
4 A.M. | |
The place: | Your bedroom |
The event: | Your pager and cellular phone start ringing, buzzing, and vibrating like crazy, waking you from a deep sleep. |
The reason: | Your company’s mission-critical Microsoft SQL Server is down, and has been for about an hour. The overnight operations staff was unable to bring it online. |
Unfortunately, tomorrow is the busiest day of the week and the databases must be fully functional by 8 A.M. Can you not only get there in time, but also bring the server up by then? The last thing that you want to have is the CEO/CTO/CFO/CIO (or other "chief") standing over your shoulder asking you, "When will it be up?"
Assuming you have a disaster recovery plan in place (which is crucial in any IT organization wanting high availability), the preparation, planning, and testing of that plan can mean the difference between seconds and minutes of downtime versus hours, days, or even weeks. You need to know how long it takes to execute the plan and, more importantly, how to execute it. In addition, if you’re facing a truly worst-case disaster recovery scenario for your SQL Server, you need to know how long it would take to restore the database from backups, including the last known good (that means tested) backup and where it is located.
If this or a similar scenario is your recurring nightmare, the full gravity of making systems and solutions highly available is in the forefront of your mind. If this situation does not speak to you in any way, it might be that stress does not get to you or that you are unaware of the situation’s implications. Your employer makes you carry a pager or cellular phone for a reason; he or she wants to be able to get in touch with you day or night in the event something catastrophic happens. There is one driver behind all of this: the risk of losing something critical to the company’s business, whether it is revenue, productivity, both revenue and productivity, or an intangible such as industry credibility.
The simple definition of the availability of a system is the amount of time a system is up in a given year. In the past few years, the availability of a company’s mission-critical systems has been a major focus point. Availability needs to be given the proper attention, in addition to performance and security, which have always been paramount in the mind of anyone who has interaction with the systems. End users and management are concerned when the system is down; they do not usually spend time worrying about availability or allocating additional money for availability when the system is up and running. Availability is not just a SQL Server issue, either—it is applicable to every aspect of a computing environment.
There are two main aspects to consider when thinking about high availability, prevention and disaster recovery, both of which have many more facets than just technology. Prevention is anything—including people, processes, and technology—that, when put in place, is designed to reduce the risk of a catastrophic occurrence. The harsh reality is that, despite planning, failures can occur. A highly available system is one that can potentially mask the effects of the failure and maintain availability to such a degree that end users are not affected by the failure.
Disaster recovery is exactly what it claims to be—a catastrophic event happened, and it must be dealt with. Achieving high availability must take into account both pieces of the proverbial puzzle to make the complete picture. High availability is not just the sigh of relief when the system comes back up. If you are a fighter pilot, would you rather be a daredevil and have fast planes with no safety precautions or fast planes with ejection seats? During World War I, it was thought of as a sign of weakness to carry a parachute, but obviously this attitude has changed. Taking precautions to save systems—or human lives—should never be viewed as extraneous.
The basic tenets of prevention are deceptively simple:
Deploy redundant systems in which one or more servers act as standbys for the primary servers.
Reduce and try to eliminate single points of failure.
Both tenets provide a solution to only one aspect of the technology part of the equation—the server itself. What about the network connecting to the server? What about an application’s ability to handle the switch to a secondary server during an outage? These are just two examples of possible problem areas; there will be more for your environment that you need to prepare for. The bottom line, though, is that planning, implementation, and administration of systems are equally important aspects of preventing an availability problem.
The more redundancy you have, the better off you are. However, there is a conundrum. No system is completely infallible in and of itself, but adding too many levels of redundancy might make an availability solution so complex that it becomes unmanageable.
