
IN THIS CHAPTER
Any attempt to secure an enterprise must be well thought out and planned. Ad-hoc security measures, although useful, will not lead to an enterprise being truly secure. Proper security is a complex ongoing process. Without proper preparation, any security program is going to fail because it will have gaps in its coverage. This chapter briefly examines essential components of an effective security program.
In security, two models or postures exist:
Reactive—. The reactive model is a largely historical animal. In it, administrators add security controls as needed, on a case-by-case basis. This model is typically used in response to security incidents, such as attackers cracking a machine because it didn’t have network access control.
Proactive—. The now preferred proactive model, this is where administrators perform risk analysis, establish stringent controls, and apply those controls enterprise-wide. No machine on this network can have connectivity until it first has network access control.
Reactive policies were once the norm, but changes in the business world rendered them inadequate. A good comparison is a country. As leader of a country, do you wait until you are attacked to have an army to defend yourself? If you decide to have a standing army, do you have training and advanced planning in place? Of course, you need a standing army that has been trained and some planning on how to defend the company in place. The same applies to your computer systems. Thus, your security program must be proactive.
To establish such a program, you must, at a minimum
A decade ago, most enterprises weren’t wired, or if they were, their networks were closed and had no Internet connectivity. The average security administrator’s universe, therefore, was limited. Her network supported few protocols, a limited application set, and known users.
Today this is no longer true. Modern computing has become ubiquitous. By default, every box on every network supports multiple protocols, thousands of applications, and potentially unlimited users, many that are (or can be) anonymous.
To appreciate how profoundly this climate affects an administrator’s responsibilities, consider this: Historically, few administrators had to understand workflow patterns or human process models because data rarely traversed networks as pervasively as it does today. Rather, in those golden, olden days, administrators needed only to understand where an enterprise’s valued assets were, and the measures to protect them.
Today, where is relative, because an organization’s data can exist in several places simultaneously. For example, how many times a day do you mail spreadsheets to multiple recipients? Of those recipients, how many are in-house, and how many operate from outside domains? Can you definitively say (at this moment) where your data is?
This new climate demands that contemporary security administrators understand more than merely data’s static locale and the tools to secure it. Security administrators must now grasp how their enterprise operates, and not just in general terms.
To that end, administrators now grapple with issues that once had limited security relevance, including the following:
Contractor relationships
Government regulations
Workflow patterns
Consider, for example, a security administrator at a hospital that falls under the Health Insurance Portability and Accountability Act (commonly called “HIPAA”). HIPAA imposes regulations and restrictions on qualified health care facilities regarding the transmission and storage of confidential patient data.
Two such restrictions are
Documents must have digital signatures or checksums
Transmissions must travel encrypted
On their face, such regulations seem straightforward enough. However, bringing a facility into compliance presents security administrators with unique and sometimes difficult problems. The divide between well-intentioned guidelines and practical application can be considerable, because information technology has limitations. To demonstrate this point, I offer two real-life scenarios, one for each of the aforementioned regulations.
Certain data, such as admission information, follow a patient through various hospital departments. Many departments use admission data to derive new documents, and by law, each such new document must carry a checksum. These conditions demand that the hospital administrator understand workflow patterns.
Many health care facilities, for example, now use digital duplicators that transmit pages via IP. That is, you create and scan a document in one office, and the network delivers copies to another (or several). This poses a unique problem, especially if the initiating software interfaces directly with duplicator hardware, and many such programs do.
If the document you broadcast this way is new, how do you derive its checksum and preserve that checksum’s relationship to the document? Where in that workflow pattern can you insert a checksum generation routine? Finally, until you do, must you resign yourself to manual checksum generation? What if your professional staff transmits and distributes 1,000 such documents daily?
Next, consider the encryption regulations. The hospital doesn’t do its own billing but instead outsources that task to a billing contractor. That contractor demands patient billing information in X12 format (plain text, essentially), and provides a gateway service that receives transmissions electronically over the network.
