and the other three are for wrist movement. The biggest advantage of this connection is the ability to reach every point in the work area.
- SCARA Robotlar: The Selective Compliance Assembly stands for the Robotic Arm, i.e. the assembly robot arm that matches the selected. SCARA‐type robots are a type of robot with very high speed and best repetition capability. There are three general features: accuracy, high speed, and easy installation.
17.4.3 Other Robotic Classifications
There are many other classification methods such as classification by skill level, classification by control type, classification by technology level, classification by energy source, classification according to their work, holders, and limiters in robots.
- Robot holders: It is used very easily in the assembly process, welding operations, and painting operations. However, in an assembly line, it is seen that the same holder can do more than one job, or carry parts of various features, which can be seen as functional difficulties. In this case, it is a fact that a general purpose robot is needed. Robot hands have actuators based on various technologies that produce the power required for the movement of joints. The most widely used actuator technologies are electric motors, hydraulic actuators, and pneumatic actuators.
- Mechanical holders: They hold the parts between the mechanical holders and the fingers move mechanically.
- Vacuum holders: It is used to hold flat objects such as glass. The workpiece is held with the help of the vacuum formed between the holder and the holder.
- Magnetic holders: They are used to hold metal materials.
- Adhesive holders: It is used for carrying flexible materials such as adhesive materials and fabric.
The specifications of the programming languages of robots are listed below:
- The programming language is specific to the robot. (Example: Melfa Basic IV for Mitsubishi robot arms.)
- The language sets the electrical traffic for the robot components, processing the sensor data.
- It is simple to use and is limited by the capacity of the robot.
17.5 Image Processing
Basically, image processing is a name for analyzing a picture or video and identifying its characteristics. The characteristic feature of detection is, of course, based on distinctive character [2]. All of the facial recognition systems used today are performed with image processing.
The image can be modeled in a two‐dimensional (2D) and n × m matrix. Each element of this matrix determines the magnitude of that pixel between black and white. The values of the pixels in bits and the size of the image in horizontal and vertical pixels affect the quality and size of the image. In an 8‐bit black and white image, if a pixel is 0, it is black, and if a pixel is 255, it is white. The values are also proportional to black‐and‐white values.
Let us give another example. If we have an image whose size is 200 × 200 and each of the pixels in the image is 8‐bits, the total size of the image is 40 000 byte (40 kB). For the calculation, the formula is used ![]() . This information is correct if the image is stored as a bitmap. There are different compressed image formats that will reduce the size of these files.
. This information is correct if the image is stored as a bitmap. There are different compressed image formats that will reduce the size of these files.
The display format of color images is slightly different. The most common is the RGB (Red, Green, and Blue) representation, although there are different display formats. This impression assumes that each color can be created with a mixture of these three colors. Mathematically, these three colors can be considered for individual matrices.
17.5.1 Artificial Intelligence in Image Processing
The information expected to be obtained by visual processing has gone far beyond the labeling of a cat or dog on the photograph. The factors leading to this increase in expectation are both the increase in the number of data that can be processed and the development of the algorithms used. We are now able to work in important areas such as visual processing techniques to diagnose cancer cells or to develop sensors to be used in military fields. This advanced technology in image processing is made possible by the use of side heads such as machine learning, deep learning, and artificial neural networks.
Face recognition technologies, driverless tools, or Google's translation mode are among the simplest examples of machine learning‐based image processing systems. Google Translate creates the image processing system in the translation application by machine learning and artificial neural network algorithms.
Google Translate's camera‐to‐camera mode allows you to save letters of any language with image processing and machine learning. When we scan the word with the camera, it combines the letters in the system database to reveal the words. After the emergence of the word or sentence as in the classic Google Translate application with its own language processing algorithm translates words. The important point for this mode to work is that the words you read with the camera are recognized by the system, which is thanks to the machine learning.
Artificial intelligence, in addition to providing advanced technology in image processing, also reduces processing time. The electro‐optical sensor systems used in the military field have been used for the determination of mobile or fixed targets for many years. Nowadays, these systems are strengthened by artificial intelligence to provide both faster and more precise target detection.
17.5.2 Image Processing Techniques
Recently, new development techniques have been developed to support classical image processing methods or to walk through completely new algorithms. Most of the techniques are designed to develop images from unmanned spacecraft, space probes, and military reconnaissance flights. However, the developments have shown the effect in all areas where image processing is used.
A digital image consists of the numbers that gives information about the image or color. The main advantages of digital image processing methods are multidirectional scanning capability, reproducibility, and original data accuracy. Major image processing techniques are image preprocessing, image enhancement, image separation, feature extraction, and image classification.
17.5.2.1 Image Preprocessing and Enhancement
Images from satellites or digital cameras produce contrast and brightness errors due to limitations in imaging subsystems and lighting conditions when capturing images. Images can have different types of noise. Image preprocessing prevents the geometry and brightness values of the pixels. These errors are corrected using empirical or theoretical mathematical models.
Image enhancement improves the appearance of the image, allowing the image to be transformed into a more suitable form for human or machine interpretation, or emphasizes specific image properties for subsequent analysis. Visual enhancement is mainly provided by fluctuations on pixel brightness values. Examples of applications include contrast and edge enhancement, pseudo‐coloration, noise filtering, sharpening, and magnification.
The enhancement process does not increase the content of internal information in the data. It emphasizes only certain image properties. Enhancement algorithms are usually a preparation for subsequent image processing steps and are directly related to the application.
17.5.2.2 Image Segmentation
Image segmentation is the process of dividing the image into self‐constituent components and objects. It is determined when image segmentation will be stopped according to the application subject. Segmentation is stopped as soon as the searched object or component is obtained from the image. For example, airborne targets are firstly divided into photographs, roads, and vehicles as a whole. Each tool and path alone forms the split parts of this image. The image segmentation process is stopped when the appropriate subpicture is reached according to the target criteria.
Image threshold generation methods are used for image segmentation. In these limiting methods, the object pixels are set to a gray level and the background to different pixels. Usually, object pixels are black and the background is white. These binary images resulting from pixel difference are evaluated according to gray scale and image separation is made. Segmentation of images includes not only the distinction between objects and background but also the distinction between different regions.
17.5.2.3 Feature Extraction
Feature extraction can be considered as a top version of image segmentation. The goal is not only to separate objects from the background; the object is to define the object according to features such as size, shape, composition, and location. By mathematical expression, it is the process of extracting from raw data information to increase the variability of the class pattern while minimizing the in‐class pattern variability. In this way, quantitative property measurements, classification, and identification of the object are facilitated. Because the recognition system has an observable effect on the efficiency, the feature extraction phase is an important step in the visual processing processes.