The designers of the Titanic thought she was unsinkable, yet the ship went to the bottom of the ocean on her maiden voyage. For protection, the Titanic had 16 watertight compartments that could be sealed with 12 watertight doors. In theory, this would have kept the ship afloat despite flooding in three or four compartments. Unfortunately, the watertight compartments themselves only went to a certain level above the water line. When the iceberg struck the Titanic, the damage it caused was, in reality, only six noncontiguous small gashes totaling about 12 square feet. But they made it possible for water to overflow from one compartment into another (think of the way an ice cube tray fills with water) and eventually caused the ship to sink.
What turned out to be a fatal flaw was addressed to the best of the designers’ ability at the time, but the unknown always lurks in the shadows. You must do your best when you are seeking to prevent a catastrophe.
Technology is only one part of the equation. Environmental and human aspects also contributed to the Titanic’s fate. She was caught in a set of circumstances—an ice field that affected most ships in the North Atlantic at that exact time, the lookout saw the iceberg too late, no other ships were close enough to assist after the Titanic struck the iceberg, and so on—for which no amount of technology could compensate.
Similarly, you might have two exact copies of your production database, but what happens if they are located in two data centers in the same state and are affected by an earthquake simultaneously? Do not overthink your availability solutions; there is only so much you can plan for.
When the iceberg struck, the Titanic was unprepared. There had been no safety drills to test an emergency plan (if one existed), not enough lifeboats for all passengers, and so on. Survivor accounts of the chaos during the last few hours reinforce the importance of proper planning in ensuring that more good than harm occurs during a crisis. Consider that each database, or even the entire system, could need to be rescued but not have to be salvaged from the bottom of the ocean. Rash decisions for the solution could have dire consequences. The only way to execute a rescue or salvage operation is to have the right people in place with a complete, well-tested plan to direct them.
When the crisis has passed, a postmortem should be done to determine the lessons learned to prevent such an outage from occurring in the future. Chapter 12, includes an in-depth discussion on disaster recovery and the plans needed.
Keep in mind that when it comes to disaster recovery, there can be another extreme. You can be proactive to the point of being negative. The person who is constantly worried about everything might be considered obsessed. There is a happy balance somewhere. If the crew of the Titanic made each passenger walk around with life preservers, a ration kit, and some sunblock, would that have been practical? No. Being prepared does not equate to paranoia. Assume that there is always something that could happen to your systems, anticipate and plan to the best of your ability, but go about your day knowing that you cannot control every factor.
If something happens—and something will happen at some point during your career—ensure that you will not go down with the ship. Whether you are the captain or just one of the passengers or crew, a disaster situation might make or break your career with your employer. Not being able to answer a question such as the one posed in the beginning of the chapter—"When will it be up?"—because, for example, the plan was never tested or the backups themselves were never tested and timed, is generally considered unacceptable. Keep in mind that fallout might still occur when the dust settles, but as long as you were prepared and handled the situation properly, all should be fine.
Before starting on the design, purchase, and eventually roll out of any systems, the key players must meet to agree on the specifics of the solution that will eventually be deployed. This should be done for every deployment and solution desired, whether or not it is considered mission-critical.
Assemble a project team that will own the overall responsibility for the availability of the solution. The leader should be the business sponsor—a person from the management team who will ultimately answer for the success or failure of the operation and have the greatest influence on its budget. Representatives from all parts of the organization—from management to end users—should be part of the team, as each of them will be affected in one way or another by the availability of the systems or solution that will be put in place.
Once the project team is assembled, it should meet to decide the principles that will govern how the solution will be designed and supported. The following are some sample questions to ask; there might be more for your environment.
What type of application is being designed or purchased?
How many users are expected to be supported concurrently by this solution in the short term? In the long term?
How long is this solution, with its systems, supposed to stay in production?
How much will the data grow over time? What is projected versus actual growth (if known)?
What is acceptable performance from both an end user and administrative or management perspective? Keep in mind that performance can be defined in various ways—it might mean throughput, response time, or something else.
What is the availability goal for the individual system? The entire solution?
How is maintenance going to be executed on this system? Like performance, how you maintain your systems is specific to your particular environment.