Even five years ago this scenario presented few concerns, but today HIPAA demands encrypted transmissions. Hence, the administrator must convene with the billing contractor’s security staff and establish a mutually acceptable encryption scheme, and until she does, each X12 transmission will violate government regulations. Further, she can’t develop and test the new scheme on production systems, for if she does, this activity can interrupt billing (a vital service).
Many enterprises, and not merely those in healthcare, face stringent regulations or policies such as HIPAA. Moreover, even those firms that escape regulatory guidelines face complicated workflow patterns that offer attackers innumerable opportunities.
Your first aim, therefore, is to understand your enterprise’s process model, and this may prove more difficult than it first seems. You may discover that no one in your enterprise has ever modeled its workflow patterns before, and you must do so yourself.
When we discuss process models and workflow patterns, what do we mean? In software circles, these terms conjure images of application phases, subroutines, stored procedures, and so forth. Most administrators and programmers have experience in these areas. However, a smaller number have never seen or drafted business-oriented process models. Because this issue is vital to your security program, we’ll quickly cover it here.
Business-oriented process models illustrate data paths as they relate to tasks vital to business operation. That is, business process models graphically show a given transaction’s workflow pattern, the personnel or automated systems that intervene during each phase, the decisions these individuals or systems can make, and every possible result.
For example, suppose your enterprise performs telephone sales. Each day, the database must distribute sales leads to sales personnel. In turn, sales personnel call those leads and make sales (you hope). If sales personnel do make a sale, they record that data somewhere, the system retrieves it, and custom applications track it. Finally, when a purchase order comes due, collectors bill clients and make attempts to collect. If clients pay, the system records this information.
Throughout that process (or, more esoterically, that life cycle) many things can happen—humans can make decisions, and upon such decisions, take action. Each decision can trigger different results, and those results can create, affect, transform, or destroy data. Moreover, each phase along the route will expose your enterprise’s data to different environments, and often each such environment will expose your data to unique risks.
What you want, in short, is a model showing a data element’s entire life cycle as it winds through your enterprise. After you can visualize this path, you’ll know what controls to institute and where, when, and how to use them.
In drafting that model, you’ll consider many issues, including the following:
How does a data element come into being?
Where does that genesis happen?
From there, where can the data go?
Along its route, who can access the data and how?
At what points along the route must you accrue accounting, auditing, or logging statistics?
At its final destination (presumably, a database), in what form must the data exist? Who can access it there? Who can change it and how?
To ascertain all this, you’ll interface with other individuals and departments, and this process can often take time. Don’t become discouraged, though. Mapping your firm’s process model is the most vital step you’ll take.
After you grasp your enterprise’s process model, you can perform risk analysis, and you begin by evaluating your firm’s security posture.
In doing so, consider the following issues:
Management awareness
Employee awareness
Security policies
Network security
Application security
Prior losses and security incidents
Incident tracking and response
These inquiries will tell you how vulnerable the enterprise is or was, what risks it faces, and the likelihood of future loss. Armed with this data, you can author a decent security proposal. However, even here, you’ll need to get creative.
Traditionally, such proposals revolved around cost-benefit analyses, and from those analyses, management decided what controls to institute. One popular formula was to evaluate annual losses against annual costs of security measures. That is, if real or projected losses did or were likely to exceed a specific security measure’s cost, the enterprise should deploy that security measure. Conversely, if the measure’s cost exceeded projected losses, the enterprise can survive without it.
These formulas, once staples of risk assessment, are likely outdated. Today, data doesn’t always have a concrete, identifiable value. In many cases, the data itself does not have an easily quanitifable valuable, but instead represents competitive advantage, prospective advantage, or other difficult-to-articulate benefits.
Rather, such cost-benefit analysis formulas are today more suited for calculating a firm’s disaster recovery costs (replacing hardware, software, and so on) than costs of security breaches.
NOTE
In some situations, such formulas are still appropriate. For example, let’s revisit our hospital security administrator. She has certain advantages in evaluating risk. HIPAA regulations assign specific monetary penalties for each violation. Hence, it’s easy to attach a concrete dollar value to a given security lapse. Such environments, however, are more exceptions than rules these days.