17.5.2.4 Image Classification
Classification is one of the most frequently used information extraction methods. In its simplest form, a pixel or pixel group is labeled based on its gray value. It uses multiple properties of an object during labeling, which makes it easier to classify it as having many images of the same object in the database. In vehicles using remote sensing technology, most of the information extraction techniques analyze the spectral reflection properties of images. Spectral analyses are performed by a number of specialized algorithms and are generally carried out by two different systems, supervised and uncontrolled multispectral classification.
17.5.3 Artificial Intelligence Support in Digital Image Processing
All of these methods are the basic principles of image processing, which can help us to define the definition of image processing. The widespread use of image processing in the technological field and the expectation of increase in image processing applications necessitated the introduction of artificial intelligence into image processing.
17.5.3.1 Creating a Cancer Treatment Plan
Some cancer centers are developing artificial intelligence technologies to automate their radiation treatment processes. The researchers at the center produced a technology combining artificial intelligence and image processing to develop a customized individual radiotherapy treatment plan for each patient. AutoPlanning establishes quantitative relationships between patients using machine learning and image processing techniques. An appropriate treatment plan is created based on the visual data associated with the disease information, diagnosis, and treatment details of each patient. Learn to model the shape and intensity of radiation therapy in relation to the images of the patient. Thus, the planning times are reduced from hours to minutes. In particular, it uses a database of thousands of high‐quality plans to produce the most appropriate solutions to the problems experienced in the planning phase.
17.5.3.2 Skin Cancer Diagnosis
Computer scientists at the Standford Artificial Intelligence Laboratory have created an algorithm for skin cancer detection by combining deep learning with image processing. This algorithm can visually diagnose potential cancer with a high accuracy rate over a database containing approximately 130 000 skin disease images. The algorithm is fed as raw pixels associated with each image. This method is more useful than classical training algorithms because it requires very little processing of images before classification. The major contribution of deep learning to the algorithm is that it can be trained to solve a problem rather than adapting programmed responses to the current situation.
17.6 Problem Solving
Problem solving is mostly related to the performance outputs of reasonable creature. Problem solving is the activity of the mind when searching for a solution to a problem [3]. The term problem is a bit misleading. We often think of the problem as sadness and danger. Although this is true in some cases, it is not true in every case. For example, analyzing a potential merger is an opportunity research and can be considered as problem solving. Likewise, a new technology research is a problem‐solving process. The term problem solving was first used by mathematicians. Decision making is used in the sense of problem solving in business world.
17.6.1 Problem‐solving Process
The definition of the problem‐solving process depends on the training and experience of the researchers. For example, Bel et al. has proposed several approaches to problem solving and decision‐making that vary quantitatively according to people's intuition. Generally, six basic steps can be observed in the process: identifying and defining the problem, setting criteria for finding a solution, creating alternatives, searching for and evaluating solutions, making selections, and making recommendations and implementing them.
Some scientists use different classifications. Simon's classical approach, for example, has three phases: intelligence, design, and choice. Although the process in Figure 17.2 is shown as linear, it is rarely linear. In real life, some of these steps can be combined, some steps can be the basic steps, or revisions can be made in the initial steps. In short, this process is iterative. A brief description of each step is given below.
- Step 1 – Identifying and defining the problem: A problem (or opportunity) must be recognized first. The magnitude and significance of the problem (or opportunity) is specified and identified.
- Step 2 – Determining criteria: The solution of a problem depends on the criterion used to compare possible alternatives. For example, a good investment depends on criteria such as security, liquidity, and rejection rate. In this step, we determine the criteria and their relative importance to each other.
- Step 3 – Creating alternatives: According to the definition, there must be two or more chances to make a decision. Creating potential solutions requires creativity and intelligence.
- Step 4 – Finding and evaluating solutions: In this step, solution options are examined in the light of predetermined criteria. This step is basically a search process because we are trying to find the best or “good enough” solutions. Several step‐by‐step methodologies can be used in this step.
- Step 5 – Making choices and making recommendations: The result of the search is choosing a solution to recommend as a remedy to a problem.
- Step 6 – Implementation: To solve the problem, the recommended solution must be successfully implemented. In fact, this process is more complex because at each step, there may be several interim decisions, each following a similar process.

Figure 17.2 Steps of problem‐solving process.
Applied Artificial Intelligence technologies can be used to support all of these six steps. However, most of the artificial intelligence movements take place in steps 4 and 5. In particular, expert systems are used to find solutions from the presumed alternatives. The role of artificial intelligence is mainly to manage search and evaluation by using some inference capabilities. Today, despite the limited role of artificial intelligence, it is hoped that after a certain time, technologies will play a greater role in the steps of the process. Nevertheless, artificial intelligence technologies have another great advantage. Although artificial intelligence effectively uses only two steps of the problem‐solving process, artificial intelligence is used in many other tasks that are not classified as problem solving and decision‐making. For example, expert systems help to develop computer commands. Expert systems are also used to simulate people's help centers, which provide information in catalogs and manuals, and for planning, complex scheduling, and information interpretation.
17.7 Optimization
Optimization tries to find the best possible solution using mathematical formulas that model a particular situation. The problem area must be structured in accordance with the rules, and optimization is managed by a one‐step formula or an algorithm. Remember that the algorithm is a step‐by‐step search process in which solutions are produced and tested for possible improvements. Wherever possible, improvements are made and the new solution is subjected to an improvement test. This process continues until it becomes impossible to improve. Optimization is widely used in nonintelligence technologies such as business research (management science) and mathematics. In artificial intelligence, blind search and heuristic search are widely used [4].
Optimization is the job of finding the best solution under the constraints given by a basic definition. The solution of a problem is trying to find an optimal option that is listed in the solution set. These options are based on mathematical expressions. The optimal option of any problem is not the efficient solution for all problems. The solution or optimal option can be changed by the problem scope and the definition. The methods used do not guarantee the real solution. However, they are generally successful in finding the best possible solution at an acceptable speed. Various classifications of optimization problems have been made. However, according to the generally accepted classification [5];
- Minimization or maximization of objective function without any limitation of parameters, unrestricted optimization,
- Optimization problem with constraints or constraints on parameters is constrained optimization,
- According to whether the objective function and parameters are linear, an optimization problem is linear optimization,
- Nonlinear optimization if objective function or parameters are nonlinear,
- The problem of optimal regulation, grouping, or selection of discrete quantities discrete optimization,
- If the values of design variables are continuous values, such problems are called continuous optimization problems.
