
Reading an Existing XML Document
The only way to make sense of all this information is to build a program that puts it to use. The XML Viewer program will help you see how exactly C# reads an XML document and how to get around in it. The XML Viewer is more than a programming exercise. It is a tool you can use to analyze and explore the structure of any XML document. After you see how it describes the data in an XML document, you will be ready to get inside the engine and see how the program does its work. Figure 10.7 illustrates the XML Viewer as it first loads the quiz document.
Figure 10.7. The starting node is named xml, but it isn’t very interesting.
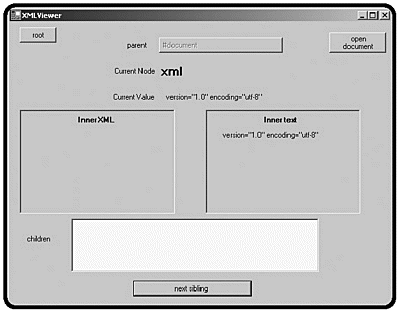
The root node is the xml tag itself. It usually provides some background information, but it doesn’t have any children and doesn’t contain a lot of other data. To get to the interesting parts of the file, you click the Next Sibling button (see Figure 10.8).
Figure 10.8. The test node has a lot more information. (Almost too much!)

The test node is much more interesting. All the interesting data in the quiz file was somehow related to the test node, so it isn’t surprising that the test node shows much more information. All the screen elements in the XML Viewer program describe properties of the current node. The Parent button refers to the test node’s parent node, which is the document itself. I disabled the Parent button in this particular case because the document is the top layer. The node field refers to the Name property of the current node. In this case, the name of the current node is test. The value label refers to the Value property of the current node. You might be surprised that the test node has no value at all. That is because all the information of the test is actually stored in its children. As you will see, the InnerText property often turns out to be more useful than the Value property.
The InnerXml property returns all the XML associated with the current node. When test is the current node, all the XML between the <test> and </test> tags in the original XML show up as the InnerXml property. The InnerText property simply strips out the XML tags from the InnerXml property and returns the resulting text. Notice that the Next Sibling button is disabled because the program has detected that the test element does not have a next sibling.
A node can have several child nodes, as you can see from the test node. In this particular file, the test has three problems, and you can see a list box with three problem nodes. To view one of the child nodes, double-click it. I chose the first problem, which results in Figure 10.9.
Figure 10.9. I have clicked the first problem, and the viewer is now looking at the problem node.
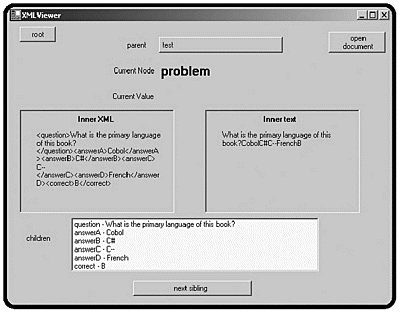
All the screen elements have changed to reflect that the problem node has the focus. The test node is now listed as the parent node, and you can click the button to return to the parent node. (That’s why I made the parent node a button instead of a label.) The problem node still doesn’t have a value because it is mainly a container for other nodes. You can see that the InnerXml and InnerText properties have narrowed their scope considerably. Also, the list of ChildNodes shows the question, possible answers, and correct answer. The Next Sibling button is activated because this question has siblings. Click the Next Sibling button a couple times until it becomes disabled. It will do so at the last question, which gives you a screen like Figure 10.10.
Figure 10.10. Now the viewer is pointed at the last child of the test node.
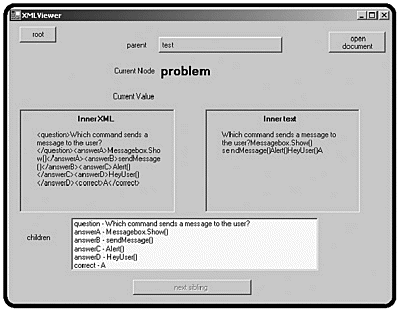
It’s time to investigate the children of the problem node. Click the first child (the question), and you will see something like Figure 10.11.
Figure 10.11. You might be surprised that there still isn’t anything useful in the value field.

It would seem as though the question is the lowest level of the XML document, but it isn’t. The InnerText and InnerXml of the question (and all its siblings) are useful information, but you will see that the question has one child, marked as #text. Not until you get to the #text node do you finally have actual data in the value field. The XML Viewer program is particularly interesting because it can be used to analyze any legal XML document. This points out one of XML’s advantages. The format of the data describes the data’s meaning, so a program can work with data in a new format with some hope of deciphering it.
Figure 10.12 illustrates how the .NET framework sees the quiz document.
Figure 10.12. This diagram more accurately reflects how .NET sees an XML document.