The key to identifying likely losses and affixing concrete values to them (if you can) is known as digital asset assessment.
When pondering the term asset identification, most IT folks think of asset management or asset tracking. This is because most (if not all) administrators have received, at one time or another, orders to catalog physical network assets, record serial numbers, and track what employee signed out what laptop and when.
Overt costs in such garden-variety asset tracking are obvious. An e-commerce system can consist of a dozen Web servers, several database servers, a merchant gateway, and supporting infrastructure equipment. Such a setup can run $400,000 in hardware. That’s a concrete, easily identifiable cost. Likewise, the software and network devices all have set book values you can easily calculate and depreciate.
A more difficult problem is to identify the costs that a site-wide outage might accrue, but given sufficient time, you can still skillfully juggle the numbers to derive a reasonably accurate forecast. Here, you’ll calculate hourly or daily revenue losses, costs of emergency response, technical support costs, and other costs unattached to any physical quantity or commodity.
Some costs are still more difficult to identify, though. Suppose your e-commerce initiative’s client records and purchasing trend data reside on a single database server. Again, the server’s value is obvious. But what happens when attackers compromise that server? What if they leak your data to the public? This can trigger other, less tangible but still critical costs: damaged consumer confidence, damaged industry reputation, or even legal liability.
Such costs are more difficult (and sometimes impossible) to forecast. Damaged strategic or financial partners, for example, might bring not only contract claims but also tort claims, and today, jury awards are sometimes inequitable, unreasonable, or inexplicable. Similarly, insurance companies may initially agree to defend you, and then midstream through a litigation procedure, refuse to go further, leaving you to bankroll your own defense.
Bookstores carry many asset identification titles that ponder how asset management relates to risk analysis, but few such books offer definitive formulas on forecasting “unforeseeable losses.” Instead, authors typically identify key digital assets and classify these as low, medium, and high-value items.
Most authors identify the following assets as high-value:
Customer data
Financial reports
Financial systems
Marketing strategies
Miscellaneous proprietary data
Payroll information
Research and development data
Sales information
Source code
Of these, you must choose what are most valuable, and only you can determine that (and then, only armed with a process model in hand). After you determine their relative values, you must next decide on what means you’ll use to protect them.
Many organizations begin their analysis at their perimeter and move inward, roughly simulating (what they perceive to be) an attacker’s entry point and ultimate trajectory. Organizations that adopt this posture typically identify their perimeter by equating it with a tangible, physical point in space. This point in space, more often than not, is their firewall.
This approach has merit from a network security standpoint, but also has pitfalls. For example:
Statistics indicate that internal security breaches far outweigh external breaches. For this reason, some administrators prefer to start at an enterprise’s core and work outward.
This “fortress mentality” sometimes concentrates human efforts telescopically on perimeter systems. This leads to an inverse relationship between security and network depth. That is, the deeper you travel into the network’s inner core, the less security controls you find. This results in a hard outer shell and a comparatively soft internal posture.
Not every enterprise operates in an exclusively horizontal environment, where frontal attacks comprise their sole risk. Some enterprises operate in vertical (or even parallel) environments, where frontal attacks take a back seat to other attack methodologies.
Often there are non-obvious ways to bypass the firewall. A couple of examples are modems and VPNs.
Finally, some enterprises simply can’t rely solely on the fortress posture because their business models depend on open, ubiquitous computing (a P2P file-sharing system, for example, with thousands of anonymous users).
Hence, during this phase, your enterprise’s process model plays a starring role. As you examine each possible phase or transformation a data element can traverse, you’ll find that data element deposited in widely varying environments. For each such environment that may pose different or unique risks, you must identify a protection scheme that meets its specific demands.
Unless you’re using an entirely Web-based solution that centralizes all data and processing, you’ll invariably find many environments along the process route that demand solutions for which no existing out-of-the-box cure exists. For this reason, you’ll initially benefit more from an education in prevailing security technologies (and schools of thought) than with specific vendor products.
