
Scalability has been a much-discussed subject over the years. Even though many things have already been said about it, this topic is very important and here, in this book, it will surely find its place too.
It is not in our interest to deal with all the concepts that involve database scalability, especially in NoSQL databases, but to show the possibilities that MongoDB offers when working with scalability in our collections and also how the flexibility of MongoDB's data model can influence our choices.
It is possible to horizontally scale MongoDB based on a simple infrastructure and low-cost sharding requests. Sharding is the technique of distributing data through multiple physical partitions called shards. Even though the database is physically partitioned, to our clients the database itself is a single instance. The technique of sharding is completely transparent for the database's clients.
Dear reader, get ready! In this chapter, you will see some crucial topics for database maintenance, such as:
- Scaling out with sharding
- Choosing the shard key
- Scaling a social inbox schema design
When we talk about database scalability, we have two reference methods:
The choice between one or the other does not depend on our desire. It depends on the system that we want to scale. It is necessary to know whether it is possible to scale that system in the way that we want to. We must also keep in mind that there is a difference and trade-off between the two techniques.
Increasing the storage capacity, CPU, or memory can be very expensive and sometimes impossible due to our service provider's limitations. On the other hand, increasing the number of nodes in a system can also increase complexity both conceptually and operationally.
However, considering the advances in virtualization technology and the facilities offered by cloud providers, scaling horizontally is becoming the more practical solution for some applications.
MongoDB is prepared to scale horizontally. This is done with the help of a technique of sharding. This technique consists of partitioning our data set and distributing the data among many servers. The main purpose of sharding is to support bigger databases that are able to deal with a high-throughput operation by distributing the operation's load between each shard.
For example, if we have a 1-terabyte database and four configured shards, each shard should have 256 GB of data. But, this does not mean that each shard will manage 25 percent of throughput operation. This will only depend on the way that we decided to construct our shard. This is a big challenge and the main target of this chapter.
The following diagram demonstrates how a shard works on MongoDB:
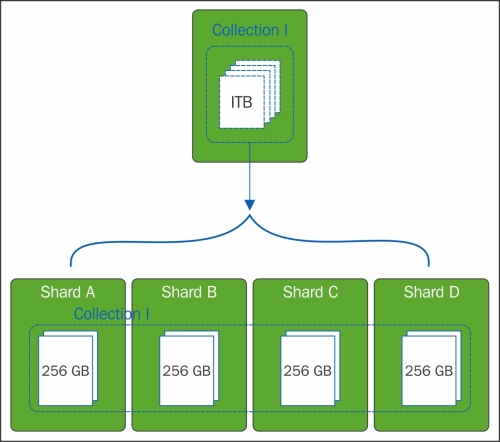
At the time that this book was written, MongoDB, in its 3.0 version, offers multiple sharding policies: range-based, hash-based, and location-based sharding.
- In the range-based policy, MongoDB will partition the data based on the value for the shard key. The documents that the shard key values close to each other will be allocated in the same shard.
- In the hash-based policy, the documents are distributed considering the MD5 value for the shard key.
- In the location-based policy, the documents will be distributed in shards based on a configuration that will associate shard range values with a specific shard. This configuration uses tags to do this, which is very similar to what you saw in Chapter 6, Managing the Data, where we discussed operation segregation.
Sharding works in MongoDB at the collections level, which means we can have collections with sharding and without sharding enabled in the same database. To set sharding in a collection, we must configure a sharded cluster. The elements for a sharded cluster are shards, query routers, and configuration servers:
- A shard is where a part of our data set will be allocated. A shard can be a MongoDB instance or a replica set
- The query router is the interface offered for the database clients that will be responsible for directing the operations to the correct shard
- The config server is a MongoDB instance that is responsible for keeping the sharded cluster configurations or, in other words, the cluster's metadata
The following diagram shows a shared cluster and its components:
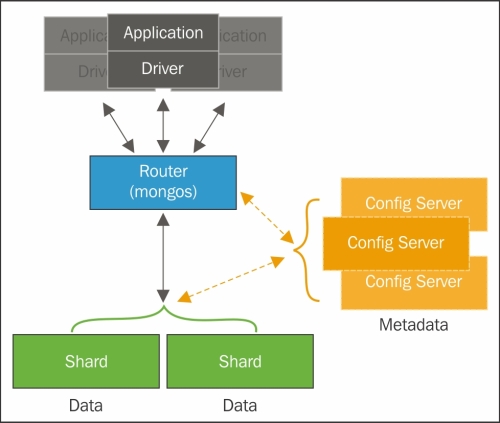
We will not go any deeper into the creation and maintenance of a sharded cluster, as this is not our objective in this chapter. However, it is important to know that the sharded cluster's setup depends on the scenario.
In a production environment, the minimum recommended setup is at least three configuration servers, two or more replica sets, which will be our shards, and one or more query routers. By doing this, we can ensure the minimum redundancy and high availability for our environment.
