
Customer satisfaction is the ultimate validation of quality. Product quality and customer satisfaction together form the total meaning of quality. Indeed, what differentiates total quality management (TQM) from the sole focus on product quality in traditional quality engineering is that TQM is aimed at long-term business success by linking quality with customer satisfaction. In this modern-day quality era, enhancing customer satisfaction is the bottom line of business success. With ever-increasing market competition, customer focus is the only way to retain the customer base and to expand market share. Studies show that it is five times more costly to recruit a new customer than it is to keep an old customer, and that dissatisfied customers tell 7 to 20 people about their experiences, while satisfied customers tell only 3 to 5.
As a result of TQM, more and more companies are conducting surveys to measure their customers’ satisfaction. In this chapter we discuss customer satisfaction surveys and the analysis of survey data. As an example, we describe an analysis of the relationship between overall customer satisfaction and satisfaction with specific attributes for a software product. In the last section we discuss the question of how good is good enough.
There are various ways to obtain customer feedback with regard to their satisfaction levels with the product(s) and the company. For example, telephone follow-up regarding a customer’s satisfaction at a regular time after the purchase is a frequent practice by many companies. Other sources include customer complaint data, direct customer visits, customer advisory councils, user conferences, and the like. To obtain representative and comprehensive data, however, the time-honored approach is to conduct customer satisfaction surveys that are representative of the entire customer base.
There are three common methods to gather survey data: face-to-face interviews, telephone interviews, and mailed questionnaires (self-administered). The personal interview method requires the interviewer to ask questions based on a prestructured questionnaire and to record the answers. The primary advantage of this method is the high degree of validity of the data. Specifically, the interviewer can note specific reactions and eliminate misunderstandings about the questions being asked. The major limitations are costs and factors concerning the interviewer. If not adequately trained, the interviewer may deviate from the required protocol, thus introducing biases into the data. If the interviewer cannot maintain neutrality, any statement, movement, or even facial expression by the interviewer could affect the response. Errors in recording the responses could also lead to erroneous results.
Telephone interviews are less expensive than face-to-face interviews. Different from personal interviews, telephone interviews can be monitored by the research team to ensure that the specified interview procedure is followed. The computer-aided approach can further reduce costs and increase efficiency. Telephone interviews should be kept short and impersonal to maintain the interest of the respondent. The limitations of this method are the lack of direct observation, the lack of using exhibits for explanation, and the limited group of potential respondents—those who can be reached by telephone.
The mailed questionnaire method does not require interviewers and is therefore less expensive. However, this savings is usually at the expense of response rates. Low response rates can introduce biases to the data because if the respondents are different from the nonrespondents, the sample will not be representative of the population. Nonresponse can be a problem in any method of surveys, but the mailed questionnaire method usually has the lowest rate of response. For this method, extreme caution should be used when analyzing data and generalizing the results. Moreover, the questionnaire must be carefully constructed, validated, and pretested before final use. Questionnaire development requires professional knowledge and experience and should be dealt with accordingly. Texts on survey research methods provide useful guidelines and observations (e.g., Babbie, 1986).
Figure 14.1 shows the advantages and disadvantages of the three survey methods with regard to a number of attributes.
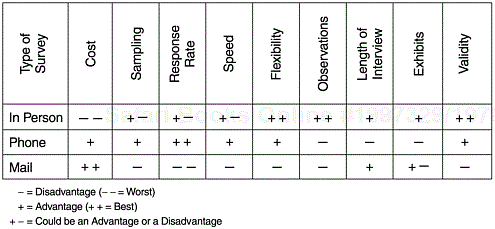
When the customer base is large, it is too costly to survey all customers. Estimating the satisfaction level of the entire customer population through a representative sample is more efficient. To obtain representative samples, scientific probability sampling methods must be used. There are four basic types of probability sampling: simple random sampling, systematic sampling, stratified sampling, and cluster sampling.