Several reasons necessitate this:
Security vendors earn their daily bread by exploiting fear. Often, such vendors peddle quality products that nonetheless fail to address your specific needs. By knowing what technologies your network requires, you can cut through marketing smoke.
It’s more important that, at a glance, you have the capability to determine that a specific environment requires a proxy gateway (described in detail in Chapter 10), than that you need this or that commercial firewall product.
It’s vital that you understand why you need a given technology. A vendor might well sell you the correct or applicable tool, but as a security administrator, you must know how that product’s controls will help you, and what potential risks such a product presents.
When (and only when) you understand the risks inherent in each environment along the process path, you’ll next break risks into their respective categories. It’s here that you begin identifying solutions that have real relevance. During this process model phase, the data travels from your network to your partner’s, and therefore, you must encrypt it. Possible solutions include IPsec, SSH, and RSA, among others.
However, before you make final decisions on solutions, you first narrow your investigation’s scope even further. You do this by identifying and removing pre-existing system vulnerabilities, and here’s why: Risk management, security, and administration hinge much on efficiency. Commercial security solutions are expensive, and wherever possible, you should exploit pre-existing controls. Your administrative personnel likely already have proven experience with your firm’s platforms and their security controls. Exploit their knowledge wherever and whenever possible, because new products sometimes present steep learning curves.
The process of identifying and removing vulnerabilities differs from evaluating environmental risks along your process model’s route. In examining your process model, you seek to isolate human or business procedures that expose data to external risks (for example, where data must pass from one network to another safely, encrypted and protected against electronic eavesdropping). Such risks aren’t attributable to any particular weakness or flaw in your specific underlying system.
In contrast, the process of identifying and removing vulnerabilities focuses on your specific hardware, software, and network equipment. All of these elements likely harbor flaws, and not merely environmental conditions that incidentally expose data to risk. Instead you’ll look for software and hardware design errors, security holes, weak encryption algorithms, weak password storage procedures, bad application security policies, and so on.
Here, you seek several objectives:
Identify and eliminate historical hardware and software security issues to achieve a baseline from which to work (for example, determine which systems are patched, which aren’t, and remedy this where necessary).
Identify and eliminate application security policies that invite security breaches (for example, install proactive password checking so that even at an application level, your security remains proactive).
Identify weaknesses for which infrastructure vendors have no immediate, viable solution (so you can find or recommend alternatives).
Only after you take these steps can you determine what specific security solutions and products (hardware, software, and so on) you need to harden your enterprise. Like all Maximum Security titles, this edition both lists and provides (on the accompanying CD-ROM) many security assessment tools to assist you in this phase.
From all this data (risk assessment, digital assets, your enterprise’s process model, risky environments, application security policies, and inherent platform weaknesses), you can generate the two cardinal documents or roadmap elements:
Your security proposal—. This is a document describing what your firm must do to achieve baseline security, the costs involved, and what tools, modalities, and, if necessary, services you’ll require.
Your forward-thinking, proactive security plan—. This is a document that establishes what tools, policies, procedures, and postures your organization must deploy to sustain security.
Your security proposal will develop dynamically as you conduct your investigation. Your proactive security plan, however, emerges only after you finish your investigation. Its main body will consist of proactive policies, the most important of which focus on internal system standardization. Let’s discuss that now.
A natural by-product of your investigation is a transparent look at what technologies are vital to your enterprise. This will emerge without much effort on your part. As you interface with each department or division in your process model analysis, folks there will tell you (perhaps in more detail than you’d like) what applications they need to satisfy their responsibilities.
This data provides you with a basis on which to classify departments or divisions by their respective functions, and within that framework, identify indispensable technologies for them. After you know this, you can compile an approved application set—that is, you can develop a generic must-have list in topology, platforms, services, protocols, and applications on a department-by-department basis.
This, too, is more complicated than it initially seems, because many firms deploy widely disparate technologies. IT divisions today often commonly support Solaris, Windows NT, NetWare, Linux, HP/UX, AIX, AS/400, and OS/390-based systems, all in the same enterprise, and sometimes, in the same divisions. However, the totality of systems will eventually emerge as a fixed quantity (even if it’s wide in scope).