What are the security requirements for both the application and the systems for the solution? Are they in line with corporate policies?
What is the short-term cost of developing, implementing, and supporting the solution? The long-term cost?
How much money is available for the hardware?
What is the actual cost of downtime for any one system? The entire solution?
What are the dependencies of the components in the solution? For example, are there external data feeds into SQL Server that might fail as the result of an availability problem?
What technologies will be used in the construction of the solution?
Some of the questions you ask might not have answers until other pieces of the puzzle are put in place, such as the specifications for each application, because they will drive how SQL Server and other parts of the solution (for example, Microsoft Windows 2000 Server) are used and deployed. Others might be answered right away. Ensure that both the business drivers and the more detailed "what if" scenarios are well documented, as they are crucial in every other aspect of planning for high availability. It might even be a good idea when documenting to divide the questions into separate lists: one that pertains to the requirements of the business independent of technology, and one that is technology-dependent.
Having listed questions, it is a safe assumption that each person in the room will have a different answer for each question. The goal is to have everyone on the same page from the start of the project; otherwise the proverbial iceberg might start ripping holes in the hull of your solution. Compromise will always be involved. Compromise can only be achieved if there is a business sponsor who is driving and ultimately owning the solution at all levels. It is the responsibility of this person to gather consensus and make decisions that result in the compromise that everyone can live with. As long as all parties agree on the compromise, the planning, implementation, and support of the solution will be much smoother than if the voices of those two steps down the road are not heard or are ignored.
High availability is not synonymous with other vital aspects of any production system, such as performance, security, feature sets, and graphical user interfaces (GUIs). Achieving high availability is ultimately some form of a trade-off of availability versus performance versus usability. All aspects also need to be considered when doing overall system, infrastructure, and application design. Designing a highly available system that is not usable will not satisfy anyone. This is where the trade-offs come into play.
Is buying a single 32-processor server to support a larger amount of concurrent users for a database that is used 24 hours a day the most important business factor, or is it more important to ensure that the server is going to be up 24 hours a day to support the continuous business? Chances are people will say both are equally as important, but in reality, a budget dictates that some sort of trade-off must occur. Having slightly lower performance to ensure availability might be a reasonable trade-off if the cost of downtime is greater than the ability to have 10 additional users on the system. The same could be said for security—if the system or solution is so secure that no one can use it, is it really available? Conversely, if a developer coded the database server’s security administrator account and password into the application to make things more convenient, this may compromise security, as well as the application’s ability to work with certain high-availability technologies.
Think of it another way: If money was no object and you had to purchase a car, would you buy a fast, sleek sports car or a sensible four-door sedan with airbags for all passengers? Many would choose style over substance—that is human nature. High availability is like buying the sedan; it might not be the best looking car on the block, but it is a solid, reliable investment. The airbags and sturdy roll bar, among other safety features, will make you as prepared as you can be for a possible accident.
For a clear example of a trade-off, briefly consider the Titanic again and that the White Star Line valued luxury over lifeboats. That was their trade-off, and at the time it made sense to the people funding the ship as well as the designers. That decision ultimately proved to be fatal. You need to determine what the acceptable trade-offs are for each situation so that the solution will meet the needs of everyone, especially those responsible for administering it and, most important, the end user or customer.
Once the basic principles governing the solution have been put into place, it is time to mitigate the known and unknown risks by asking the "what if" questions to the best of the group’s ability. You might know what the risk and its associated questions are, but not the solution to mitigate them. Even more risks will become apparent as the solution moves from conception to planning, on through to implementation, and as more and more technology and application decisions are undertaken. Whenever a risk is identified, even if there is no answer at the time, make sure it is documented. Continually check the documented list of risks to see that there has been a corresponding answer to the question recorded. By the time the solution hits production, all identified risks should have a response, even if it is that nothing can be done to mitigate the risk.