If a sample of size n is drawn from a population in such a way that every possible sample of size n has the same chance of being selected, the sampling procedure is called simple random sampling. The sample thus obtained is called a simple random sample (Mendenhall et al., 1971). Simple random sampling is often mistaken as convenient sampling or accidental sampling for which the investigator just “randomly” and conveniently selects individuals he or she happens to come across. The latter is not a probability sample. To take a simple random sample, each individual in the population must be listed once and only once. Then some mechanical procedure (such as using a random number table or using a random number-generating computer program) is used to draw the sample. To avoid repeated drawing of one individual, it is usually more convenient to sample without replacement. Notice that on each successive draw the probability of an individual being selected increases slightly because there are fewer and fewer individuals left unselected from the population. If, on any given draw, the probabilities are equal of all remaining individuals being selected, then we have a simple random sample.
Systematic sampling is often used interchangeably with simple random sampling. Instead of using a table of random numbers, in systematic sampling one simply goes down a list taking every kth individual, starting with a randomly selected case among the first k individuals. (k is the ratio between the size of the population and the size of the sample to be drawn. In other words, 1/k is the sampling fraction.) For example, if we wanted to draw a sample of 500 customers from a population of 20,000, then k is 40. Starting with a random number between 1 and 40 (say, 23), then we would draw every fortieth on the list (63, 103, 143, . . . ).
Systematic sampling is simpler than random sampling if a list is extremely long or a large sample is to be drawn. However, there are two types of situations in which systematic sampling may introduce biases: (1) The entries on the list may have been ordered so that a trend occurs and (2) the list may possess some cyclical characteristic that coincides with the k value. For example, if the individuals have been listed according to rank and salary and the purpose of the survey is to estimate the average salary, then two systematic samples with different random starts will produce systematic differences in the sample means. As another example for bias (2), suppose in a housing development every twelfth dwelling unit is a corner unit. If the sampling fraction happens to be 1/12 (k = 12), then one could obtain a sample either with all corner units or no corner units depending on the random start. This sample could be biased. Therefore, the ordering of a list should be examined before applying systematic sampling. Fortunately, neither type of problem occurs frequently in practice, and once discovered, it can be dealt with accordingly.
In a stratified sample, we first classify individuals into nonoverlapping groups, called strata, and then select simple random samples from each stratum. The strata are usually based on important variables pertaining to the parameter of interest. For example, customers with complex network systems may have a set of satisfaction criteria for software products that is very different from those who have standalone systems and simple applications. Therefore, a stratified sample should include customer type as a stratification variable.
Stratified sampling, when properly designed, is more efficient than simple random sampling and systematic sampling. Stratified samples can be designed to yield greater accuracy for the same cost, or for the same accuracy with less cost. By means of stratification we ensure that individuals in each stratum are well represented in the sample. In the simplest design, one can take a simple random sample within each stratum. The sampling fractions in each stratum may be equal (proportional stratified sampling) or different (disproportional stratified sampling). If the goal is to compare subpopulations of different sizes, it may be desirable to use disproportional stratified sampling. To yield the maximum efficiency for a sample design, the following guidelines for sample size allocation can be used: Make the sampling fraction for each stratum directly proportional to the standard deviation within the stratum and inversely proportional to the square root of the cost of each case in the stratum.
In stratified sampling we sample within each stratum. Sometimes it is advantageous to divide the population into a large number of groups, called clusters, and to sample among the clusters. A cluster sample is a simple random sample in which each sampling unit is a cluster of elements. Usually geographical units such as cities, districts, schools, or work plants are used as units for cluster sampling. Cluster sampling is generally less efficient than simple random sampling, but it is much more cost effective. The purpose is to select clusters as heterogeneous as possible but which are small enough to cut down on expenses such as travel costs involved in personal interviews. For example, if a company has many branch offices throughout the country and an in-depth face-to-face interview with a sample of its customers is desired, then a cluster sample using branch offices as clusters (of customers) may be the best sampling approach.
For any survey, the sampling design is of utmost importance in obtaining unbiased, representative data. If the design is poor, then despite its size, chances are the sample will yield biased results. There are plenty of real-life examples in the literature with regard to the successes and failures of sampling. The Literary Digest story is perhaps the most well known. The Literary Digest, a popular magazine in the 1930s, had established a reputation for successfully predicting winners of presidential elections on the basis of “straw polls.” In 1936 the Digest’s history of successes came to a halt when it predicted a 3-to-2 victory for the Republican nominee, Governor Alf Landon, over the incumbent Franklin Roosevelt. As it turned out, Roosevelt won by a landslide, carrying 62% of the popular votes and 46 of the 48 states. The magazine suspended publication shortly after the election.