Different techniques are used to solve optimization problems. There are three main categories that are mathematical programming, stochastic process techniques, and artificial intelligence optimization techniques [5]. There are many examples of mathematical programming techniques: classical analysis, nonlinear programming, linear programming, dynamic programming, game theory, squared programming, etc. Statistical decision theory, Markov processes, regeneration theory, simulation method, and reliability theory are the examples of stochastic process techniques. In the last category, which is an artificial intelligence optimization technique, there are many examples such as genetic algorithm, simulated annealing, taboo search, ant colony algorithm, differential development algorithm, and artificial immune algorithm.
17.7.1 Optimization Techniques in Artificial Intelligence
Optimization techniques are called metaintuitive and research techniques. The aim of these algorithms is solving the problem. Some of the algorithms about the solution of the problem can guarantee the exact solution, but an appropriate solution can guarantee it.
Application results show that artificial intelligence optimization algorithms are problem‐dependent algorithms. In other words, they may be successful in one problem and not in the same way for another problem. The most important artificial intelligence optimization algorithms are artificial heat treatment algorithms, genetic algorithms, and taboo search algorithms [6].
- Artificial heat treatment algorithm: Artificial heat treatment algorithms, which are also mentioned in the literature as an annealing simulation method, are basically a different form of application of the best search methods by accepting the better solution encountered first. Unlike the search method with gradient, which aims to go to a better point at each step, the main disadvantage of this algorithm is that it may lead to a worse solution with a decreasing probability in the process.
- Genetic algorithm: Genetic algorithms were proposed by Holland based on the biological evolution process. Unlike the other two methods described here, the genetic algorithm evaluates multiple solutions at the same time instead of a single solution. This feature is described as the parallel search feature of the genetic algorithm. Problem solving is expressed by a chromosome consisting of genes.
- Taboo search: Taboo search is basically an adaptation of the best fit strategy around a solution that seeks the best local solution. The last steps taken by the algorithm are declared taboo so that the algorithm does not return to the same local best solution immediately after it leaves a local best solution. The taboo list is dynamic. Each time a new element enters the taboo list, the most remaining element in the taboo list is removed from the list. In this way, the algorithm is given a memory.
Applications of artificial intelligence optimization techniques are listed below:
- Scheduling: Production schedules, workforce planning, class schedules, machine scheduling, and business schedules
- Telecommunication: Search route problems, path assignment problems, network design for service, and customer account planning
- Design: Computer‐aided design, transport network design, and architectural area planning
- Production and finance: Manufacturing problems, material requirements planning (MRP) capacities, selection of production department, production planning, cost calculations, and stock market forecasts
- Location determination and distribution: Multiple trading problems, trade distribution planning, oil, and mineral exploration
- Route: Vehicle route problems, transportation routes problems, mobile salesman problems, computer networks, and airline route problems
- Logic and artificial intelligence: Maximum satisfaction problems, logic of probability, clustering, model classification and determination, and data storage problems
- Graphics optimization: Graphics partitioning problems, graphic color problems, graphics selection problems, P‐median problems, and image processing problems
- Technology: Seismic technology problems, electrical power distribution problems, engineering structure design, and robot movements
- General combinational optimization problems: 0–1 Programming problems, partial and multiple optimization, nonlinear programming, “all‐or‐none” networks, and general optimization
17.8 Autonomous Systems
17.8.1 History of Autonomous System
After Turing, the father of computer science, John McCarthy is the father of artificial intelligence. He is also the one who indirectly brings us together with Siri. He established the Artificial Intelligence Laboratory at Stanford University and developed the list processing (LISP), which is considered the programming language of artificial intelligence based on lambda calculations. He first described the concept as science and engineering for the construction of intelligent machines, especially intelligent computer programs, at a conference in Dartmouth in 1956. The term reason is, of course, the subject of scientific and philosophical discussions. Some researchers believe that strong artificial intelligence can be done, and that we can develop an artificial intelligence that matches or exceeds human intelligence, and that it is possible to accomplish any intellectual task that a human can accomplish. Other researchers believe that weak artificial intelligence applications may be possible and that software can be used to perform certain tasks much better than humans, but can never cover all of human cognitive abilities. No one is yet sure which one is right.
When we look at the history of autonomous vehicles in 1920–1930, some prominent systems already gave the gospel of autonomous vehicles. The first models that could travel on their own were introduced in the 1980s. The first vehicle was built in 1984 by Carnegie Mellon University with Navlab and autonomous land vehicle (ALV) projects. This was followed in 1987 by the Eureka Prometheus project, jointly implemented by Mercedes‐Benz and the Bundeswehr University. After these two vehicles, countless companies have built thousands of autonomous cars, some of which are currently in traffic in several countries.
Autonomous automobiles seem to lead to a revolution in the passenger car sector, leading to a major transformation in the automotive sector. The rapid development of driver vehicle technology will soon change the rules of Henry Ford's game dramatically. Especially, the automotive industry will be one of the most affected units from this development. It is thought that driverless or autonomous cars will lead to an unprecedented economic, social, and environmental change in the near future. It is also clear that it will lead to an excellent equality of social status on the basis of citizens. Autonomous tools ensure that young people, the elderly, or physically disabled people have the same level of freedom to travel.
In addition to a few fundamental changes in the technological field, changes in the demands of consumers are being caused by the production of more powerful batteries, the provision of more environmentally friendly fuels, and the production of autonomous vehicles. These changes in the demands of consumers also lead to drastic changes in the planning of the manufacturing companies. In addition, the sharing economy has reached the automotive industry with BMW's diverse services, such as DriveNow in Paris or Autolib. Tesla has taken advantage of such developments so far, offering products that can be offered to the market among the most successful candidates. However, manufacturers in other companies such as BMW, Toyota, and General Motors in Silicon Valley are also making ambitious developments in this field. These developments seem to be one of the biggest steps toward the fourth industrial revolution in the automotive sector. Roland Berger, one of the largest strategic consulting firms based in Europe, says that the automotive, technology, and telecommunications sectors will unite at some point. Nowadays, considering the vehicles that have gained value in the market, we see that approximately 30% of the vehicles are based on electronics, and this ratio is expected to increase to 80% with the future innovations of the sector.
17.8.2 What Is an Autonomous Car?
Autonomous vehicles are automobiles that can go on the road without the intervention of the driver by detecting the road, traffic flow, and environment without the need of a driver thanks to the automatic control systems. Autonomous vehicles can detect objects around them by using technologies and techniques such as radar, light detection and ranging (LIDAR), GPS, odometry, and computer vision. Let us see detailed information about the sensors.
LIDAR, which stands for light detection and ranging, was developed in 1960s for the detection of airborne submarines and started to be used in 1970s. In the following years, there has been an increase in the usage area and types of sensors using LIDAR technique, both from air and land. LIDAR technology is currently used in architecture, archeology, urban planning, oil and gas exploration, mapping, and forest and water research. An LIDAR instrument principally consists of a laser, scanner, and specialized GPS receiver [7]. You can see an example of LIDAR view in Figure 17.3.