Although there are many more possibilities, here are some common questions to jump-start the risk management process:
What will you do if one disk fails? The entire disk subsystem?
What will you do if a network card fails?
What will you do if network connectivity is lost?
What will you do if the entire system goes down or stops responding? Is loss of life involved (for example, a health system)? Although this is related to the overall cost of downtime, the specific result of downtime should be known.
How does the application handle a hardware (including network) or software failure?
Is there a corporate standard—what do we do now for availability on other systems—and is that plan working well?
How will the proper people be notified in an emergency?
How will a problem be detected?
Your guiding principles are now documented, along with some risks that might or might not have answers. At this point, the principles should be reviewed and debated to ensure that they are correct. If something is not right, now is the time to correct it, as these principles will live through the entire project life cycle. They can be modified and reassessed if necessary, but the initial principles should be the measuring stick against which the success or failure of a solution is measured. There should be a formal signing off by the entire team, because availability is the responsibility of everyone involved.
The definition of uptime and downtime is different in every computing environment. Technically, all downtime should count toward a final availability number, whether it is planned or unplanned, because both are service disruptions. Some environments do not count planned downtime, such as periods of normal maintenance, against an eventual system availability calculation. Although this is an individual decision each company makes, padding availability numbers by excluding planned downtime might send the wrong message to both management and end users. In fact, many enterprise customers pay for an external service to monitor the availability of their systems in comparison to their competitors’ to ensure that the entire system’s availability meets the guiding principles determined by the team.
Calculating availability is simple:
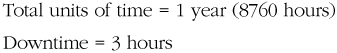
Plug that into this formula:
which results in .999658 availability of the individual system.
Keep in mind that the individual system rarely exists alone: it is part of a whole solution. You have now calculated the individual system’s availability, but what is the entire solution’s overall availability? That number is only as good as the weakest critical link, so if one of the essential servers in the solution only has .90497 uptime, that is the uptime of the entire solution. The number for the overall solution also has to factor in such things as network uptime, latency, and throughput. These critical distinctions bring the availability of a solution into focus. Having said that, qualify numbers when they are calculated and explained. This definition might be too simplistic for some environments—if the server that has .90497 uptime is not considered mission-critical and does not affect the end user’s experience or the overall working of the solution, it might not need to be counted as the number for the overall solution. The bottom line is that multiple components in a solution can fail at the same time or at different times, and everything counts toward the end availability number.
There are also the related concepts of mean time between failures (MTBF) and mean time to recovery (MTTR). MTBF is the average expected time between failures of a specific component. A good example is a disk drive—every disk has an MTBF that is published in its corresponding documentation. If a drive advertises 10,000 hours as its MTBF, you then need to think about not only how long that is, but also how the usage patterns of your application will shorten or lengthen the life (that is, a highly used drive might have a shorter life than one that is used sparingly). An easy way to think of MBTF is predicted availability, whereas the calculation detailed earlier provides actual availability.
MTTR is the average time it takes to recover from a failure. Some define the MTTR for only nonfatal failures, but it should apply to all situations. MTTR fits into the disaster recovery phase of high availability.
The calculation example yielded a result of 99.9 percent uptime. This equates to three nines of availability, but what exactly is a nine? A nine is the total number of consecutive nines in the percentage calculation for uptime, starting from the leftmost digit, and is usually measured up to five nines.
The following table shows the calculations from one to five nines.