Once we've decided that we have the need for a sharded cluster, the next step is to choose the shard key. The shard key is responsible for determining the distribution of documents among the cluster's shards. These will also be a key factor in determining the success or the failure of our database.
For each write operation, MongoDB will allocate a new document based on the range value for the shard key. A shard key's range is also known as a chunk. A chunk has a default length of 64 MB, but if you want this value to be customized to your need, it can be configured. In the following diagram, you can see how documents are distributed on chunks given an numeric shard key from infinity negative to infinity positive:
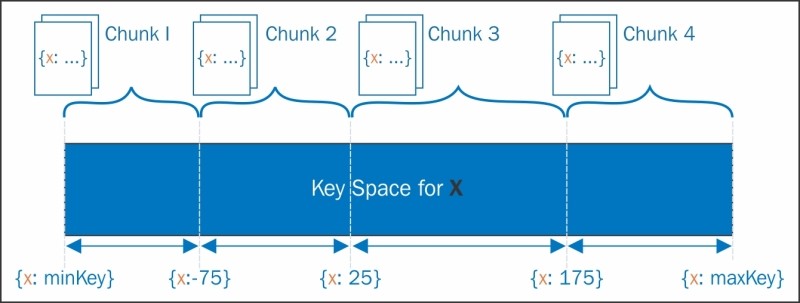
Before starting a discussion about the things that can affect our shard key's construction, there are some limitations in MongoDB that must be respected. These limitations are significant and, in some ways, they help us to eliminate the possibilities of some errors in our choices.
A shard key cannot exceed a length of 512 bytes. A shard key is an indexed field in the document. This index can be a simple field or a composed field, but it will never be a multikey field. It is also possible to use indexes of simple hash fields since the 2.4 version of MongoDB.
The following information must be read quietly, like a mantra, so you will not make any mistakes from the very beginning.
Note
You have to keep one thing in your mind: the shard key is unchangeable.
To repeat, the shard key is unchangeable. That means, dear reader, that once a shard key is created, you can never change it. Never!
You can find detailed information about MongoDB sharded cluster limitations in the MongoDB manual reference at http://docs.mongodb.org/manual/reference/limits/#sharded-clusters.
But what if I created a shard key and I want to change it? What should I do? Instead of trying to change it, we should do the following:
- Execute a dump of the database in a disk file.
- Drop the collection.
- Configure a new collection using the new shard key.
- Execute a pre-split of the chunks.
- Recover the dump file.
As you can see, we do not change the shard key. We recreated almost everything from scratch. Therefore, be careful when executing the command for shard key's creation or you will get a headache if you need to change it.
There is no use in trying to execute the update() method in a field that is part of a shard key. It will not work.
Before we proceed, let's see in practice what we discussed until this point. Let's create a sharded cluster for testing. The following shard configuration is very useful for testing and developing. Never use this configuration in a production environment. The commands given will create:
- Two shards
- One configuration server
- One query router
As a first step, let's start a configuration server instance. The configuration server is nothing more than a mongod instance with the initialization parameter --configsvr. If we do not set a value for the parameter --port <port number>, it will start on port 27019 by default:
mongod --fork --configsvr --dbpath /data/configdb --logpath /log/configdb.log
The next step is to start the query router. The query router is a mongos MongoDB instance, which route queries and write operations to shards, using the parameter --configdb <configdb hostname or ip:port>, which indicates the configuration server. By default, MongoDB starts it on port 27017:
mongos --fork --configdb localhost --logpath /log/router.log
Finally, let's start the shards. The shards in this example will be just two simple instances of mongod. Similar to mongos, a mongod instance starts on port 27017 by default. As we already started the mongos instance on this port, let's set a different port for the mongod instance:
mongod --fork --dbpath /data/mongod1 --port 27001 --logpath /log/mongod1.log mongod --fork --dbpath /data/mongod2 --port 27002 --logpath /log/mongod2.log
Done! Now we have the basic infrastructure for our test sharded cluster. But, wait! We do not have a sharded cluster yet. The next step is to add the shards to the cluster. To do this, we must connect the mongos instance that we already started to the query router:
mongo localhost:27017
Once on the mongos shell, we have to execute the addShard method in the following way:
mongos> sh.addShard("localhost:27001") mongos> sh.addShard("localhost:27002")
If we want to check the result of the preceding operations, we can execute the status()command and see some information about the created shard:
mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("54d9dc74fadbfe60ef7b394e") } shards: { "_id" : "shard0000", "host" : "localhost:27001" } { "_id" : "shard0001", "host" : "localhost:27002" } databases: { "_id" : "admin", "partitioned" : false, "primary" : "config" }
In the returned document, we can only see basic information, such as which the hosts are for our sharded cluster and the databases that we have. For now, we do not have any collection using the sharding enabled. For that reason, the information is greatly simplified.