Figure 17.3 Examples of LIDAR views [7].
Both natural and manmade environments can be displayed by LIDAR. In a study, it is said to be very advantageous to use LIDAR for the emergency response operations [7].
GPS, which stands for global positioning system, is a system that helps to provide a location with satellites, receivers, and algorithms. It is generally used for traveling such as air, sea, and land locations. GPS works at all times and in almost all weather conditions [8].
In general, there are five important usage of GPS:
- Location: Detects the location and position.
- Navigation: Gets from a location to another.
- Tracking: Monitors objects or personal movement.
- Mapping: Creates maps of the world.
- Timing: Calculates the precise time measurements.
17.8.3 Literature of Autonomous Car
There are several studies describing the level of autonomy in the literature. However, the most common of these is suggested by Thomas B. Sheridan [9]. According to this scale, the order of increasing autonomy level from 1 to 10 is given below.
- Computer will not help; human makes the entire task.
- The computer provides a set of motion options that includes all options.
- The computer reduces the options up to a few.
- The computer recommends a single action.
- The computer executes the movement if the person approves.
- The computer gives the person the right to refuse for a limited time before automatic execution.
- The computer automatically executes the task and informs the person necessarily.
- The computer informs the person after the automatic execution if he wishes.
- Computer automatically informs people if they want after the automatic execution.
- The computer decides and executes everything and does not care about people.
The first developments in the field of advanced vehicle control systems were discovered by the General Motors Research Group in the early 1960s. This group developed and exemplified the automatic control of automobile steering, speed, and brakes on test tracks [10]. This research triggered other research groups. In the late 1960s, Ohio State University and Massachusetts University of Technology began working on the application of these techniques to address urban transport problems.
From the first days of intelligent transportation systems, we can see that the results of the studies carried out in the laboratory environment can be seen in advanced driving support systems in the vehicles on sale. Large vehicle manufacturers are constantly researching new and improved driving assistance systems [11]. The purpose of these systems is to help drivers rather than replace them. The most important developments in this field are cruise control [12], dynamic stability control [9], antilock brakes (ABs) [13], and pedestrian detection with night vision systems [14], collision avoidance [15], and semiautonomous parking system [16]. In these applications, longitudinal control (acceleration and braking actions) is mostly emphasized.
One of the leaders of lateral control studies on the steering wheel movement is Ackermann [17]. Ackermann's approach is used to combine active steering with feedback of the swing rate to strongly distinguish between skidding and lateral movements. It is possible to control nonlinear dynamic systems such as steering control thanks to techniques that allow fast, trouble‐free, and high‐quality control. In order for the vehicle to continue to follow the reference trajectory; fuzzy logic [18], optimization of linear matrix inequalities [19], and skew rate control [20].
Another important change in the steering system has been the replacement of hydraulic power steering system (HPS) with electric power steering system (EPS) in new‐generation vehicles. Such a system has advanced control simulations [17–21]. Sugeno and Murakami published a landmark publication in 1984. They have shown that any industrial process can be controlled by a simple process of human process or human experience [18]. The problem is reduced to finding the right control rules and fine‐tuning them based on a drive experience. Several studies have compared fuzzy control and classical control techniques in autonomous vehicles, and fuzzy controllers have shown good results [22].
The first serious step in fuzzy logic was demonstrated in an article written by Azerbaijani scientist Lütfi Aliasker Zade in 1965 [23]. In this study, Zade stated that a large part of human thought is blurred and not precise. Therefore, human reasoning system cannot be expressed with dual logic. Human logic uses expressions such as hot and cold, as well as expressions such as warm and cool.
After the introduction of fuzzy logic, it was not accepted for a long time in the Western world. The idea found its place in practice only nine years after its production, when Mamdani carried out the inspection of a steam engine [24]. As the 1990s approached, fuzzy logic attracted attention in Japan and began to be used in many applications. In 1987, the Japanese Sendai subway designed by Hitachi managed to reduce energy consumption by 10% while using fuzzy logic to provide more comfortable travel, smoother slowdown, and acceleration in the subway [25]. The products of fuzzy logic applications were introduced to consumers in Japan in the early 1990s. According to the degree of pollution in dishwashers and washing machines, washing technology has yielded fruitful results [26]. The Western world could not remain indifferent to these developments, and in 1993, IEEE Transactions on Fuzzy Systems magazine began to publish.
In order to develop autonomous vehicles, there are models developed on ATVs (all‐terrain vehicles). These models have a structure built on the acceleration and steering systems of the vehicle, as in almost all autonomous vehicle studies. Rather than developing a new vehicle from the start, it seems reasonable to make an already existing vehicle autonomous. One of the reasons for this is the opportunity to work with vehicles that have already been tested to work in all harsh conditions. Another reason is that the product that will be produced as a result of the studies will be independent of the vehicle to be integrated, and this will maximize the applicability. In this context, four teams whose names are Ensco [27], Spirit of Las Vegas [28], Overbot [29], and Cajunbot [30] that are built on the ATVs shown in Figure 17.4 produced for the DARPA Grand Challenge in 2004 and 2005 were examined. All the four teams controlled acceleration using a servo motor on the accelerator pedal. For steering, Cajunbot and Spirit of Las Vegas teams preferred DC Motors, while Ensco and Overbot teams preferred servo motors.

Figure 17.4 (a) Ensco, (b) Spirit of Las Vegas, (c) Overbot, and (d) Cajunbot.
Researchers use DGPS (differential global positioning system) for positioning. In this way, the vehicle is able to determine its position with an average error of 10 cm instead of locating with an average of 15 m error with normal GPS [31]. The operating principle of DGPS is that in addition to the normal GPS system, an antenna with a location on the ground is taken as a reference. The satellites are detected with the reference antenna after the connection with the user and the reference antenna, and the location of the user is detected with very small errors. DGPS is the only solution yet available for positioning in outdoor applications.
In order to determine the exact movement of the vehicle, the researchers used a three‐axis gyroscope and an accelerometer. The three‐axis gyroscope is a key instrument in marine and aviation and is now being used in land vehicles. It works according to the basic physics rules and is based on the conservation of angular momentum. The gyroscope, which is also used in smartphones today, can easily be determined in which direction an object is inclined.
The accelerometer measures the acceleration to which a mass is exposed. The principle of operation is to measure the forces applied to the test mass from the mass in the reference axis. With this device, the forces applied to the mass such as acceleration, deceleration, and skidding can be measured.