For the prediction, the Digest chose a sample of ten million persons originally selected from telephone listings and from the list of its subscribers. Despite the huge sample, the prediction was in error because the sample was not representative of the voting population. In the 1930s more Republicans than Democrats had telephones. Furthermore, the response rate was very low, about 20% to 25%. Therefore, the responses obtained from the poll and used for the prediction were not representative of those who voted (Bryson, 1976).
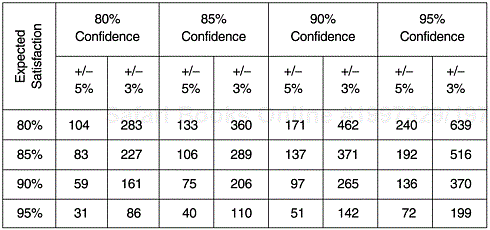
How large a sample is sufficient? The answer to this question depends on the confidence level we want and the margin of error we can tolerate. The higher the level of confidence we want from the sample estimate, and the smaller the error margin, the larger the sample we need, and vice versa. For each probability sampling method, specific formulas are available for calculating sample size, some of which (such as that for cluster sampling) are quite complicated. The following formula is for the sample size required to estimate a population proportion (e.g., percent satisfied) based on simple random sampling:
where
|
N |
= population size |
|
Z |
= Z statistic from normal distribution:
for 80% confidence level, Z = 1.28 for 85% confidence level, Z = 1.45 for 90% confidence level, Z = 1.65 for 95% confidence level, Z = 1.96 |
|
p |
= estimated satisfaction level |
|
B |
= margin of error |
A common misconception with regard to sample size is that the size of a sample must be a certain percentage of the population in order to be representative; in fact, the power of a sample depends on its absolute size. Regardless of the size of its population, the larger the sample the smaller its standard deviation will become and therefore the estimate will be more stable. When the sample size is up to a few thousands, it gives satisfactory results for many purposes, even if the population is extremely large. For example, sample sizes of national fertility surveys (representing all women of childbearing age for the entire nation) in many countries are in the range of 3,000 to 5,000.
Figure 14.2 illustrates the sample sizes for 10,000 customers for various levels of confidence with both 5% and 3% margins of error. Note that the required sample size decreases as the customer satisfaction level increases. This is because the larger the p value, the smaller its variance, p(1 – p) = pq. When an estimate for the satisfaction level is not available, using a value of 50% (p = 0.5) will yield the largest sample size that is needed because pq is largest when p = q.
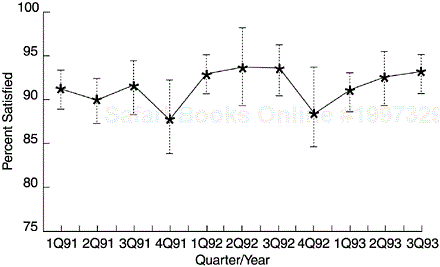
The five-point satisfaction scale (very satisfied, satisfied, neutral, dissatisfied, and very dissatisfied) is often used in customer satisfaction surveys. The data are usually summarized in terms of percent satisfied. In presentation, run charts or bar charts to show the trend of percent satisfied are often used. We recommend that confidence intervals be formed for the data points so that the margins of error of the sample estimates can be observed immediately (Figure 14.3).
Traditionally, the 95% confidence level is used for forming confidence intervals and the 5% probability (p value) is used for significance testing. This p value means that if the true difference is not significant, the chance we wrongly conclude that the difference is significant is 5%. Therefore, if a difference is statistically significant at the 5% level, it is indeed very significant. When analyzing customer satisfaction, it is not necessary to stick to the traditional significance level. If the purpose is to be more sensitive in detecting changes in customers’ satisfaction levels, or to trigger actions when a significant difference is observed, then the 5% level is not sensitive enough. Based on our experience, a p value as high as 20%, or a confidence level of 80%, is still reasonable—sensitive enough to detect a substantial difference, yet not giving false alarms when the difference is trivial.
Although percent satisfied is perhaps the most used metric, some companies, such as IBM, choose to monitor the inverse, the percent nonsatisfied. Nonsatisfied includes the neutral, dissatisfied, and very dissatisfied in the five-point scale. The rationale to use percent nonsatisfied is to focus on areas that need improvement. This is especially the case when the value of percent satisfied is quite high. Figure 12.3 in Chapter 12 shows an example of IBM Rochester’s percent nonsatisfied in terms of CUPRIMDA (capability, usability, performance, reliability, installability, maintainability, documentation/information, and availability) categories and overall satisfaction.