Table 1-1. Nines Calculations (Per Year), in Descending Order
Percentage | Downtime (Per Year) |
|---|---|
100 percent | No downtime |
99.999 percent (five nines) | Less than 5.26 minutes |
99.99 percent (four nines) | 5.26 minutes up to 52 minutes |
99.9 percent (three nines) | 52 minutes up to 8 hours, 45 minutes |
99.0 percent (two nines) | 8 hours, 45 minutes up to 87 hours, 36 minutes |
90.0–98.9 percent (one nine) | 87 hours, 36 minutes up to 875 hours, 54 minutes |
Most environments desire the five nines level of availability. However, the gap between wanting and achieving that number is pretty large. How many companies can tolerate only 5.26 or less minutes of downtime—planned and unplanned—in a given calendar year? That number is fairly small. Good-quality, properly configured, reliable hardware should yield approximately two to three nines. Beyond that, achieving a higher level of nines comes from operational and design excellence. The cost of achieving more than three nines is high, not only in terms of money, but also effort. The cost might be exponential to go from three, to four, and ultimately, to five nines. Realistically, striving to achieve an overall goal of three or four nines for an individual system and its dependencies is very reasonable and something that, if sustained, can be considered an achievement.
Consider the following example: Microsoft SQL Server 2000 is installed in your environment. Assume that Microsoft releases a minimum of two service packs per year. Each service pack installation puts the SQL Server into single-user mode, which means it is unavailable for end user requests. Also assume that because of the speed of your hardware, the service pack takes 15 minutes to install. At the end of the install process, it might or might not require a reboot. For the sake of this example, assume it does. A reboot requires 7 minutes, for a total of 44 minutes of planned server downtime per year. This translates into 99.9916 percent uptime for the system, which is still four nines, but you can see how something as simple as installing a service pack can eliminate five nines of availability in short order. One possible way to mitigate this type of situation is to have one of the standby systems brought online to take requests, synchronize the primary server when the service pack is finished, and then switch back to the primary server. Each switch will result in a small outage, but it might wind up being less than the 22 minutes it takes for one service pack. That process also assumes that it has been tested and accurately timed on equivalent test hardware.
If you ask the CEO, CFO, CIO, or CTO, each one will most likely tell you that they require five nines and 24/7 uptime. Down in the trenches, where the day-to-day battles of system administration are fought, the reality of achieving either of those goals is challenging, to say the least.
Keep in mind that the level of nines and the requirement might change during the day. If the company is, say, an 8-to-5 or a 9-to-6, Monday-to-Friday type of shop, those are the crucial hours of availability. Although the other hours might require the system to be up, there might not be a 100 percent uptime guarantee for the outlying hours. When the solution is designed, the goal should be to achieve the highest level of nines required, not shooting for the moon (five nines)—that might be overkill. When the question is asked during the business drivers meeting, such situations need to be taken into account. Five nines of availability from Monday to Friday might only mean 9 hours a day, which translates into 2340 hours per year. This number is well below the 8760 hours required for 24/7 support, 365 days a year. All of a sudden, what once seemed like a large problem might now seem much easier to tackle.
Also be mindful that each person—from members of management right down to each end user—will have different goals, work patterns, and agendas. In good times, the demand for high availability might be someone’s priority, but if other factors and goals, such as high profitability, are currently driving the business, availability might not be number one on the list of priorities. This also relates to the nature of some industries or different organizations—financial and medical institutions by default require availability, whereas service or retail organizations might see availability only as an aspect of the business that might or might not be important. This could mean that in the negotiations, a variable rate of availability might be discussed, and might confuse people.
For example, if you need your systems to have five nines of availability from 8 A.M. to 8 P.M., that should be your target for availability. Stating different rates of availability for different hours can potentially lead to the design of an inferior system that will not be able to support the highest required availability number. In the end, it is important to understand all of the factors when putting together the business drivers and guiding principles that ultimately will govern the solution. Ignoring any one of the groups touching the systems is a mistake.
Perception is reality, whether we like it or not. Because of this, it is important to make a distinction between the types of unavailability:
Actual unavailability. Anything that makes the system and its resulting solution unavailable to the people who are using it. There are varying degrees of total unavailability (complete system failure, site down, and data gone, all of which are described in more detail in Chapter 13, along with ways to mitigate them), and this is more often than not the catastrophic or unplanned failure. That said, things such as system maintenance—like service pack installs—might cause total unavailability of a system.