Researchers have chosen a wide range of power sources for their projects. Power is an important issue because it is a major factor determining all dynamics in a drone. Although it is first considered that it meets the needs when supplying power to the system, the preferred power source should not place excessive volume and weight on the vehicle. In this context, internal combustion engines, high‐current batteries, generators, and uninterruptible power supplies are used as power supplies. When required, the required voltages are produced with DC/DC converters.
Processors, random access memory (RAM), and hard drives used to process data and control devices can be catered for a wide variety of projects. Because the vehicles will move, it is generally taken care not to use moving parts. In this context, it is seen that solid‐state disks are used for storage purposes. According to the needs of the project, wireless technologies are used to send the data to the computer.
Environment detection is the most important need of unmanned vehicles. The vehicles have to perform all their movements in the light of the data coming from the sensors. LIDAR, cameras, and ultrasonic sensors are the most commonly used sensors in unmanned land vehicle projects [32]. In the aforementioned studies, all teams used both LIDAR and camera. LIDAR is an optical distance sensing technology that can detect and measure objects by direction and distance, usually by laser‐transmitted rays. LIDAR systems used in unmanned land vehicles have laser range finders of the type, which are reflected by rotating mirrors [33]. The device is very high‐priced and helps to identify objects around the vehicle. Google's driverless vehicle can detect the perimeter of the vehicle.
The cameras used in the studies are two of types, mono and stereo. Mono cameras are generally used to monitor the vehicle's surrounding information, while stereo cameras are used to understand depth information. The images taken with all these sensors are combined, interpreted, and interpreted with advanced image processing methods. Open source software is widely used in the studies. Developed according to project‐specific requirements, these softwares are shaped according to the requirements of the hardware used.
17.8.4 How Does an Autonomous Car Work?
The autopilot drive of autonomous vehicles starts briefly with the ultrasonic sensors on its wheels detecting the positions of vehicles that are braking or parked, and data from a wide range of sensors are analyzed with a central computer system, and events such as steering control, braking, and acceleration are performed. This event can only be described as a beginning. With the technology becoming cheaper, the future of driverless vehicles becomes increasingly realizable.
In autonomous vehicles, systems such as sensor data, extensive data analysis, machine learning, and the M2M (machine‐to‐machine) communication system are essential for the successful implementation of the Internet of Things philosophy. The autonomous vehicle projects currently on the market, evaluates the sensor data, analyzes and provides machine movements as well as machine learning. At present, there are not enough autonomous vehicles in today's traffic to design a vehicle suitable for M2M communication system. However, when a certain threshold is reached in this issue, interesting developments such as autonomous traffic control systems and autonomous traffic control can also be allowed.
Such a system would have a very extraordinary impact on industry and society as a whole. At the level of community and living standards, the biggest impacts are the decrease in the number of accidents, the increase in the use of passenger cars that easily accompany, and the decrease in crowds in public transportation centers. Together with the increase in the use of vehicles, the increase in the amount of fuel consumption because of the increase in oil trade seems to cause a new activity in the country's economy.
In the next eight years, Korea plans to produce autonomous vehicles that will be developed entirely with its own technology. Currently in the monopoly of American‐ and European‐based companies in this sector in the future, market is expected to expand further into Asia. Until 2019, the Korean Government set aside a budget of approximately US$ 2 billion to produce the eight main components required for driverless vehicles, including visual sensors and radars. However, in 2024, 100% of Korean‐made autonomous vehicles are planned to hit the road. It is clear that autonomous vehicles have a very bright future around the world. Korean car manufacturers and technology giants such as Samsung have already been thrown into developments in the autonomous vehicle industry. The structure of an autonomous car is given in Figure 17.5.
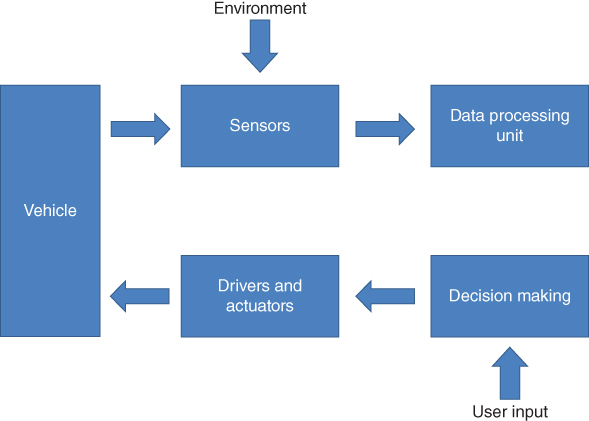
Figure 17.5 The structure of autonomous car.
There are two different types of autonomous car systems. The traditional approach divides the task into some basic sections, which is lane detection [34,35], path planning [36,37], and control logic [35,38], and is often investigated separately. Image processing techniques such as Hough Transform, edge detection algorithms are usually used for detecting lane marks. After detecting lane marks, path planning can be done, and control logic helps to check conditions. In this approach, feature extraction and interpretation of image data are done. On the other hand, the end‐to‐end learning approach to self‐driving tools is using convolutional neural networks (CNNs) [39]. End‐to‐end learning takes the raw image as the input and outputs the control signal automatically. The model optimizes itself based on training data, and there are no manually defined rules. These become two important advantages of end‐to‐end learning: better performance and less manual effort. Because the model is self‐optimizing based on data to give maximum overall performance, the intermediate parameters are automatically adjusted to be optimal. In addition, there is no need to design control logic based on identifying certain predefined objects, labeling these objects during training, or observing them. As a result, less manual effort is required.
17.8.5 Concept of Self‐driving Car
The concept of self‐driving car has a relationship between computer vision, sensor fusion, deep learning, path planning, actuator, and localization [40]. These are the main parts of the self‐driving car.
- Computer vision: Computer vision is an interdisciplinary field that can understand high‐level form of digital images or videos. Computer can see like from human's eye with the advanced computer vision algorithms [41,42].
- Sensor fusion: Sensor fusion is basically the combination of the data that is derived from the source [43,44].
- Deep learning: Deep learning is part of machine learning methods based on learning data representations. There are three types of methods, which are supervised, partially supervised, or unsupervised, for the learning [45,46].
- Path planning: Path planning is the most important field in the concept of robotics. In this field, shortest path can be calculated by the algorithm, and the calculated path helps autonomous mobile robots to move individually. Otherwise optimal paths could be paths that minimize the amount of turning, the amount of braking, or whatever a specific application requires [40].
- Actuator system: An actuator is the main component of the machine for controlling a machine or system. It is the heart of the system.
- Localization: Localization has a close relationship with navigation. For the navigation, robot or autonomous system needs a local or real‐time map. For generating a map of the robot or autonomous system, the system needs to know its position in the frame and plans a path toward the target. In order to navigate in its environment, the robot or any other mobility device requires representation, i.e. a map of the environment and the ability to interpret that representation [40].