The major advantage of monitoring customer satisfaction with specific attributes of the software, in addition to overall satisfaction, is that such data provide specific information for improvement. The profile of customer satisfaction with those attributes (e.g., CUPRIMDA) indicates the areas of strength and weakness of the software product. One easy mistake in customer satisfaction analysis, however, is to equate the areas of weakness with the priority of improvement, and to increase investment to improve those areas. For instance, if a product has low satisfaction with documentation (D) and high satisfaction with reliability (R), that does not mean that there is no need to continually improve the product’s reliability and that the first priority of the development team is to improve documentation. Reliability may be the very reason the customers decide to buy this product and that customers may expect even further improvement. On the other hand, customers may not like the product’s documentation but may find it tolerable given other considerations. To answer the question on priority of improvement, therefore, the subject must be looked at in the broader context of overall customer satisfaction with the product. Specifically, the correlations of the satisfaction levels of specific attributes with overall satisfaction need to be examined. After all, it is the overall satisfaction level that the software developer aims to maximize; it is the overall satisfaction level that affects the customer’s purchase decision.
Here we describe an example of analyzing the relationship between satisfaction level with specific attributes and overall satisfaction for a hypothetical product. For this product, data are available on the UPRIMD parameters and on availability (A). The purpose of the analysis is to determine the priority for improvement by assessing the extent to which each of the UPRIMD-A parameters affects overall customer satisfaction. The sample size for this analysis is 3,658. Satisfaction is measured by the five-point scale ranging from very dissatisfied (1) to very satisfied (5).
To achieve the objectives, we attempted two statistical approaches: least-squares multiple regression and logistic regression. In both approaches overall customer satisfaction is the dependent variable, and satisfaction levels with UPRIMD-A are the independent variables. The purpose is to assess the correlations between each specific attribute and overall satisfaction simultaneously. For the ordinary regression approach, we use the original five-point scale. The scale is an ordinal variable and data obtained from it represent a truncated continuous distribution. Sensitivity research in the literature, however, indicates that if the sample size is large (such as in our case), violation of the interval scale and the assumption of Gaussian distribution results in very small bias. In other words, the use of ordinary regression is quite robust for the ordinal scale with large samples.
For the logistic regression approach, we classified the five-point scale into a dichotomous variable: very satisfied and satisfied (4 and 5) versus nonsatisfied (1, 2, and 3). Categories 4 and 5 were recoded as 1 and categories 1, 2, and 3 were recoded as 0. The dependent variable, therefore, is the odds ratio of satisfied and very satisfied versus nonsatisfied. The odds ratio is a measurement of association that has been widely used for categorical data analysis. In our application it approximates how much more likely customers will be positive in overall satisfaction if they were satisfied with specific UPRIMD-A parameters versus if they were not. For instance, let customers who were satisfied with the performance of the system form a group and those not satisfied with the performance form another group. Then an odds ratio of 2 indicates that the overall satisfaction occurs twice as often among the first group of customers (satisfied with the performance of the system) than the second group. The logistic model in our analysis, therefore, is as follows:
The correlation matrix, means, and standard deviations are shown in Table 14.1. Two types of means are shown: the five-point scale and the 0–1 scale. Means for the latter reflect the percent satisfaction level (e.g., overall satisfaction is 85.5% and satisfaction with reliability is 93.8%). Among the parameters, availability and reliability have the highest satisfaction levels, whereas documentation and installability have the lowest.