After you have this information, you begin the standardization process and establish the following:
What topology, platforms, services, protocols, and applications each department needs
The security issues common to each department
Based on these variables, you next establish standard installation, deployment, policy, security, auditing, and application settings on each respective platform or infrastructure system. This provides you with a template of sorts, and that template should explicitly specify the following:
Approved applications—. These are applications vital to the enterprise. You add applications not on this list (chatting and messaging systems that employees don’t deploy except for personal use, for example) to your disapproved applications list.
Disapproved applications—. These are superfluous applications you can neither support nor secure, and which don’t contribute to your enterprise’s productivity or security.
Installation options—. Most operating systems and service applications now ship with dozens of features your enterprise likely doesn’t need (and which invite security breaches). Prohibit such unneeded features.
Directory, filesystem, and application resource layouts—. These are configuration options indispensable to your enterprise. For example, perhaps every user in accounting needs access to the same shared-out volume.
Account security policies—. Certain departments will require specific security policies. For example, divisions that employ part-time, temporary, or consulting-basis personnel have high turnover rates. These departments will probably demand more stringent password lockout, audit, and regeneration policies than anchor divisions.
Network security policies—. Certain network resources are more sensitive than others. For some, you’ll deploy deep, stringent, or fanatical logging, auditing, and authentication procedures. For others, you may establish less stringent guidelines.
These templates not only standardize and simplify your security posture enterprise-wide, they also provide you with an immediate upgrade, restoration, or recovery path (or an easy way to duplicate them, such as when you add a station to a given department). Finally, they provide a baseline to which all personnel must adhere, so they eliminate unknown quantities or qualities. This fosters much easier and more efficient security management.
Other issues your proactive security plan’s policies should account for are
Acceptable usage
Data value classification
Data disclosure and destruction
Roles and responsibilities
Change control
Business continuity plan
NOTE
Business continuity planning is the process by which you can plan on how to continue running your business if something bad happens, such as a tornado or a terrorist attack. In the past, the term disaster recovery was used to mean the same thing, but it has fallen out of fashion.
You’ll naturally need management approval for your plan and policies, and that’s why you must document all the aforementioned things scrupulously. You must also incorporate two final features into your proposal: your incident response policy and personnel education.
Incident response policy articulates what steps security personnel must take when a breach occurs. Issues your proposal should cover in this department include the following:
Taxonomy of security incidents—. This articulates all known security breach types.
Security incident risk classification—. This articulates the risk level for each type of security breach.
Incident team roster—. This identifies who (besides yourself) is responsible for responding to security incidents, and who’s authorized to direct such activity and make decisions.
Incident response path—. This describes, in general terms, what acts security personnel should undertake in sequence.
Escalation protocol—. This indicates time periods or events after which security personnel take increasingly proactive, hands-on, or critical (emergency) procedures.
Reporting—. This describes how, when, to whom, and in what intervals security personnel provide on-the-scene updates.
Finally, we reach the issue of personnel education. Here, you’ll encounter the most resistance, but you must nonetheless include education in your proposal. You’ll doubtless find creative ways to express the need for security education, but ensure that you do the following:
Inform all employees of security policies (such as AUPs, or Acceptable Use Policies).
Embark on an awareness campaign. This will help the general user population understand threats and reaffirm that your organization has an information security effort afoot.
Enlist an executive sponsor willing to publish memos, issue statements, and otherwise support you in establishing and maintaining aggressive security practices.
Introduce responsibility matrices that identify specific security responsibilities, including those expected of average employees (such as not taping post-it notes with passwords to their monitors).
Now that we’ve enumerated all the aforementioned granularly, let’s quickly look at the entire process. Figure 1.1 illustrates a fast-track cycle to an effective proactive security plan.