An autonomous vehicle needs data that come from the different types of sensors such as camera, radar, laser, etc., to see the perspective of the car. This is used for creating a digital map that is very important for object detection [47].
17.8.5.1 Image Classification
Image classification is the main action of self‐driving car in the concept of object detection. The image is taken by the camera, and then computer vision algorithms are run on the image, and finally, items or objects are detected and labeled. There is an example of object detection in Figure 17.6.

Figure 17.6 A simple example of object detection.
Object detection consists of two processes, image classification and image localization. Image classification is used for determining the objects in the image, such as an animal or a plane, while image localization is used for determining the specific location of these objects. In the localization part, the objects are seen by the bounding boxes.
To perform image classification, a CNN is trained to recognize various objects, such as traffic lights and pedestrians. A CNN performs many operations on images in order to classify them.
17.8.5.2 Object Tracking
Object tracking algorithms can be divided into two categories that are tracking‐by‐detection methods and generative methods [48]. In tracking‐by‐detection methods, object is detected in every time. For the detection, a pretrained detector and the positions are used [49]. In this approach, all object categories must be trained previously. Generative object tracking methods are especially used for autonomous car. In these approaches, the most important thing is the appearance of the object. The object model is often updated online, adapting to appearance variations.
17.8.5.3 Lane Detection
Lane detection is one of the main actions for the autonomous vehicles. In that part, computer vision algorithms help to detect and find the lanes. In that point, a large amount of data is needed. A huge amount of data and complex algorithms mean deep learning. Object and lane detection for self‐driving car is done by deep learning. There are many kinds of datasets such as ImageNet [50], ActivityNet [51], MS COCO, Open Images [52], YouTube‐8M, and YouTube‐BB. Recently, in the field of autonomous car or driving, various datasets have been published including CamVid [53], KITTI [54], TORCS [55], GTA5 [56], Cityscapes [57], and SYNTHIA [58]. In these datasets, user can find high‐level scenes. Semantic segmentation is required for analyzing complex scenes. Segmenting objects means to detect all objects that are static or dynamic. After detecting, classification can be done according to the analysis of object [59].
At present, 90% of traffic accidents are caused by human error, but autonomous vehicles designed and developed today will be presented as programmed not to crash in the near future. Research is being carried out to solve some of the ongoing technology problems to ensure this technology. It will also be difficult to coordinate traffic with mixed drivers and driverless vehicles. In this transition period, the biggest problem that may arise in the traffic consisting of autonomous and nonautonomous vehicles is that both vehicles will share the road while the driverless automobiles will try to dominate the road.
In one company, which is located at Turkey, a self‐driving robot has been developed for cleaning the streets of the big cities. This robot can also analyze and report the problems that are located in the streets.
17.8.5.4 Introduction to Deep Learning
The software that is designed to make human life easier can create excitement in the world of science, sometimes giving results beyond human intelligence. Deep learning is one of the most current and popular examples of this situation. You can think of deep learning as a more advanced version of the concept of machine learning. Deep learning is an approach used in machines to perceive and understand the world. The myth of artificial intelligence is only possible with deep learning. Everything from the automatic scanning of unnecessary emails to a mailbox to the driving cars without drivers or cancer research done without a doctor is the work of this chain of algorithms. In addition to top‐ranking research companies, universities, social media companies, and technology giants are increasingly investing in this field.
Rather than constructing software step‐by‐step, lead up to make this fiction by computer is the goal of deep learning. In this way, it can produce computer model solutions against alternative scenarios. Although the scenarios that programmers can produce in the software phase are limited, there are innumerable solutions that deep learning machines can offer. Therefore, what kind of objects a computer needs to recognize must first be loaded into the computer as a training set. Because this set consists of layers, it can also be likened to nerve cells interacting in the human brain. Each object to be introduced must be uploaded to the system as labeled/tagged data as the first job. By referring to the deep neural networks in the human body, deep learning algorithms begin to establish their own causal relationships over time. Although useless codes are subject to elimination, useful codes are being used more frequently and efficiently.
Some basic applications, which are used in real life, of deep learning are listed below.
- Face recognition: The ability to open the lock screen with face recognition, which is used in smart phones or to suggest the person to be tagged in a photo uploaded to social media by the program, can be given as an example of face recognition.
- Voice recognition: In telephone banking, it can be considered as an example of voice recognition that voice can be detected and directed to the necessary services. Voice assistants on the phones are also inspired by deep learning. Likewise, there is no mistake to predict that all devices and people will stay in constant contact with voice recognition in the long run.
- Use in vehicles: In addition to autopilot feature, even when the field of view is limited, making the right decision and creating a safe area during lane change continue. Among the work of automobile giants, there is also a driverless vehicle.
- Use in defense and security fields: Deep learning facilitates the work of security and defense companies through video recognition. Rather than constantly monitoring camera recordings, technologies such as the receipt of a written record of the recording or the activation of the alarm system in unusual movements are possible through in‐depth learning.
- Health care: One of the most exciting uses of deep learning is definitely health. Especially in cancer research, there are studies that eliminate time loss. Deep learning algorithms introducing cancer cell samples are both faster and more successful in diagnosing whether new cells are cancerous.
17.8.6 Evaluation
Until now, all studies on autonomous vehicles have been tested mostly during daytime or in well‐lit environments. Uber accident that occurred in the night in recent years has frightened and upset everyone. After the accident, Uber interrupted the test drive on its driverless vehicles. For this reason, driverless vehicles continue to work in night/dark environments. Although there is a certain amount of illumination of the road and environment without a driver at night, the biggest problem of this issue is the lack of illumination. Apart from that, the current traffic is seen as a pattern of bright lights on a black background. To solve this problem, the fusion of the sensors is also required. Multiple sensors (LIDAR, GPS, advanced driver assistance systems – ADAS, etc.) and data from these sensors must be processed at the same time. At this point, testing this subject with deep learning will facilitate the procedures. When the previous studies are examined, the algorithm is generally followed as follows:
- First, the data from the sensors used are collected and the collected data are simplified/extracted.
- With a preferred algorithm, the object is detected and the objects around the vehicle are detected and labeled.
- Lane detection is done by using deep learning architecture and image processing algorithms.
- After all these determinations are made, decision‐making is carried out. (Gas/brake adjustment, updating steering angle, stop/start the car, etc.)
The above steps continue until the autonomous vehicle reaches the destination.