Table 14.1. Correlation Matrix, Means, and Standard Deviations
|
Overall |
U |
P |
R |
I |
M |
D |
A | |
|---|---|---|---|---|---|---|---|---|
|
Overall | ||||||||
|
U—usability |
.61 | |||||||
|
P—performance |
.43 |
.46 | ||||||
|
R—reliability |
.63 |
.56 |
.42 | |||||
|
I—installability |
.51 |
.57 |
.39 |
.47 | ||||
|
M—maintainability |
.40 |
.39 |
.31 |
.40 |
.38 | |||
|
D—documentation |
.45 |
.51 |
.34 |
.44 |
.45 |
.35 | ||
|
A—availability |
.39 |
.39 |
.52 |
.46 |
.32 |
.28 |
.31 | |
|
Mean |
4.20 |
4.18 |
4.35 |
4.41 |
3.98 |
4.15 |
3.97 |
4.57 |
|
Standard Deviation |
.75 |
.78 |
.75 |
.66 |
.90 |
.82 |
.89 |
.64 |
|
% SAT |
85.50 |
84.10 |
91.10 |
93.80 |
75.30 |
82.90 |
73.30 |
94.50 |
As expected, there is moderate correlation among the UPRIMD-A parameters. Usability with reliability, installability, and documentation, and performance with availability are the more notable ones. In relation to overall satisfaction, reliability, usability, and installability have the highest correlations.
Results of the multiple regression analysis are summarized in Table 14.2. As indicated by the p values, all parameters are significant at the 0.0001 level except the availability parameter. The total variation of overall customer satisfaction explained by the seven parameters is 52.6%. In terms of relative importance, reliability, usability, and installability are the highest, as indicated by the t value. This finding is consistent with what we observed from the simple correlation coefficients in Table 14.1. Reliability being the most significant variable implies that although customers are quite satisfied with the software’s reliability (93.8%), reliability is still the most determining factor for achieving overall customer satisfaction. In other words, further reliability improvement is still demanded. For usability and installability, the current low and moderate levels of satisfaction, together with the significance finding, really pinpoint the need for drastic improvement.
More interesting observations can be made on documentation and availability. Although being the lowest satisfied parameter, intriguingly, documentation’s influence on overall satisfaction is not strong. This may be because customers have become more tolerant with documentation problems. Indeed, data from software systems within and outside IBM often indicate that documentation/information usually receive the lowest ratings among specific dimensions of a software product. This does not mean that one doesn’t have to improve documentation; it means that documentation is not as sensitive as other variables when measuring its effects on the overall satisfaction of the software. Nonetheless, it still is a significant variable and should be improved.
Table 14.2. Results of Multiple Regression Analysis
|
Variable |
Regression Coefficient (Beta) |
t value |
Significance Level (p Value) |
|---|---|---|---|
|
R—reliability |
.391 |
21.4 |
.0001 |
|
U—usability |
.247 |
15.2 |
.0001 |
|
I—installability |
.091 |
7.0 |
.0001 |
|
P—performance |
.070 |
4.6 |
.0001 |
|
M—maintainability |
.067 |
5.4 |
.0001 |
|
D—documentation |
.056 |
4.5 |
.0001 |
|
A—availability |
.022 |
1.2 |
.22 (not significant) |
Availability is the least significant factor. On the other hand, it has the highest satisfaction level (94.5%, average 4.57 in the five-point scale).
Results of the logistic regression model are shown in Table 14.3. The most striking observation is that the significance of availability in affecting customer satisfaction is in vivid contrast to findings from the ordinary regression analysis, as just discussed. Now availability ranks third, after reliability and usability, in affecting overall satisfaction. The difference observed from the two models lies in the difference in the scaling of the dependent and independent variables in the two approaches. Combining the two findings, we interpret the data as follows:
Availability is not very important in influencing the average shift in overall customer satisfaction from one level to the next (from dissatisfied to neutral, from neural to satisfied, etc.).
However, availability is very important in affecting whether customers are satisfied versus nonsatisfied.
Therefore, availability is a sensitive factor in customer satisfaction and should be improved despite its level of high satisfaction.
Because the dependent variable of the logistic regression model (satisfied versus nonsatisfied) is more appropriate for our purpose, we use the results of the logistic model for the rest of our example.
The odds ratios indicate the relative importance of the UPRIMD-A variables in the logistics model. That all ratios are greater than 1 means that each UPRIMD-A variable has a positive impact on overall satisfaction, the dependent variables. Among them, reliability has the largest odds ratio, 14.4. So the likelihood of overall satisfaction is much higher for customers who are satisfied with reliability than for those who aren’t. On the other hand, documentation has the lowest odds ratio, 1.4. This indicates that the impact of documentation on overall satisfaction is not very strong, but there is still a positive effect.