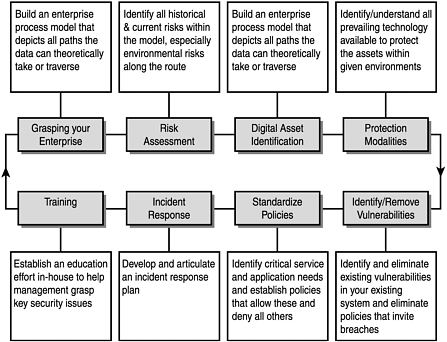
We’ll proceed hereafter with a very small model, a mere division of an enterprise, in a telephone sales operation. In that operation, a sales department employee’s responsibilities and data access are limited to examining and calling on leads and reporting pitch results, as shown in Figure 1.2.
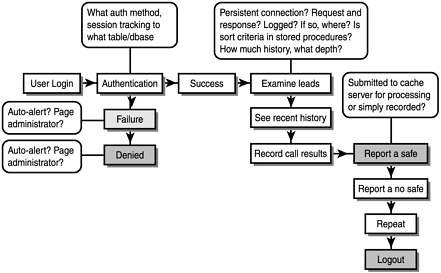
The sales representative performs his duties from a workstation bay that other sales personnel also use, and this bay is connected to larger system. Hence, even in the salesperson’s relatively simple process model, he ties into a superceding life cycle. Your chief objective, then, is to ascertain the environmental risks that exist along that life cycle’s route, and where these occur. To do so, you examine all technology systems within that cycle, illustrated in Figure 1.3.
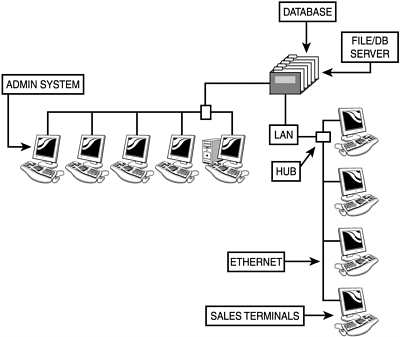
Figure 1.3, even at a glance, reveals several environmental risks.
First, salespeople share bandwidth at adjacent terminals, drawing connectivity from a simple Ethernet strung to a hub. Hence, wily salespersons could install electronic eavesdropping devices to intercept competing sales personnel’s leads. Moreover, because the file and database server’s connectivity comes from the same source, they can even sniff database traffic. (This probably calls for a switch-based solution coupled with encrypted traffic.)
Next, the system survives on a single database server. Access to this server—for all departments—is direct, and no redundancy exists. One good attack is all it takes: a skilled attacker who had breached the system’s security could destroy your database. Here, perhaps you would consider shared-out volumes from a RAID that snapshots hourly, data replication (if your RDBMS supports it), or other measures.
Third, the model as-is doesn’t specify what type of network device ties administration into the database. Unknown quantities such as this obstruct your ability to accurately assess risk. Given these facts, you might have to physically go to the network operations center and ascertain that device’s type, make, model, and so on.
Additionally, at some point, you must ascertain what protocols users use to access the database. This can be anything (simple Ethernet, SQL*Net, TCP/IP, and so on), but whatever it is will bear on security. Moreover, you must ascertain what authentication methods the database supports. This will give clues as to whether you’ll need additional third-party or native authentication support (and so it goes).
Also, by examining such a model, you can identify where your digital assets are, where they go, who can access them, and so forth. Here, you can physically notate your most valuable digital assets, calculate their exposure risk, and determine where you should concentrate your efforts.
After assaying all this, you next turn to determining the system’s current vulnerabilities (perhaps with system assessment tools). Concurrent with this, you catalog patch and maintenance histories for all integrated systems, review their security policies, and update or tighten these where necessary.
Based on your findings, you establish your guidelines and policies for each class of station or system, and enforce these policies system-wide. This establishes an across-the-board, baseline security posture.
And finally, you establish an incident response policy based on what risks remain, and institute an education program.
This chapter is not exhaustive. Instead, it merely offers a bare bones, fast-track route to a proactive security program. For more in-depth information, see Chapter 19, “Network Architecture Considerations,” and Chapter 25, “Policies, Procedures, and Enforcement.” In the interim, we’ll move on to the next chapter, which highlights important risks.