In another study, a leading vehicle was placed in front of the autonomous vehicle and the vehicle in front was followed on a dark and curvy road [60]. A real‐time autonomous car chaser operating optimally at night (RACCOON) solves these problems by creating an intermediate map structure that records the trajectory of the leading vehicle. The path is represented by points in a global reference frame and the computer‐controlled vehicle is routed from point to point. The autonomous vehicle follows this track at any speed and takes into account the taillights of the leading vehicle. Using this approach, the autonomous vehicle travels around corners and obstacles, not inside the vehicle. RACCOON was tested successfully applied on Carnegie Mellon Navlab I1. RACCOON consists of the following subsystems:
- Start
- Image acquisition
- Rear lamp (taillight) tracking
- Leader vehicle position calculation
- Consistency check and error recovery
- Output
In another study, object classification was successfully performed by using LIDAR, which is one of the most useful sensors for autonomous vehicles in night vision and image processing techniques. The collected samples were processed with CNN. The system works as follows:
- Autonomous vehicle receives RGB image and LIDAR data from the camera.
- These data are clipped by forming color and depth pairs.
- The edited data are trained in the CNN architecture and the result is recorded on the driving cognitive map.
17.9 Conclusion
As a result, artificial intelligence takes place in our lives with all fields. The most important point here is to use this field correctly and in accordance with ethical rules. Five years from now, machines can discuss and discuss new areas. Those who want to work in this field should first of all have good mathematics and be a good researcher. Do not hesitate to share your work so that many hands make light work. The more important it is to train an individual well, the more important it is to code a machine well.
References
- 1 Özdemir, S. (2018). Robotik Nedir. https://www.muhendisbeyinler.net/robotik-nedir/ (accessed 1 June 2019).
- 2 Information about computer vision. http://www.elektrik.gen.tr/2015/08/bilgisayar-gorusu-ve-imge-isleme/360 (accessed 1 June 2019).
- 3 Lecture Notes of an instructor: Information about Artificial Intelligence. https://web.itu.edu.tr/∼sonmez/lisans/ai/yapay_zeka_problem_cozme.pd (accessed 1 June 2019).
- 4 Coşkun, A. Yapay Zeka Optimizasyon Teknikleri: Literatür Değerlendirmesi. Ankara: Gazi Üniversitesi Endüstriyel Sanatlar Eğitim Fakültesi Bilgisayar Eğitimi Bölümü.
- 5 Karaboğa, D. (2004). Yapay Zeka Optimizasyon Algo‐ritmaları, 75–112. İstanbul: Atlas Yayınevi.
- 6 Ulusoy, G. (2002). Proje Planlamada Kaynak Kısıtlı Çizelgeleme. Sabancı Üniversitesi Mühendislik ve Doğa Bilimleri Fakültesi Dergisi 8: 23–29.
- 7 LIDAR. https://oceanservice.noaa.gov/facts/lidar.html (accessed 2 June 2019).
- 8 GPS. https://www.geotab.com/blog/what-is-gps/ (accessed 2 June 2019).
- 9 Sheridan, T.B. and Verplank, W.L. (1978). Human and Computer Control of Undersea Teleoperators. Cambridge, MA: Massachusetts Institute of Technology Man‐Machine Systems Laboratory.
- 10 Gardels, K. (1960). Automatic Car Controls for Electronic Highways. MI: General Motors Research Laboratories.
- 11 Cheng, H., Zheng, N., Zhang, X. et al. (2007). Interactive road situation analysis for driver assistance and safety warning systems: framework and algorithms. IEEE Transactions on Intelligent Transportation Systems 8 (1): 157–167.
- 12 van Arem, B., van Driel, C.J.G., and Visser, R. (2006). The impact of cooperative adaptive cruise control on traffic‐flow characteristics. IEEE Transactions on Intelligent Transportation Systems 7 (4): 429–436.
- 13 Lin, J.S. and Ting, W.E. (2007). Nonlinear control design of anti‐lock braking systems with assistance of active suspension. IET Control Theory and Applications 1 (1): 343–348.
- 14 Bi, L., Tsimhoni, O., and Liu, Y. (2009). Using image‐based metrics to model pedestrian detection performance with night‐vision systems. IEEE Transactions on Intelligent Transportation Systems 10 (1): 155–164.
- 15 Gehrig, S.K. and Stein, F.J. (2007). Collision avoidance for vehicle‐following systems. IEEE Transactions on Intelligent Transportation Systems 8 (2): 233–244.
- 16 Li, T.H.S. and Chang, S.J. (2003). Autonomous fuzzy parking control of a car‐like mobile robot. IEEE Transactions on Systems, Man, and Cybernetics Part A: Systems and Humans 33 (4): 451–465.
- 17 Ackermann, J., Bünte, T., and Odenthal, D. (1999). Advantages of Active Steering for Vehicle Dynamics Control. Cologne: German Aerospace Center.
- 18 Sugeno, M. and Murakami, K. (1984). Fuzzy parking control of model car. The 23rd IEEE Conference on Decision and Control, Las Vegas, Nevada, USA (12–14 December 1984). IEEE.
- 19 Tan, H.S., Bu, F., and Bougler, B. (2007). A real‐world application of lane‐guidance technologies – automated snowblower. IEEE Transactions on Intelligent Transportation Systems 8 (3): 538–548.
- 20 White, R. and Tomizuka, M. (2001). Autonomous following lateral control of heavy vehicles using laser scanning radar. Proceedings of the 2001 American Control Conference, Arlington, VA, USA (25–27 June 2001). IEEE.
- 21 Chen, X., Yang, T., and Zhou, X.C.K. (2008). A generic model‐based advanced control of electric power‐assisted steering systems. IEEE Transactions on Control Systems Technology 16 (6): 1289–1300.
- 22 Chaib, S., Netto, M.S., and Mammar, S. (2004). H∞, adaptive, PID and fuzzy control: a comparison of controllers for vehicle lane keeping. IEEE Intelligent Vehicles Symposium, Parma, Italy (14–17 June 2004). IEEE.
- 23 Zade, L.A. (1965). Fuzzy sets and information granularity. Information and Control 8: 338–353.
- 24 Mamdani, E.H. (1974). Application of fuzzy algorithms for control of simple dynamic plant. Proceedings of the Institution of Electrical Engineers 121 (12): 1585–1588.
- 25 Alçı M., Karatepe E. (2002). Bulanık Mantık ve MATLAB Uygulamaları In: Chapter 6, MATLAB Fuzzy Logic Toolbox Kullanarak Bulanık Mantık Tabanlı Sistem Tasarımı, İzmir. 8–10.
- 26 Elmas, Ç. (2011). Yapay Zeka Uygulamaları. In: Bulanık Mantık Denetleyici Sistemler, 185–187. Ankara: Seçkin Yayıncılık.
- 27 Team Ensco (2004). 5th IFAC/EURON Symposium on Intelligent Autonomous Vehicles Instituto Superior Técnico, Lisboa, Portugal July 5–7, 2004. DARPA Grand Challenge Technical Paper.