Table 14.3. Results of Logistic Regression Analysis
|
Variable |
Regression Coefficient (Beta) |
Chi Square |
Significance Level (p Value) |
Odds Ratio |
|---|---|---|---|---|
|
R—reliability |
1.216 |
138.6 |
<.0001 |
11.4 |
|
U—usability |
.701 |
88.4 |
<.0001 |
4.1 |
|
A—availability |
.481 |
16.6 |
<.0001 |
2.6 |
|
I—installability |
.410 |
33.2 |
<.0001 |
2.3 |
|
M—maintainability |
.376 |
26.2 |
<.0001 |
2.1 |
|
P—performance |
.321 |
14.3 |
.0002 |
1.9 |
|
D—documentation |
.164 |
5.3 |
.02 |
1.4 |
Table 14.4 presents the probabilities for customers being satisfied depending on whether or not they are satisfied with the UPRIMD-A parameters. These conditional probabilities are derived from the earlier logistic regression model. When customers are satisfied with all seven parameters, chances are they are 96.32% satisfied with the overall software product. From row 2 through row 8, we show the probabilities that customers will be satisfied with the software when they are not satisfied with one of the seven UPRIMD-A parameters, one at a time. The drop in probabilities in row 2 through row 8 compared with row 1 indicates how important that particular parameter is to indicate whether customers are satisfied. Reliability (row 6), usability (row 8), and availability (row 2), in that order, again, are the most sensitive parameters. Data in rows 9 through 16 show the reverse view of rows 1 through 8: the probabilities that customers will be satisfied with the software when they are satisfied with one of the seven parameters, one at a time. This exercise, in fact, is a confirmation of the odds ratios in Table 14.3.
Table 14.4. Conditional Probabilities
|
Row |
P(Y=1/X) |
U |
P |
R |
I |
M |
D |
A |
Frequency |
|---|---|---|---|---|---|---|---|---|---|
|
Y = 1: satisfied, Y = 0: nonsatisfied; X: the UPRIMDA vector | |||||||||
|
1 |
.9632 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1632 |
|
2 |
.9187 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
14 |
|
3 |
.9552 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
267 |
|
4 |
.9331 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
155 |
|
5 |
.9287 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
212 |
|
6 |
.7223 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
12 |
|
7 |
.9397 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
42 |
|
8 |
.8792 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
47 |
|
9 |
.0189 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
20 |
|
10 |
.0480 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
8 |
|
11 |
.0260 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
2 |
|
12 |
.0392 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
9 |
|
13 |
.0132 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
|
14 |
.1796 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
12 |
|
15 |
.0353 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
4 |
|
16 |
— |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
By now we have a good understanding of how important each UPRIMD-A variable is in terms of affecting overall customer satisfaction in the example. Now let us come back to the initial question of how to determine the priority of improvement among the specific quality attributes. We propose the following method:
Determine the order of significance of each quality attribute on overall satisfaction by statistical modeling (such as the regression model and the logistic model in the example).
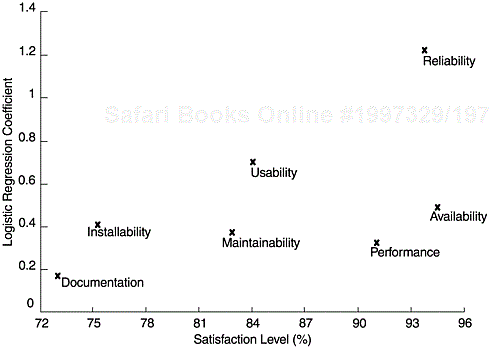
Plot the coefficient of each attribute from the model (Y-axis) against its satisfaction level (X-axis).
Use the plot to determine priority by
going from top to bottom, and
going from left to right, if the coefficients of importance have the same values.
To illustrate this method based on our example, Figure 14.4 plots the estimated logistic regression coefficients against the satisfaction level of the variable. The Y-axis represents the beta values and the X-axis represents the satisfaction level. From the plot, the order of priority for improvement is very clear: reliability, usability, availability, installability, maintainability, performance, and documentation. As this example illustrates, it is useful to use multiple methods (including scales) to analyze customer satisfaction data—so as to understand better the relationships hidden beneath the data. This is exemplified by our seemingly contradictory findings on availability from ordinary regression and logistic regression models.