Perceived unavailability. When a system appears to be functioning properly from an administrative standpoint, but is unavailable to end users or customers. This can happen if only one aspect of the solution is down, for example, if the database administrators (DBAs) know SQL Server is up and running, but the front-end Web servers fielding the initial requests and serving up Active Server Page (ASP) pages are down. Another example is if someone outside has cut the network cable that goes from the data center to the outside world. Poor performance or lack of scalability can also lead to perceived unavailability, because an end user requires an answer back from your systems in a reasonable amount of time.
Each person in the availability equation sees a system or the entire solution differently. To mitigate issues caused by varied perceptions, service level agreements (SLAs) must be negotiated with all parties involved in the solution, including hosting companies, end users, contractors, administrators, and so on, to ensure that uptime and performance needs are met. Each SLA might state a different availability goal, but the overall availability is based on every component, not just one. Chapter 2, delves further into SLAs.
Take a mental poll of your current workplace or companies you have worked for in the past: how many applications and solutions were designed with availability in mind from inception? The reality is that in most—not all—development, test, and production environments, availability is an afterthought. In the minds of some application developers and management, availability is solely Information Technology’s (IT’s) concern—meaning not a design, just an end-of-line implementation issue—right? Wrong! Availability is not just a technology problem: it encompasses people, process, and technology, as well as end-to-end designs of applications, infrastructure, and systems. Chapter 2 gets into some of the specifics of the basics of high availability, from basic infrastructure to change control.
There are two approaches for assessing your environment for availability:
The application or solution is already in place. Availability needs to be retrofitted to the environment. In the evaluation process of adding availability for the first time, or enhancing existing availability methods, new hardware might need to be purchased, new maintenance and other processes are added to the administrator’s daily tasks, the application itself might need to be patched or redesigned, and more. Some of this might be the result of outgrowing current hardware capacity or scalability, causing a perceived unavailability problem.
The application or solution has not yet been implemented. This more than likely means starting from the beginning, and the solution starts from a clean slate. In the evaluation of a completely new solution, planning is every bit as important, if not more important, than the final step of implementation. Planning ensures fewer problems over the solution’s entire life cycle. It is much easier to get something right from the start than it is to take an existing solution and redesign it to be something else. Remember that scope creep is a problem for any planning, design, and implementation process—not just availability ones!
As noted earlier, Chapter 2 covers more specifics about the basics of high availability, but it is very important to keep in mind the differences in the two approaches and how they really are not the same. Keep this in mind as you go through each chapter in this book, as well as when you start to plan, design, and implement highly available solutions in your environment.
In assessing availability, it is important to keep in the forefront of everyone’s mind that applications directly impact the availability of systems. One could even argue that in spite of massive amounts of other software and hardware redundancy, in the end the application might prove to be the weak point in the availability chain if it is not designed to handle such things as a server name change if it should be required during disaster recovery. The application drives the requirements of how each production server, its related hardware, and third-party software—such as database platforms and operating systems—will be selected and assembled; the infrastructure should not dictate the application. Designing the perfect infrastructure does no good if the one component accessing it cannot properly utilize the new multimillion-dollar infrastructure. This is also the reason that retrofitting high availability into an already existing environment is much more challenging than starting from scratch. Sometimes, it can be akin to putting a square peg into a round hole. A bad application means low availability.
No ones likes the cost aspect of assessing availability and, to a large degree, it is the toughest aspect to handle. The question is not so much the cost of availability, but the cost of not having availability and, subsequently, the actual cost of downtime. Money is always a factor, as achieving availability is not cheap. Speaking realistically, achieving five nines of availability on a limited budget is just about impossible.
Consider the following example: A high volume e-commerce Web site generates, on average, $10,000 in sales per hour. For a day, that equates to $240,000, and weekly, $1,680,000. On the busiest day, the Web site encountered an unexpected availability problem around noon. When all was said and done, the Web site was down for six hours, which is the equivalent of $60,000 in sales. That was the surface cost of downtime.