- 28 Team Spirit of Las Vegas (2004). Defense Advanced Research Projects Agency (DARPA) and DARPA Grand Challenge Technical Paper.
- 29 Overboat Team (2005). Defense Advanced Research Projects Agency (DARPA) and Team Banzai Technical Paper DARPA Grand Challenge.
- 30 Cajunbot Team (2005). Defense Advanced Research Projects Agency (DARPA) and Technical Overview of CajunBot.
- 31 Differential GPS. Wikipedia. http://www.webcitation.org/query?url=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FDifferential_GPS&date=2015-07-20 (accessed 20 July 2015).
- 32 Cremean, L.B., Foote, T.B., Gillula, J.H. et al. (2006). Alice: an information‐rich autonomous vehicle for highspeed desert navigation. Journal of Field Robotics 23 (9): 777–810.
- 33 Hachman, M. ‘Eyes’ of Google's self‐driving car may bust crooks. PCMAG. https://uk.pcmag.com/cars/64978/eyes-of-googles-self-driving-car-may-bust-crooks (accessed 20 July 2015).
- 34 Zhao, J., Xie, B., and Huang, X. (2014). Real‐time lane departure and front collision warning system on an FPGA. In: 2014 IEEE High Performance Extreme Computing Conference (HPEC), 1–5. IEEE.
- 35 Humaidi, A.J. and Fadhel, M.A. (2016). Performance comparison for lane detection and tracking with two different techniques. In: 2016 Al‐Sadeq International Conference on Multidisciplinary in IT and Communication Science and Applications (AIC‐MITCSA), 1–6. IEEE.
- 36 Li, C., Wang, J., Wang, X., and Zhang, Y. (2015). A model based path planning algorithm for self‐driving cars in dynamic environment. In: 2015 Chinese Automation Congress (CAC), 1123–1128. IEEE.
- 37 Yoon, S., Yoon, S.E., Lee, U. et al. (2015). Recursive path planning using reduced states for car‐like vehicles on grid maps. IEEE Transactions on Intelligent Transportation Systems 16 (5): 2797–2813.
- 38 Wang, D. and Qi, F. (2001). Trajectory planning for a four‐wheel‐steering vehicle. In: Proceedings 2001 ICRA. IEEE International Conference on Robotics and Automation, vol. 4, 3320–3325. IEEE.
- 39 Bojarski, M., Testa, D.D., Dworakowski, D. et al. (2016). End to end learning for selfdriving cars. CoRR, vol. abs/1604.07316. http://arxiv.org/abs/1604.07316.
- 40 Aziz, M.V.G., Prihatmanto, A.S., and Hindersah, H. (2017). Implementation of lane detection algorithm for self‐driving car on Toll Road Cipularang using Python language. International Conference on Electric Vehicular Technology (ICEVT), Bali, Indonesia (2–5 October 2017).
- 41 Ballard, D.H. and Brown, C.M. (1982). Computer Vision. Prentice Hall. ISBN: 0‐13‐165316‐4.
- 42 Huang, T. (1996). Computer vision: evolution and promise. In: 19th CERN School of Computing (ed. C.E. Vandoni), 21–25. Geneva: CERN https://doi.org/10.5170/CERN-1996-008.21. ISBN: 978‐9290830955.
- 43 Elmenreich, W. (2002). Sensor fusion in time‐triggered systems. PhD thesis (PDF). Vienna University of Technology, Vienna, Austria. p. 173.
- 44 Haghighat, M.B.A., Aghagolzadeh, A., and Seyedarabi, H. (2011). Multi‐focus image fusion for visual sensor networks in DCT domain. Computers and Electrical Engineering 37 (5): 789–797.
- 45 Bengio, Y., Courville, A., and Vincent, P. (2013). Representation learning: a review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1798–1828. arXiv:1206.5538doi:https://doi.org/10.1109/tpami.2013.50.
- 46 Schmidhuber, J. (2015). Deep learning in neural networks: an overview. Neural Networks 61: 85–117. PMID: 25462637. arXiv:1404.7828doi:https://doi.org/10.1016/j.neunet.2014.09.003.
- 47 About an Information of self‐driving car. https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503 (accessed 1 June 2019).
- 48 Yang, H., Shao, L., Zheng, F. et al. (2011). Recent advances and trends in visual tracking: a review. Neurocomputing 74 (18): 3823–3831.
- 49 Geiger, A., Lauer, M., Wojek, C. et al. (2014). 3d traffic scene understanding from movable platforms. IEEE Transactions on Pattern Analysis and Machine Intelligence 36: 1012–1025.
- 50 Russakovsky, O., Deng, J., Su, H. et al. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision 115 (3): 211–252.
- 51 Heilbron, F.C., Escorcia, V., Ghanem, B., and Niebles, J.C. (2015). ActivityNet: a large‐scale video benchmark for human activity understanding. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA (7–12 June 2015). IEEE.
- 52 Krasin, I., Duerig, T., Alldrin, N. et al. (2016). Openimages: A Public Dataset for Large‐Scale Multi‐label and Multiclass Image Classification. Springer. https://github.com/openimages.
- 53 Brostow, G.J., Fauqueur, J., and Cipolla, R. (2008). Semantic object classes in video: a high‐definition ground truth database. Pattern Recognition Letters 30: 88–97.
- 54 Geiger, A., Lenz, P., and Urtasun, R. (2012). Are we ready for autonomous driving? The KITTI vision benchmark suite. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA (16–21 June 2012). IEEE.
- 55 Chen C., Seff A., Kornhauser A., and Xiao J. (2015). Deepdriving: learning affordance for direct perception in autonomous driving. In Proceedings of 15th IEEE International Conference on Computer Vision (ICCV2015),
- 56 Richter S. R., Vineet V., Roth S., and Koltun V. (2016). Playing for data: ground truth from computer games. In 14th European Conference on Computer Vision (ECCV 2016), Computer Vision and Pattern Recognition (cs.CV).
- 57 Cordts, M., Omran, M., Ramos, S. et al. (2016). The cityscapes dataset for semantic urban scene understanding. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA (27–30 June 2016). IEEE.
- 58 Ros, G., Sellart, L., Materzynska, J. et al. (2016). The synthia dataset: a large collection of synthetic images for semantic segmentation of urban scenes. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA (27–30 June 2016). IEEE.
- 59 Kim, J. and Park, C. (2017). End‐to‐end ego lane estimation based on sequential transfer learning for self‐driving cars. IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA (21–26 July 2017). IEEE.
- 60 Bolc, L. and Cytowski, J. (1992). Search Methods for Artificial Intelligence. London: Academic Press.