Our example focuses on the relationships between specific quality attributes and overall customer satisfaction. There are many other meaningful questions that our example does not address. For example, what are the relationships among the specific quality attributes (e.g., CUPRIMDA) in a cause-and-effect manner? What variables other than specific quality attributes, affect overall customer satisfaction? For instance, in our regression analysis, the R2 is 52.8%. What are the factors that may explain the rest of the variations in overall satisfaction? Given the current level of overall customer satisfaction, what does it take to improve one percentage point (in terms of CUPRIMD-A and other factors)?
To seek answers to such questions, apparently a multitude of techniques is needed for analysis. Regardless of the analysis to be performed, it is always beneficial to consider issues in measurement theory, such as those discussed in Chapter 3, whenever possible.
Thus far our discussion on customer satisfaction has been product oriented—satisfaction with the overall software and with specific attributes. A broader scope of the subject deals with customers’ overall satisfaction with the company. This broad definition of customer satisfaction includes a spectrum of variables in addition to the quality of the products. For instance, in their study of the customers’ view model with regard to IBM Rochester, Hoisington and associates (Hoisington et al., 1993; Naumann and Hoisington, 2001) found that customers’ overall satisfaction and loyalty is attributed to a set of common attributes of the company (as perceived by the customers) and satisfaction levels with specific dimensions of the entire company. The common attributes include ease of doing business with, partnership, responsiveness, knowledge of customer’s business, and the company’s being customer driven. The key dimensions of satisfaction about the company include technical solutions, support and service, marketing, administration, delivery, and company image. The dimension of technical solutions includes product quality attributes. In the following, we list several attributes under each dimension:
Technical solutions: quality/reliability, availability, ease of use, pricing, installation, new technology
Support and service: flexible, accessible, product knowledge
Marketing: solution, central point of contact, information
Administration: purchasing procedure, billing procedure, warranty expiration notification
Delivery: on time, accurate, postdelivery process
Company image: technology leader, financial stability, executives image
It is remarkable that in Hoisington’s customer view model, company image is one of the dimensions of customer satisfaction. Whether this finding holds true in other cases remains to be seen. However, this finding illustrates the importance of both a company’s actual performance and how it is perceived with regard to customer satisfaction.
It is apparent that customer satisfaction at both the company level and the product level needs to be analyzed and managed. Knowledge about the former enables a company to take a comprehensive approach to total quality management; knowledge about the latter provides specific clues for product improvements.
Yet another type of analysis centers on why customers choose a company’s products over other companies’, and vice versa. This kind of analysis requires information that is not available from regular customer satisfaction surveys, be they product level or company level. It requires data about customers’ decision making for purchases and requires responses from those who are not the company’s current customers as well as those who are. This type of analysis, albeit difficult to conduct, is worthwhile because it deals directly with the issue of gaining new customers to expand the customer base.
How much customer satisfaction is good enough? Of course, the long-term goal should be 100%—total customer satisfaction. However, there are specific business questions that need better answers. Should my company invest $2,000,000 to improve satisfaction from 85% to 90%? Given that my company’s customer satisfaction is at 95%, should I invest another million dollars to improve it or should I do this later?
The key to answering questions such as these lies in the relationship between customer satisfaction and market share. The basic assumption is that satisfied customers continue to purchase products from the same company and dissatisfied customers will buy from other companies. Therefore, as long as market competition exists, customer satisfaction is key to customer loyalty. Even if a company has no direct competitors, customers may purchase substitute products if they are dissatisfied with that company’s products. Even in monopoly markets, customer dissatisfaction encourages the development and emergence of competition. Studies and actual cases in business have lent strong support to this assumption.