Analyzing the downtime further, when the outage happened, no plan was in place, so an hour of that time was spent gathering the team together. This also meant that whomever was called in to work on the problem had to stop working on whatever they were doing. Because no plan was in place, there was no clear chain of command, resulting in many people attempting the same thing, further tying up system resources. This impacted other schedules and mission-critical timelines, a cost that must also be measured.
When the company went to call support, they realized that they never renewed their Microsoft Premier Support agreement because they did not really use support services in the past, so they felt it was not needed. Instead of getting the quick response engineers, they were left waiting in the queue with other pay-per-incident customers. Also hindering quick time to resolution, certain information was either not known about the systems or could not be gathered because of stringent processes. It took a committee a half hour to decide to allow the information to be gathered. The technical issue was eventually solved, but due to the delays caused by the lack of a support contract and the information problem, it took longer than it should have. These were tangible costs and direct problems.
Perhaps even more important than the tangibles are the intangibles: how many existing customers went to the Web site to buy something, could not access it, and did not come back because they knew they could get the item from another e-tailer that was up and running? Those users might be enticed by discount coupons to return—but perhaps not. An even bigger intangible was the loss of prospective customers who visited the site during the downtime, saw it was down, and never visited again. That might factor into the $10,000 hourly rate, but can you put a price on future business? Customer loyalty is directly associated with a brand name. A bad experience generates negative word of mouth. If word spreads that the site is unreliable, the more people that spread that message, the more potential there is of losing current and future business.
For this example, there are a few conclusions that should be highlighted as part of a postmortem to prevent the problem from happening again:
A proper disaster recovery plan must be devised and implemented to avoid additional unnecessary downtime.
A clear chain of command must be established to reduce confusion and duplicate efforts.
Always have a support contract with appropriate vendors that provide the level of support and response needed.
Support personnel need certain information sooner rather than later.
Make sure customers are welcomed back with open arms after a significant outage.
Chapter 12 walks you through putting together a complete disaster recovery plan. Because the downtime cost at least $60,000 in this case (again, this is the only concrete number), would a $10,000 support contract have paid for itself? Most likely it would have. If the technical problem was found to be an issue of configuration, was it completely thought out during the planning process, or was the system rushed into production? Correcting these kinds of issues can save money and time to resolution.
The preceding example shows that the lack of a proper disaster recovery plan, no support contract, and the possible missed configuration point are potential barriers to availability, or roadblocks to achieving the level of availability required. These barriers include, but are not limited to, the following:
People. Everything from improper staffing to too many chiefs mulling around and giving orders during downtime.
Process. Is there a plan? Are there normal company standards and processes that will impede the availability and possibly disaster recovery solutions?
Budget. Was enough money invested in all aspects of the solution (people, process, design, software, hardware, support, and so on)? Will cutting costs or restraining budgets cause more downtime in the end? Every solution obviously is not given carte blanche in terms of a budget, but an availability solution must fit a budget and the availability requirements. The two cannot be in direct conflict, otherwise there will not be a successful implementation.
Time. Are the goals set for coming back online unreasonable? Are maintenance windows too short, which means that if maintenance is not being done, it could cause availability problems down the road?
During the planning phase, you must take into account barriers to availability and mitigate any risks associated with them.
Achieving high availability is not as simple as installing a piece of software, a new piece of hardware, or using a /highavailability command-line switch when starting up a program. If it were that easy, you would not be reading this book. Constructing and testing an end-to-end solution that encompasses people, process, and technology is the only tried-and-true method of preparing for a potential disaster. Redundant technology for availability only provides the end physical manifestation of a larger, agreed-on goal that also takes into account security and performance. Trade-offs can be made to achieve the end result, but the end result should satisfy management, administrators, and end users. Each group should also formally buy into and share responsibility for high availability.