
Fault Tolerance
Just because we move to a microservices architecture and have isolated one component from another in either a process, container, or instance, it does not necessarily mean we get fault tolerance for free. Faults can sometimes be more prevalent and more of a challenge in a microservices architecture. We split our application into services and put a network in between them, which can cause failures. Although services are running in their own processes or containers and other services should not directly affect them, one bad microservice can bring the entire application down. For instance, a service could take too long to respond, exhausting all the threads in the calling service. This can cause cascading failures, but there are some techniques we can employ to help address this.
• Timeouts: Properly configured timeouts can reduce the chance of resources being tied up waiting on service calls that fail slowly.
• Circuit breaker: If we can know a request to a service is going to result in a failure then we should not call it.
• Bulkheads: Isolate resources used to call-dependent services.
• Retry: In a cloud environment, some failed service operations are transient and we can simply detect these and retry the operation.
Let’s have a look at these patterns and what they are.
If an application or update is going to fail, it’s better to fail fast. We cannot allow a service we are calling to cause a failure that cascades through the system. We can often avoid cascading failures by configuring proper timeouts and circuit breakers. Sometimes, not receiving a response from a service can be worse than receiving an exception. Resources are then tied up waiting for a response, and as more requests are piled up, we start to run out resources. We can’t wait forever for a response that we may never receive. It would be far better if we never send requests to a service that is unavailable. In Figure 1.6, Service E is failing to respond in a timely manner, which consumes all the resources of the upstream services waiting for a response, causing a cascading failure across the system.

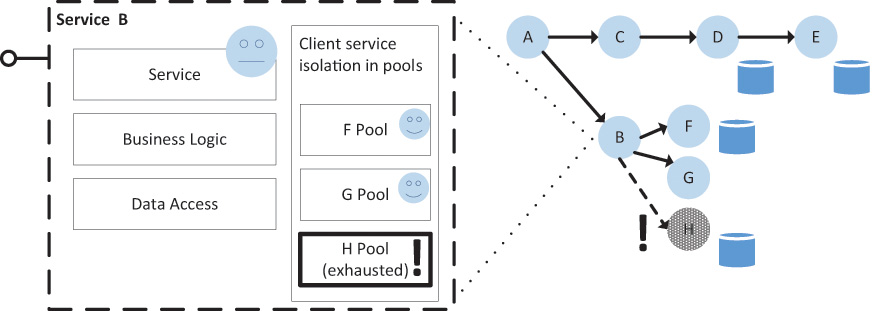
Quite often a service will have a dependency on multiple services, and if one is behaving badly we don’t want that to affect requests to the others. We can isolate the service dependencies and place them in different thread pools, so if Service A starts to time out, it does not affect the thread pool for Service B. This protection is similar to that of bulkheads in a ship; if we get a leak in the hull of the ship we can seal off that section to avoid sinking the entire ship. As we see in Figure 1.7, calls to different services are isolated into bulkheads. This means that if service ‘H’ is behaving badly, it’s not going to affect calls to service ‘G’ or other resources in the service.
Some exceptions from service calls are transient in nature and we can simply retry the operations. This can avoid exceptions and the need to handle the entire request again. This typically involves a detection strategy to determine what exceptions are transient, and then to define a strategy for how to handle it, such as how many times to retry the operation and how long to wait before retrying. We do need to be careful that our retry logic does not overwhelm a failing service, however.
More information on retry patterns is available in “Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications,” an article available on MSDN (https://msdn.microsoft.com/en-us/library/dn589788.aspx). Additional guidance implementing this pattern can be found in the Microsoft Patterns & Practices repository (https://azure.microsoft.com/en-us/documentation/articles/best-practices-retry-general/).
If we can know that a request to a service is going to fail, it’s better to fail fast and not call the service at all. Resources are required to make a service call, and if the service is unhealthy and is going to fail, then there is little point in calling it. Also, the service might be trying to recover or scale up to meet some increased demand, and retrying the call is only making it worse. To address this, we can utilize a pattern called the circuit breaker pattern. If the calls exceed some threshold, we move to an open state, or trip the breaker just like the circuit breaker in your home. When the circuit breaker is open, we stop sending requests until it’s closed. Like the wiring and devices in the home, a circuit breaker can help protect the rest of the system from faults. Circuit breakers are not triggered automatically exclusively when a service is failing, but can sometimes be triggered manually when a service needs to be taken offline for maintenance or to recover.
More information on the circuit breaker design pattern is available in “Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications” (https://msdn.microsoft.com/en-us/library/dn589784.aspx).