Assuming that satisfied customers will remain customers of the company, Babich (1992) studied the “how good is good enough” question based on a simplified model of customer satisfaction and market share that contains only three companies: A, B, and C. Therefore, when customers are dissatisfied with company A, they choose company B or C, and so forth. Babich further assumed that the distribution of dissatisfied customers among the alternative suppliers is in proportion to the suppliers’ current market share. Babich then determined the algorithm for the market shares of the three companies at time t + 1 as follows:
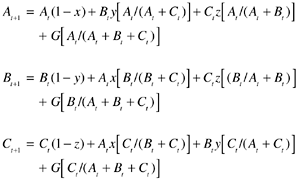
where:
A = number of A customers
B = number of B customers
C = number of C customers
G = number of new customers to market
x = dissatisfaction level with A products
y = dissatisfaction level with B products
z = dissatisfaction level with C products
t = time
Based on this model, Babich computed the market shares of the three companies assuming satisfaction levels of 95%, 91%, and 90% for A, B, and C, respectively, over a number of time periods. The calculations also assume equal initial market share. As shown in Figure 14.5 (A), after 12 time periods the 95% satisfaction prod-uct (company A) would basically own the market. However, had the satisfaction levels of companies B and C been 98% and 99%, respectively, and company A’s satisfaction level remained at 95%, company A’s product would have had less than 10% market share in 24 time periods, as shown in Figure 14.5(B).
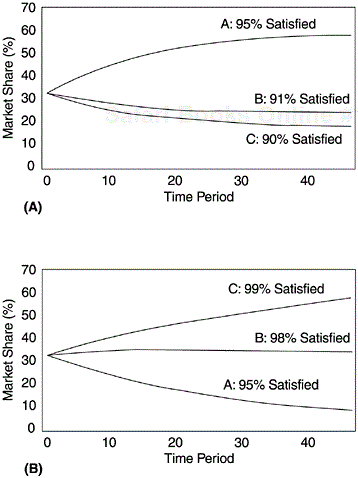
From “Customer Satisfaction: How Good Is Good Enough?” by Pete Babich. Quality Progress, December 1992. Copyright © 1992 American Society for Quality. Reprinted with permission.
Figure 14.5. Satisfaction Levels and Market Share
From Babich’s simple model and examples, the answer to the “how good is good enough” is obvious: You have to be better than your competitors. Therefore, it is important to measure not only one’s customer satisfaction level, but also the satisfaction level of one’s competitors. Indeed, many companies have been doing exactly that.
Finally, we emphasize that measuring and analyzing customer satisfaction is but one element of customer satisfaction management. A good customer satisfaction management process must form a closed loop of measurement, analysis, and actions. While it is not the intent of this chapter to cover the customer satisfaction management process, we recommend that such a process cover at least the following elements:
Measure and monitor the overall customer satisfaction over time, one’s own as well as key competitors’.
Perform analyses on specific satisfaction dimensions, quality attributes of the products and their strengths, weaknesses, prioritization, and other relevant issues.
Perform root cause analysis to identify inhibitors for each dimension and attribute.
Set satisfaction targets (overall and specific) by taking competitors’ satisfaction levels into consideration.
Formulate and implement action plans based on the above.
Various methods are available to gauge customer satisfaction, the most common of which is to conduct representative sampling surveys. The three major methods of survey data collection are face-to-face interview, telephone interview, and mailed questionnaire. Each method has its advantages and disadvantages. To obtain representative samples, scientific probability sampling methods must be used. There are four basic types of probability sampling: simple random sampling, systematic sampling, stratified sampling, and cluster sampling.
Given a probability sample, the larger the sample size, the smaller the sampling error. A common misconception with regard to sample size is that it must be a certain percentage of the population in order to be representative; in fact, the power of a sample depends on its absolute size. However, the sample must be a scientific (probability) sample. If the sample is drawn unscientifically, then even a huge size does not guarantee its representativeness. There are many real-life examples of huge and unrepresentative samples, which are results of unscientific design.
When analyzing and presenting customer satifaction survey data, the confidence interval and margin of error must be included. Furthermore, good analysis is paramount in transforming data into useful information and knowledge. In satisfaction surveys, satisfaction with specific quality attributes of a product are often queried, in addition to overall satisfaction. However, attributes with the lowest levels of satisfaction should not automatically be accorded the highest priority for improvement and additional investment. To answer the priority question, the subject must be looked at in the broader context of customers’ overall satisfaction with the product; the correlations of the satisfaction levels of specific attributes with overall satisfaction need to be examined; and the improvement actions should aim to maximize overall satisfaction.
Beyond satisfaction with a product, customers’ satisfaction with the company should be analyzed. A customer view model at the company level often entails improvement actions in areas in addition to product improvement, such as marketing, order process, delivery, support, and so forth. As a simple market-share model illustrates in this chapter, one must be better than one’s competitors in overall customer satisfaction in order to retain customer loyalty and to expand market share.