It’s okay if you’re still a little confused, because the various characteristics of a node can be very confusing. If you’re still hazy, run the XML Viewer and watch what happens as you move around in a document. Look at the XML source code of your XML document so that you can see how it relates to the various properties of the node object. The best way to make sure that you understand this is to build a quick XML document in the XML editor, load it into the XML Viewer, and see whether you understand how everything fits together. The XML Viewer is really just a window into the XmlNode class, so if you understand how it works, you are well on your way to understanding XML in .NET.
Creating the XML Viewer Program
The design of the XML Viewer program is more transparent than in many programs in this book because the XML Viewer is meant primarily as a programmer’s tool. Most of the form’s visual elements map directly to a specific property of the XmlNode class.
Building the Visual Layout
The XML Viewer provides a window to a document by providing details about one node at a time. Several properties of the current node are shown, including the Name, Value, InnerText, and InnerXml properties. The values of each of these properties are displayed in an appropriately named label (see Figure 10.13).
Figure 10.13. Most of the visual interface is composed of labels, with a few buttons and a list box added for navigation.

In addition to the mentioned properties of the node, the XML Viewer displays the name of the parent node in the Parent button. The name and description of each of the current node’s child nodes are listed in a text box.
The user can maneuver through the document by clicking the Parent button, double-clicking a child in the list box, clicking the Root button (which takes the user directly to the document’s root), or clicking the Next Sibling button, which displays the current node’s next sibling, if it has one.
I made the lblInnerText and lblInnerXml labels taller than a typical label because I knew that they would sometimes include large amounts of text. I placed these labels and their descriptors inside panels to break up the screen and make the purpose of the large labels apparent.
I used a list box to display child nodes because it seemed like a natural fit. The children can be any number of elements and can easily be described by string values. The list box seemed like the simplest way to handle the display and selection of child nodes.
Creating Instance Variables
The XML Viewer program has only two form-level variables, and both are classes from the System.Xml namespace. The viewer code begins with a reference to that namespace:
using System.Xml;
The two instance variables are an XmlDocument object named doc and an XmlNode object named theNode:
private XmlNode theNode;
private XmlDocument doc;The doc variable will contain a reference to the entire XML document. It will remain the same until the user requests another document with the Open Doc ument button. The theNode variable will change to reflect whichever node is currently being described on the screen.
Initializing the Program
As usual, I did much of my initialization in the form’s load event. The main objectives of the xmlReader_Load() method are to load the document from a file, set theNode to the root document of the file, and display the root node:
private void xmlReader_Load(object sender,
System.EventArgs e) {
doc = new XmlDocument();
doc.Load("c#Test.xml");
theNode = doc.FirstChild;
displayNode();
} // end form loadThe doc = new XmlDocument() code assigns a new instance of the XmlDocument class to doc. The next line uses doc’s Load() method to load a pre-existing file name. The FirstChild property of doc will call the first tag in the document, which is usually the <xml> tag. displayNode() is a method of the XML Reader class that I’ll describe in the next section.
Displaying a Node
The code to display a node is the centerpiece of the XML Viewer program. It is involved, so I’ll explain the displayMode() method in smaller pieces: (look on the CD-ROM to see the function in its complete form.)
The displayNode() method begins by creating a local XmlNode named childNode. This variable will be used to populate the child list box.
Working with the Plain Text Properties
The first series of statements deals with the properties of a node that return plain text:
//handle all the straight text properties lblCurName.Text = theNode.Name; lblCurValue.Text = theNode.Value; lblInnerXml.Text = theNode.InnerXml; lblInnerText.Text = theNode.InnerText;
There isn’t anything at all challenging about this code because all the properties return a text value, which is easily mapped to the Text property of the labels.
Displaying and Enabling the Parent Button
The more interesting work comes when dealing with the parent, child, and sibling properties because they do not simply return a string value, but an actual node. You must take more care when dealing with these properties:
//handle the parent button
btnParent.Text = theNode.ParentNode.Name;
//enable btnParent only when appropriate
if (theNode.ParentNode.NodeType == XmlNodeType.Element){
btnParent.Enabled = true;
} else {
btnParent.Enabled = false;
} // end ifThe ParentNode property returns an XmlNode. I mapped the name of this node to a button because I want the user to be able to view the parent by clicking the button. This is easily accomplished, but there’s a potential problem. If the user is already at the document’s root, the parent is listed as #document, which cannot be traversed. The easiest way to prevent this problem is to check the parent node’s type as soon as a node is loaded and to disable the Parent button when displaying the parent node is inappropriate. I used an if statement to compare the NodeType of the parent node to a built-in value called Xml.NodeType.Element. I allowed the Parent button to be displayed only if the parent is an element type. This will be true in all nodes of an XML document but the root, so it prevents moving above the root node.