Now that we have the shards, the configuration server, and the query router, let's enable sharding in the database. It is necessary first to enable sharding in a database before doing the same for a collection. The following command enables sharding in a database called ecommerce:
mongos> sh.enableSharding("ecommerce")
By consulting the sharded cluster's status, we can notice that we have information about our ecommerce database:
mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("54d9dc74fadbfe60ef7b394e") } shards: { "_id" : "shard0000", "host" : "172.17.0.23:27017" } { "_id" : "shard0001", "host" : "172.17.0.24:27017" } databases: { "_id" : "admin", "partitioned" : false, "primary" : "config" } { "_id" : "ecommerce", "partitioned" : true, "primary" : "shard0000" }
Consider that in the ecommerce database, we have a customers collection with the following documents:
{ "_id" : ObjectId("54fb7110e7084a229a66eda2"), "isActive" : true, "age" : 28, "name" : "Paige Johnson", "gender" : "female", "email" : "[email protected]", "phone" : "+1 (830) 484-2397", "address" : { "city" : "Dennard", "state" : "Kansas", "zip" : 2492, "latitude" : -56.564242, "longitude" : -160.872178, "street" : "998 Boerum Place" }, "registered" : ISODate("2013-10-14T14:44:34.853Z"), "friends" : [ { "id" : 0, "name" : "Katelyn Barrett" }, { "id" : 1, "name" : "Weeks Valentine" }, { "id" : 2, "name" : "Wright Jensen" } ] }
We must execute the shardCollection command to enable sharding in this collection, using the collection name and a document that will represent our shard key as a parameter.
Let's enable the shard in the customers collection by executing the following command in the mongos shell:
mongos> sh.shardCollection("ecommerce.customers", {"address.zip": 1, "registered": 1}) { "proposedKey" : { "address.zip" : 1, "registered" : 1 }, "curIndexes" : [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "ecommerce.customers" } ], "ok" : 0, "errmsg" : "please create an index that starts with the shard key before sharding." }
As you can see, something went wrong during the command's execution. MongoDB is warning us that we must have an index and the shard key must be a prefix. So, we must execute the following sequence on the
mongos shell:
mongos> db.customers.createIndex({"address.zip": 1, "registered": 1}) mongos> sh.shardCollection("ecommerce.customers", {"address.zip": 1, "registered": 1}) { "collectionsharded" : "ecommerce.customers", "ok" : 1 }
Well done! Now we have the customers collection of the ecommerce database with the shard enabled.
But what was the factor that determined the choice of address.zip and registered as the shard key? In this case, as I said before, I chose a random field just to illustrate. From now on, let's think about what factors can establish the creation of a good shard key.
The choice of which shard key is not an easy task and there is no recipe for it. Most of the time, knowing our domain and its use in advance is fundamental. It is essential to be very careful when doing this. A not-so-appropriate shard key can bring us a series of problems in our database and consequently affect its performance.
First of all is divisibility. We must think of a shard key that allows us to visualize the documents' division among the shards. A shard key with a limited number of values may result in "unsplittable" chunks.
We can state that this field must have a high cardinality, such as fields with a high variety of values and also unique fields. Identifications fields such as e-mail addresses, usernames, phone numbers, social security numbers, and zip codes are a good example of fields with high cardinality.
In fact, each one of them can be unique if we take into account a certain situation. In an ecommerce system, if we have a document that is related to shipment, we will have more than one document with the same zip code. But, consider another example, a catalogue system for beauty salons in a city. Then, if a document represents a beauty salon, the zip code will be a more unique number than it was in the previous example.
The third is maybe the most polemical point until now because it contradicts the last one in a certain way. We have seen that a shard key with a high randomness degree is good practice in trying to increase the performance in write operations. Now, we will consider a shard key's creation to target a single shard. When we think about performance on read operations, it is a good idea to read from a single shard. As you already know, in a sharded cluster, the database complexity is abstracted on the query router. In other words, it is mongos' responsibility to discover which shards it should search for the information requested in a query. If our shard key is distributed across multiple shards, then mongos will search for the information on the shards, collect and merge them all, and then deliver it. But, if the shard key was planned to target a single shard, then the mongos task will search for the information in this unique shard and, in sequence, deliver it.
The fourth and last point is about cases when we do not have any field in the document that would be a good choice for our shard key. In this situation, we must think about a composed shard key. In the previous example, we use a composed shard key with the fields address.zip and registered. A composed shard key will also help us to have a more divisible key due the fact that if the first value from the shard key does not have a high cardinality, adding a second value will increase the cardinality.
So, these basic concerns show us that depending on what we want to search for, we should choose different approaches for the shard key's document. If we need query insulation, then a shard key that can focus on one shard is a good choice. But, when we need to escalate the write operation, the more random our shard key, the better it will be for performance.