The code for moving to the parent class belongs in the Parent button’s click event. You might think that it would make more sense to put code that traps for an error in the event method where the error will occur (which is in the button click, in this instance). However, sometimes the best kind of error handling is error prevention. Rather than trap for an error after it has occurred (which would happen if you put the code in the button press method), you can prevent the button from being pressed when you know that it will cause an error. Often this type of preventive programming saves you grief in the long run. You will see the practice used in a couple other places in the XML Viewer program.
Enabling the Next Sibling Button
Like the Parent button, the Next Sibling button is enabled only if the program has determined that the current node has a next sibling. If it does not, the NextSibling property returns the value null. Using an else clause is important because it’s possible that the button has been disabled by a previous node. Therefore, you must always explicitly set it disabled or enabled, based on the NextSibling property of the current node.
Populating the Children List Box
The child nodes require a different display technique because you cannot predict how many children a node will have. The list box control is a very convenient way to work with child nodes because it is designed to hold lists. Whenever the user wants to display a new node, the list box must be repopulated, based on the current node’s children:
//populate the list box with children
XmlNode childNode;
1stChildren.Items.Clear();
if (theNode.HasChildNodes){
childNode = theNode.FirstChild;
while (childNode != null){
lstChildren.Items.Add(childNode.Name
+ " - " + childNode.InnerText);
childNode = childNode.NextSibling;
} // end while
} // end if statementThe first task is to clear the list box so that any residual items are removed. Then the program checks whether the current node has any child nodes. If not, there is no need to proceed. If so, the local childNode variable is assigned the first child of the parent node. As long as the child node exists (in other words, isn’t null), the name and inner text of the child node are added to the ListBox, and the next sibling is assigned to childNode. If there isn’t a next sibling, childNode will get a null value, which ends the loop.
Moving to the Other Nodes
Three buttons on the XML Viewer form are used to move to a new place within the XML document and display the resulting node. The code for these three methods is very similar, so I will present them together:
private void btnNextSib_Click(object sender,
System.EventArgs e) {
theNode = theNode.NextSibling;
displayNode();
} // end btnNextSib
private void btnParent_Click(object sender,
System.EventArgs e) {
theNode = theNode.ParentNode;
displayNode();
} // end btnParent
private void btnRoot_Click(object sender,
System.EventArgs e) {
theNode = doc.FirstChild;
displayNode();
} // end btnRootAll three of these buttons set theNode to a new node and then call the displayNode() method to display the new node. The only thing different about the various methods is which node is displayed. The btnNextSib_Click() method sets the button to the current node’s next sibling. It isn’t necessary to ensure that there is a next sibling here because the displayNode() method disables this button if there are no more siblings. The code can be called only when theNode has a next sibling.
The btnParent_Click() method sets theNode to the current node’s parent node. As with the sibling, the showNode() method prevents the Parent button from being active if the current node’s parent is not an element.
The btnRoot_Click() method always goes to the root element of the XML document, which is always the first child of the document. There’s no need for error checking here because any valid XML document has at least one child element. The first child of the document is commonly referred to as the root of the document.
Moving to a Child Node
The child nodes of the current node are stored in the lstChildren list box. The general approach to selecting a child is much like that for the buttons. However, ensuring that the viewer moves to the appropriate node requires attention. First, I did not use the default event of the list box because it seemed more appropriate to move to a new child after the user double-clicks a child in the list box. (Usually, if a list box has any direct events, they are related to double clicks. A single click is usually used to change which element in the list box currently has the focus.) The double-click event code uses the selectedIndex property to determine which child the user wants to see and to set theNode appropriately:
private void lstChildren_DoubleClick(object sender,
System.EventArgs e) {
if (lstChildren.Items.Count > 0){
theNode = theNode.ChildNodes[lstChildren.SelectedIndex];
displayNode();
} // end if
} // end lstChildrenUpon testing the program, I discovered that the user could double-click the list box even if the current node has no children, causing an exception. I used an if statement to prevent this situation from occurring.
Opening a New Document
The XML Viewer program works with any valid XML document, not just the one I used as a default. To take advantage of this, I added a button to open a new file. The code for this button displays a File dialog, opens the requested file, and sets the node to the new file’s root node:
private void btnOpen_Click(object sender,
System.EventArgs e) {
if (opener.ShowDialog() != DialogResult.Cancel){
doc.Load(opener.FileName);
theNode = doc.FirstChild;
} // end if
} // end btnOpen
You might want to use the Open button to examine a version of the test XML that might be considered a better design. TestComplex.xml (included on the CD-ROM) has an <answer> element that contains a group of elements. Use the XML Viewer to explore this document and see how it changes things. You might also want to open the XML document in Visual Studio and see how it changes the data mode.